Procédure pas à pas : Débogage d’une application C++ AMP
Cet article montre comment déboguer une application qui utilise le parallélisme massif accéléré C++ (C++ AMP) pour tirer parti de l’unité de traitement graphique (GPU). Il utilise un programme de réduction parallèle qui additionne un grand tableau d’entiers. Cette procédure pas à pas décrit les tâches suivantes :
- Lancement du débogueur GPU.
- Inspection des threads GPU dans la fenêtre Threads GPU.
- Utilisation de la fenêtre Stacks parallèles pour observer simultanément les piles d’appels de plusieurs threads GPU.
- Utilisation de la fenêtre Parallel Watch pour inspecter les valeurs d’une seule expression sur plusieurs threads en même temps.
- Marquer, geler, dégeler et regrouper des threads GPU.
- Exécution de tous les threads d’une vignette vers un emplacement spécifique dans le code.
Prérequis
Avant de commencer cette procédure pas à pas :
Remarque
Les en-têtes AMP C++ sont déconseillés à partir de Visual Studio 2022 version 17.0.
L’inclusion d’en-têtes AMP génère des erreurs de génération. Définissez _SILENCE_AMP_DEPRECATION_WARNINGS avant d’inclure tous les en-têtes AMP pour silence les avertissements.
- Lire la vue d’ensemble de L’AMP C++.
- Assurez-vous que les numéros de ligne sont affichés dans l’éditeur de texte. Pour plus d’informations, consultez Guide pratique pour afficher les numéros de ligne dans l’éditeur.
- Vérifiez que vous exécutez au moins Windows 8 ou Windows Server 2012 pour prendre en charge le débogage sur l’émulateur logiciel.
Remarque
Il est possible que pour certains des éléments de l'interface utilisateur de Visual Studio, votre ordinateur affiche des noms ou des emplacements différents de ceux indiqués dans les instructions suivantes. L'édition de Visual Studio dont vous disposez et les paramètres que vous utilisez déterminent ces éléments. Pour plus d’informations, consultez Personnalisation de l’IDE.
Pour créer l'exemple de projet
Les instructions de création d’un projet varient en fonction de la version de Visual Studio que vous utilisez. Vérifiez que vous disposez de la version correcte de la documentation sélectionnée au-dessus de la table des matières de cette page.
Pour créer l’exemple de projet dans Visual Studio
Dans la barre de menus, choisissez Fichier>Nouveau>Projet pour ouvrir la boîte de dialogue Créer un projet.
En haut de la boîte de dialogue, définissez Langage sur C++, Plateforme sur Windows et Type de projet sur Console.
À partir de la liste des types de projets, choisissez Application console, puis choisissez Suivant. Dans la page suivante, entrez
AMPMapReducedans la zone Nom pour spécifier un nom pour le projet, puis spécifiez l’emplacement du projet si vous le souhaitez.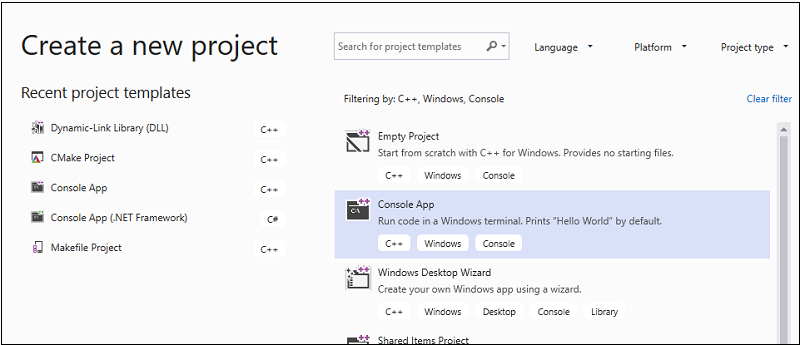
Choisissez le bouton Créer pour créer le projet client.
Pour créer l’exemple de projet dans Visual Studio 2017 ou Visual Studio 2015
Démarrez Visual Studio.
Dans la barre de menus, choisissez Fichier>Nouveau>Projet.
Sous Installé dans le volet modèles, choisissez Visual C++.
Choisissez Application console Win32, tapez
AMPMapReducela zone Nom , puis cliquez sur le bouton OK .Choisissez le bouton Suivant.
Désactivez la case à cocher En-tête précompilé, puis cliquez sur le bouton Terminer .
Dans Explorateur de solutions, supprimez stdafx.h, targetver.h et stdafx.cpp du projet.
Suivant :
Ouvrez AMPMapReduce.cpp et remplacez son contenu par le code suivant.
