Appliquer des modèles CQRS et DDD simplifiés dans un microservice
Conseil
Ce contenu est un extrait du livre électronique « .NET Microservices Architecture for Containerized .NET Applications », disponible sur .NET Docs ou sous forme de PDF téléchargeable gratuitement et pouvant être lu hors ligne.

CQRS est un modèle d’architecture qui sépare les modèles pour la lecture et l’écriture de données. Le terme connexe CQS (séparation des commandes et des requêtes) a été initialement défini par Bertrand Meyer dans son livre Object-Oriented Software Construction. L’idée de base est que vous pouvez diviser les opérations d’un système en deux catégories nettement séparées :
Requêtes. Ces requêtes retournent un résultat et ne modifient pas l’état du système, et elles sont exemptes d’effets secondaires.
Les commandes. Ces commandes modifient l’état d’un système.
CQS est un concept simple : il s’agit de méthodes du même objet qui sont soit des requêtes, soit des commandes. Chaque méthode retourne l’état ou transforme l’état, mais pas les deux. Même un seul objet de modèle de dépôt peut se conformer à CQS. L’approche CQS peut être considérée comme un principe fondamental de CQRS.
L’approche CQRS (séparation des responsabilités dans les commandes et les requêtes), introduite par Greg Young, a été vivement plébiscitée par Udi Dahan et d’autres. Elle est basée sur le principe CQS, même si elle est plus détaillée. Elle peut être considérée comme un modèle basé sur les commandes et les événements, et éventuellement sur les messages asynchrones. Dans de nombreux cas, CQRS est lié à des scénarios plus avancés, comme disposer d’une base de données physique différente pour les lectures (requêtes) et pour les écritures (mises à jour). De plus, un système CQRS plus évolué peut implémenter la fonctionnalité d’Event Sourcing (approvisionnement d’événements) pour votre base de données de mises à jour, de sorte que vous ne stockez que les événements du modèle de domaine au lieu de stocker les données d’état actuel. Toutefois, cette approche n’est pas utilisée dans ce guide. Ce guide utilise l’approche CQRS la plus simple, qui consiste simplement à séparer les requêtes des commandes.
L’aspect de séparation de CQRS est obtenu en regroupant les opérations de requête dans une couche et les commandes dans une autre couche. Chaque couche a son propre modèle de données (notez que nous disons « modèle », pas nécessairement une base de données différente) et est construite à l’aide de sa propre combinaison de modèles et de technologies. Plus important encore, les deux couches peuvent se trouver dans le même niveau ou microservice, comme dans l’exemple (microservice de commandes) utilisé dans ce guide. Elles peuvent également être implémentées sur des microservices ou processus différents afin de pouvoir être optimisées et adaptées séparément sans s’affecter mutuellement.
CQRS implique d’avoir deux objets pour une opération de lecture/écriture où, dans d’autres contextes, il y en a un. Il existe des raisons d’avoir une base de données de lectures dénormalisée, sur laquelle vous pouvez obtenir des informations dans une documentation CQRS plus avancée. Mais nous n’utilisons pas cette approche ici, où l’objectif est d’avoir plus de souplesse dans les requêtes, et non pas de limiter les requêtes avec des contraintes à partir de modèles DDD comme les agrégats.
Il peut s’agir, par exemple, du microservice de commandes de l’application de référence eShopOnContainers. Ce service implémente un microservice basé sur une approche CQRS simplifiée. Il utilise une seule source de données ou base de données, mais deux modèles logiques plus des modèles DDD pour le domaine transactionnel, comme illustré dans la figure 7-2.
