Communication entre services
Conseil
Ce contenu est un extrait du livre électronique, Cloud Native .NET apps for Azure (Architecture d’applications .NET natives cloud pour Azure), disponible dans la documentation .NET ou au format PDF à télécharger gratuitement pour le lire hors connexion.

Après avoir discuté du client front-end, nous abordons les microservices back-end qui communiquent entre eux.
Lors de la construction d’une application native cloud, vous devez être sensible à la façon dont les services back-end communiquent entre eux. Dans l’idéal, il est préférable de limiter autant que possible la communication interservice. Mais il n’est pas toujours possible de l’éviter, car les services back-end sont souvent dépendants d’un autre service pour exécuter une opération.
Il existe plusieurs approches largement acceptées pour implémenter la communication entre les services. Le type d’interaction de communication détermine souvent la meilleure approche.
Envisagez les types d’interactions suivants :
Requête : lorsqu’un microservice appelant nécessite une réponse d’un microservice appelé, par exemple « Bonjour, donnez-moi les informations de l’acheteur pour un ID client donné ».
Commande : lorsque le microservice appelant a besoin d’un autre microservice pour exécuter une action, mais ne nécessite pas de réponse, telle que « Bonjour, il suffit d’expédier cette commande ».
Événement : lorsqu’un microservice, appelé éditeur, déclenche un événement dont l’état a changé ou pour lequel une action s’est produite. D’autres microservices, appelés abonnés, qui sont intéressés, peuvent réagir à l’événement de manière appropriée. L’éditeur et les abonnés ne sont pas conscients les uns des autres.
Les systèmes de microservices utilisent généralement une combinaison de ces types d’interaction lors de l’exécution d’opérations nécessitant une interaction entre les services. Examinons de près chacun d’eux et la façon dont vous pouvez les implémenter.
Requêtes
Souvent, un microservice peut avoir besoin d’interroger un autre microservice, car il nécessite une réponse immédiate pour terminer une opération. Un microservice de panier d’achat peut avoir besoin d’informations sur le produit et d’un prix pour ajouter un article à son panier. Il existe de nombreuses approches pour implémenter des opérations de requête.
Messages de requête-réponse
L’une des options d’implémentation de ce scénario consiste à appeler le microservice back-end pour qu’il effectue des requêtes HTTP directes aux microservices qu’il doit interroger, comme illustré dans la Figure 4-8.
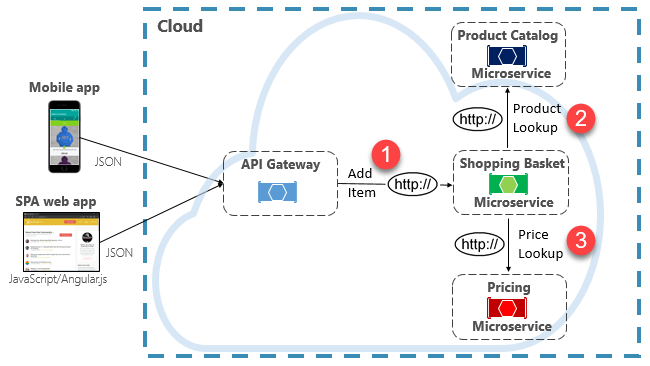
Figure 4-8. Communication HTTP directe
Bien que les appels HTTP directs entre les microservices soient relativement simples à implémenter, vous devez éviter au maximum de faire appel à cette pratique. Pour commencer, ces appels sont toujours synchrones et bloquent l’opération jusqu’à ce qu’un résultat soit retourné ou que la demande expire. Autrefois autonomes, indépendants et capables d’évoluer indépendamment et de déployer fréquemment, ces services sont à présent couplés les uns aux autres. À mesure que le couplage entre les microservices augmente, leurs avantages architecturaux diminuent.
L’exécution d’une requête peu fréquente qui effectue un seul appel HTTP direct vers un autre microservice peut être acceptable pour certains systèmes. Toutefois, les appels à volume élevé qui appellent des appels HTTP directs vers plusieurs microservices ne sont pas conseillés. Ils peuvent augmenter la latence et avoir un impact négatif sur les performances, la scalabilité et la disponibilité de votre système. Pire encore, une longue série de communications HTTP directes peut entraîner des chaînes profondes et complexes d’appels de microservices synchrones, comme illustré dans la Figure 4-9 :
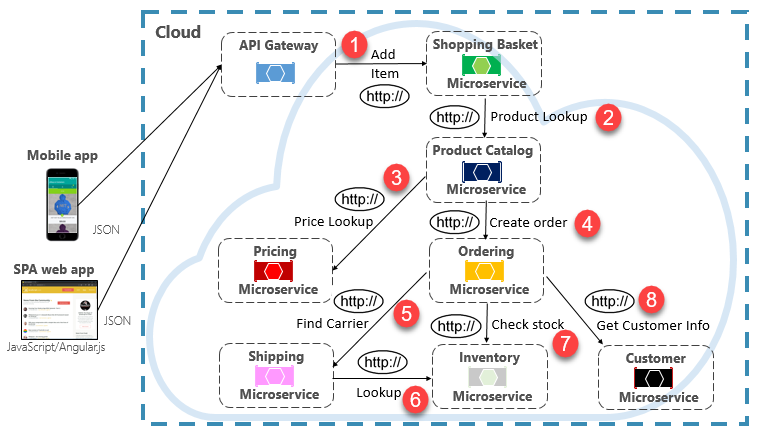
Figure 4-9. Chaînage de requêtes HTTP
Vous pouvez certainement imaginer le risque que fait courir la conception présentée dans l’image précédente. Que se passe-t-il si l’étape 3 échoue ? Ou si l’étape 8 échoue ? Comment récupérer ? Que se passe-t-il si l’étape 6 est lente, car le service sous-jacent est occupé ? Comment continuez-vous ? Même si tout fonctionne correctement, pensez à la latence que cet appel entraînerait, c’est-à-dire la somme de la latence de chaque étape.
