Se connecter à des tables Common Data Model dans Azure Data Lake Storage
Note
Azure Active Directory est désormais Microsoft Entra ID. En savoir plus
Ingérer des données dans Dynamics 365 Customer Insights - Data en utilisant votre Azure Data Lake Storage compte avec les tables Common Data Model. L’ingestion de données peut être complète ou incrémentielle.
Conditions préalables
Le compte Azure Data Lake Storage doit avoir activé l’espace de noms hiérarchique. Les données doivent être stockées dans un format de dossier hiérarchique qui définit le dossier racine et comporte des sous-dossiers pour chaque table. Les sous-dossiers peuvent contenir des données complètes ou des dossiers de données incrémentielles.
Pour vous authentifier dans un principal de service Microsoft Entra, assurez-vous que celui-ci est configuré dans votre client. Pour plus d’informations, consultez Se connecter à un compte Azure Data Lake Storage avec un principal de service Microsoft Entra.
Pour vous connecter au stockage protégé par des pare-feu, Configurez des liens privés Azure.
Si votre lac de données a actuellement des connexions de lien privé qui lui sont associées, Customer Insights - Data doit également se connecter à l’aide d’un lien privé, quel que soit le paramètre d’accès au réseau.
Le Azure Data Lake Storage à partir duquel vous souhaitez vous connecter et ingérer les données doit se trouver dans la même région Azure que l’environnement Dynamics 365 Customer Insights et les abonnements doivent se trouver dans le même client. Les connexions à un dossier Common Data Model à partir d’un lac de données situé dans une autre région Azure ne sont pas prises en charge. Pour connaître la région Azure de l’environnement, accédez à Paramètres>Système>À propos de dans Customer Insights - Data.
Les données stockées dans des services en ligne peuvent être stockées dans un emplacement différent de celui où les données sont traitées ou stockées. En important ou en vous connectant aux données stockées dans des services en ligne, vous acceptez que les données puissent être transférées. En savoir plus dans le Centre de gestion de la confidentialité Microsoft.
Le principal du service Customer Insights - Data doit être dans l’un des rôles suivants pour accéder au compte de stockage. Pour plus d’informations, voir Accorder des autorisations au principal du service pour accéder au compte de stockage.
- Lecteur de données d’objets BLOB de stockage
- Propriétaire de données d’objets BLOB de stockage
- Contributeur de données BLOB de stockage
Lors de la connexion à votre stockage Azure à l’aide de l’option Abonnement Azure, l’utilisateur qui configure la connexion à la source de données a besoin au moins des autorisations de Contributeur des données blob de stockage sur le compte de stockage.
Lors de la connexion à votre stockage Azure à l’aide de l’option Ressource Azure, l’utilisateur qui configure la connexion à la source de données a besoin au moins de l’autorisation pour l’action Microsoft.Storage/storageAccounts/read sur le compte de stockage. Un rôle intégré Azure qui inclut cette action est le rôle de Lecteur. Pour limiter l’accès uniquement à l’action nécessaire, créez un rôle personnalisé Azure qui inclut uniquement cette action.
Pour obtenir des performances optimales, la taille d’une partition doit être inférieure ou égale à 1 Go et le nombre de fichiers de partition dans un dossier ne dépasse pas 1 000.
Les données de votre Data Lake Storage doivent suivre la norme Common Data Model pour le stockage de vos données et avoir le manifeste Common Data Model pour représenter le schéma des fichiers de données (*.csv ou *.parquet). Le manifeste doit fournir les détails des tables telles que les colonnes de table et les types de données, ainsi que l’emplacement du fichier de données et le type de fichier. Pour plus d’informations, voir Manifeste Common Data Model. Si le manifeste n’est pas présent, les utilisateurs administrateurs disposant d’un accès Propriétaire des données blob de stockage ou Contributeur de données blob de stockage peuvent définir le schéma lors de l’ingestion des données.
