Microservices conteneurisés
Conseil
Ce contenu est un extrait du livre électronique Modèles d’application d’entreprise avec .NET MAUI, disponible dans la .documentation .NET ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

Le développement d’applications client-serveur a conduit à mettre l’accent sur la création d’applications hiérarchisées qui utilisent des technologies spécifiques à chaque niveau. Les applications de ce genre sont souvent qualifiées de monolithiques et sont packagées sur du matériel ayant fait l’objet d’une mise à l’échelle préalable pour les pics de charge. Les principaux inconvénients de cette approche de développement sont le couplage étroit entre les composants de chaque niveau, le fait que les composants individuels ne peuvent pas être facilement mis à l’échelle et le coût des tests. Une simple mise à jour peut avoir des effets imprévus sur le reste du niveau. Ainsi, si vous apportez un changement à un composant d’application, vous devez retester et redéployer son niveau tout entier.
À l’ère du cloud, il est particulièrement important de se rendre compte de la difficulté que représente la mise à l’échelle de composants individuels. Une application monolithique contient des fonctionnalités spécifiques à un domaine et est généralement divisée en couches fonctionnelles telles que le front-end, la logique métier et le stockage de données. L’image ci-dessous montre qu’une application monolithique est mise à l’échelle via le clonage de l’intégralité de l’application sur plusieurs machines.
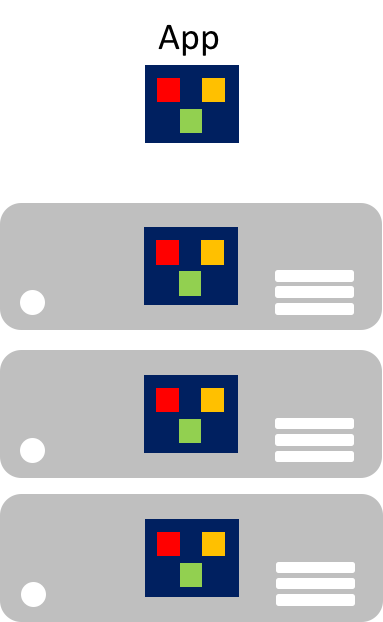
Microservices
Les microservices offrent une autre approche du développement et du déploiement d’applications, une approche adaptée aux impératifs d’agilité, de mise à l’échelle et de fiabilité des applications cloud modernes. Une application de microservices est divisée en composants indépendants qui fonctionnent ensemble pour fournir les fonctionnalités globales de l’application. Le terme microservice souligne le fait que les applications doivent être composées de services suffisamment petits pour répondre à des préoccupations particulières. Ainsi, chaque microservice implémente une seule fonction. De plus, chaque microservice a des contrats bien définis grâce auxquels les autres microservices communiquent et partagent des données. Parmi les exemples typiques de microservices, citons les paniers d’achat, la gestion des stocks, les sous-systèmes d’achat et la gestion des paiements.
Les microservices peuvent être mis à l’échelle de façon indépendante par opposition aux applications monolithiques géantes qui se mettent à l’échelle ensemble. Cela signifie qu’une zone fonctionnelle spécifique qui nécessite plus de puissance de traitement ou de bande passante réseau pour prendre en charge la demande peut être mise à l’échelle sans qu’il soit nécessaire d’effectuer un scale-out inutile d’autres zones de l’application. L’image ci-dessous illustre cette approche. Les microservices sont déployés et mis à l’échelle indépendamment, ce qui entraîne la création d’instances de services sur les machines.
