Réaliser des tests « shift left » avec des tests unitaires
Les tests permettent de s’assurer que le code fournit les résultats attendus, mais le temps et les efforts consacrés à la génération de tests vous laissent moins de temps pour d’autres tâches telles que le développement de fonctionnalités. Il est donc primordial de tirer profit des tests au maximum. Cet article présente les principes de test DevOps, en se concentrant sur la valeur des tests unitaires et sur une stratégie de test « shift-left ».
Les testeurs ayant pour mission d’écrire la plupart des tests ainsi que de nombreux développeurs de produits n’ont pas appris à écrire des tests unitaires. L’écriture de tests peut parfois sembler trop difficile ou trop fastidieuse. Certains sont parfois sceptiques quant à l’efficacité d’une stratégie de tests unitaires, ont une expérience négative causée par des tests unitaires mal écrits ou craignent encore que les tests unitaires remplacent les tests fonctionnels.

Pour mettre en place une stratégie de test DevOps, soyez pragmatique et essayez de créer un élan sur lequel vos équipes pourront surfer. Bien que vous puissiez insister sur les tests unitaires pour le nouveau code ou le code existant qui peut être remanié proprement, il peut être judicieux d’autoriser une certaine dépendance pour une base de code héritée. Si des parties significatives du code produit utilisent SQL, permettant aux tests unitaires de dépendre du fournisseur de ressources SQL au lieu de simuler cette couche peut être une approche à court terme permettant d’avancer.
À mesure que les organisations DevOps arrivent à maturité, il devient plus facile pour les preneurs de décision d’améliorer les processus. Bien qu’il y ait une certaine résistance au changement, les organisations Agile valorisent les changements qui sont clairement payants. Il devrait être facile de vendre la vision d’exécutions de tests plus rapides avec moins d’échecs, car cela laisse plus de temps pour investir dans la création de valeur par le biais du développement de fonctionnalités.
Taxonomie des tests DevOps
La définition d’une taxonomie de test est un aspect important du processus de test DevOps. Une taxonomie de test DevOps classifie les tests individuels par leurs dépendances et le temps nécessaire à leur exécution. Les développeurs doivent comprendre les types de tests adaptés à chaque scénario et les différents tests requis par le processus. La plupart des organisations classent les tests sur quatre niveaux :
- Les tests L0 et L1 sont des tests unitaires, ou des tests qui dépendent du code dans l’assembly testé et rien d’autre. Les tests L0 sont une vaste classe de tests unitaires rapides et en mémoire.
- Les tests L2 sont des tests fonctionnels qui peuvent nécessiter l’assembly ainsi que d’autres dépendances, comme SQL ou le système de fichiers.
- Les tests fonctionnels L3 sont exécutés sur des déploiements de service testables. Cette catégorie de test nécessite un déploiement de service, mais peut utiliser des stubs pour les dépendances de services clés.
- Les tests L4 sont une classe restreinte de tests d’intégration qui s’exécutent sur la production. Les tests L4 nécessitent un déploiement complet du produit.
Bien qu’il serait idéal que tous les tests s’exécutent en continu, cela n’est pas possible. Les équipes peuvent sélectionner l’emplacement pour exécuter chaque test dans le processus DevOps, et utiliser des stratégies shift-left ou shift-right pour avancer ou reculer l’emplacement de différents types de test dans le processus.
Par exemple, on pourrait s’attendre à ce que les développeurs exécutent toujours des tests L2 avant de valider, une demande de tirage échoue automatiquement si l’exécution du test L3 échoue et que le déploiement peut être bloqué si les tests L4 échouent. Certaines règles peuvent varier d’une organisation à l’autre, mais instaurer un tel niveau d’exigence pour toutes les équipes au sein d’une organisation oriente tout le monde vers des objectifs communs en termes d’approche de la qualité.
