Accès aux données distantes
Conseil
Ce contenu est un extrait du livre électronique Modèles d’application d’entreprise avec .NET MAUI, disponible dans la .documentation .NET ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

De nombreuses solutions web modernes utilisent des services web, hébergés par des serveurs web, pour fournir des fonctionnalités aux applications clientes distantes. Les opérations exposées par un service web constituent une API web.
Les applications clientes doivent pouvoir utiliser l’API web sans savoir comment les données ou les opérations exposées par l’API sont implémentées. Pour cela, l’API doit respecter les standards courants qui permettent à une application cliente et à un service web de s’accorder sur les formats de données à utiliser ainsi que sur la structure des données échangées entre les applications clientes et le service web.
Présentation du Representational State Transfer
REST (Representational State Transfer) est un style d’architecture qui permet de créer des systèmes distribués basés sur l’hypermédia. L’un des principaux avantages du modèle REST est qu’il est basé sur des standards ouverts, et qu’il ne lie pas l’implémentation du modèle ou les applications clientes qui y accèdent à une implémentation spécifique. Ainsi, un service web REST peut être implémenté à l’aide de Microsoft ASP.NET Core, et les applications clientes peuvent être développées à l’aide de n’importe quel langage et ensemble d’outils pouvant générer des requêtes HTTP et analyser des réponses HTTP.
Le modèle REST utilise un schéma de navigation pour représenter les objets et les services sur un réseau, appelés ressources. Les systèmes qui implémentent REST utilisent généralement le protocole HTTP pour transmettre les requêtes d’accès à ces ressources. Dans ces systèmes, une application cliente envoie une requête sous la forme d’un URI qui identifie une ressource, et d’une méthode HTTP (par exemple GET, POST, PUT ou DELETE) qui indique l’opération à effectuer sur cette ressource. Le corps de la requête HTTP contient toutes les données nécessaires à l’exécution de l’opération.
Notes
REST définit un modèle de requête sans état. Ainsi, les requêtes HTTP doivent être indépendantes et peuvent s’exécuter dans n’importe quel ordre.
La réponse d’une requête REST utilise des codes d’état HTTP standard. Par exemple, une requête qui retourne des données valides doit inclure le code de réponse HTTP 200 (OK), alors qu’une requête qui ne parvient pas à trouver ou à supprimer une ressource spécifique doit retourner une réponse qui inclut le code d’état HTTP 404 (Not Found).
Une API web RESTful expose un ensemble de ressources connectées et fournit les opérations de base qui permettent à une application de manipuler ces ressources et de naviguer facilement parmi celles-ci. Ainsi, les URI qui constituent une API web RESTful classique sont orientés vers les données qu’elle expose, et utilisent les fonctionnalités fournies par HTTP pour agir sur ces données.
Les données incluses par une application cliente dans une requête HTTP et les messages de réponse correspondants du serveur web peuvent être présentés dans divers formats, appelés types de média. Quand une application cliente envoie une requête qui retourne des données dans le corps d’un message, elle peut spécifier les types de contenu multimédia qu’elle peut gérer dans l’en-tête Accept de la requête. Si le serveur web prend en charge ce type de contenu multimédia, il peut retourner une réponse incluant l’en-tête Content-Type, qui spécifie le format des données dans le corps du message. L’application cliente doit ensuite analyser le message de réponse et interpréter les résultats dans le corps du message de manière appropriée.
Pour plus d’informations sur REST, consultez Conception d’API et Implémentation d’API sur Microsoft Docs.
Consommation d’API RESTful
L’application multiplateforme eShop utilise le modèle-vue-vue modèle (MVVM), et les éléments de modèle du modèle représentent les entités de domaine utilisées dans l’application. Les classes de contrôleur et de référentiel dans l’application de référence eShop acceptent et retournent un grand nombre de ces objets de modèle. Ainsi, ils sont utilisés en tant qu’objets de transfert de données (DTO) qui contiennent toutes les données passées entre l’application et les microservices conteneurisés. Le principal avantage de l’utilisation des objets DTO pour passer des données et recevoir des données d’un service web est le suivant : en transmettant davantage de données en un seul appel distant, l’application peut réduire le nombre d’appels distants à effectuer.
