What is ML.NET and how does it work?
ML.NET gives you the ability to add machine learning to .NET applications, in either online or offline scenarios. With this capability, you can make automatic predictions using the data available to your application. Machine learning applications make use of patterns in the data to make predictions rather than needing to be explicitly programmed.
Central to ML.NET is a machine learning model. The model specifies the steps needed to transform your input data into a prediction. With ML.NET, you can train a custom model by specifying an algorithm, or you can import pretrained TensorFlow and Open Neural Network Exchange (ONNX) models.
Once you have a model, you can add it to your application to make the predictions.
ML.NET runs on Windows, Linux, and macOS using .NET, or on Windows using .NET Framework. 64 bit is supported on all platforms. 32 bit is supported on Windows, except for TensorFlow, LightGBM, and ONNX-related functionality.
The following table shows examples of the type of predictions that you can make with ML.NET.
| Prediction type | Example |
|---|---|
| Classification/Categorization | Automatically divide customer feedback into positive and negative categories. |
| Regression/Predict continuous values | Predict the price of houses based on size and location. |
| Anomaly detection | Detect fraudulent banking transactions. |
| Recommendations | Suggest products that online shoppers might want to buy, based on their previous purchases. |
| Time series/sequential data | Forecast the weather or product sales. |
| Image classification | Categorize pathologies in medical images. |
| Text classification | Categorize documents based on their content. |
| Sentence similarity | Measure how similar two sentences are. |
Simple ML.NET app
The code in the following snippet demonstrates the simplest ML.NET application. This example constructs a linear regression model to predict house prices using house size and price data.
using Microsoft.ML;
using Microsoft.ML.Data;
class Program
{
public record HouseData
{
public float Size { get; set; }
public float Price { get; set; }
}
public record Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
static void Main(string[] args)
{
MLContext mlContext = new();
// 1. Import or create training data.
HouseData[] houseData = [
new() { Size = 1.1F, Price = 1.2F },
new() { Size = 1.9F, Price = 2.3F },
new() { Size = 2.8F, Price = 3.0F },
new() { Size = 3.4F, Price = 3.7F }
];
IDataView trainingData = mlContext.Data.LoadFromEnumerable(houseData);
// 2. Specify data preparation and model training pipeline.
EstimatorChain<RegressionPredictionTransformer<Microsoft.ML.Trainers.LinearRegressionModelParameters>> pipeline = mlContext.Transforms.Concatenate("Features", ["Size"])
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
// 3. Train model.
TransformerChain<RegressionPredictionTransformer<Microsoft.ML.Trainers.LinearRegressionModelParameters>> model = pipeline.Fit(trainingData);
// 4. Make a prediction.