Le fort degré de couplage dans l’image précédente suggère que les services n’ont pas été modélisés de manière optimale. Il incomberait à l’équipe de revoir sa conception.
Modèle de vue matérialisée
Une option populaire pour supprimer le couplage de microservice est le modèle de vue matérialisée. Avec ce modèle, un microservice stocke sa propre copie locale et dénormalisée de données détenues par d’autres services. Au lieu d’interroger les services Catalogue de produits et Tarification, le microservice Panier d’achat conserve sa propre copie locale de ces données. Ce modèle élimine le couplage inutile et améliore la fiabilité et le temps de réponse. L’opération entière s’exécute à l’intérieur d’un seul processus. Nous explorons ce modèle et d’autres préoccupations en matière de données dans le chapitre 5.
Modèle d’agrégateur de service
Une autre option permettant d’éliminer le couplage de microservice à microservice est un microservice Agrégateur, illustré dans la Figure 4-10.
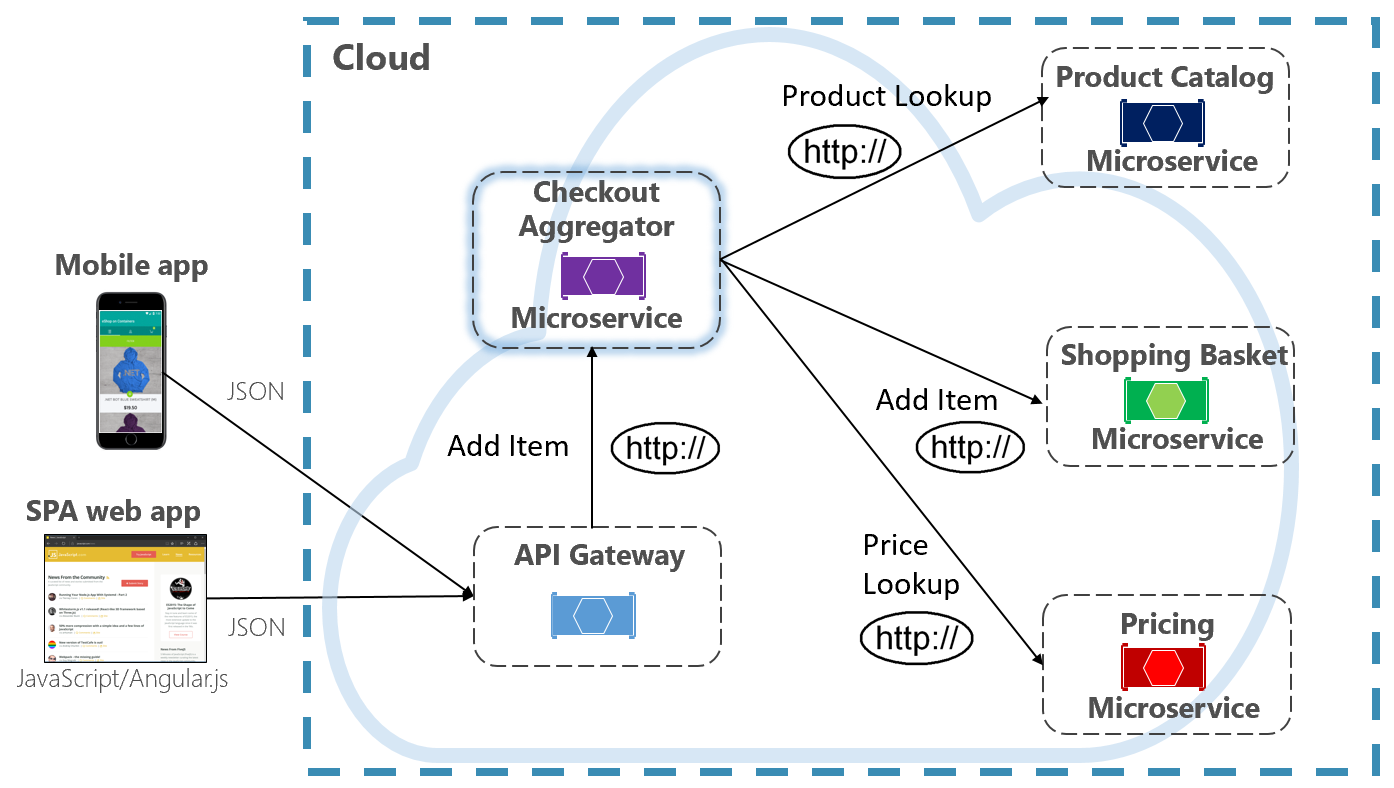
Figure 4-10. Microservice Agrégateur
Le modèle isole une opération qui effectue des appels à plusieurs microservices back-end, en centralisant sa logique dans un microservice spécialisé. Le microservice Agrégateur de paiement violet dans la figure précédente orchestre le workflow pour l’opération Paiement. Il inclut des appels à plusieurs microservices back-end dans un ordre précis. Les données du workflow sont agrégées et retournées à l’appelant. Bien qu’il implémente toujours des appels HTTP directs, le microservice Agrégateur réduit les dépendances directes entre les microservices back-end.
Modèle de requête/réponse
Une autre approche pour le découplage des messages HTTP synchrones est un modèle de requête-réponse, qui utilise la communication de mise en file d’attente. La communication à l’aide d’une file d’attente est toujours un canal unidirectionnel, où le producteur envoie le message et le consommateur le reçoit. Avec ce modèle, une file d’attente de requêtes et une file d’attente de réponses sont implémentées, comme illustré dans la Figure 4-11.