Exécution de requêtes web
L’application multiplateforme eShop utilise la classe HttpClient pour effectuer des requêtes sur HTTP, avec JSON utilisé comme type de média. Cette classe fournit des fonctionnalités permettant d’envoyer de manière asynchrone des requêtes HTTP à une ressource identifiée par un URI, et de recevoir des réponses HTTP à partir de celle-ci. La classe HttpResponseMessage représente un message de réponse HTTP reçu de la part d’une API REST après l’exécution d’une requête HTTP. Il contient des informations sur la réponse, notamment le code d’état, les en-têtes et le corps du message. La classe HttpContent représente le corps HTTP et les en-têtes de contenu, par exemple Content-Type et Content-Encoding. Le contenu peut être lu à l’aide de l’une des méthodes ReadAs, par exemple ReadAsStringAsync et ReadAsByteArrayAsync, en fonction du format des données.
Exécution d’une requête GET
La classe CatalogService permet de gérer le processus d’extraction de données à partir du microservice de catalogue. Dans la méthode RegisterViewModels de la classe MauiProgram, la classe CatalogService est inscrite en tant que mappage de type par rapport au type ICatalogService auprès du conteneur d’injection de dépendances. Puis, quand une instance de la classe CatalogViewModel est créée, son constructeur accepte un ICatalogService type, que le conteneur d’injection de dépendances résout en retournant une instance de la classe CatalogService. Pour plus d’informations sur l’injection de dépendances, consultez Injection de dépendances.
L’image ci-dessous montre l’interaction des classes qui lisent les données de catalogue à partir du microservice de catalogue pour qu’elles soient affichées par CatalogView.
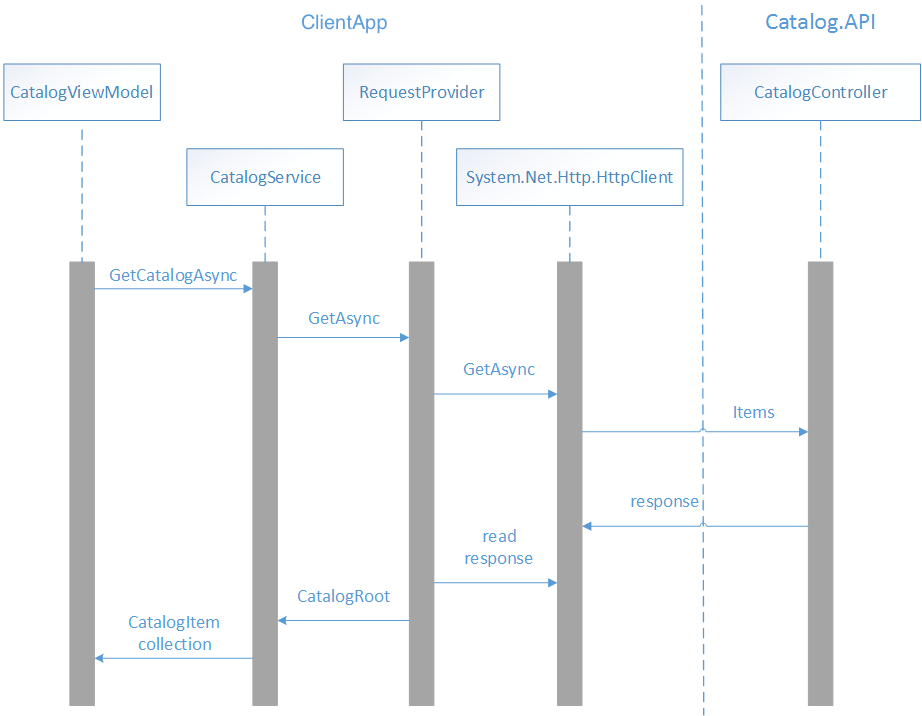
En cas de navigation vers CatalogView, la méthode OnInitialize de la classe CatalogViewModel est appelée. Cette méthode extrait les données de catalogue à partir du microservice de catalogue, comme le montre l’exemple de code suivant :
public override async Task InitializeAsync()
{
Products = await _productsService.GetCatalogAsync();
}
Cette méthode appelle la méthode GetCatalogAsync de l’instance de CatalogService, qui a été injectée dans CatalogViewModel par le conteneur d’injection de dépendances. L’exemple de code suivant montre la méthode GetCatalogAsync :
public async Task<ObservableCollection<CatalogItem>> GetCatalogAsync()
{
UriBuilder builder = new UriBuilder(GlobalSetting.Instance.CatalogEndpoint);
builder.Path = "api/v1/catalog/items";
string uri = builder.ToString();
CatalogRoot? catalog = await _requestProvider.GetAsync<CatalogRoot>(uri);
return catalog?.Data;
}
Cette méthode crée l’URI qui identifie la ressource à laquelle la requête est envoyée, et utilise la classe RequestProvider pour appeler la méthode HTTP GET sur la ressource, avant de retourner les résultats à CatalogViewModel. La classe RequestProvider contient une fonctionnalité qui envoie une requête sous la forme d’un URI qui identifie une ressource, d’une méthode HTTP qui indique l’opération à effectuer sur cette ressource et d’un corps qui contient les données nécessaires à l’exécution de l’opération. Pour plus d’informations sur la façon dont la classe RequestProvider est injectée dans la classe CatalogService, consultez Injection de dépendances.