HouseData size = new() { Size = 2.5F };
Prediction price = mlContext.Model.CreatePredictionEngine<HouseData, Prediction>(model).Predict(size);
Console.WriteLine($"Predicted price for size: {size.Size * 1000} sq ft = {price.Price * 100:C}k");
// Predicted price for size: 2500 sq ft = $261.98k
}
}
Code workflow
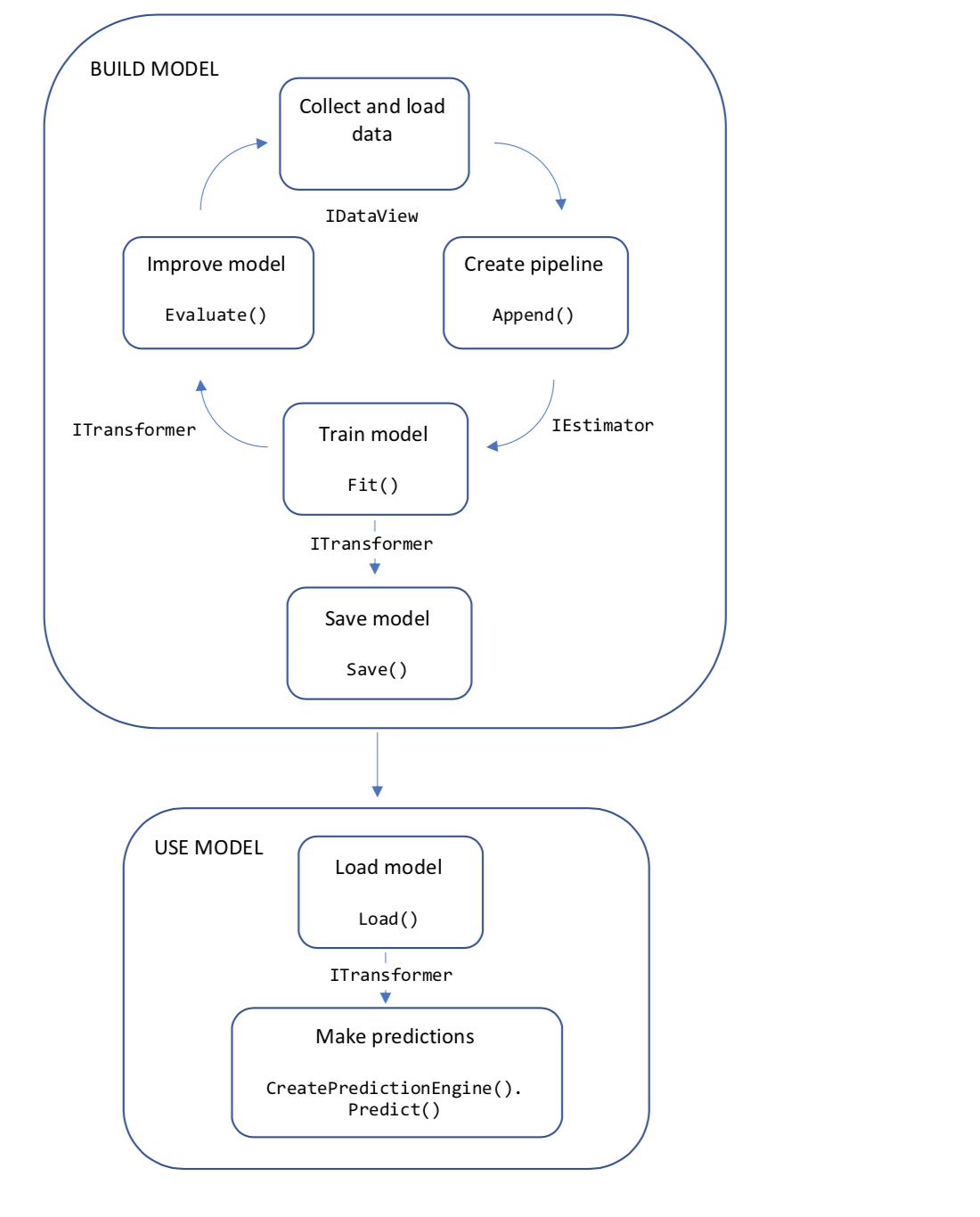
The following diagram represents the application code structure and the iterative process of model development:
- Collect and load training data into an IDataView object
- Specify a pipeline of operations to extract features and apply a machine learning algorithm
- Train a model by calling Fit(IDataView) on the pipeline
- Evaluate the model and iterate to improve
- Save the model into binary format, for use in an application
- Load the model back into an ITransformer object
- Make predictions by calling PredictionEngineBase<TSrc,TDst>.Predict
Let's dig a little deeper into those concepts.
Machine learning model
An ML.NET model is an object that contains transformations to perform on your input data to arrive at the predicted output.
Basic
The most basic model is two-dimensional linear regression, where one continuous quantity is proportional to another, as in the house price example shown previously.

The model is simply: $Price = b + Size * w$. The parameters $b$ and $w$ are estimated by fitting a line on a set of (size, price) pairs. The data used to find the parameters of the model is called training data. The inputs of a machine learning model are called features. In this example, $Size$ is the only feature. The ground-truth values used to train a machine learning model are called labels. Here, the $Price$ values in the training data set are the labels.
More complex
A more complex model classifies financial transactions into categories using the transaction text description.
Each transaction description is broken down into a set of features by removing redundant words and characters, and counting word and character combinations. The feature set is used to train a linear model based on the set of categories in the training data. The more similar a new description is to the ones in the training set, the more likely it will be assigned to the same category.

Both the house price model and the text classification model are linear models. Depending on the nature of your data and the problem you're solving, you can also use decision tree models, generalized additive models, and others. You can find out more about the models in Tasks.
Data preparation
In most cases, the data that you have available isn't suitable to be used directly to train a machine learning model. The raw data needs to be prepared, or preprocessed, before it can be used to find the parameters of your model. Your data might need to be converted from string values to a numerical representation. You might have redundant information in your input data. You might need to reduce or expand the dimensions of your input data. Your data might need to be normalized or scaled.