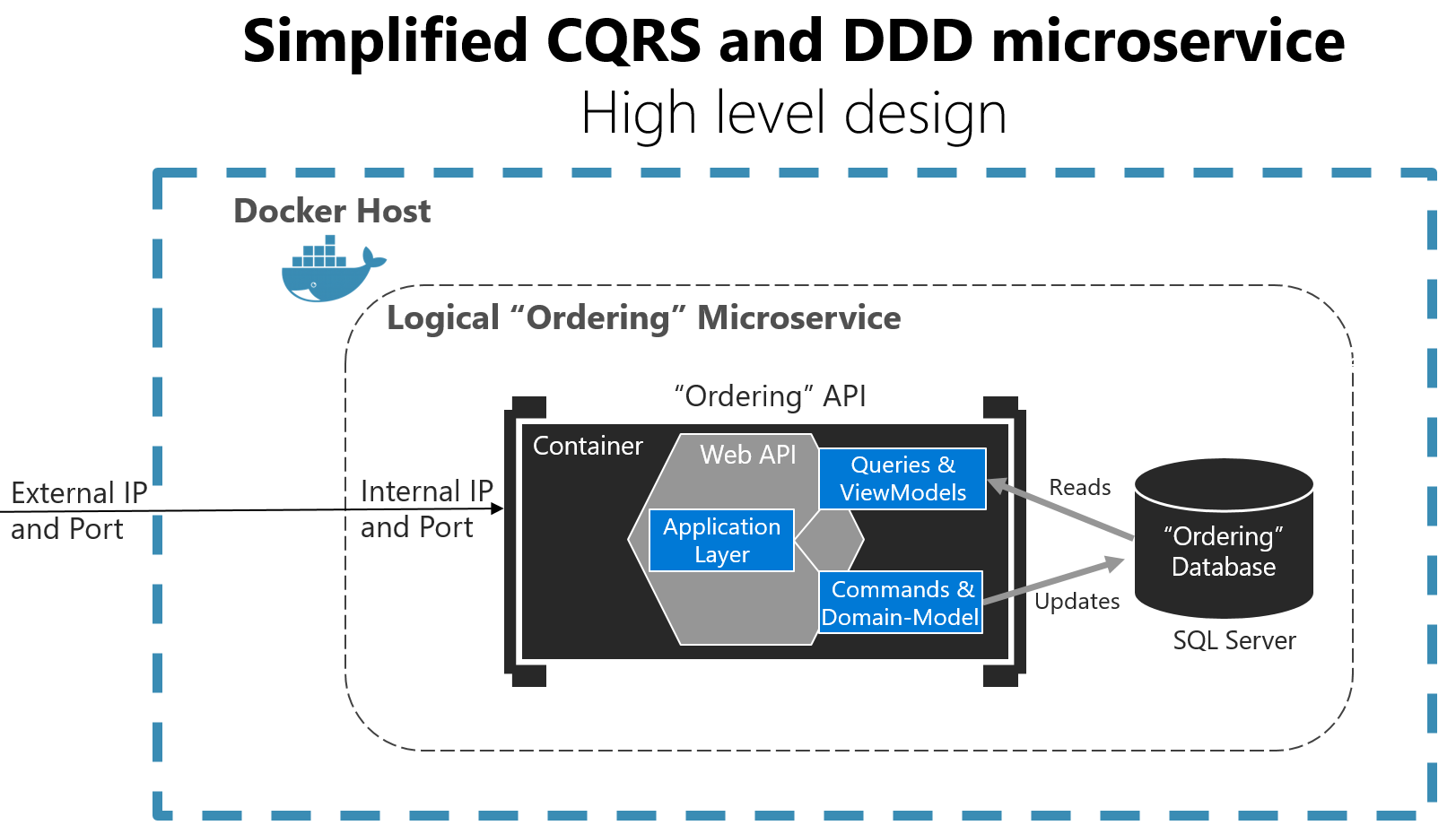
Figure 7-2. Microservice basé sur les modèles CQRS et DDD simplifiés
Le microservice « Ordering » logique inclut sa base de données Ordering, qui peut être, mais sans obligation, le même hôte Docker. Le fait d’avoir la base de données dans le même hôte Docker est parfait pour le développement, mais pas pour la production.
La couche Application peut être l’API web elle-même. Ici, l’aspect important de la conception est que le microservice a séparé les requêtes et les ViewModels (modèles de données spécialement créés pour les applications clientes) des commandes, du modèle de domaine et des transactions suivant le modèle CQRS. Avec cette approche, les requêtes restent indépendantes des restrictions et des contraintes provenant de modèles DDD qui conviennent uniquement pour les transactions et les mises à jour, comme expliqué dans des sections ultérieures.
Ressources supplémentaires
- Greg Young. Gestion de versions dans un système reposant sur les sources d’événements (Livre électronique en ligne gratuit)
https://leanpub.com/esversioning/read