L’exemple de code suivant montre la méthode GetAsync dans la classe RequestProvider :
public async Task<TResult> GetAsync<TResult>(string uri, string token = "")
{
HttpClient httpClient = GetOrCreateHttpClient(token);
HttpResponseMessage response = await httpClient.GetAsync(uri);
await HandleResponse(response);
TResult result = await response.Content.ReadFromJsonAsync<TResult>();
return result;
}
Cette méthode appelle la méthode GetOrCreateHttpClient, qui retourne une instance de la classe HttpClient avec les en-têtes appropriés définis. Elle envoie ensuite une requête GET asynchrone à la ressource identifiée par l’URI, la réponse étant stockée dans l’instance de HttpResponseMessage. La méthode HandleResponse est ensuite appelée, ce qui lève une exception si la réponse n’inclut pas de code d’état HTTP de réussite. La réponse est ensuite lue sous forme de chaîne, convertie du format JSON en objet CatalogRoot et retournée à CatalogService.
La méthode GetOrCreateHttpClient est illustrée dans l’exemple de code suivant :
private readonly Lazy<HttpClient> _httpClient =
new Lazy<HttpClient>(
() =>
{
var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json"));
return httpClient;
},
LazyThreadSafetyMode.ExecutionAndPublication);
private HttpClient GetOrCreateHttpClient(string token = "")
{
var httpClient = _httpClient.Value;
if (!string.IsNullOrEmpty(token))
{
httpClient.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", token);
}
else
{
httpClient.DefaultRequestHeaders.Authorization = null;
}
return httpClient;
}
Cette méthode crée une instance ou récupère une instance en cache de la classe HttpClient, puis affecte la valeur application/json à l’en-tête Accept des requêtes effectuées par l’instance de HttpClient, ce qui indique qu’elle attend le contenu des réponses au format JSON. Ensuite, si un jeton d’accès est passé en tant qu’argument de la méthode GetOrCreateHttpClient, il est ajouté à l’en-tête Authorization des requêtes effectuées par l’instance de HttpClient, en étant précédé de la chaîne Bearer. Pour plus d’informations sur l’autorisation, consultez Autorisation.
Conseil
Il est fortement recommandé de mettre en cache et de réutiliser les instances de HttpClient pour améliorer les performances de l’application. La création d’un HttpClient pour chaque opération peut entraîner un problème de pénurie de sockets. Pour plus d’informations, consultez Instanciation de HttpClient dans le Centre des développeurs Microsoft.
Quand la méthode GetAsync de la classe RequestProvider appelle HttpClient.GetAsync, la méthode Items de la classe CatalogController du projet Catalog.API est appelée, comme le montre l’exemple de code suivant :
[HttpGet]
[Route("[action]")]
public async Task<IActionResult> Items(
[FromQuery]int pageSize = 10, [FromQuery]int pageIndex = 0)
{
var totalItems = await _catalogContext.CatalogItems
.LongCountAsync();
var itemsOnPage = await _catalogContext.CatalogItems
.OrderBy(c => c.Name)
.Skip(pageSize * pageIndex)
.Take(pageSize)
.ToListAsync();
itemsOnPage = ComposePicUri(itemsOnPage);
var model = new PaginatedItemsViewModel<CatalogItem>(
pageIndex, pageSize, totalItems, itemsOnPage);
return Ok(model);
}
Cette méthode extrait les données de catalogue à partir de la base de données SQL à l’aide d’EntityFramework, puis les retourne sous forme de message de réponse comprenant un code d’état HTTP de réussite et une collection d’instances de CatalogItem au format JSON.