Instructions relatives aux tests unitaires
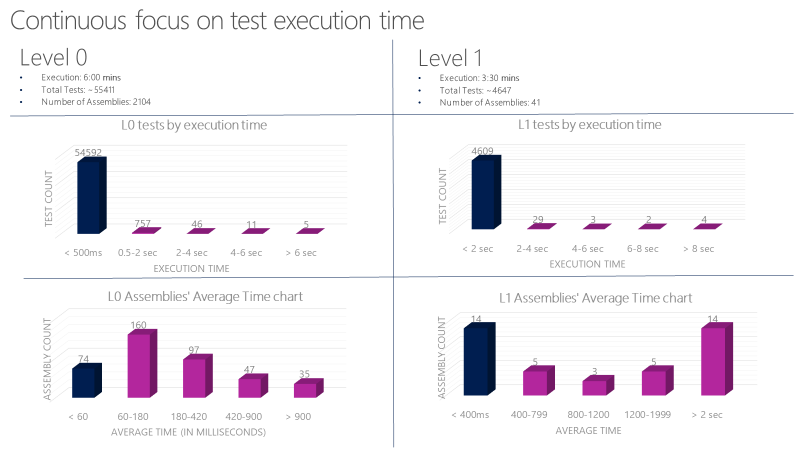
Définissez des instructions strictes pour les tests unitaires L0 et L1. Ces tests doivent être très rapides et fiables. Par exemple, le temps d’exécution moyen d’un test L0 dans un assembly doit être inférieur à 60 millisecondes. Le temps d’exécution moyen d’un test L1 dans un assembly doit être inférieur à 400 millisecondes. Aucun test à ce niveau ne doit excéder 2 secondes.
Une équipe Microsoft exécute plus de 60 000 tests unitaires en parallèle en moins de six minutes. Leur objectif est de réduire ce temps à moins d’une minute. L’équipe contrôle le temps d’exécution des tests unitaires avec des outils comme le graphique suivant et classe les bugs par rapport aux tests qui dépassent le temps autorisé.
Recommandations en matière de tests fonctionnels
Les tests fonctionnels doivent être indépendants. Le concept clé pour les tests L2 est l’isolation. Les tests correctement isolés peuvent s’exécuter de manière fiable dans n’importe quelle séquence, car ils bénéficient d’un contrôle total sur l’environnement dans lequel ils s’exécutent. L’état doit être connu au début du test. Si un test a créé des données qui ont été laissées dans la base de données, cela pourrait corrompre l’exécution d’un autre test s’appuyant sur un autre état de base de données.
Les tests sur du code hérité qui ont besoin d’une identité utilisateur peuvent avoir fait appel à des fournisseurs d’authentification externes pour obtenir l’identité. Cette pratique présente plusieurs problèmes potentiels à surmonter. La dépendance externe peut être peu fiable ou indisponible momentanément, provoquant l’échec du test. Cette pratique enfreint également le principe d’isolation des tests, car un test peut modifier l’état d’une identité, comme l’autorisation, ce qui entraîne un état par défaut inattendu pour d’autres tests. Nous vous recommandons d’éviter ces problèmes en investissant dans la prise en charge des identités dans l’infrastructure de test.
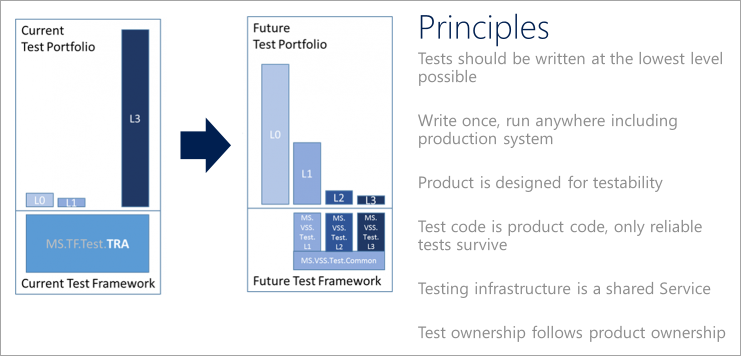
Principes de test DevOps
Pour faciliter la transition d’un portefeuille de tests vers des processus DevOps modernes, mettez en œuvre une approche qualitative. Les équipes doivent respecter les principes de test suivants lors de la définition et de la mise en œuvre d’une stratégie de test DevOps.