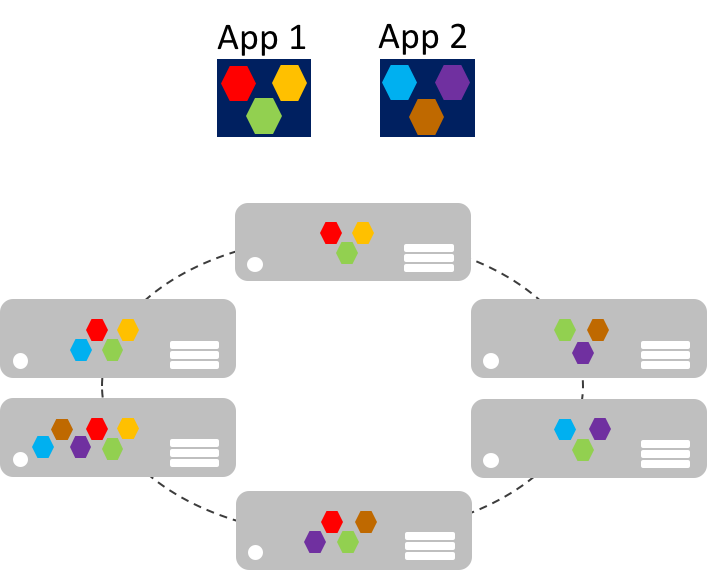
Le scale-out des microservices peut être quasiment instantané, ce qui permet à une application de s’adapter aux changements de charge. Par exemple, si vous devez choisir un seul microservice dans la fonctionnalité web d’une application, il peut s’agir de celui qui doit faire l’objet d’un scale-out pour gérer le trafic entrant supplémentaire.
Le modèle classique de scalabilité des applications consiste à disposer d’un niveau sans état, à charge équilibrée, avec un magasin de données externe partagé pour stocker les données persistantes. Les microservices avec état gèrent leurs propres données persistantes, et les stockent généralement localement sur les serveurs où ils sont placés, pour éviter la surcharge liée à l’accès réseau et la complexité des opérations interservices. Cela permet de traiter les données le plus rapidement possible, et d’éviter les systèmes de mise en cache. De plus, les microservices avec état scalables partitionnent généralement les données entre leurs instances, pour gérer la taille et le débit de transfert des données au-delà de la limite prise en charge par un seul serveur.
Les microservices prennent également en charge les mises à jour indépendantes. Ce couplage faible entre les microservices permet une évolution rapide et fiable des applications. Leur nature indépendante et distribuée facilite les mises à jour propagées, où seul un sous-ensemble d’instances d’un seul microservice est mis à jour à un moment donné. Ainsi, si un problème est détecté, une mise à jour boguée peut être restaurée à son état antérieur, avant que toutes les instances ne soient mises à jour à partir du code ou de la configuration problématique. De même, les microservices utilisent généralement le versioning de schéma, ce qui permet aux clients d’accéder à une version cohérente quand les mises à jour sont appliquées, quelle que soit l’instance de microservice avec laquelle la communication a lieu.
Ainsi, les applications de microservices présentent de nombreux avantages par rapport aux applications monolithiques :
- Chaque microservice est relativement petit, facile à gérer et à faire évoluer.
- Chaque microservice peut être développé et déployé indépendamment des autres services.
- Chaque microservice peut faire l’objet d’un scale-out indépendant. Par exemple, un service de catalogue ou un service de panier d’achat peut faire l’objet d’un scale-out supérieur à celui d’un service de commande. Ainsi, l’infrastructure résultante consomme plus efficacement les ressources durant le scale-out.
- Chaque microservice isole les problèmes. Par exemple, s’il existe un problème dans un service, il impacte uniquement ce service. Les autres services peuvent continuer à gérer les requêtes.
- Chaque microservice peut utiliser les dernières technologies. Dans la mesure où les microservices sont autonomes et s’exécutent côte à côte, vous pouvez vous servir des dernières technologies et des frameworks les plus récents, au lieu de devoir employer un ancien framework susceptible d’être utilisé par une application monolithique.
Toutefois, une solution basée sur des microservices présente également des inconvénients potentiels :
- Le choix du partitionnement d’une application en microservices peut être un défi, car chaque microservice doit être complètement autonome, de bout en bout, notamment au niveau de la responsabilité de ses sources de données.
- Les développeurs doivent implémenter une communication interservice, ce qui accroît la complexité et la latence de l’application.
- Les transactions atomiques entre plusieurs microservices ne sont généralement pas possibles. Les besoins métier doivent donc adopter une cohérence finale entre les microservices.
- En production, il existe une complexité opérationnelle liée au déploiement et à la gestion d’un système résultant d’un compromis entre de nombreux services indépendants.