Exécution d’une requête POST
La classe BasketService permet de gérer le processus d’extraction de données et de mise à jour avec le microservice de panier. Dans la méthode RegisterAppServices de la classe MauiProgram, la classe BasketService est inscrite en tant que mappage de type par rapport au type IBasketService auprès du conteneur d’injection de dépendances. Puis, quand une instance de la classe BasketViewModel est créée, son constructeur accepte un type IBasketService, que le conteneur d’injection de dépendances résout en retournant une instance de la classe BasketService. Pour plus d’informations sur l’injection de dépendances, consultez Injection de dépendances.
L’image ci-dessous montre l’interaction des classes qui envoient les données de panier affichées par BasketView au microservice de panier.
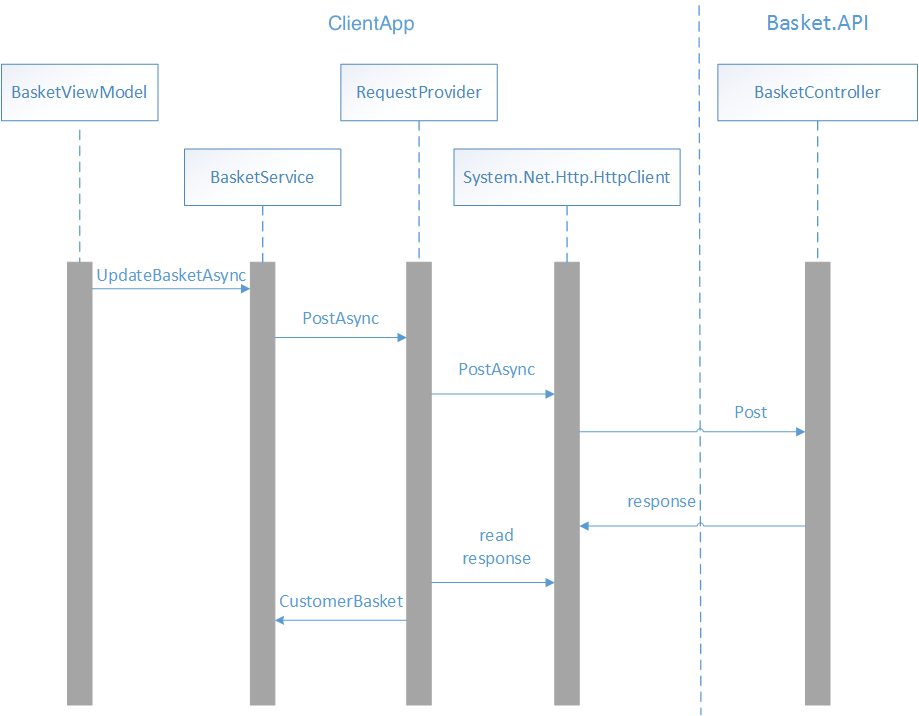
Quand un article est ajouté au panier d’achat, la méthode ReCalculateTotalAsync de la classe BasketViewModel est appelée. Cette méthode met à jour la valeur totale des éléments du panier, puis envoie les données de panier au microservice de panier, comme le montre l’exemple de code suivant :
private async Task ReCalculateTotalAsync()
{
// Omitted for brevity...
await _basketService.UpdateBasketAsync(
new CustomerBasket
{
BuyerId = userInfo.UserId,
Items = BasketItems.ToList()
},
authToken);
}
Cette méthode appelle la méthode UpdateBasketAsync de l’instance de BasketService, qui a été injectée dans BasketViewModel par le conteneur d’injection de dépendances. La méthode suivante illustre l’utilisation de la méthode UpdateBasketAsync :
public async Task<CustomerBasket> UpdateBasketAsync(
CustomerBasket customerBasket, string token)
{
UriBuilder builder = new UriBuilder(GlobalSetting.Instance.BasketEndpoint);
string uri = builder.ToString();
var result = await _requestProvider.PostAsync(uri, customerBasket, token);
return result;
}
Cette méthode crée l’URI qui identifie la ressource à laquelle la requête est envoyée, et utilise la classe RequestProvider pour appeler la méthode HTTP POST sur la ressource, avant de retourner les résultats à BasketViewModel. Notez qu’un jeton d’accès, obtenu à partir de IdentityServer durant le processus d’authentification, est nécessaire pour autoriser les requêtes adressées au microservice de panier. Pour plus d’informations sur l’autorisation, consultez Autorisation.