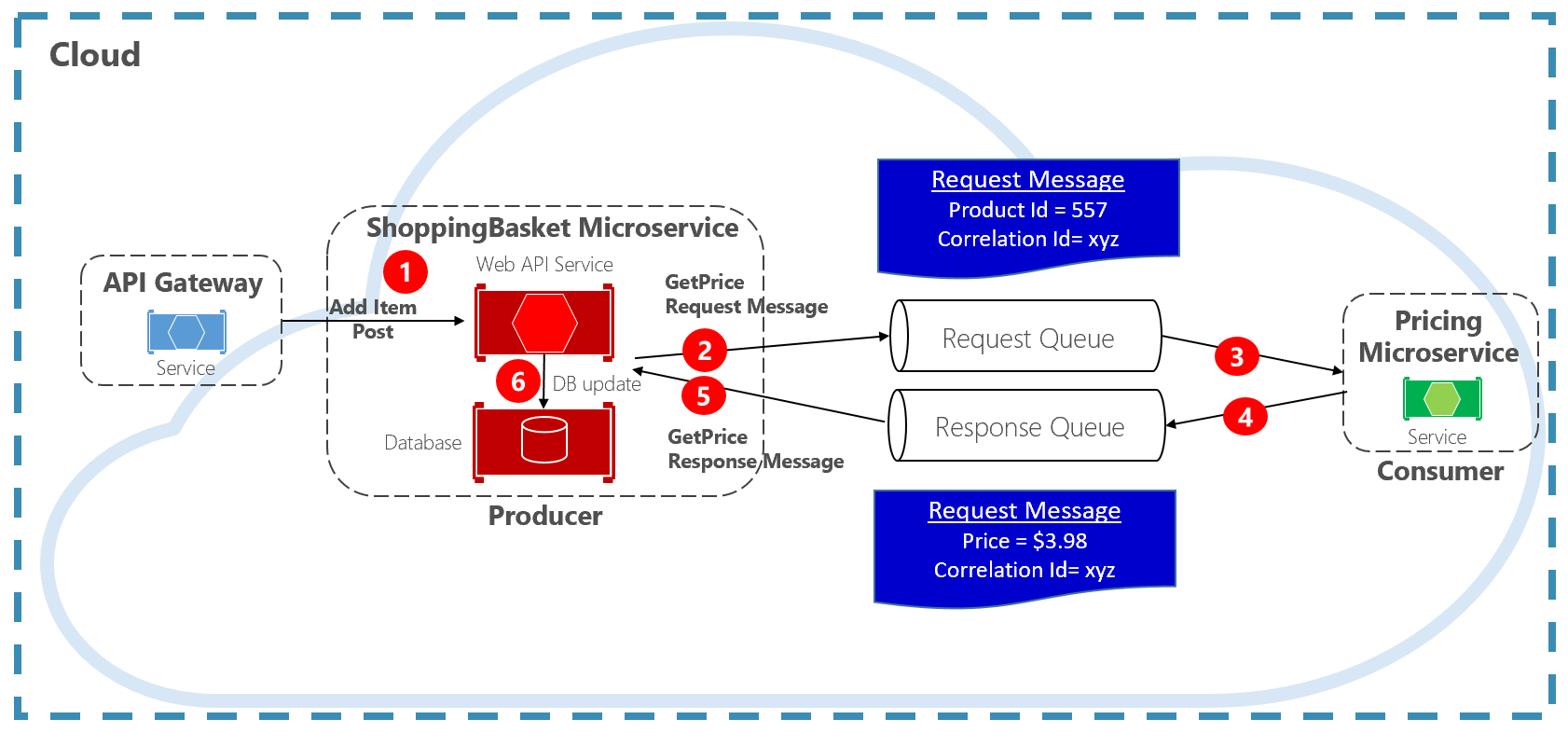
Figure 4-11. Modèle de requête/réponse
Ici, le producteur de messages crée un message basé sur une requête qui contient un ID de corrélation unique et le place dans une file d’attente de requêtes. Le service consommant annule la mise en file d’attente des messages, effectue le traitement et place la réponse dans la file d’attente de réponses avec le même ID de corrélation. Le service producteur annule la mise en file d’attente du message, le met en correspondance avec l’ID de corrélation et poursuit le traitement. Nous abordons les files d’attente en détail dans la section suivante.
Commandes
La commande est un autre type d’interaction de communication. Un microservice peut avoir besoin d’un autre microservice pour effectuer une action. Le microservice Commande peut nécessiter que le microservice Expédition crée une expédition pour une commande approuvée. Dans la Figure 4-12, un microservice, appelé producteur, envoie un message à un autre microservice, le consommateur, en lui commandant de faire quelque chose.
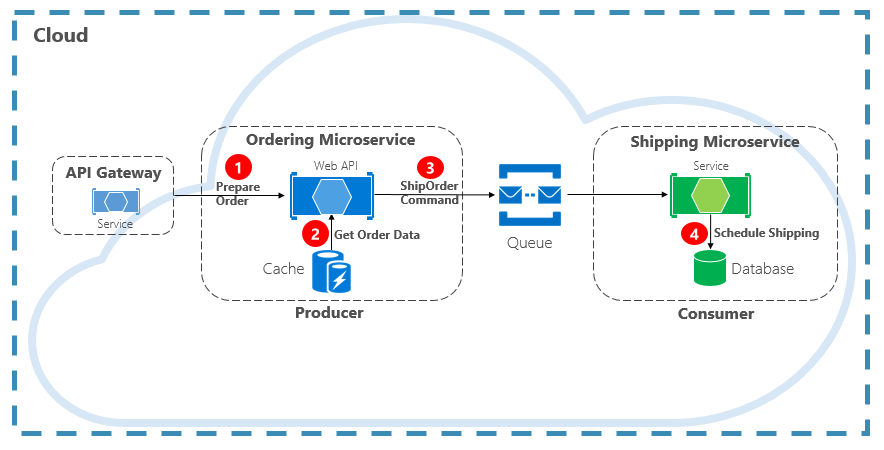
Figure 4-12. Interaction de commande avec une file d’attente
Le plus souvent, le Producteur ne nécessite pas de réponse et peut déclencher et oublier le message. Si une réponse est nécessaire, le Consommateur renvoie un message distinct au Producteur sur un autre canal. Un message de commande est mieux envoyé de façon asynchrone avec une file d’attente de messages prise en charge par un répartiteur de messages léger. Dans le diagramme précédent, notez la façon dont une file d’attente sépare et découple les deux services.