Ayez recours au « shift left » pour tester plus précocement
L’exécution des tests peut prendre beaucoup de temps. À mesure que les projets sont redimensionnés, les quantités et types de tests augmentent considérablement. Lorsque les ensembles de tests deviennent si longs qu’ils prennent des heures voire des jours pour être achevés, ils peuvent être repoussés de plus en plus tard jusqu’à être exécutés au dernier moment. Les avantages des tests en termes de qualité du code ne deviennent concrets que longtemps après la validation du code.
Les tests à long terme peuvent également causer des échecs qui prennent beaucoup de temps à analyser. Les équipes peuvent ainsi développer une tolérance aux défaillances, en particulier en début de sprint. Cette tolérance impacte négativement la valeur des tests en tant qu’aperçu de la qualité du codebase. Les tests de longue durée et de dernière minute ajoutent également une prévisibilité aux attentes de fin de sprint, car il existe une dette technique inconnue qui aura un coût pour rendre le code livrable.
L’objectif de l’approche shift-left est de déplacer la qualité en amont en effectuant les tâches de test plus tôt dans le pipeline. Grâce à une combinaison d’améliorations des tests et des processus, la stratégie de tests shift left réduit à la fois le temps nécessaire à l’exécution des tests, ainsi que l’impact des défaillances sur la suite du cycle. Le shift left garantit que la plupart des tests sont effectués avant qu’une modification ne soit intégrée dans la branche principale.
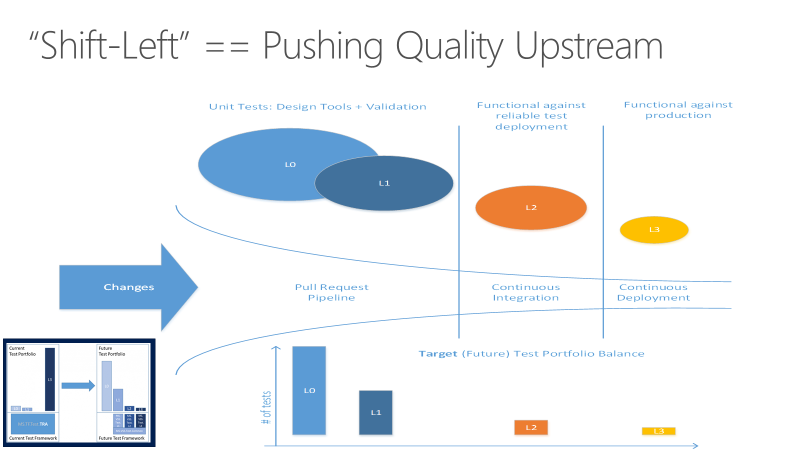
En plus de déplacer certaines responsabilités de test vers les premières étapes du processus pour améliorer la qualité du code, les équipes peuvent effectuer d’autres aspects de test ultérieurement dans le cycle de tests, ou dans le cycle DevOps, pour améliorer le produit final. Pour plus d’informations, consultez Décalage vers la droite pour tester en production.
Écrivez des tests au niveau le plus bas possible
Écrivez davantage de tests unitaires. Privilégiez les tests ayant le moins de dépendances externes et concentrez-vous sur l’exécution de la plupart des tests dans le cadre du build. Envisagez un système de construction parallèle qui peut exécuter les tests unitaires pour un assembly dès que l’assembly et les tests associés sont disponibles. Il n’est pas possible de tester tous les aspects d’un service à ce niveau, mais le principe consiste à utiliser des tests unitaires plus légers s’ils peuvent produire les mêmes résultats que des tests fonctionnels plus lourds.
Fixez vous comme objectif la fiabilité de vos tests.