// AMPMapReduce.cpp defines the entry point for the program. // The program performs a parallel-sum reduction that computes the sum of an array of integers. #include <stdio.h> #include <tchar.h> #include <amp.h> const int BLOCK_DIM = 32; using namespace concurrency; void sum_kernel_tiled(tiled_index<BLOCK_DIM> t_idx, array<int, 1> &A, int stride_size) restrict(amp) { tile_static int localA[BLOCK_DIM]; index<1> globalIdx = t_idx.global * stride_size; index<1> localIdx = t_idx.local; localA[localIdx[0]] = A[globalIdx]; t_idx.barrier.wait(); // Aggregate all elements in one tile into the first element. for (int i = BLOCK_DIM / 2; i > 0; i /= 2) { if (localIdx[0] < i) { localA[localIdx[0]] += localA[localIdx[0] + i]; } t_idx.barrier.wait(); } if (localIdx[0] == 0) { A[globalIdx] = localA[0]; } } int size_after_padding(int n) { // The extent might have to be slightly bigger than num_stride to // be evenly divisible by BLOCK_DIM. You can do this by padding with zeros. // The calculation to do this is BLOCK_DIM * ceil(n / BLOCK_DIM) return ((n - 1) / BLOCK_DIM + 1) * BLOCK_DIM; } int reduction_sum_gpu_kernel(array<int, 1> input) { int len = input.extent[0]; //Tree-based reduction control that uses the CPU. for (int stride_size = 1; stride_size < len; stride_size *= BLOCK_DIM) { // Number of useful values in the array, given the current // stride size. int num_strides = len / stride_size; extent<1> e(size_after_padding(num_strides)); // The sum kernel that uses the GPU. parallel_for_each(extent<1>(e).tile<BLOCK_DIM>(), [&input, stride_size] (tiled_index<BLOCK_DIM> idx) restrict(amp) { sum_kernel_tiled(idx, input, stride_size); }); } array_view<int, 1> output = input.section(extent<1>(1)); return output[0]; } int cpu_sum(const std::vector<int> &arr) { int sum = 0; for (size_t i = 0; i < arr.size(); i++) { sum += arr[i]; } return sum; } std::vector<int> rand_vector(unsigned int size) { srand(2011); std::vector<int> vec(size); for (size_t i = 0; i < size; i++) { vec[i] = rand(); } return vec; } array<int, 1> vector_to_array(const std::vector<int> &vec) { array<int, 1> arr(vec.size()); copy(vec.begin(), vec.end(), arr); return arr; } int _tmain(int argc, _TCHAR* argv[]) { std::vector<int> vec = rand_vector(10000); array<int, 1> arr = vector_to_array(vec); int expected = cpu_sum(vec); int actual = reduction_sum_gpu_kernel(arr); bool passed = (expected == actual); if (!passed) { printf("Actual (GPU): %d, Expected (CPU): %d", actual, expected); } printf("sum: %s\n", passed ? "Passed!" : "Failed!"); getchar(); return 0; }Dans la barre de menus, sélectionnez Fichier>Enregistrer tout.
Dans Explorateur de solutions, ouvrez le menu contextuel pour AMPMapReduce, puis choisissez Propriétés.
Dans la boîte de dialogue Pages de propriétés, sous Propriétés de configuration, choisissez En-têtes précompilés C/C++>.
Pour la propriété Header précompilé, sélectionnez Not Using Precompiled Headers, puis choisissez le bouton OK .
Dans la barre de menus, choisissez Générer>Générer la solution.
Débogage du code processeur
Dans cette procédure, vous allez utiliser le débogueur Windows local pour vous assurer que le code processeur de cette application est correct. Le segment du code uc de cette application particulièrement intéressant est la for boucle de la reduction_sum_gpu_kernel fonction. Il contrôle la réduction parallèle basée sur l’arborescence exécutée sur le GPU.
Pour déboguer le code de l’UC
Dans Explorateur de solutions, ouvrez le menu contextuel pour AMPMapReduce, puis choisissez Propriétés.
Dans la boîte de dialogue Pages de propriétés, sous Propriétés de configuration, choisissez Débogage. Vérifiez que le débogueur Windows local est sélectionné dans le débogueur pour lancer la liste.
Revenez à l’éditeur de code.
Définissez des points d’arrêt sur les lignes de code indiquées dans l’illustration suivante (environ les lignes 67 ligne 70).