Comme de nombreuses files d’attente de messages peuvent distribuer le même message plusieurs fois, appelé remise au moins une fois, le consommateur doit être en mesure d’identifier et de gérer correctement ces scénarios à l’aide des modèles de traitement de messages idempotent pertinents.
Une file d’attente de messages est une construction intermédiaire par laquelle un producteur et un consommateur transmettent un message. Les files d’attente implémentent un modèle de messagerie asynchrone point à point. Le Producteur sait où une commande doit être envoyée et la route de manière appropriée. La file d’attente garantit qu’un message est traité par l’une des instances de consommateur qui lisent à partir du canal. Dans ce scénario, le service producteur ou consommateur peut effectuer un scale-out sans affecter l’autre service. De plus, les technologies peuvent être disparates de chaque côté, ce qui signifie que nous pourrions avoir un microservice Java appelant un microservice Golang.
Dans le chapitre 1, nous avons parlé des services de sauvegarde. Les services de sauvegarde sont des ressources auxiliaires sur lesquelles dépendent les systèmes natifs cloud. Les files d’attente de messages sont des services de sauvegarde. Le cloud Azure prend en charge deux types de files d’attente de messages que vos systèmes natifs cloud peuvent consommer pour implémenter la messagerie de commande : les files d’attente Stockage Azure et les files d’attente Azure Service Bus.
Files d’attente Stockage Azure
Les files d’attente Stockage Azure offrent une infrastructure de mise en file d’attente simple qui est rapide, abordable et soutenue par les comptes de stockage Azure.
Les files d’attente Stockage Azure intègrent un mécanisme de mise en file d’attente basé sur REST avec une messagerie fiable et persistante. Elles fournissent un ensemble de fonctionnalités minimal, mais sont peu coûteuses et stockent des millions de messages. Leur capacité varie jusqu’à 500 To. La taille maximale d’un seul message est de 64 Ko.
Vous pouvez accéder aux messages depuis n’importe où dans le monde par le biais d’appels authentifiés à l’aide du protocole HTTP ou HTTPS. Les files d’attente de stockage peuvent effectuer un scale-out vers un grand nombre de clients simultanés pour gérer les pics de trafic.
Cela dit, il existe des limitations avec le service :
L’ordre des messages n’est pas garanti.
Un message ne peut persister que pendant sept jours avant qu’il ne soit automatiquement supprimé.
La prise en charge de la gestion de l’état, de la détection en double ou des transactions n’est pas disponible.
La Figure 4-13 montre la hiérarchie d’une file d’attente de stockage Azure.
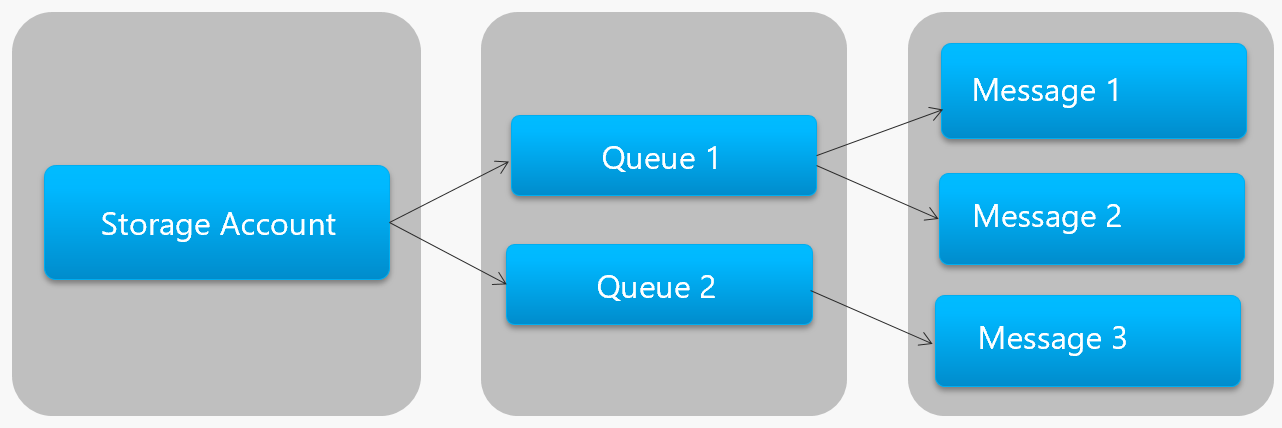
Figure 4-13. Hiérarchie de files d’attente de stockage
Dans la figure précédente, notez comment les files d’attente de stockage stockent leurs messages dans le compte de stockage Azure sous-jacent.