Un test non fiable coûte cher à l’organisation en termes de maintenance. Il est difficile d’apporter des modifications en toute confiance avec de tels tests, ce qui pénalise directement les objectifs d’efficacité de l’ingénierie. Les développeurs doivent pouvoir apporter des modifications n’importe où en toute confiance, avec l’assurance que ces dernières n’ont rien cassé. Maintenez un niveau élevé de fiabilité. Déconseillez l’utilisation de tests de l’interface utilisateur (UI), car ils ont tendance à être peu fiables.
Rédigez des tests fonctionnels qui peuvent être exécutés n’importe où
Les tests peuvent utiliser des points d’intégration spécialisés conçus spécifiquement pour permettre les tests. Une raison de cette pratique est le manque de testabilité du produit lui-même. Malheureusement, les tests comme ceux-ci dépendent souvent de connaissances internes et utilisent des détails d’implémentation qui n’ont pas d’importance du point de vue des tests fonctionnels. Ces tests sont limités aux environnements qui ont les secrets et la configuration nécessaires pour les exécuter, ce qui exclut généralement les déploiements en production. Les tests fonctionnels doivent uniquement utiliser l’API publique du produit.
Concevoir des produits pour la testabilité
Les organisations dont le processus DevOps est arrivé à maturité adoptent une vision complète de ce que signifie livrer un produit de qualité à une cadence cloud. Le fait de déplacer fortement l’équilibre en faveur des tests unitaires par rapport aux tests fonctionnels exige que les équipes fassent des choix de conception et d’implémentation qui favorisent la testabilité. Il existe différentes façons de penser un code bien conçu et bien implémenté pour la testabilité, tout comme il existe différents styles de codage. Le principe est le suivant : la conception pour la testabilité doit devenir une partie majeure de la discussion concernant la conception et la qualité du code.
Considérez le code de test comme du code produit
Indiquer explicitement que le code de test est du code produit met en exergue le fait que la qualité du code de test est aussi importante pour la livraison que celle du code produit. Les équipes doivent traiter le code de test de la même manière que le code produit, et appliquer le même niveau de soin à la conception et à la mise en œuvre des tests et des infrastructures de test. Cet effort est similaire à la gestion de la configuration et de l’infrastructure en tant que code (IaC). Pour être complet, une vérification du code doit prendre en compte le code de test et l’évaluer selon les mêmes critères de qualité que le code produit.
Utilisez une infrastructure de test partagée
Mettez la barre plus bas en ce qui concerne l’utilisation de l’infrastructure de test afin de générer des signaux de qualité fiables. Considérez les tests comme un service partagé pour l’ensemble de l’équipe. Stockez le code des tests unitaires à côté du code produit et compilez-le avec le produit. Les tests qui s’exécutent dans le cadre du processus de build doivent également s’exécuter sous des outils de développement tels qu’Azure DevOps. Lorsque les tests peuvent s’exécuter dans chaque environnement, du développement local à la production, ils ont la même fiabilité que le code produit.
Faites des propriétaires de code les responsables des tests
Le code de test doit résider à côté du code produit dans un référentiel. Pour que le code soit testé au niveau d’exigence du composant, attribuez la responsabilité des tests à la personne rédigeant le code du composant. Ne vous fiez pas à d’autres personnes pour tester le composant.
Étude de cas : shift left avec des tests unitaires
Une équipe Microsoft a décidé de remplacer ses suites de tests hérités par des tests unitaires DevOps modernes et un processus shift left. L’équipe a suivi la progression sur des sprints tri-hebdomadaires, comme le montre le graphique suivant. Le graphique couvre les sprints 78 à 120, ce qui représente 42 sprints sur 126 semaines, soit environ deux ans et demi d’efforts.
L’équipe est passée de 27 000 tests hérités au sprint 78 à zéro test hérité au sprint 120. Un ensemble de tests unitaires L0 et L1 a remplacé la plupart des anciens tests fonctionnels. De nouveaux tests de niveau L2 ont remplacé certains des tests, et de nombreux anciens tests ont été supprimés.