Note
Si l’un des champs des fichiers .parquet a le type de données Int96, les données peuvent ne pas s’afficher sur la page Tables. Nous vous recommandons d’utiliser des types de données standard, tels que le format d’horodatage Unix (qui représente le temps en nombre de secondes depuis le 1er janvier 1970 à minuit UTC).
Limitations
- Customer Insights - Data ne prend pas en charge les colonnes de type décimal avec une précision supérieure à 16.
Se connecter à Azure Data Lake Storage
Les noms de connexion de données, les chemins de données tels que les dossiers dans un conteneur et les noms de table doivent utiliser des noms commençant par une lettre. Les noms ne peuvent contenir que des lettres, des nombres et des traits de soulignement (_). Les caractères spéciaux ne sont pas pris en charge.
Accédez à Données>Sources de données.
Sélectionnez Ajouter une source de données.
Sélectionner Tables Common Data Model Azure Data Lake.

Entrez le nom de la source de données et une description facultative. Le nom est référencé dans les processus en aval et ne peut pas être modifié après la création de la source de données.
Choisissez l’une des options suivantes pour Connecter votre stockage à l’aide de. Pour plus d’informations, consultez Se connecter à un compte Azure Data Lake Storage avec un principal de service Microsoft Entra.
- Ressource Azure : entrez l’ID de la ressource.
- Abonnement Azure : Sélectionnez le compte Abonnement, puis le Groupe de ressources et le Compte de stockage.
Note
Vous devez avoir l’un des rôles suivants pour le conteneur pour créer la source de données :
- Le rôle Lecteur des données blob de stockage est suffisant pour lire à partir d’un compte de stockage et ingérer les données dans Customer Insights - Data.
- Le rôle Contributeur ou propriétaire des données blob de stockage est nécessaire si vous souhaitez modifier les fichiers manifeste directement dans Customer Insights - Data.
Avoir le rôle dans le compte de stockage fournira le même rôle dans tous ses conteneurs.
Choisissez le nom du Conteneur contenant les données et le schéma (fichier model.json ou manifest.json) à partir desquels importer les données.
Note
Tout fichier model.json ou manifest.json associé à une autre source de données dans l’environnement n’apparaîtra pas dans la liste. Cependant, le même fichier model.json ou manifest.json peut être utilisé pour les sources de données dans plusieurs environnements.
Facultativement, si vous souhaitez ingérer des données à partir d’un compte de stockage via un lien privé Azure, sélectionnez Activer la liaison privée. Pour plus d’informations, consultez Liens privés.
Pour créer un nouveau schéma, accédez à Créer un nouveau fichier de schéma.
Pour utiliser un schéma existant, accédez au dossier contenant le fichier model.json ou manifest.cdm.json. Vous pouvez effectuer une recherche dans un répertoire pour trouver le fichier.
Sélectionnez le fichier json, puis sélectionnez Suivant. La liste des tables disponibles s’affiche.
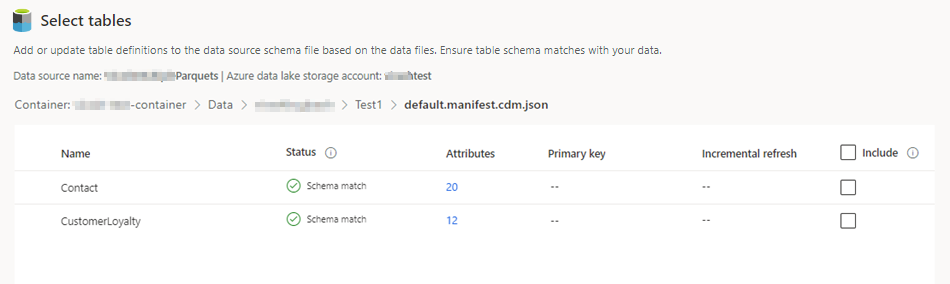
Sélectionnez les tables que vous souhaitez inclure.