Points d'arrêt d'UCDans la barre de menus, choisissez Débogage>Démarrer le débogage.
Dans la fenêtre Locals , observez la valeur jusqu’à
stride_sizece que le point d’arrêt à la ligne 70 soit atteint.Dans la barre de menus, choisissez Débogage>Arrêter le débogage.
Débogage du code GPU
Cette section montre comment déboguer le code GPU, qui est le code contenu dans la sum_kernel_tiled fonction. Le code GPU calcule la somme des entiers pour chaque « bloc » en parallèle.
Pour déboguer le code GPU
Dans Explorateur de solutions, ouvrez le menu contextuel pour AMPMapReduce, puis choisissez Propriétés.
Dans la boîte de dialogue Pages de propriétés, sous Propriétés de configuration, choisissez Débogage.
Dans la liste Débogueur à lancer, sélectionnez Débogueur Windows local.
Dans la liste Type du débogueur, vérifiez que l’option Auto est sélectionnée.
Auto est la valeur par défaut. Dans les versions antérieures à Windows 10, gpu uniquement est la valeur requise au lieu d’Auto.
Cliquez sur le bouton OK.
Définissez un point d’arrêt à la ligne 30, comme illustré dans l’illustration suivante.

Point d’arrêt GPUDans la barre de menus, choisissez Débogage>Démarrer le débogage. Les points d’arrêt dans le code processeur aux lignes 67 et 70 ne sont pas exécutés pendant le débogage GPU, car ces lignes de code s’exécutent sur l’UC.
Pour utiliser la fenêtre Threads GPU
Pour ouvrir la fenêtre Threads GPU, dans la barre de menus, choisissez Déboguer>des threads GPU Windows.>
Vous pouvez inspecter l’état des threads GPU dans la fenêtre Threads GPU qui s’affiche.
Ancrez la fenêtre Threads GPU en bas de Visual Studio. Choisissez le bouton Développer le commutateur de thread pour afficher les zones de texte de vignette et de thread. La fenêtre Threads GPU affiche le nombre total de threads GPU actifs et bloqués, comme illustré dans l’illustration suivante.

Fenêtre Threads GPU313 vignettes sont allouées pour ce calcul. Chaque vignette contient 32 threads. Étant donné que le débogage GPU local se produit sur un émulateur de logiciel, il existe quatre threads GPU actifs. Les quatre threads exécutent les instructions simultanément, puis passent ensemble à l’instruction suivante.
Dans la fenêtre Threads GPU, il existe quatre threads GPU actifs et 28 threads GPU bloqués à l’instruction tile_barrier ::wait définie à environ la ligne 21 (
t_idx.barrier.wait();). Tous les 32 threads GPU appartiennent à la première vignette.tile[0]Une flèche pointe vers la ligne qui inclut le thread actuel. Pour basculer vers un autre thread, utilisez l’une des méthodes suivantes :Dans la ligne du thread à basculer vers la fenêtre Threads GPU, ouvrez le menu contextuel et choisissez Basculer vers le thread. Si la ligne représente plusieurs threads, vous basculez vers le premier thread en fonction des coordonnées du thread.
Entrez la vignette et les valeurs de thread du thread dans les zones de texte correspondantes, puis choisissez le bouton Changer de thread .
La fenêtre Pile des appels affiche la pile des appels du thread GPU actuel.
Pour utiliser la fenêtre Stacks parallèles
Pour ouvrir la fenêtre Stacks parallèles, dans la barre de menus, choisissez Déboguer>des piles parallèles Windows.>
Vous pouvez utiliser la fenêtre Stacks parallèles pour inspecter simultanément les trames de pile de plusieurs threads GPU.
Ancrez la fenêtre Stacks parallèles en bas de Visual Studio.
Assurez-vous que threads est sélectionné dans la liste dans le coin supérieur gauche. Dans l’illustration suivante, la fenêtre Stacks parallèles affiche une vue axée sur la pile des appels des threads GPU que vous avez vus dans la fenêtre Threads GPU.