- La communication directe de client à microservice peut compliquer la refactorisation des contrats des microservices. Par exemple, avec le temps, la façon dont le système est partitionné en services peut être amenée à changer. Un seul service peut être divisé en deux services ou plus, et deux services peuvent fusionner. Quand les clients communiquent directement avec les microservices, ce travail de refactorisation peut rompre la compatibilité avec les applications clientes.
Mise en conteneur
La conteneurisation est une approche du développement logiciel dans laquelle une application et son ensemble versionné de dépendances ainsi que sa configuration d’environnement abstraite sous forme de fichiers manifeste de déploiement, sont packagés ensemble en tant qu’image conteneur, testés en tant qu’unité et déployés sur un système d’exploitation hôte.
Un conteneur est un environnement d’exploitation portable et isolé, dont les ressources sont contrôlées, où une application peut s’exécuter sans toucher aux ressources des autres conteneurs ou de l’hôte. Ainsi, un conteneur ressemble à un ordinateur physique ou à une machine virtuelle qui vient tout juste d’être installée.
Il existe de nombreuses similitudes entre les conteneurs et les machines virtuelles, comme illustré ci-dessous.
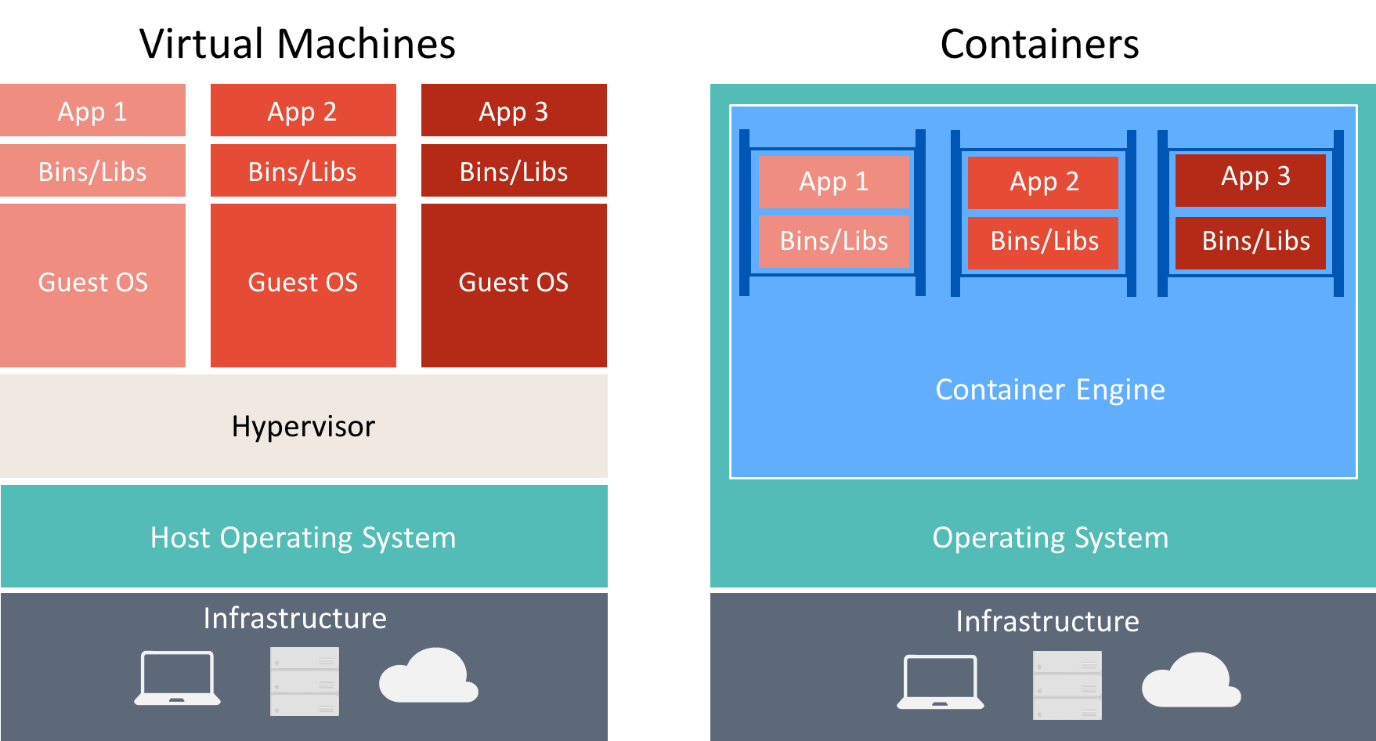
Un conteneur exécute un système d’exploitation, comporte un système de fichiers et est accessible en réseau, comme s’il s’agissait d’une machine physique ou virtuelle. Toutefois, la technologie et les concepts utilisés par les conteneurs sont très différents de ceux des machines virtuelles. Les machines virtuelles incluent les applications, les dépendances nécessaires et un système d’exploitation invité complet. Les conteneurs incluent l’application et ses dépendances, mais partagent le système d’exploitation avec d’autres conteneurs. Ils s’exécutent en tant que processus isolés sur le système d’exploitation hôte (à l’exception des conteneurs Hyper-V qui s’exécutent à l’intérieur d’une machine virtuelle spéciale par conteneur). Ainsi, les conteneurs partagent des ressources et nécessitent généralement moins de ressources que les machines virtuelles.
