La génération d’extraction augmentée (RAG) fournit des connaissances LLM
Cet article décrit comment la génération augmentée par la recherche permet aux LLM de traiter vos sources de données comme des connaissances sans avoir à s'entraîner.
Les modules LLM ont des bases de connaissances étendues par le biais de la formation. Dans la plupart des cas, vous pouvez sélectionner un LLM conçu pour répondre à vos besoins, mais ces LLM nécessitent toujours une formation supplémentaire pour comprendre vos données spécifiques. La génération augmentée par récupération vous permet de rendre vos données disponibles pour les machines virtuelles LLM sans les entraîner en premier.
Fonctionnement de RAG
Pour effectuer une génération augmentée de récupération, vous créez des incorporations pour vos données, ainsi que des questions courantes sur celles-ci. Vous pouvez le faire à la volée ou vous pouvez créer et stocker les incorporations à l’aide d’une solution de base de données vectorielle.
Lorsqu’un utilisateur pose une question, le LLM utilise vos incorporations pour comparer la question de l’utilisateur à vos données et trouver le contexte le plus pertinent. Ce contexte et la question de l’utilisateur passent ensuite à LLM dans une invite, et le LLM fournit une réponse basée sur vos données.
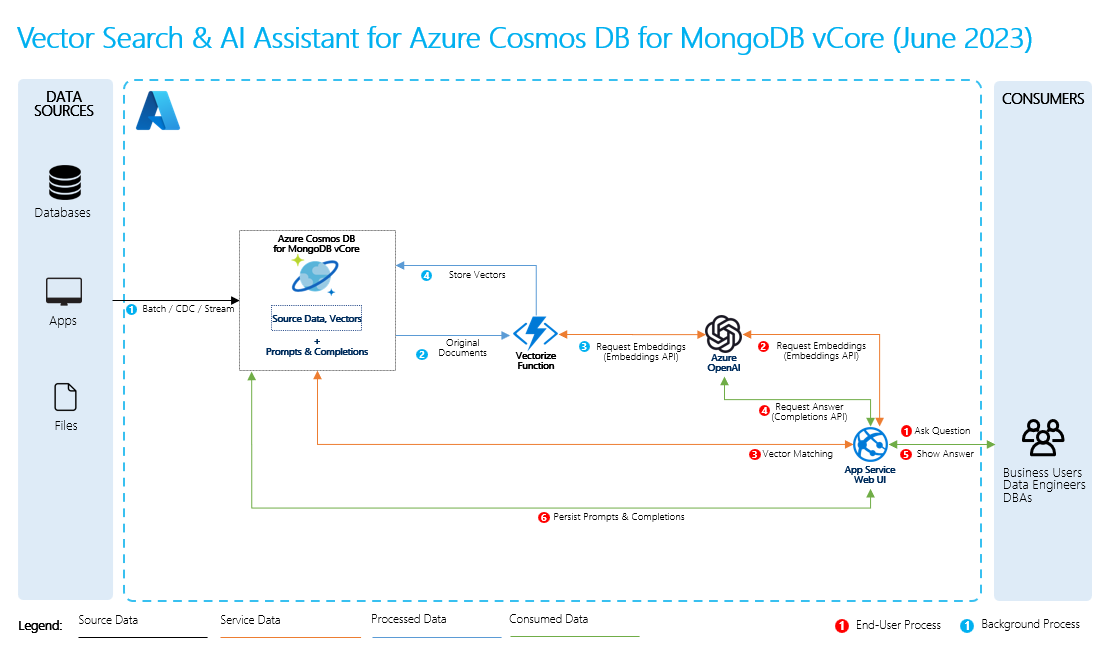
Processus RAG de base
Pour effectuer RAG, vous devez traiter chaque source de données que vous souhaitez utiliser pour les récupérations. Le processus de base est le suivant :
- Segmenter des données volumineuses en éléments gérables.
- Convertissez les blocs dans un format pouvant faire l’objet d’une recherche.
- Stockez les données converties dans un emplacement qui permet un accès efficace. En outre, il est important de stocker les métadonnées pertinentes pour les citations ou les références lorsque le LLM fournit des réponses.
- Alimentez vos données converties en machines virtuelles LLM dans les invites.
- Données sources : il s’agit de l’emplacement de vos données. Il peut s’agir d’un fichier/dossier sur votre machine, d’un fichier dans un stockage cloud, d’une ressource de données Azure Machine Learning, d’un référentiel Git ou d’une base de données SQL.
- Segmentation des données : les données de votre source doivent être converties en texte brut. Par exemple, les documents Word ou les fichiers PDF doivent être ouverts et convertis en texte. Le texte est ensuite segmenté en blocs plus petits.
- Convertir le texte en vecteurs: il s’agit d’incorporations. Les vecteurs sont des représentations numériques de concepts convertis en séquences numériques, qui permettent aux ordinateurs de comprendre facilement les relations entre ces concepts.
- Liens entre les données sources et les incorporations: ces informations sont stockées sous forme de métadonnées sur les blocs que vous avez créés, qui sont ensuite utilisées pour aider les LLMs à générer des citations lors de la génération de réponses.