Astuce
Pour modifier une table dans une interface d’édition JSON, sélectionnez-la, puis sélectionnez Modifier le fichier de schéma. Apportez vos modifications, puis sélectionnez Enregistrer.
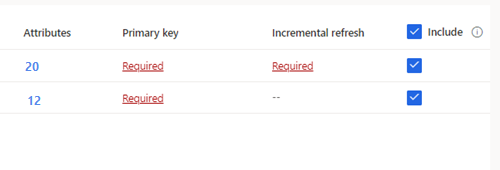
Pour les tables sélectionnées où une clé primaire n’a pas été définie, Obligatoire s’affiche sous Clé primaire. Pour chacune de ces tables :
- Sélectionnez Obligatoire. Le panneau Modifier l’entité s’affiche.
- Choisissez la Clé primaire. La clé primaire est un attribut unique à la table. Pour qu’un attribut soit une clé primaire valide, il ne doit inclure aucune valeur en double, aucune valeur manquante, ni aucune valeur nulle. Les attributs de type de données chaîne, entier et GUID sont pris en charge en tant que clés primaires.
- Facultativement, modifiez le modèle de partition.
- Sélectionnez Fermer, puis enregistrez et fermez le volet.
Sélectionnez le nombre de colonnes pour chaque table incluse. La page Gérer les attributs s’affiche.
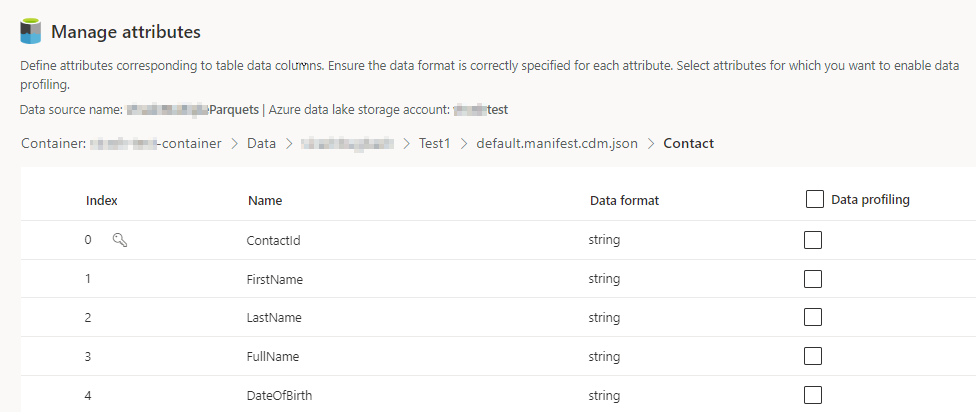
- Créez des colonnes, modifiez ou supprimez des colonnes existantes. Vous pouvez modifier le nom, le format des données ou ajouter un type sémantique.
- Pour activer l’analyse et d’autres fonctionnalités, sélectionnez Profilage des données pour toute la table ou pour des colonnes spécifiques. Par défaut, aucune table n’est activée pour le profilage des données.
- Cliquez sur Terminé.
Sélectionnez Enregistrer. La page Source de données s’ouvre et affiche la nouvelle source de données avec le statut Actualisation en cours.
Astuce
Il existe des statuts pour les tâches et les processus. La plupart des processus dépendent d’autres processus en amont, tels que l’actualisation des sources de données et du profilage des données.
Sélectionnez le statut pour ouvrir le volet Détails de la progression et afficher la progression des tâches. Pour annuler la tâche, sélectionnez Annuler la tâche en bas du volet.
Sous chaque tâche, sélectionnez Afficher les détails pour plus d’informations sur l’avancement, telles que l’heure du traitement, la date du dernier traitement et les erreurs et avertissements applicables associés à la tâche ou au processus. Sélectionnez l’option Afficher le statut du système en bas du volet pour voir les autres processus du système.