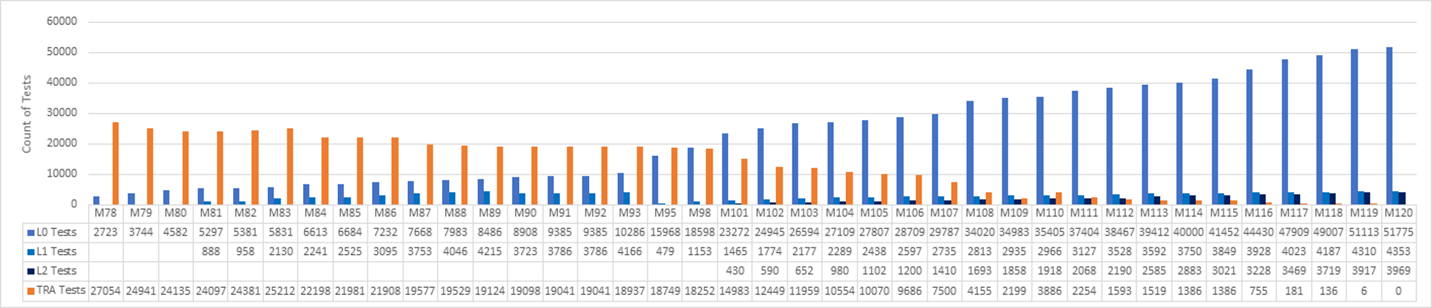
Dans un parcours logiciel qui s’étend sur plus de deux ans, il y a beaucoup à apprendre du processus en lui-même. Dans l’ensemble, l’effort de refonte complète du système de test sur deux ans a été un investissement massif. Toutes les équipes n’ont travaillé en même temps. De nombreuses équipes au sein de l’ensemble de l’organisation ont investi de leur temps pour chaque sprint, et certains sprints ont occupé la majeure partie de leur temps. Bien qu’il soit difficile de mesurer le coût du shift, c’était une exigence non négociable pour les objectifs de qualité et de performance de l’équipe.
Bien démarrer
Au début, l’équipe a laissé de côté les anciens tests fonctionnels, appelés tests TRA. L’équipe voulait que les développeurs adhèrent à l’idée d’écrire des tests unitaires, en particulier pour les nouvelles fonctionnalités. La priorité était de rendre aussi simple que possible la rédaction de tests de niveau L0 et L1. L’équipe devait tout d’abord développer cette capacité et créer un élan commun.
Le graphique précédent montre que le nombre de tests unitaires a commencé à augmenter rapidement, car l’équipe voyait réellement les avantages de la rédaction de tests unitaires. Les tests unitaires étaient plus faciles à gérer, plus rapides à exécuter et présentaient moins d’échecs. Il était facile de susciter le soutien à l’exécution de tous les tests unitaires dans le flux de demande de tirage (pull request).
L’équipe ne s’est pas concentrée sur l’écriture de nouveaux tests de niveau L2 jusqu’au sprint 101. Entre-temps, le nombre de tests TRA a diminué, passant de 27 000 à 14 000 entre le sprint 78 et le sprint 101. De nouveaux tests unitaires ont remplacé certains des tests TRA, mais beaucoup ont simplement été supprimés, après analyse par l’équipe de leur utilité.
Pour le sprint 110, le nombre de tests TRA est passé de 2100 à 3800, car davantage de tests ont été découverts dans l’arborescence source et ajoutés au graphique. Il s’est avéré que les tests avaient toujours été exécutés, mais n’étaient pas suivis correctement. Ce n’était pas la fin du monde, mais il est toujours important d’être honnête avec soi-même et de réévaluer la situation au besoin.
Passer à la vitesse supérieure
Une fois que l’équipe a pu obtenir signal d’intégration continue (CI) extrêmement rapide et fiable, c’est devenu un indicateur de confiance pour la qualité du produit. La capture d’écran suivante montre la demande de tirage (pull request) et le pipeline CI en action, et le temps nécessaire pour passer à différentes phases.