L’exemple de code suivant montre le fonctionnement de l’une des méthodes PostAsync dans la classe RequestProvider :
public async Task<TResult> PostAsync<TResult>(
string uri, TResult data, string token = "", string header = "")
{
HttpClient httpClient = GetOrCreateHttpClient(token);
var content = new StringContent(JsonSerializer.Serialize(data));
content.Headers.ContentType = new MediaTypeHeaderValue("application/json");
HttpResponseMessage response = await httpClient.PostAsync(uri, content);
await HandleResponse(response);
TResult result = await response.Content.ReadFromJsonAsync<TResult>();
return result;
}
Cette méthode appelle la méthode GetOrCreateHttpClient, qui retourne une instance de la classe HttpClient avec les en-têtes appropriés définis. Elle envoie ensuite une requête POST asynchrone à la ressource identifiée par l’URI, les données de panier sérialisées étant envoyées au format JSON et la réponse étant stockée dans l’instance de HttpResponseMessage. La méthode HandleResponse est ensuite appelée, ce qui lève une exception si la réponse n’inclut pas de code d’état HTTP de réussite. La réponse est ensuite lue sous forme de chaîne, convertie du format JSON en objet CustomerBasket et retournée à BasketService. Pour plus d’informations sur la méthode GetOrCreateHttpClient, consultez Exécution d’une requête GET.
Quand la méthode PostAsync de la classe RequestProvider appelle HttpClient.PostAsync, la méthode Post de la classe BasketController du projet Basket.API est appelée, comme le montre l’exemple de code suivant :
[HttpPost]
public async Task<IActionResult> Post([FromBody] CustomerBasket value)
{
var basket = await _repository.UpdateBasketAsync(value);
return Ok(basket);
}
Cette méthode utilise une instance de la classe RedisBasketRepository pour conserver les données de panier dans le cache Redis. Elle les retourne sous la forme d’un message de réponse incluant un code d’état HTTP de réussite ainsi qu’une instance de CustomerBasket au format JSON.
Exécution d’une requête DELETE
L’image ci-dessous montre les interactions des classes qui suppriment les données de panier du microservice de panier pour CheckoutView.
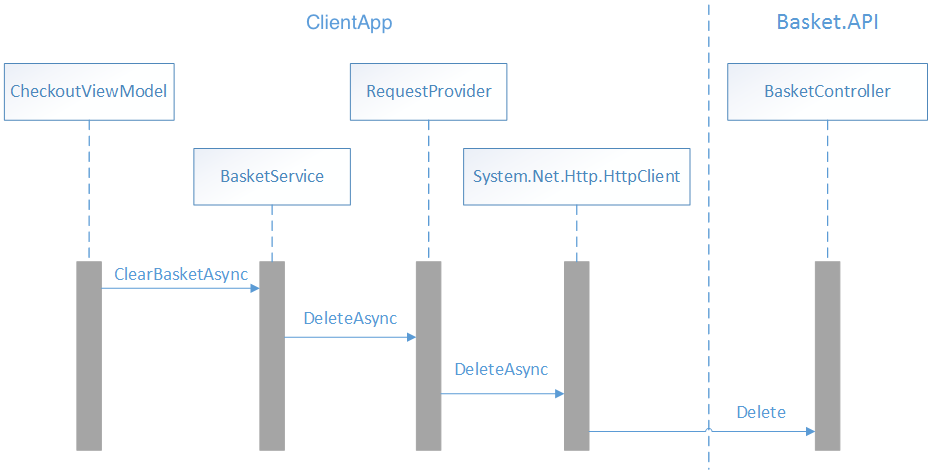
Quand le processus de paiement est appelé, la méthode CheckoutAsync de la classe CheckoutViewModel est appelée également. Cette méthode crée une commande, avant de vider le panier d’achat, comme le montre l’exemple de code suivant :
private async Task CheckoutAsync()
{
// Omitted for brevity...
await _basketService.ClearBasketAsync(
_shippingAddress.Id.ToString(), authToken);
}
Cette méthode appelle la méthode ClearBasketAsync de l’instance de BasketService, qui a été injectée dans CheckoutViewModel par le conteneur d’injection de dépendances. La méthode suivante illustre l’utilisation de la méthode ClearBasketAsync :
public async Task ClearBasketAsync(string guidUser, string token)
{
UriBuilder builder = new(GlobalSetting.Instance.BasketEndpoint);
builder.Path = guidUser;
string uri = builder.ToString();
await _requestProvider.DeleteAsync(uri, token);
}
Cette méthode crée l’URI qui identifie la ressource à laquelle la requête est envoyée, et utilise la classe RequestProvider pour appeler la méthode HTTP DELETE sur la ressource. Notez qu’un jeton d’accès, obtenu à partir de IdentityServer durant le processus d’authentification, est nécessaire pour autoriser les requêtes adressées au microservice de panier. Pour plus d’informations sur l’autorisation, consultez Autorisation.