Pour les développeurs, Microsoft fournit plusieurs bibliothèques côté client et côté serveur pour le traitement de la file d’attente de stockage. La plupart des principales plateformes sont prises en charge, notamment .NET, Java, JavaScript, Ruby, Python et Go. Les développeurs ne doivent jamais communiquer directement avec ces bibliothèques. En effet, cela aura pour effet de coupler étroitement votre code de microservice au service de File d’attente Stockage Azure. Il est préférable d’isoler les détails de l’implémentation de l’API. Introduisez une couche d’intermédiation ou une API intermédiaire qui expose des opérations génériques et encapsule la bibliothèque concrète. Ce couplage libre vous permet de basculer d’un service de mise en file d’attente à un autre sans avoir à apporter de modifications au code du service général.
Les files d’attente de stockage Azure sont une option économique pour implémenter la messagerie de commande dans vos applications natives cloud. En particulier lorsqu’une taille de file d’attente dépasse 80 Go ou qu’un ensemble de fonctionnalités simple est acceptable. Vous payez uniquement le stockage des messages ; il n’y a pas de frais horaires fixes.
Files d’attente Azure Service Bus
Pour les exigences de messagerie plus complexes, envisagez d’utiliser les files d’attente Azure Service Bus.
Situé au sommet d’une infrastructure de messages robuste, Azure Service Bus prend en charge un modèle de messagerie répartie. Les messages sont stockés de manière fiable dans un répartiteur (la file d’attente) jusqu’à ce qu’ils soient reçus par le consommateur. La file d’attente garantit la remise des messages FIFO (First-In/First-Out), en respectant l’ordre dans lequel les messages ont été ajoutés à la file d’attente.
La taille d’un message peut être beaucoup plus grande, jusqu’à 256 Ko. Les messages sont conservés dans la file d’attente pendant une période illimitée. Service Bus prend en charge non seulement les appels HTTP, mais fournit également une prise en charge complète du protocole AMQP. AMQP est une norme ouverte entre les fournisseurs qui prend en charge un protocole binaire et des degrés de fiabilité supérieurs.
Service Bus fournit un ensemble complet de fonctionnalités, notamment la prise en charge des transactions et une fonctionnalité de détection des doublons. La file d’attente garantit « au plus une remise » par message. Elle ignore automatiquement un message qui a déjà été envoyé. Si un producteur a un doute, il peut renvoyer le même message, et Service Bus garantit qu’une seule copie sera traitée. La détection des doublons vous éviter de devoir créer un plomberie d’infrastructure supplémentaire.
Deux autres fonctionnalités d’entreprise sont le partitionnement et les sessions. Une file d’attente Service Bus conventionnelle est gérée par un seul courtier de messages et stockée dans une seule banque de messages. Toutefois, le partitionnement Service Bus répartit la file d’attente sur plusieurs répartiteurs de messages et magasins de messages. Le débit global n’est plus limité par les performances d’un seul courtier de messages ou d’un seul magasin de messages. Une panne temporaire d’une banque de messagerie ne rend pas une file d’attente partitionnée indisponible.
Les sessions Service Bus permettent de regrouper les messages. Imaginez un scénario de workflow dans lequel les messages doivent être traités ensemble et l’opération terminée à la fin. Pour en tirer parti, les sessions doivent être explicitement activées pour la file d’attente et chaque message associé doit contenir le même ID de session.
Toutefois, il existe quelques mises en garde importantes : la taille des files d’attente Service Bus est limitée à 80 Go, ce qui est beaucoup plus petit que ce qui est disponible dans les files d’attente du magasin. En outre, les files d’attente Service Bus entraînent un coût de base et des frais par opération.
La Figure 4-14 décrit l’architecture générale d’une file d’attente Service Bus.
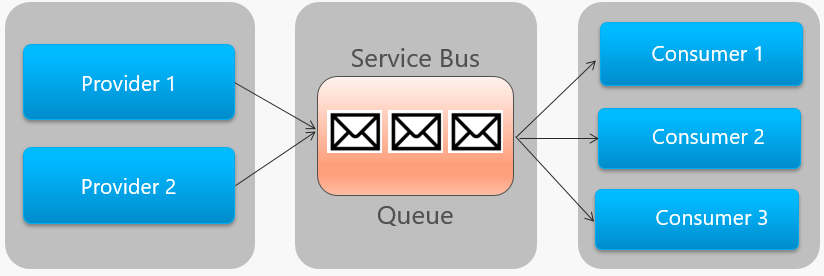
Figure 4-14. File d’attente Service Bus
Dans la figure précédente, notez la relation point à point. Deux instances du même fournisseur mettent en file d’attente des messages dans une file d’attente Service Bus unique. Chaque message est consommé par une seule des trois instances de consommateur à droite. Ensuite, nous expliquons comment implémenter une messagerie où différents consommateurs peuvent tous être intéressés par le même message.
Événements
La mise en file d’attente de messages est un moyen efficace d’implémenter une communication où un producteur peut envoyer de façon asynchrone un message à un consommateur. Toutefois, que se passe-t-il lorsque de nombreux consommateurs différents s’intéressent au même message ? Une file d’attente de messages dédiée pour chaque consommateur n’est pas correctement mise à l’échelle et devient difficile à gérer.
Pour résoudre ce scénario, nous passons au troisième type d’interaction de message, l’événement. Un microservice annonce qu’une action s’est produite. D’autres microservices, s’ils sont intéressés, réagissent à l’action ou à l’événement. C’est également ce que l’on appelle le style architectural piloté par les événements.
La gestion des événements est un processus en deux étapes. Pour une modification d’état donnée, un microservice publie un événement sur un répartiteur de messages, le rendant disponible pour tout autre microservice intéressé. Le microservice intéressé est averti en s’abonnant à l’événement dans le répartiteur de messages. Vous utilisez le modèle Publier/s’abonner pour implémenter la communication basée sur les événements.
La Figure 4-15 montre un microservice de panier d’achat qui publie un événement avec deux autres microservices qui s’y abonnent.