Une approche de développement et de déploiement orientée conteneur présente l’avantage d’éliminer la plupart des erreurs liées à des configurations d’environnement incohérentes et aux problèmes qui les accompagnent. De plus, les conteneurs permettent un scale-up rapide des applications en facilitant l’instanciation de nouveaux conteneurs selon les besoins.
Les concepts clés liés à la création et à l’utilisation de conteneurs sont les suivants :
| Concept | Description |
|---|---|
| Hôte de conteneur | Machine physique ou virtuelle configurée pour héberger les conteneurs. L’hôte de conteneur exécute un ou plusieurs conteneurs. |
| Image conteneur | Une image se compose d’une union de systèmes de fichiers en couches, empilés les uns sur les autres, et constitue la base d’un conteneur. Une image n’a pas d’état et ne change jamais quand elle est déployée sur différents environnements. |
| Conteneur | Un conteneur est une instance d’exécution d’une image. |
| Image de système d’exploitation de conteneur | Les conteneurs sont déployés à partir d’images. L’image du système d’exploitation du conteneur est la première couche d’un nombre potentiellement important de couches d’images qui composent un conteneur. Un système d’exploitation de conteneur est immuable, et ne peut pas être modifié. |
| Dépôt de conteneurs | Chaque fois qu’une image conteneur est créée, l’image et ses dépendances sont stockées dans un dépôt local. Ces images peuvent être réutilisées plusieurs fois sur l’hôte de conteneur. Les images conteneur peuvent également être stockées dans un registre public ou privé, par exemple Docker Hub, pour pouvoir être utilisées sur différents hôtes de conteneur. |
Les entreprises adoptent de plus en plus les conteneurs pour implémenter des applications basées sur les microservices. Docker est devenu l’implémentation de conteneur standard adoptée par la plupart des plateformes logicielles et des fournisseurs cloud.