Le chargement des données peut prendre du temps. Après une actualisation réussie, les données ingérées peuvent être consultées à partir de la page Tables.
Créer un fichier de schéma
Sélectionnez Créer un fichier de schéma.
Saisissez un nom pour le fichier et sélectionnez Enregistrer.
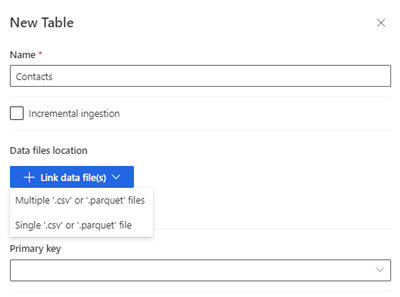
Sélectionnez Nouvelle table. Le volet Nouvelle table s’affiche.
Entrez le nom de la table et choisissez l’Emplacement des fichiers de données.
- Plusieurs fichiers .csv ou .parquet : Naviguez jusqu'au dossier racine, sélectionnez le type de motif et saisissez l'expression.
- Fichiers .csv ou .parquet uniques : Naviguez jusqu'au fichier .csv ou .parquet et sélectionnez-le.
Sélectionnez Enregistrer.
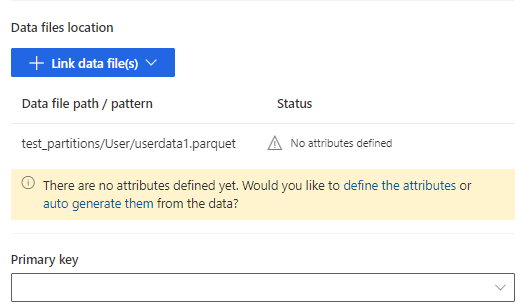
Sélectionnez définir les attributs pour ajouter manuellement les attributs, ou sélectionnez les générer automatiquement. Pour définir les attributs, entrez un nom, sélectionnez le format de données et le type sémantique facultatif. Pour les attributs générés automatiquement :
Une fois les attributs générés automatiquement, sélectionnez Examiner les attributs. La page Gérer les attributs s’affiche.
Assurez-vous que le format de données est correct pour chaque attribut.
Pour activer l’analyse et d’autres fonctionnalités, sélectionnez Profilage des données pour l’ensemble de l’entité ou pour des colonnes spécifiques. Par défaut, aucune table n’est activée pour le profilage des données.
Cliquez sur Terminé. La page Sélectionner des tables s’affiche.
Continuez à ajouter des tables et des colonnes, le cas échéant.
Une fois toutes les entités ajoutées, sélectionnez Inclure pour inclure les tables dans l’ingestion de source de données.
Pour les tables sélectionnées où une clé primaire n’a pas été définie, Obligatoire s’affiche sous Clé primaire. Pour chacune de ces tables :
- Sélectionnez Obligatoire. Le panneau Modifier l’entité s’affiche.
- Choisissez la Clé primaire. La clé primaire est un attribut unique à la table. Pour qu’un attribut soit une clé primaire valide, il ne doit inclure aucune valeur en double, aucune valeur manquante, ni aucune valeur nulle. Les attributs de type de données chaîne, entier et GUID sont pris en charge en tant que clés primaires.
- Facultativement, modifiez le modèle de partition.
- Sélectionnez Fermer, puis enregistrez et fermez le volet.
Cliquez sur Enregistrer. La page Source de données s’ouvre et affiche la nouvelle source de données avec le statut Actualisation en cours.
Astuce
Il existe des statuts pour les tâches et les processus. La plupart des processus dépendent d’autres processus en amont, tels que l’actualisation des sources de données et du profilage des données.
Sélectionnez le statut pour ouvrir le volet Détails de la progression et afficher la progression des tâches. Pour annuler la tâche, sélectionnez Annuler la tâche en bas du volet.