L’exemple de code suivant montre la méthode DeleteAsync dans la classe RequestProvider :
public async Task DeleteAsync(string uri, string token = "")
{
HttpClient httpClient = GetOrCreateHttpClient(token);
await httpClient.DeleteAsync(uri);
}
Cette méthode appelle la méthode GetOrCreateHttpClient, qui retourne une instance de la classe HttpClient avec les en-têtes appropriés définis. Elle envoie ensuite une requête DELETE asynchrone à la ressource identifiée par l’URI. Pour plus d’informations sur la méthode GetOrCreateHttpClient, consultez Exécution d’une requête GET.
Quand la méthode DeleteAsync de la classe RequestProvider appelle HttpClient.DeleteAsync, la méthode Delete de la classe BasketController du projet Basket.API est appelée, comme le montre l’exemple de code suivant :
[HttpDelete("{id}")]
public void Delete(string id) =>
_repository.DeleteBasketAsync(id);
Cette méthode utilise une instance de la classe RedisBasketRepository pour supprimer les données de panier du cache Redis.
Mise en cache de données
Vous pouvez améliorer les performances d’une application en mettant en cache les données fréquemment utilisées sur un espace de stockage rapide situé à proximité de l’application. Si l’espace de stockage rapide est situé plus près de l’application que la source d’origine, la mise en cache peut considérablement améliorer les temps de réponse au moment de l’extraction des données.
La forme la plus courante de mise en cache est la mise en cache en lecture directe, où une application extrait les données en référençant le cache. Si les données ne se trouvent pas dans le cache, elles sont récupérées dans la banque de données et ajoutées au cache. Les applications peuvent implémenter la mise en cache en lecture directe avec le modèle de type cache-aside. Ce modèle détermine si l’élément se trouve dans le cache. Si l’élément ne se trouve pas dans le cache, il est lu à partir du magasin de données et est ajouté au cache. Pour plus d’informations, consultez les détails relatifs au modèle de type cache-aside sur Microsoft Docs.
Conseil
Mettez en cache les données qui sont lues fréquemment et qui changent rarement.
Ces données peuvent être ajoutées au cache à la demande la première fois qu’elles sont extraites par une application. Cela signifie que l’application n’a besoin d’extraire les données du magasin de données qu’une seule fois, et que les accès suivants peuvent être traités à l’aide du cache.
Les applications distribuées, telles que l’application de référence eShop, doivent fournir les deux caches suivants :
- Un cache partagé, accessible à plusieurs processus ou machines.
- Un cache privé, où les données sont conservées localement sur l’appareil qui exécute l’application.
L’application multiplateforme eShop utilise un cache privé, où les données sont conservées localement sur l’appareil exécutant une instance de l’application.
Conseil
Considérez le cache comme un magasin de données temporaire qui peut disparaître à tout moment.
Vérifiez que les données sont conservées dans le magasin de données d’origine ainsi que dans le cache. Les risques de perte de données sont alors réduits au minimum si le cache cesse d’être disponible.
Gestion de l’expiration des données
Il n’est pas pratique de compter sur le fait que les données en cache soient toujours cohérentes par rapport aux données d’origine. Les données du magasin de données d’origine peuvent changer après leur mise en cache, ce qui rend les données en cache obsolètes. Les applications doivent donc implémenter une stratégie pour garantir l’actualisation la plus complète possible des données contenues dans le cache ainsi que pour détecter et gérer les situations où les données du cache sont périmées. La plupart des mécanismes de mise en cache permettent de configurer le cache pour faire expirer les données, et ainsi réduire la période pendant laquelle les données peuvent être obsolètes.
Conseil
Définissez un délai d’expiration par défaut au moment de la configuration d’un cache.