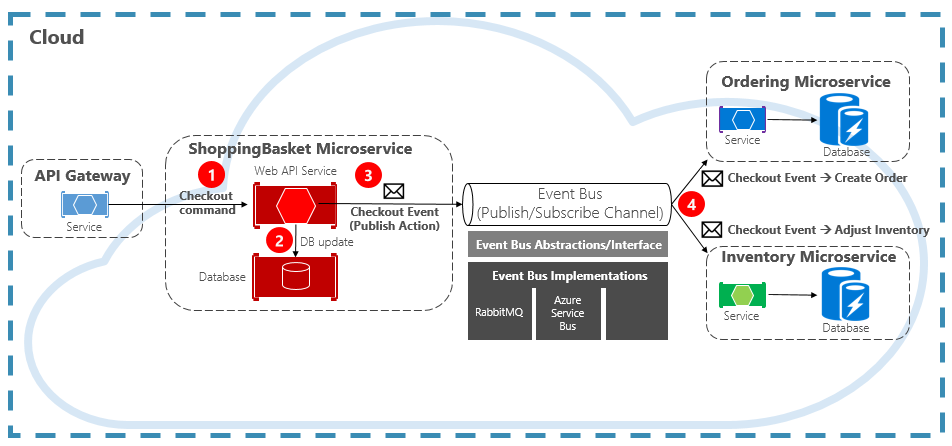
Figure 4-15. Messagerie pilotée par les événements
Notez le composant Event Bus qui se trouve au milieu du canal de communication. Il s’agit d’une classe personnalisée qui encapsule le répartiteur de messages et le dissocie de l’application sous-jacente. Les microservices de commande et d’inventaire exploitent indépendamment l’événement sans se connaître l’un l’autre, ni le microservice de panier d’achat. Lorsque l’événement inscrit est publié dans le bus d’événements, il agit en conséquence.
Avec l’événement, nous passons de la technologie de mise en file d’attente aux rubriques. Une rubrique est similaire à une file d’attente, mais prend en charge un modèle de messagerie un-à-plusieurs. Un microservice publie un message. Plusieurs microservices abonnés peuvent choisir de recevoir et d’agir sur ce message. La Figure 4-16 illustre une architecture de rubriques.
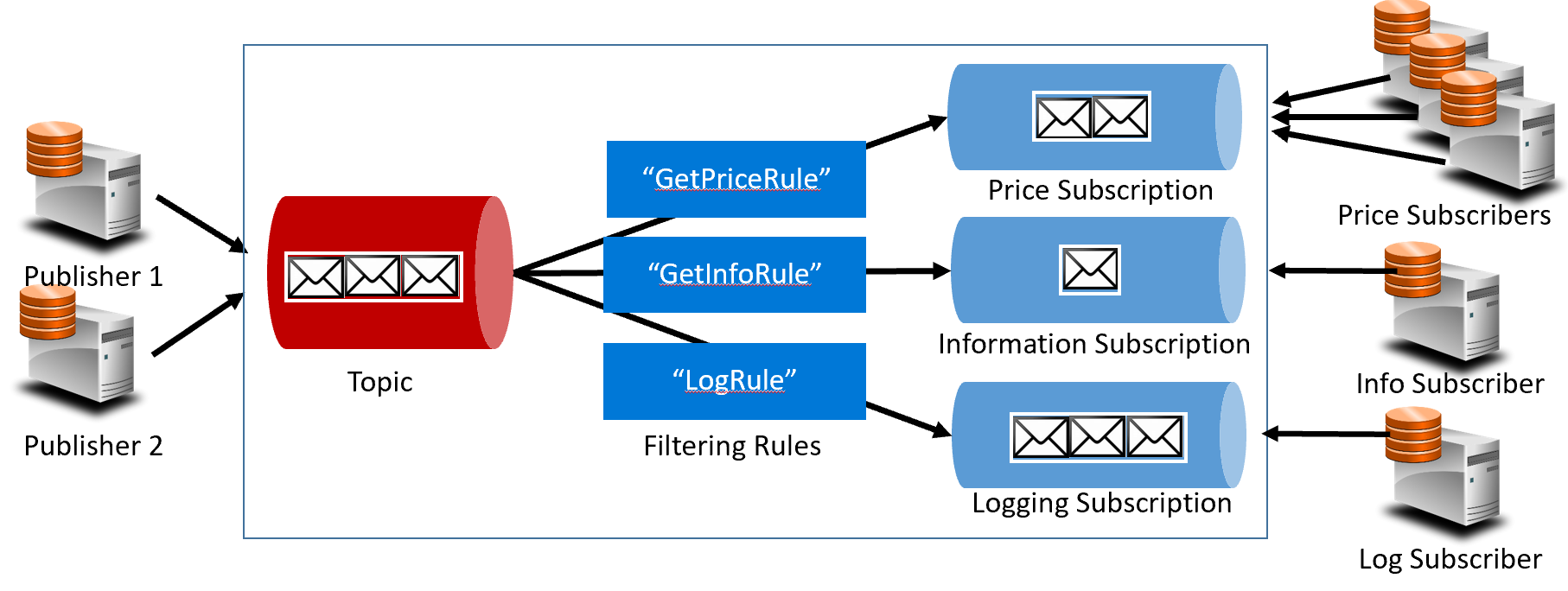
Figure 4-16. Architecture de rubriques
Dans la figure précédente, les éditeurs envoient des messages à la rubrique. À la fin, les abonnés reçoivent des messages des abonnements. Au milieu, la rubrique transfère les messages aux abonnements en fonction d’un ensemble de règles, affichés dans des zones bleues foncées. Les règles agissent comme un filtre qui transfère des messages spécifiques à un abonnement. Ici, un événement « GetPrice » est envoyé aux abonnements de prix et de journalisation, car l’abonnement de journalisation a choisi de recevoir tous les messages. Un événement « GetInformation » est envoyé aux informations et aux abonnements de journalisation.