The ML.NET tutorials teach you about different data processing pipelines for text, image, numerical, and time-series data used for specific machine learning tasks.
How to prepare your data shows you how to apply data preparation more generally.
You can find an appendix of all of the available transformations in the resources section.
Model evaluation
Once you've trained your model, how do you know how well it will make future predictions? With ML.NET, you can evaluate your model against some new test data.
Each type of machine learning task has metrics used to evaluate the accuracy and precision of the model against the test data set.
The house price example shown earlier used the Regression task. To evaluate the model, add the following code to the original sample.
HouseData[] testHouseData =
{
new HouseData() { Size = 1.1F, Price = 0.98F },
new HouseData() { Size = 1.9F, Price = 2.1F },
new HouseData() { Size = 2.8F, Price = 2.9F },
new HouseData() { Size = 3.4F, Price = 3.6F }
};
var testHouseDataView = mlContext.Data.LoadFromEnumerable(testHouseData);
var testPriceDataView = model.Transform(testHouseDataView);
var metrics = mlContext.Regression.Evaluate(testPriceDataView, labelColumnName: "Price");
Console.WriteLine($"R^2: {metrics.RSquared:0.##}");
Console.WriteLine($"RMS error: {metrics.RootMeanSquaredError:0.##}");
// R^2: 0.96
// RMS error: 0.19
The evaluation metrics tell you that the error is low-ish, and that correlation between the predicted output and the test output is high. That was easy! In real examples, it takes more tuning to achieve good model metrics.
ML.NET architecture
This section describes the architectural patterns of ML.NET. If you're an experienced .NET developer, some of these patterns will be familiar to you, and some will be less familiar.
An ML.NET application starts with an MLContext object. This singleton object contains catalogs. A catalog is a factory for data loading and saving, transforms, trainers, and model operation components. Each catalog object has methods to create the different types of components.
| Task | Catalog |
|---|---|
| Data loading and saving | DataOperationsCatalog |
| Data preparation | TransformsCatalog |
| Binary classification | BinaryClassificationCatalog |
| Multiclass classification | MulticlassClassificationCatalog |
| Anomaly detection | AnomalyDetectionCatalog |
| Clustering | ClusteringCatalog |
| Forecasting | ForecastingCatalog |
| Ranking | RankingCatalog |
| Regression | RegressionCatalog |
| Recommendation | RecommendationCatalog |
| Time series | TimeSeriesCatalog |
| Model usage | ModelOperationsCatalog |
You can navigate to the creation methods in each of the listed categories. If you use Visual Studio, the catalogs also show up via IntelliSense.
Build the pipeline
Inside each catalog is a set of extension methods that you can use to create a training pipeline.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
In the snippet, Concatenate and Sdca are both methods in the catalog. They each create an IEstimator object that's appended to the pipeline.
At this point, the objects have been created, but no execution has happened.
Train the model
Once the objects in the pipeline have been created, data can be used to train the model.
var model = pipeline.Fit(trainingData);
Calling Fit() uses the input training data to estimate the parameters of the model. This is known as training the model. Remember, the linear regression model shown earlier had two model parameters: bias and weight. After the Fit() call, the values of the parameters are known. (Most models will have many more parameters than this.)
You can learn more about model training in How to train your model.
The resulting model object implements the ITransformer interface. That is, the model transforms input data into predictions.
IDataView predictions = model.Transform(inputData);
Use the model
You can transform input data into predictions in bulk, or one input at a time. The house price example did both: in bulk to evaluate the model, and one at a time to make a new prediction. Let's look at making single predictions.
var size = new HouseData() { Size = 2.5F };
var predEngine = mlContext.CreatePredictionEngine<HouseData, Prediction>(model);
var price = predEngine.Predict(size);
The CreatePredictionEngine() method takes an input class and an output class. The field names or code attributes determine the names of the data columns used during model training and prediction. For more information, see Make predictions with a trained model.
Data models and schema
At the core of an ML.NET machine learning pipeline are DataView objects.
Each transformation in the pipeline has an input schema (data names, types, and sizes that the transform expects to see on its input); and an output schema (data names, types, and sizes that the transform produces after the transformation).
If the output schema from one transform in the pipeline doesn't match the input schema of the next transform, ML.NET will throw an exception.
A data view object has columns and rows. Each column has a name and a type and a length. For example, the input columns in the house price example are Size and Price. They are both type Single and they're scalar quantities rather than vector ones.