De nombreux caches implémentent l’expiration, ce qui permet de rendre les données non valides et de les supprimer du cache si elles ne sont pas utilisées pendant une période spécifique. Toutefois, soyez prudent au moment de choisir la période d’expiration. Si elle est trop courte, les données expirent trop rapidement et les avantages de la mise en cache s’en trouvent réduits. Si elle est trop longue, les données risquent d’être périmées. Le délai d’expiration doit donc correspondre au modèle d’accès des applications qui utilisent les données.
Quand les données en cache expirent, elles doivent être supprimées du cache. L’application doit ensuite extraire les données du magasin de données d’origine pour les replacer dans le cache.
Il est également possible qu’un cache se remplisse si les données sont autorisées à y résider trop longtemps. Ainsi, des demandes d’ajout de nouveaux éléments au cache sont parfois nécessaires pour supprimer certains éléments dans le cadre d’un processus appelé éviction. Le service caching évince généralement les données sur la base de leur utilisation la moins récente. Toutefois, il existe d’autres stratégies d’éviction, notamment la stratégie basée sur l’utilisation la plus récente et la stratégie du premier entré, premier sorti. Pour plus d’informations, consultez les conseils d’aide relatifs à la mise en cache sur Microsoft Docs.
Mise en cache des images
L’application multiplateforme eShop consomme des images de produit distantes qui bénéficient d’être mises en cache. Ces images sont affichées par le contrôle Image. Le contrôle Image .NET MAUI prend en charge la mise en cache des images téléchargées, dont la mise en cache est activée par défaut. Il stocke l’image localement pendant 24 heures. De plus, le délai d’expiration peut être configuré avec la propriété CacheValidity. Pour plus d’informations, consultez Mise en cache des images téléchargées dans le Centre des développeurs Microsoft.
Augmentation de la résilience
Toutes les applications qui communiquent avec des ressources et des services distants doivent être sensibles aux erreurs temporaires. Les erreurs temporaires incluent la perte momentanée de la connectivité réseau aux services, l’indisponibilité temporaire d’un service ou les expirations de délai qui se produisent quand un service est occupé. Ces erreurs se corrigent souvent d’elles-mêmes. Si l’action se répète après un délai approprié, elle a de fortes chances d’aboutir.
Les erreurs temporaires peuvent avoir un impact considérable sur la perception de la qualité d’une application, même si celle-ci a été testée de manière approfondie dans toutes les circonstances prévisibles. Pour qu’une application qui communique avec des services distants fonctionne de manière fiable, elle doit pouvoir effectuer toutes les opérations suivantes :
- Détectez les erreurs quand elles se produisent, et déterminez si elles sont susceptibles d’être temporaires.
- Réessayez l’opération s’il s’avère que l’erreur est probablement temporaire, et notez le nombre de nouvelles tentatives.
- Utilisez une stratégie de nouvelles tentatives appropriée, qui spécifie le nombre de nouvelles tentatives, le délai entre chaque tentative et les actions à entreprendre après un échec.
Vous pouvez effectuer cette gestion des erreurs temporaires en wrappant toutes les tentatives d’accès à un service distant dans du code qui implémente le modèle de nouvelle tentative.
Modèle Nouvelle tentative
Si une application détecte une défaillance quand elle tente d’envoyer une requête à un service distant, elle peut gérer cette défaillance de l’une des manières suivantes :
- Nouvelle tentative de l’opération. L’application peut retenter immédiatement la requête défaillante.
- Nouvelle tentative de l’opération après un délai. L’application doit attendre un délai approprié avant de retenter l’exécution de la requête.
- Annulation de l’opération. L’application doit annuler l’opération et signaler une exception.
La stratégie de nouvelles tentatives doit être configurée en fonction des besoins métier de l’application. Par exemple, il est important d’optimiser le nombre de nouvelles tentatives et l’intervalle avant nouvelle tentative en fonction de l’opération tentée. Si l’opération fait partie d’une interaction de l’utilisateur, l’intervalle avant nouvelle tentative doit être court, et seules quelques nouvelles tentatives doivent être effectuées pour éviter que les utilisateurs n’attendent une réponse. Si l’opération fait partie d’un workflow durable, pour lequel l’annulation ou le redémarrage du workflow est coûteux ou prend du temps, il est préférable d’attendre plus longtemps entre les tentatives et de réessayer plusieurs fois.