Sous chaque tâche, sélectionnez Afficher les détails pour plus d’informations sur l’avancement, telles que l’heure du traitement, la date du dernier traitement et les erreurs et avertissements applicables associés à la tâche ou au processus. Sélectionnez l’option Afficher le statut du système en bas du volet pour voir les autres processus du système.
Le chargement des données peut prendre du temps. Après une actualisation réussie, les données ingérées peuvent être consultées à partir de la page Données>Tables.
Modifier une source de données Azure Data Lake Storage
Vous pouvez mettre à jour l’option Se connecter au compte de stockage à l’aide de. Pour plus d’informations, consultez Se connecter à un compte Azure Data Lake Storage avec un principal de service Microsoft Entra. Pour vous connecter à un autre conteneur à partir de votre compte de stockage ou modifier le nom du compte, créer une connexion de source de données.
Accédez à Données>Sources de données. En regard de la source de données que vous souhaitez mettre à jour, sélectionnez Modifier.
Modifiez les informations suivantes :
Description
Connectez votre stockage à l'aide de et les informations de connexion. Vous ne pouvez pas modifier les informations du Conteneur lors de la mise à jour de la connexion.
Note
L’un des rôles suivants doit être attribué au compte de stockage ou au conteneur :
- Lecteur de données d’objets BLOB de stockage
- Propriétaire de données d’objets BLOB de stockage
- Contributeur de données BLOB de stockage
Activez la liaison privée si vous souhaitez ingérer des données à partir d'un compte de stockage via une liaison Azure Private Link. Pour plus d’informations, consultez Liens privés.
Sélectionnez Suivant.
Modifiez ce qui suit :
Accédez à un autre fichier model.json ou manifest.json avec un ensemble de tables différent du conteneur.
Pour ajouter des entités supplémentaires à ingérer, sélectionnez Nouvelle table.
Pour supprimer toutes les tables déjà sélectionnées s’il n’y a pas de dépendances, sélectionnez la table et Supprimer.
Important
S’il existe des dépendances sur le fichier model.json ou manifest.json existant et sur l’ensemble de tables, vous verrez un message d’erreur et vous ne pourrez pas sélectionner un autre fichier model.json ou manifest.json. Supprimez ces dépendances avant de modifier le fichier model.json ou manifest.json ou créez une source de données avec le fichier model.json ou manifest.json que vous souhaitez utiliser pour éviter de supprimer les dépendances.
Pour modifier l’emplacement du fichier de données ou la clé primaire, sélectionnez Modifier.
Modifiez uniquement le nom de la table pour qu’il corresponde au nom de la table dans le fichier .json.
Note
Conservez toujours le même nom de table dans que le nom de table dans le fichier model.json ou manifest.json après l’ingestion. Customer Insights - Data valide tous les noms de table avec model.json ou manifest.json lors de chaque actualisation du système. Si le nom d’une table change, une erreur se produit, car Customer Insights - Data ne peut pas trouver le nouveau nom de table dans le fichier .json. Si un nom de table ingéré a été accidentellement modifié, modifiez le nom de la table pour qu’il corresponde au nom dans le fichier .json.
Sélectionnez Colonnes pour les ajouter ou les modifier, ou pour activer le profilage des données. Puis sélectionnez Terminé.
Sélectionnez Enregistrer pour appliquer vos modifications et revenir à la page Sources de données.
Astuce
Il existe des statuts pour les tâches et les processus. La plupart des processus dépendent d’autres processus en amont, tels que l’actualisation des sources de données et du profilage des données.
Sélectionnez le statut pour ouvrir le volet Détails de la progression et afficher la progression des tâches. Pour annuler la tâche, sélectionnez Annuler la tâche en bas du volet.
Sous chaque tâche, sélectionnez Afficher les détails pour plus d’informations sur l’avancement, telles que l’heure du traitement, la date du dernier traitement et les erreurs et avertissements applicables associés à la tâche ou au processus. Sélectionnez l’option Afficher le statut du système en bas du volet pour voir les autres processus du système.