Le cloud Azure prend en charge deux services de rubrique différents : les Rubriques Azure Service Bus et Azure Event Grid.
Rubriques Azure Service Bus
Situées sur le même modèle de messagerie répartie robuste des files d’attente Azure Service Bus se trouvent les rubriques Azure Service Bus. Une rubrique peut recevoir des messages de plusieurs éditeurs indépendants et envoyer des messages à jusqu’à 2 000 abonnés. Les abonnements peuvent être ajoutés ou supprimés dynamiquement au moment de l’exécution sans arrêter le système ou recréer la rubrique.
De nombreuses fonctionnalités avancées des files d’attente Azure Service Bus sont également disponibles pour les rubriques, notamment la détection des doublons et la prise en charge des transactions. Par défaut, les rubriques Service Bus sont gérées par un répartiteur de messages unique et stockées dans un magasin de messages unique. Toutefois, le partitionnement Service Bus met à l’échelle une rubrique en la répartissant sur de nombreux répartiteurs de messages et magasins de messages.
La remise de messages planifiée étiquette un message avec une heure spécifique pour traitement. Le message n’apparaît pas dans la rubrique avant cette heure. Le report de message vous permet de reporter la récupération d’un message à une date ultérieure. Les deux sont couramment utilisés dans les scénarios de traitement de workflow où les opérations sont traitées dans un ordre particulier. Vous pouvez reporter le traitement des messages reçus jusqu’à ce que le travail précédent soit terminé.
Les rubriques Service Bus sont une technologie robuste et éprouvée qui permet d’activer la communication de publication/abonnement dans vos systèmes natifs cloud.
Azure Event Grid
Bien qu’Azure Service Bus soit un répartiteur de messagerie testé sur le terrain avec un ensemble complet de fonctionnalités d’entreprise, Azure Event Grid est le nouvel enfant chéri.
À première vue, Event Grid peut ressembler à un autre système de messagerie basé sur des rubriques. Toutefois, il est différent de plusieurs façons. Axé sur des charges de travail pilotées par les événements, il active le traitement des événements en temps réel, l’intégration approfondie d’Azure et une plateforme ouverte, tout cela se trouvant sur une infrastructure serverless. Il est conçu pour les applications cloud natives et serverless contemporaines.
En tant qu’infrastructure d’intégration d’événements centralisée, ou canal, Event Grid réagit aux événements à l’intérieur des ressources Azure et à partir de vos propres services.
Les notifications d’événements sont publiées dans une rubrique Event Grid, qui, à son tour, route chaque événement vers un abonnement. Les abonnés mappent aux abonnements et consomment les événements. Comme Service Bus, Event Grid prend en charge un modèle d’abonné filtré dans lequel un abonnement définit une règle pour les événements qu’il souhaite recevoir. Event Grid fournit un débit rapide avec une garantie de 10 millions d’événements par seconde permettant une livraison en quasi temps réel, bien plus que ce qu’Azure Service Bus peut générer.
Un avantage d’Event Grid est son intégration approfondie à la structure de l’infrastructure Azure. Une ressource Azure, telle que Cosmos DB, peut publier des événements intégrés directement sur d’autres ressources Azure intéressées, sans avoir besoin de code personnalisé. Event Grid peut publier des événements à partir d’un abonnement Azure, d’un groupe de ressources ou d’un service, ce qui donne aux développeurs un contrôle précis sur le cycle de vie des ressources cloud. Toutefois, Event Grid n’est pas limité à Azure. Il s’agit d’une plateforme ouverte qui peut consommer des événements HTTP personnalisés publiés à partir d’applications ou de services tiers et router des événements vers des abonnés externes.
Lors de la publication et de l’abonnement à des événements natifs à partir de ressources Azure, aucun codage n’est nécessaire. Avec une configuration simple, vous pouvez intégrer des événements d’une ressource Azure à un autre en tirant parti de la plomberie intégrée pour les rubriques et les abonnements. La Figure 4-17 montre l’anatomie d’Event Grid.
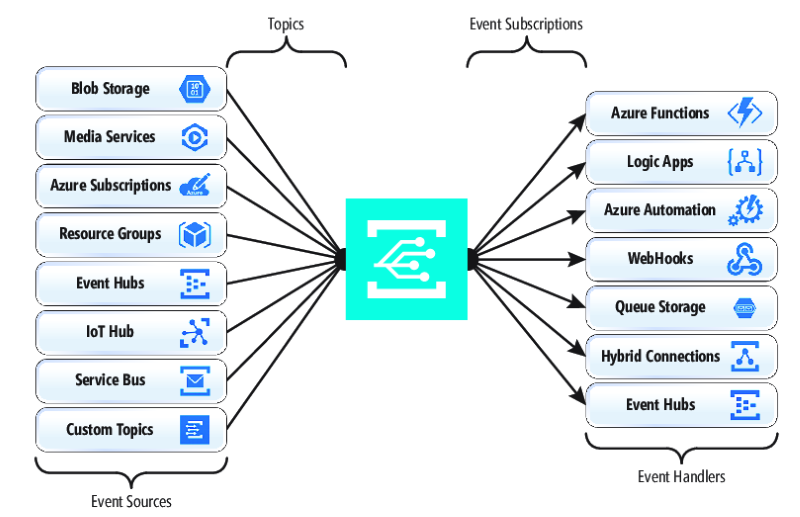
Figure 4-17. Anatomie Event Grid
Une différence majeure entre EventGrid et Service Bus est le modèle d’échange de messages sous-jacent.