Notes
Une stratégie agressive de nouvelles tentatives avec un délai minimal entre les tentatives, et un grand nombre de nouvelles tentatives, peut dégrader un service distant qui s’exécute à pleine capacité ou presque. De plus, une telle stratégie de nouvelles tentatives peut également affecter la réactivité de l’application si elle tente en permanence de relancer une opération qui n’aboutit pas.
Si une requête continue d’échouer après un certain nombre de nouvelles tentatives, il est préférable que l’application empêche l’envoi d’autres requêtes à la même ressource, et qu’elle signale l’échec. Après une période définie, l’application peut ensuite envoyer une ou plusieurs requêtes à la ressource pour déterminer si elles aboutissent. Pour plus d’informations, consultez Modèle Disjoncteur.
Conseil
N’implémentez jamais de mécanisme de nouvelle tentative infini. À la place, préférez un backoff exponentiel.
Utilisez un nombre fini de nouvelles tentatives, ou implémentez le modèle Disjoncteur pour permettre la récupération d’un service.
L’application de référence eShop implémente le modèle de nouvelle tentative.
Pour plus d’informations sur le modèle de nouvelle tentative, consultez le modèle Nouvelle tentative sur Microsoft Docs.
Modèle Disjoncteur
Dans certaines situations, des erreurs peuvent se produire en raison d’événements anticipés qui prennent plus de temps à être corrigés. Ces erreurs peuvent aller d’une perte partielle de connectivité à la défaillance complète d’un service. Dans ce genre de situation, il est inutile pour une application de retenter une opération qui a peu de chances de réussir. À la place, elle doit prendre en compte l’échec de l’opération, et le gérer de manière appropriée.
Le modèle de disjoncteur peut empêcher une application de tenter à plusieurs reprises d’exécuter une opération susceptible d’échouer, tout en permettant également à cette application de détecter si l’erreur a été résolue.
Notes
La finalité du modèle de disjoncteur est différente de celle du modèle de nouvelle tentative. Le modèle de nouvelle tentative permet à une application de retenter une opération en partant du principe qu’elle finira par réussir. Le modèle de disjoncteur empêche une application d’effectuer une opération qui a de grandes chances d’échouer.
Un disjoncteur agit comme un proxy pour les opérations qui risquent d’échouer. Le proxy doit effectuer le monitoring du nombre d’échecs récents qui se sont produits, et utiliser ces informations pour décider s’il est nécessaire d’autoriser la poursuite de l’opération ou de retourner immédiatement une exception.
L’application multiplateforme eShop n’implémente actuellement pas le modèle disjoncteur. Cependant, l’eShop le fait.
Conseil
Combinez les modèles de nouvelle tentative et de disjoncteur.
Une application peut combiner les modèles de nouvelle tentative et de disjoncteur en utilisant le modèle de nouvelle tentative pour appeler une opération via un disjoncteur. Toutefois, la logique de nouvelle tentative doit être sensible aux exceptions retournées par le disjoncteur, et abandonner les nouvelles tentatives si le disjoncteur indique qu’une erreur n’est pas temporaire.
Pour plus d’informations sur le modèle de disjoncteur, consultez le modèle Disjoncteur sur Microsoft Docs.
Résumé
De nombreuses solutions web modernes utilisent des services web, hébergés par des serveurs web, pour fournir des fonctionnalités aux applications clientes distantes. Les opérations exposées par un service web constituent une API web. Les applications clientes doivent pouvoir utiliser l’API web sans savoir comment les données ou les opérations exposées par l’API sont implémentées.
Vous pouvez améliorer les performances d’une application en mettant en cache les données fréquemment utilisées sur un espace de stockage rapide situé à proximité de l’application. Les applications peuvent implémenter la mise en cache en lecture directe avec le modèle de type cache-aside. Ce modèle détermine si l’élément se trouve dans le cache. Si l’élément ne se trouve pas dans le cache, il est lu à partir du magasin de données et est ajouté au cache.
Durant la communication avec les API web, les applications doivent être sensibles aux erreurs temporaires. Les erreurs temporaires incluent la perte momentanée de la connectivité réseau aux services, l’indisponibilité temporaire d’un service ou les expirations de délai qui se produisent quand un service est occupé. Ces erreurs se corrigent souvent d’elles-mêmes. Si l’action se répète après un délai approprié, elle a de fortes chances d’aboutir. Les applications doivent donc wrapper toutes les tentatives d’accès à une API web dans du code, qui implémente un mécanisme de gestion des erreurs temporaires.