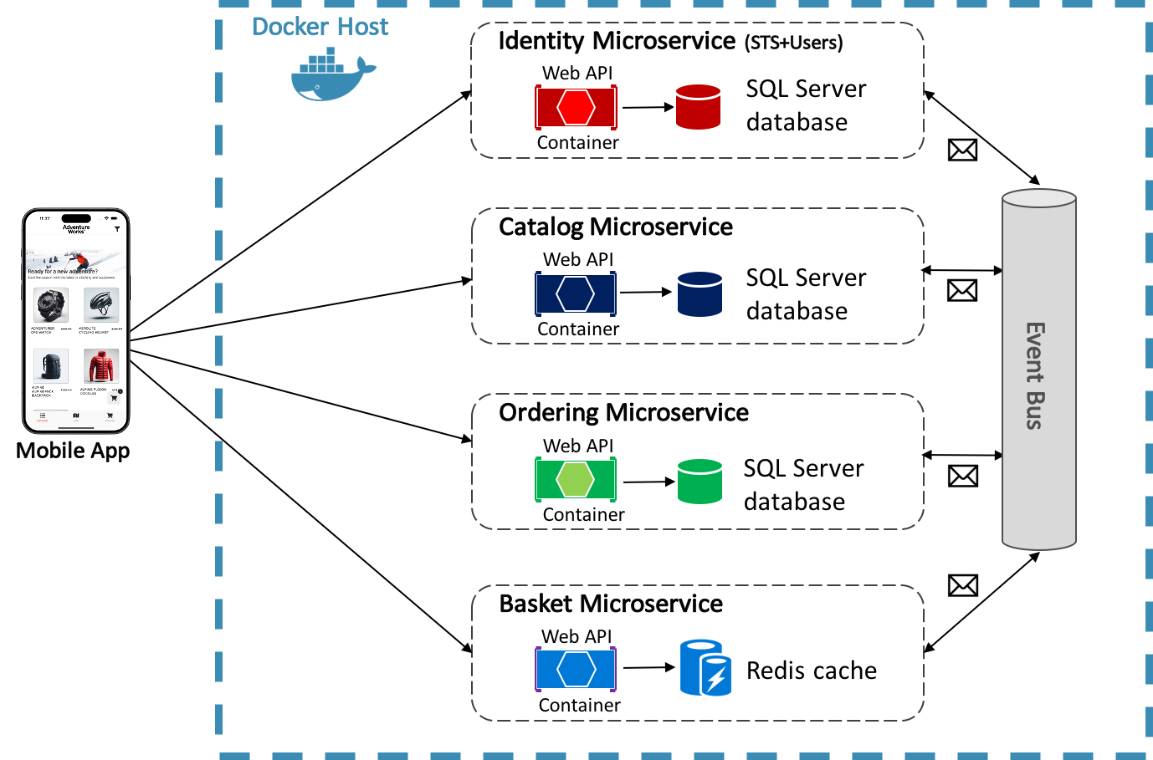
L’application de référence eShop utilise Docker pour héberger quatre microservices back-end conteneurisés, comme le montre le diagramme ci-dessous.
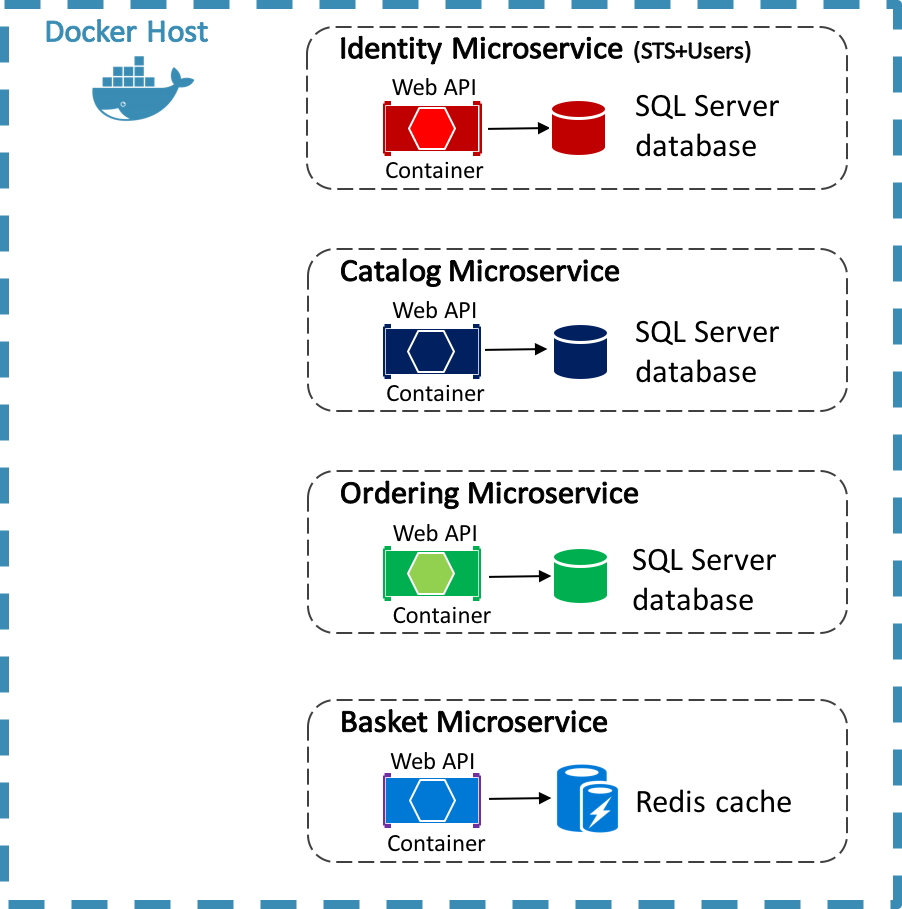
L’architecture des services back-end dans l’application de référence est décomposée en plusieurs sous-systèmes autonomes sous la forme de microservices et de conteneurs qui collaborent entre eux. Chaque microservice fournit une seule zone de fonctionnalités : un service d’identité, un service de catalogue, un service de commande et un service de panier.