Service Bus implémente un modèle d’extraction plus ancien dans lequel l’abonné en aval interroge activement l’abonnement à la rubrique pour connaître les nouveaux messages. D’un côté, cette approche donne à l’abonné un contrôle total du rythme auquel il traite les messages. Il contrôle le moment et le nombre de messages à traiter à un moment donné. Les messages non lus restent dans l’abonnement jusqu’à ce qu’ils soient traités. Une lacune significative est la latence entre le moment où l’événement est généré et l’opération d’interrogation qui extrait ce message à destination de l’abonné pour traitement. En outre, la surcharge de l’interrogation constante pour l’événement suivant consomme des ressources et de l’argent.
EventGrid, toutefois, est différent. Il implémente un modèle Push dans lequel les événements sont envoyés aux Gestionnaires d’événements tels qu’ils sont reçus, ce qui donne une remise d’événements en quasi temps réel. Il réduit également le coût à mesure que le service est déclenché uniquement lorsqu’il est nécessaire de consommer un événement, pas continuellement comme avec l’interrogation. Cela dit, un gestionnaire d’événements doit gérer la charge entrante et fournir des mécanismes de limitation pour se protéger contre la surcharge. De nombreux services Azure qui consomment ces événements, tels que Azure Functions et Logic Apps, fournissent des fonctionnalités automatiques de mise à l’échelle automatique pour gérer des charges accrues.
Event Grid est un service cloud serverless complètement managé. Il se met à l’échelle dynamiquement en fonction de votre trafic et facture uniquement votre utilisation réelle, et non la capacité pré-achetée. Les 100 000 premières opérations par mois sont gratuites : il peut s’agir notamment d’une entrée d’événement (notifications d’événements entrantes), de tentatives de remise d’abonnement, d’appels de gestion et de filtrage par objet. Avec une disponibilité de 99,99 %, EventGrid garantit la remise d’un événement dans un délai de 24 heures, avec une fonctionnalité de nouvelle tentative intégrée en cas de remise infructueuse. Les messages non remis peuvent être déplacés vers une file d’attente de lettres mortes pour résolution. Contrairement à Azure Service Bus, Event Grid est conçu pour des performances rapides et ne prend pas en charge les fonctionnalités telles que la messagerie ordonnée, les transactions et les sessions.
Streaming de messages dans le cloud Azure
Azure Service Bus et Event Grid offrent une excellente prise en charge des applications qui exposent des événements uniques et discrets, comme un nouveau document inséré dans une base de données Cosmos DB. Mais que se passe-t-il si votre système natif cloud doit traiter un flux d’événements associés ? Les flux d’événements sont plus complexes . Ils sont généralement ordonnés dans l’ordre chronologique, interconnectés et doivent être traités en tant que groupe.
Azure Event Hub est une plateforme de streaming de données et un service d’ingestion d’événements qui collecte, transforme et stocke des événements. Il est réglé pour capturer des données de streaming, telles que les notifications d’événements continus émises à partir d’un contexte de télémétrie. Le service est hautement évolutif et peut stocker et traiter des millions d’événements par seconde. Illustré dans la Figure 4-18, il s’agit souvent d’une porte d’entrée pour un pipeline d’événements, découplant le flux d’ingestion de la consommation d’événements.
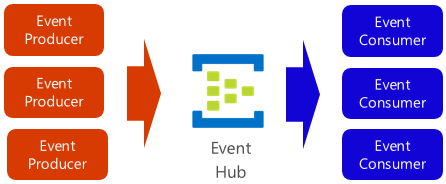
Figure 4-18. Azure Event Hub
Event Hub prend en charge une faible latence et une rétention à la durée configurable. Contrairement aux files d’attente et aux rubriques, Event Hubs conserve les données d’événement une fois qu’elles ont été lues par un consommateur. Cette fonctionnalité permet à d’autres services d’analyse des données, internes et externes, de relire les données pour une analyse plus poussée. Les événements stockés dans le hub d’événements sont supprimés uniquement à l’expiration de la période de rétention, qui est d’un jour par défaut, mais configurable.
Event Hub prend en charge les protocoles de publication d’événements courants, notamment HTTPS et AMQP. Il prend également en charge Kafka 1.0. Les applications Kafka existantes peuvent communiquer avec Event Hub à l’aide du protocole Kafka fournissant une alternative à la gestion de grands clusters Kafka. De nombreux systèmes natifs cloud open source adoptent Kafka.
Event Hubs implémente le streaming de messages suivant un modèle de consommateur partitionné dans lequel chaque consommateur ne lit qu’un sous-ensemble spécifique, ou partition, du flux de messages. Ce modèle permet de disposer d'une échelle horizontale considérable pour le traitement des événements, et offre d'autres fonctionnalités axées sur le flux, qui ne sont pas disponibles dans les rubriques et les files d'attente. Une partition est une séquence ordonnée d’événements qui est conservée dans un concentrateur d’événements. Les événements les plus récents sont ajoutés à la fin de cette séquence. La Figure 4-19 montre le partitionnement dans un hub d’événements.
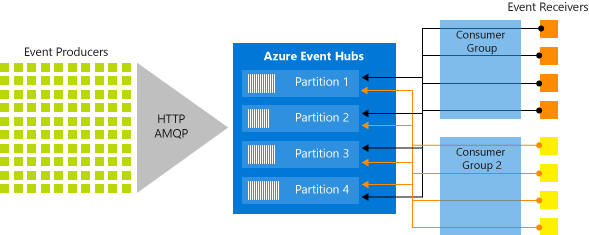
Figure 4-19. Partitionnement Event Hub
Au lieu de lire à partir de la même ressource, chaque groupe de consommateurs lit dans un sous-ensemble, ou partition, du flux de messages.
Pour les applications natives cloud qui doivent diffuser en continu un grand nombre d’événements, Azure Event Hub peut être une solution robuste et abordable.