Fenêtre Piles parallèles32 threads sont passés de
_kernel_stubl’instruction lambda dans l’appelparallel_for_eachde fonction, puis à lasum_kernel_tiledfonction, où la réduction parallèle se produit. 28 threads sur 32 ont progressé vers l’instruction et restent bloqués à latile_barrier::waitligne 22, tandis que les quatre autres threads restent actifs dans la fonction à lasum_kernel_tiledligne 30.Vous pouvez inspecter les propriétés d’un thread GPU. Ils sont disponibles dans la fenêtre Threads GPU dans l’info-bulle riche de la fenêtre Stacks parallèles . Pour les voir, pointez le pointeur sur le cadre de pile de
sum_kernel_tiled. L’illustration suivante montre l’info-bulle DataTip.
Info-bulle de thread GPUPour plus d’informations sur la fenêtre Piles parallèles , consultez Utilisation de la fenêtre Piles parallèles.
Pour utiliser la fenêtre Espion parallèle
Pour ouvrir la fenêtre Parallel Watch, dans la barre de menus, choisissez Déboguer>Windows>Parallel Watch Parallel Watch>1.
Vous pouvez utiliser la fenêtre Parallel Watch pour inspecter les valeurs d’une expression sur plusieurs threads.
Ancrez la fenêtre Parallel Watch 1 en bas de Visual Studio. Il existe 32 lignes dans la table de la fenêtre Parallel Watch . Chacun correspond à un thread GPU qui apparaît à la fois dans la fenêtre Threads GPU et la fenêtre Stacks parallèles . À présent, vous pouvez entrer des expressions dont vous souhaitez inspecter les 32 threads GPU.
Sélectionnez l’en-tête Ajouter une colonne Espion , entrez
localIdx, puis choisissez la touche Entrée .Sélectionnez à nouveau l’en-tête de colonne Ajouter une montre , tapez
globalIdx, puis choisissez la touche Entrée .Sélectionnez à nouveau l’en-tête de colonne Ajouter une montre , tapez
localA[localIdx[0]], puis choisissez la touche Entrée .Vous pouvez trier par une expression spécifiée en sélectionnant son en-tête de colonne correspondant.
Sélectionnez l’en-tête de colonne localA[0]] pour trier la colonne. L’illustration suivante montre les résultats du tri par localA[localIdx[0]].

Résultats du triVous pouvez exporter le contenu dans la fenêtre Espion parallèle vers Excel en choisissant le bouton Excel , puis en choisissant Ouvrir dans Excel. Si Excel est installé sur votre ordinateur de développement, le bouton ouvre une feuille de calcul Excel qui contient le contenu.
Dans le coin supérieur droit de la fenêtre Parallel Watch , il existe un contrôle de filtre que vous pouvez utiliser pour filtrer le contenu à l’aide d’expressions booléennes. Entrez
localA[localIdx[0]] > 20000dans la zone de texte du contrôle de filtre, puis choisissez la touche Entrée .La fenêtre contient désormais uniquement des threads sur lesquels la
localA[localIdx[0]]valeur est supérieure à 20000. Le contenu est toujours trié par lalocalA[localIdx[0]]colonne, qui est l’action de tri que vous avez choisie précédemment.
Marquage des threads GPU
Vous pouvez marquer des threads GPU spécifiques en les signalant dans la fenêtre Threads GPU, dans la fenêtre Espion parallèle ou dans la fenêtre DataTip dans la fenêtre Stacks parallèles. Si une ligne dans la fenêtre Threads GPU contient plusieurs threads, l’indicateur de cette ligne signale tous les threads contenus dans la ligne.
Pour marquer des threads GPU
Sélectionnez l’en-tête de colonne [Thread] dans la fenêtre Parallel Watch 1 pour trier par index de vignette et index de thread.
Dans la barre de menus, choisissez Déboguer>Continuer, ce qui entraîne la progression des quatre threads actifs vers la barrière suivante (défini à la ligne 32 de AMPMapReduce.cpp).
Choisissez le symbole d’indicateur sur le côté gauche de la ligne qui contient les quatre threads qui sont maintenant actifs.
L’illustration suivante montre les quatre threads avec indicateur actif dans la fenêtre Threads GPU.