Chaque microservice a sa propre base de données, ce qui lui permet d’être complètement découplé des autres microservices. Le cas échéant, la cohérence entre les bases de données des différents microservices est assurée à l’aide d’événements au niveau de l’application. Pour plus d’informations, consultez Communication entre les microservices.
Communication entre le client et les microservices
L’application multiplateforme eShop communique avec les microservices back-end conteneurisés en utilisant une communication directe entre le client et les microservices, comme indiqué ci-dessous.
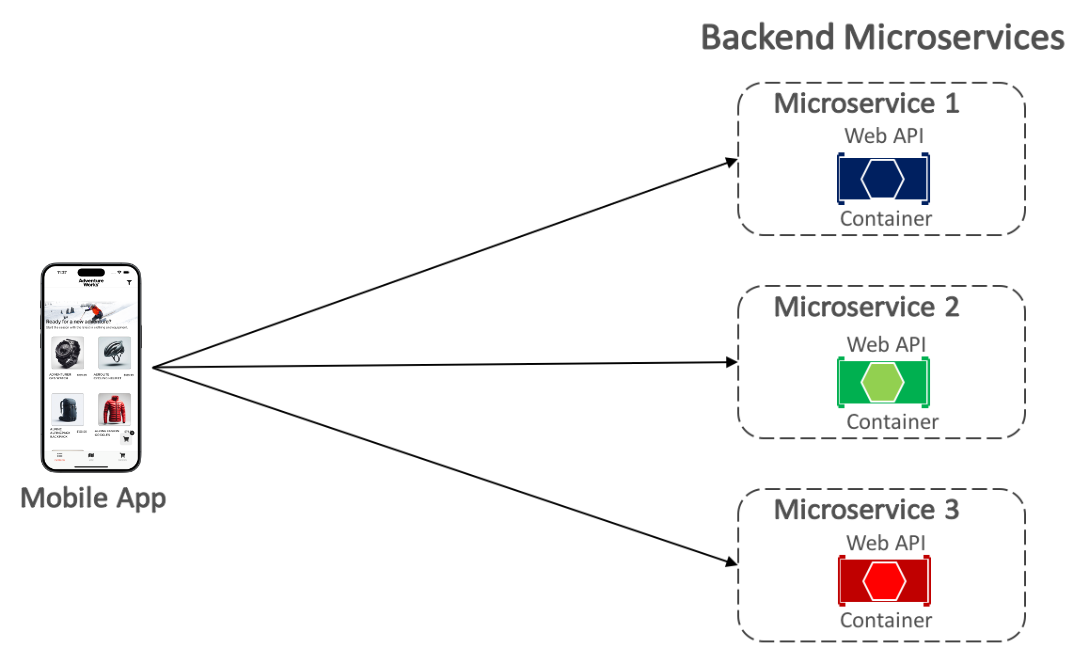
Grâce à la communication directe entre le client et les microservices, l’application multiplateforme envoie des requêtes à chaque microservice directement via son point de terminaison public, en utilisant un port TCP distinct par microservice. En production, le point de terminaison est généralement mappé à l’équilibreur de charge du microservice, qui répartit les requêtes entre les instances disponibles.