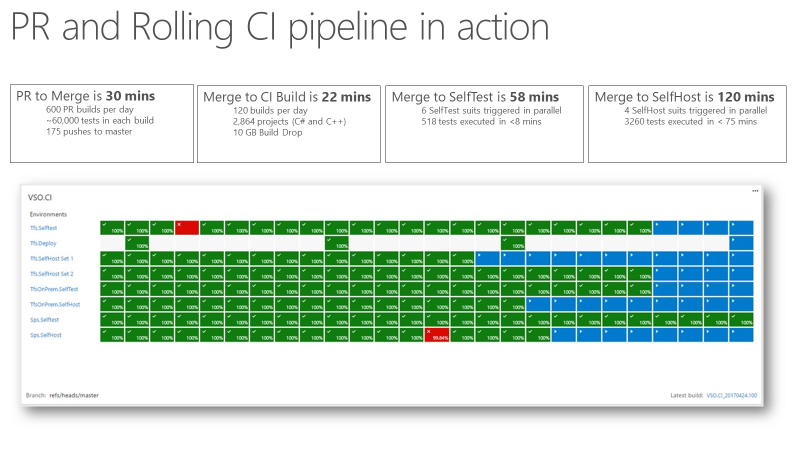
Il faut environ 30 minutes pour passer du pull request à la fusion, ce qui comprend l’exécution de 60 000 tests unitaires. Il se passe environ 22 minutes entre la fusion de code et la build CI. Le premier signal de qualité de CI, SelfTest, arrive au bout d’une heure environ. Ensuite, la plupart du produit est testé avec la modification proposée. En deux heures à partir de Merge to SelfHost, l’ensemble du produit est testé et la modification est prête à être mise en production.
Utilisation des métriques
L’équipe tient un tableau de bord comme dans l’exemple suivant. À un niveau élevé, le tableau de bord suit deux types de métriques : la santé du projet ou la dette technique, ainsi que la vélocité.
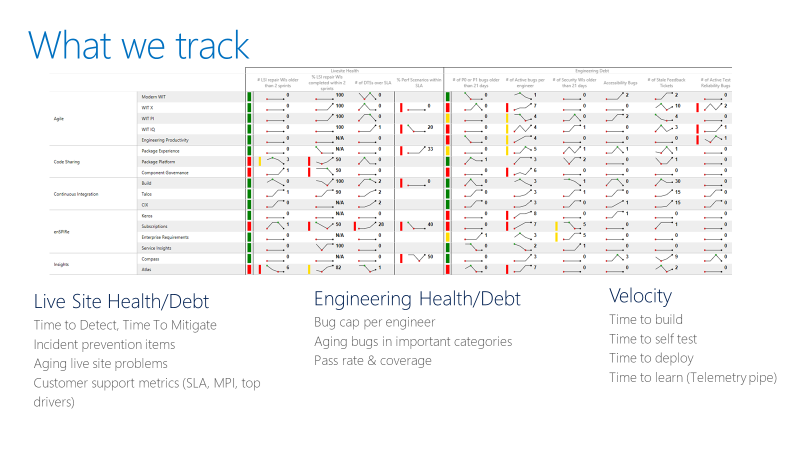
Pour les métriques de santé du site en direct, l’équipe suit le temps de détection, le temps d’atténuation et le nombre de points de correction portés par une équipe. Un point de correction, identifié par l’équipe lors d’une rétrospective sur le site en direct, est le travail nécessaire pour prévenir la récurrence d’incidents similaires. Le tableau de bord suit également si les équipes résolvent les points de correction dans un délai raisonnable.
Pour les métriques de santé de l’ingénierie, l’équipe suit le nombre de bugs actifs par développeur. Si une équipe a plus de cinq bugs par développeur, elle doit résoudre ces bugs en priorité avant de développer de nouvelles fonctionnalités. L’équipe suit également les anciens bugs dans des catégories spéciales comme la sécurité.
Les métriques de vélocité de l’ingénierie mesurent la rapidité dans différentes parties du pipeline d’intégration continue et de déploiement continu (CI/CD). L’objectif global est d’augmenter la vélocité du pipeline DevOps : partir d’une idée, mettre le code en production et recevoir des données des clients.