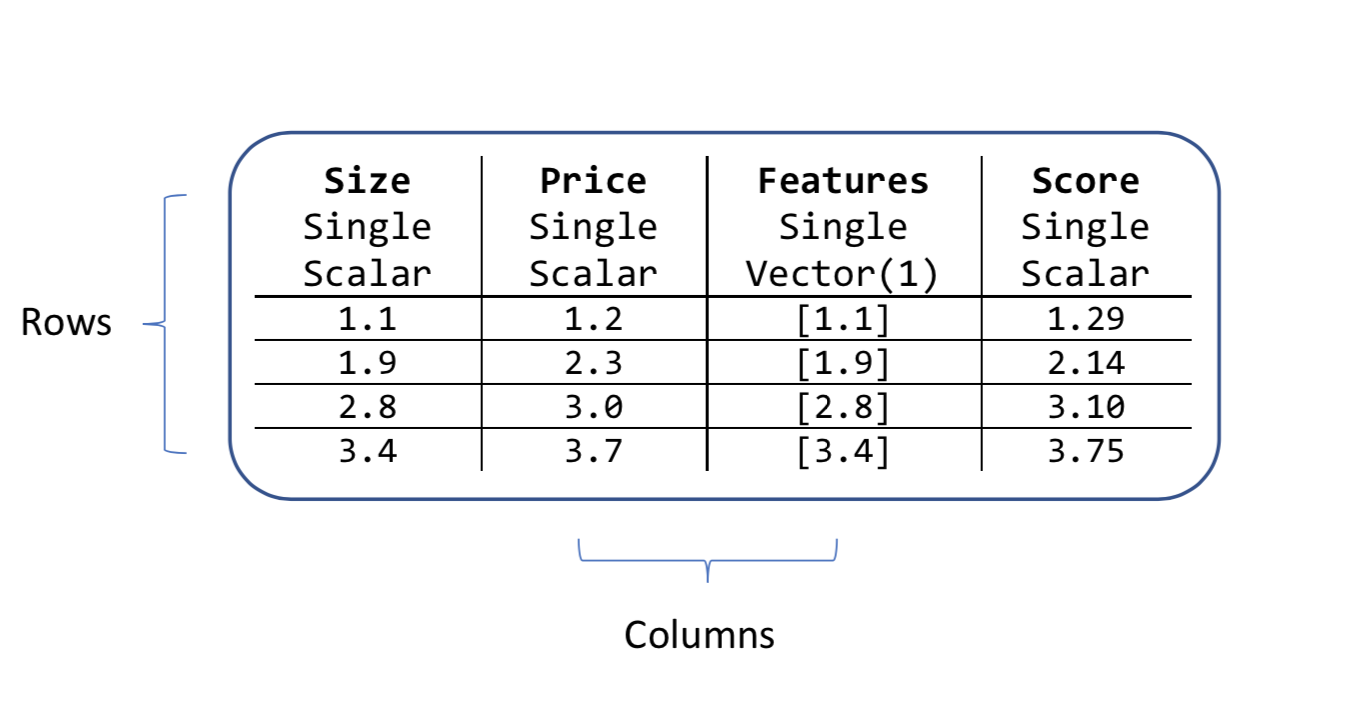
All ML.NET algorithms look for an input column that's a vector. By default, this vector column is called Features. That's why the house price example concatenated the Size column into a new column called Features.
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
All algorithms also create new columns after they've performed a prediction. The fixed names of these new columns depend on the type of machine learning algorithm. For the regression task, one of the new columns is called Score as shown in the price data attribute.
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
You can find out more about output columns of different machine learning tasks in the Machine Learning Tasks guide.
An important property of DataView objects is that they're evaluated lazily. Data views are only loaded and operated on during model training and evaluation, and data prediction. While you're writing and testing your ML.NET application, you can use the Visual Studio debugger to take a peek at any data view object by calling the Preview method.
var debug = testPriceDataView.Preview();
You can watch the debug variable in the debugger and examine its contents.
Note
Don't use the Preview(IDataView, Int32) method in production code, as it significantly degrades performance.
Model deployment
In real-life applications, your model training and evaluation code will be separate from your prediction. In fact, these two activities are often performed by separate teams. Your model development team can save the model for use in the prediction application.
mlContext.Model.Save(model, trainingData.Schema, "model.zip");
Next steps
- Learn how to build applications using different machine learning tasks with more realistic data sets in the tutorials.
- Learn about specific topics in more depth in the how-to guides.
- Dive straight into the API reference documentation.