Conseil
Pensez à utiliser la communication par passerelle API.
La communication directe entre le client et les microservices peut présenter des inconvénients quand vous créez une application volumineuse et complexe, mais elle est plus qu’appropriée pour une petite application. Pensez à utiliser la communication par passerelle API quand vous concevez une application d’envergure basée sur des microservices se comptant par dizaines.
Communication entre microservices
Une application basée sur des microservices est un système distribué, qui s’exécute potentiellement sur plusieurs machines. Chaque instance de service est généralement un processus. Ainsi, les services doivent interagir à l’aide d’un protocole de communication interprocessus, par exemple HTTP, TCP, AMQP (Advanced Message Queuing Protocol) ou de protocoles binaires, selon la nature de chaque service.
Les deux approches courantes pour la communication de microservice à microservice sont la communication REST basée sur le protocole HTTP durant l’interrogation des données, et la messagerie asynchrone légère durant la communication des mises à jour entre plusieurs microservices.
La communication pilotée par les événements et basée sur la messagerie asynchrone est essentielle à la propagation des changements entre plusieurs microservices. Avec cette approche, un microservice publie un événement quand un événement important se produit, par exemple quand il met à jour une entité métier. D’autres microservices s’abonnent à ces événements. Quand un microservice reçoit ensuite un événement, il met à jour ses propres entités métier, ce qui peut entraîner la publication d’un plus grand nombre d’événements. Cette fonctionnalité de communication par publication-abonnement repose généralement sur un bus d’événements.
Un bus d’événements permet la communication par publication-abonnement entre les microservices sans que les composants ne soient explicitement informés de la présence de chacun d’entre eux, comme indiqué ci-dessous.
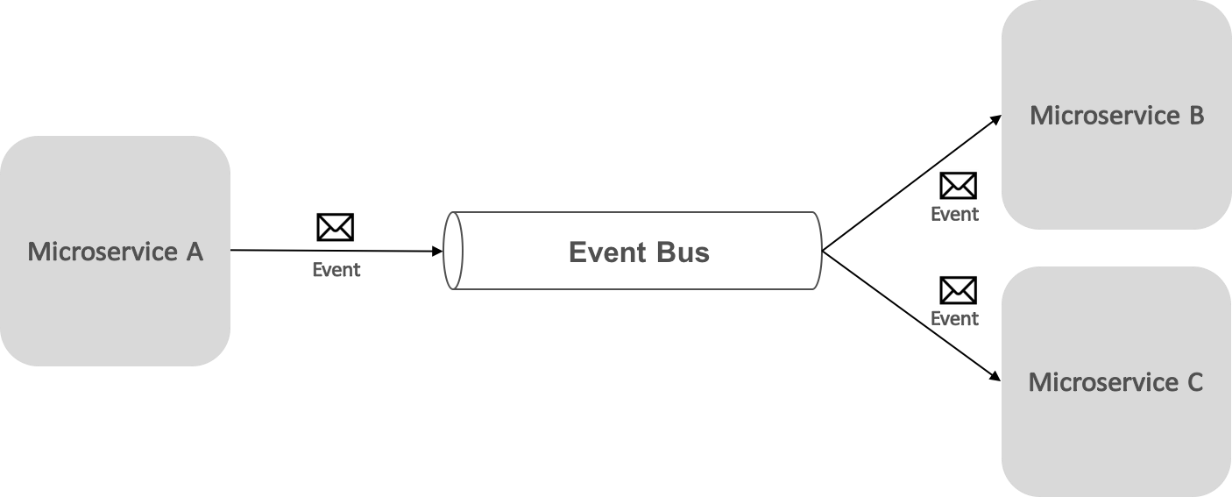
Du point de vue de l’application, le bus d’événements est simplement un canal de publication/d’abonnement exposé via une interface. Toutefois, la façon dont le bus d’événements est implémenté peut varier. Par exemple, une implémentation de bus d’événements peut utiliser RabbitMQ, Azure Service Bus ou d’autres bus de services tels que NServiceBus et MassTransit. Le diagramme ci-dessous montre l’utilisation d’un bus d’événements dans l’application de référence eShop.