Threads actifs dans la fenêtre Threads GPULa fenêtre Parallel Watch et l’info-bulle de la fenêtre Stacks parallèles indiquent les threads marqués.
Si vous souhaitez vous concentrer sur les quatre threads que vous avez marqués, vous pouvez choisir d’afficher uniquement les threads avec indicateur. Il limite ce que vous voyez dans les fenêtres Threads GPU, Parallel Watch et Parallel Stacks .
Choisissez le bouton Afficher avec indicateur uniquement sur l’une des fenêtres ou dans la barre d’outils Emplacement de débogage . L’illustration suivante montre le bouton Afficher uniquement avec indicateur dans la barre d’outils Emplacement de débogage.

Bouton Afficher uniquement avec indicateurÀ présent, les fenêtres Threads GPU, Parallel Watch et Parallel Stacks affichent uniquement les threads avec indicateur.
Gel et dégel des threads GPU
Vous pouvez figer (suspendre) et dégeler (reprendre) des threads GPU à partir de la fenêtre Threads GPU ou de la fenêtre Parallel Watch . Vous pouvez figer et dégeler les threads de processeur de la même façon ; pour plus d’informations, consultez Guide pratique pour utiliser la fenêtre Threads.
Pour figer et dégeler des threads GPU
Choisissez le bouton Afficher avec indicateur uniquement pour afficher tous les threads.
Dans la barre de menus, choisissez Déboguer>Continuer.
Ouvrez le menu contextuel de la ligne active, puis choisissez Figer.
L’illustration suivante de la fenêtre Threads GPU montre que les quatre threads sont figés.

Threads figés dans la fenêtre Threads GPUDe même, la fenêtre Parallel Watch indique que les quatre threads sont figés.
Dans la barre de menus, choisissez Debug>Continue to allow the next four GPU threads to progress past the barrier at line 22 and to reach the breakpoint at line 30. La fenêtre Threads GPU indique que les quatre threads précédemment gelés restent figés et dans l’état actif.
Dans la barre de menus, choisissez Déboguer, Continuer.
Dans la fenêtre Parallel Watch , vous pouvez également dégeler des threads GPU individuels ou multiples.
Pour regrouper des threads GPU
Dans le menu contextuel de l’un des threads de la fenêtre Threads GPU, choisissez Regrouper par, Adresse.
Les threads de la fenêtre Threads GPU sont regroupés par adresse. L’adresse correspond à l’instruction dans le désassemblement où se trouve chaque groupe de threads. 24 threads se trouvent à la ligne 22 où la méthode tile_barrier ::wait est exécutée. 12 threads sont à l’instruction de la barrière à la ligne 32. Quatre de ces threads sont marqués. Huit threads sont au point d’arrêt à la ligne 30. Quatre de ces threads sont figés. L’illustration suivante montre les threads groupés dans la fenêtre Threads GPU.

Threads groupés dans la fenêtre Threads GPUVous pouvez également effectuer l’opération Group By en ouvrant le menu contextuel de la grille de données de la fenêtre Espion parallèle. Sélectionnez Regrouper par, puis choisissez l’élément de menu qui correspond à la façon dont vous souhaitez regrouper les threads.
Exécution de tous les threads vers un emplacement spécifique dans le code
Vous exécutez tous les threads d’une vignette donnée sur la ligne qui contient le curseur à l’aide du curseur Exécuter la vignette active vers le curseur.
Pour exécuter tous les threads à l’emplacement marqué par le curseur
Dans le menu contextuel des threads figés, choisissez Thaw.
Dans l’Éditeur de code, placez le curseur à la ligne 30.
Dans le menu contextuel de l’Éditeur de code, choisissez Exécuter la vignette active vers le curseur.
Les 24 threads qui étaient précédemment bloqués à la barrière à la ligne 21 ont progressé jusqu’à la ligne 32. Il s’affiche dans la fenêtre Threads GPU.
Voir aussi
Vue d’ensemble de L’AMP C++
Débogage du code GPU
Guide pratique pour utiliser la fenêtre Threads GPU
Guide pratique pour utiliser la fenêtre Espion parallèle
Analyse du code AMP C++ avec le visualiseur concurrentiel