Le bus d’événements eShop, implémenté à l’aide de RabbitMQ, fournit une fonctionnalité de publication/d’abonnement asynchrone de type un-à-plusieurs. Cela signifie qu’après la publication d’un événement, plusieurs abonnés peuvent écouter le même événement. Le diagramme ci-dessous illustre cette relation.
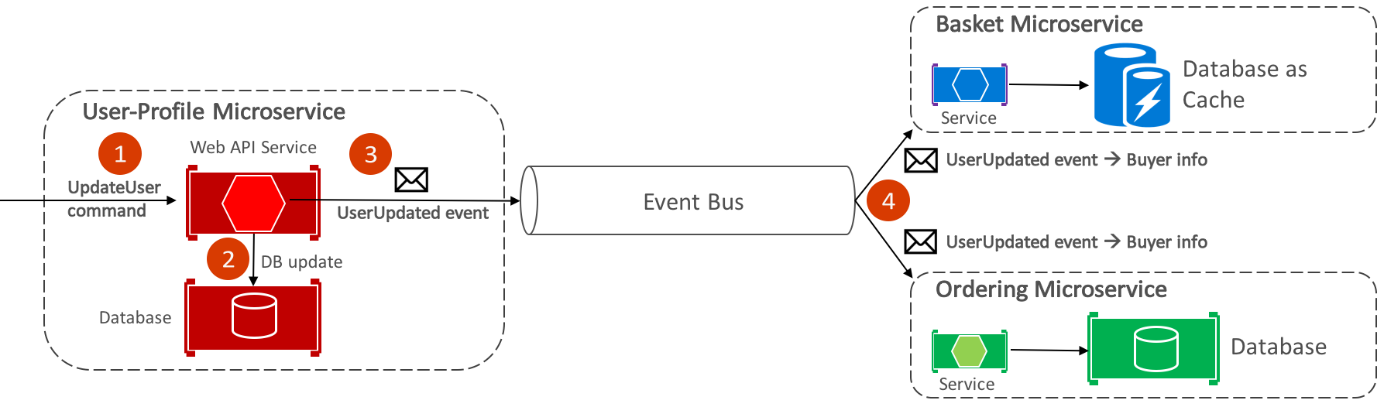
Cette approche de communication de type un-à-plusieurs utilise des événements pour implémenter des transactions métier qui couvrent plusieurs services, ce qui garantit ainsi une cohérence à terme entre les services. Une transaction cohérente à terme se compose d’une série d’étapes distribuées. Ainsi, quand le microservice de profil utilisateur reçoit la commande UpdateUser, il met à jour les détails de l’utilisateur dans sa base de données et publie l’événement UserUpdated sur le bus d’événements. Le microservice de panier et le microservice de commande se sont abonnés pour recevoir cet événement et, en réponse, ont mis à jour les informations relatives à l’acheteur dans leurs bases de données respectives.
Résumé
Les microservices offrent une approche du développement et du déploiement d’applications adaptée aux impératifs d’agilité, de mise à l’échelle et de fiabilité des applications cloud modernes. L’un des principaux avantages des microservices est qu’ils peuvent faire l’objet d’un scale-out indépendant. En d’autres termes, vous pouvez mettre à l’échelle une zone fonctionnelle spécifique nécessitant davantage de puissance de traitement ou une bande passante réseau plus importante pour prendre en charge la demande, sans mettre à l’échelle inutilement les zones de l’application qui ne sont pas soumises à une demande accrue.
Un conteneur est un environnement d’exploitation portable et isolé, dont les ressources sont contrôlées, où une application peut s’exécuter sans toucher aux ressources des autres conteneurs ou de l’hôte. Les entreprises adoptent de plus en plus les conteneurs pour implémenter des applications basées sur les microservices. Docker est devenu l’implémentation de conteneur standard adoptée par la plupart des plateformes logicielles et des fournisseurs cloud.