Recommandations en matière de réponse aux incidents de sécurité
S’applique à la recommandation de la liste de contrôle de sécurité d’Azure Well-Architected Framework :
| SE :12 | Définissez et testez des procédures efficaces de réponse aux incidents qui couvrent un éventail d’incidents, des problèmes localisés à la récupération d’urgence. Définissez clairement l’équipe ou l’individu qui exécute une procédure. |
|---|
Ce guide décrit les recommandations relatives à l’implémentation d’une réponse aux incidents de sécurité pour une charge de travail. En cas de compromission de sécurité pour un système, une approche systématique de réponse aux incidents permet de réduire le temps nécessaire pour identifier, gérer et atténuer les incidents de sécurité. Ces incidents peuvent menacer la confidentialité, l’intégrité et la disponibilité des systèmes logiciels et des données.
La plupart des entreprises ont une équipe centrale d’opérations de sécurité (également appelée Security Operations Center (SOC) ou SecOps. La responsabilité de l’équipe chargée de l’opération de sécurité est de détecter, hiérarchiser et trier rapidement les attaques potentielles. L’équipe surveille également les données de télémétrie liées à la sécurité et examine les violations de sécurité.
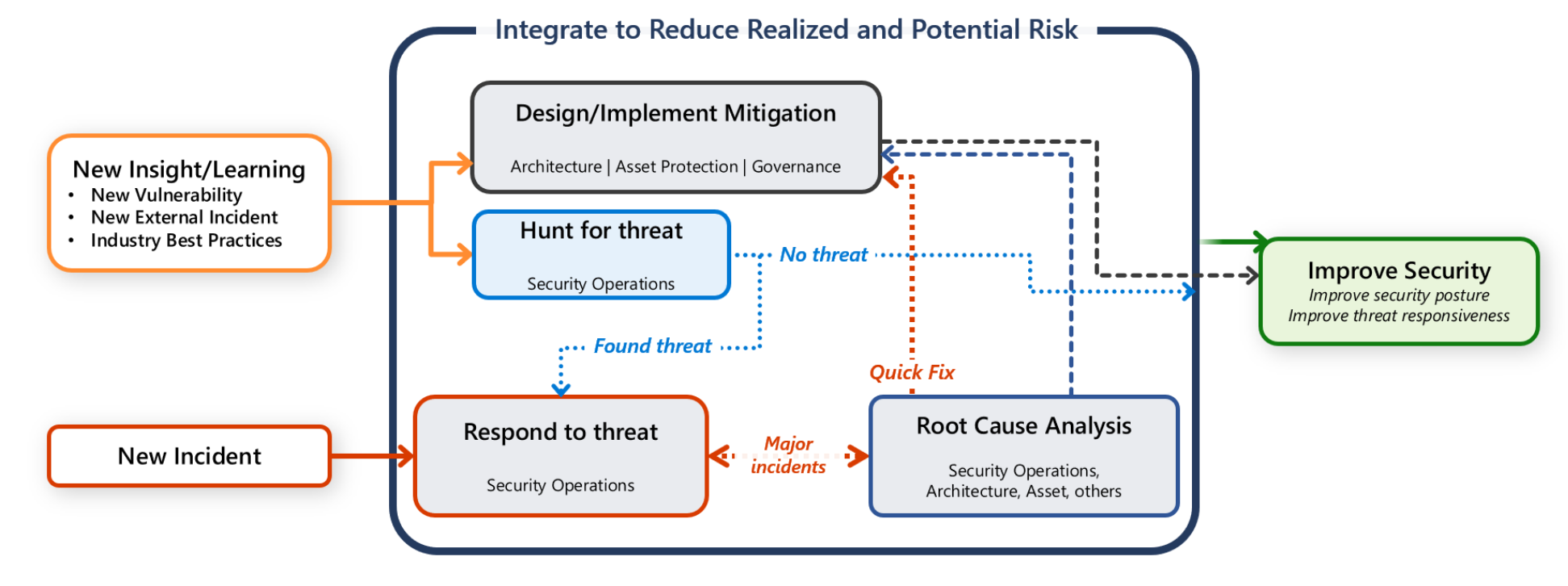
Toutefois, vous avez également la responsabilité de protéger votre charge de travail. Il est important que toutes les activités de communication, d’investigation et de chasse soient un effort collaboratif entre l’équipe de charge de travail et l’équipe SecOps.
Ce guide fournit des recommandations pour vous et votre équipe de charge de travail pour vous aider à détecter, trier et examiner rapidement les attaques.
Définitions
| Terme | Définition |
|---|---|
| Alerte | Notification qui contient des informations sur un incident. |
| Fidélité des alertes | Précision des données qui déterminent une alerte. Les alertes haute fidélité contiennent le contexte de sécurité nécessaire pour effectuer des actions immédiates. Les alertes à faible fidélité ne contiennent pas d’informations ou contiennent du bruit. |
| Faux positif | Alerte qui indique un incident qui n’a pas eu lieu. |
| Incident | Événement qui indique un accès non autorisé à un système. |
| Réponse aux incidents | Processus qui détecte, répond et atténue les risques associés à un incident. |
| Tri | Opération de réponse aux incidents qui analyse les problèmes de sécurité et hiérarchise leur atténuation. |
Stratégies de conception
Vous et votre équipe effectuez des opérations de réponse aux incidents lorsqu’il existe un signal ou une alerte pour une compromission potentielle. Les alertes haute fidélité contiennent un contexte de sécurité suffisant qui facilite la prise de décisions par les analystes. Les alertes haute fidélité entraînent un faible nombre de faux positifs. Ce guide suppose qu’un système d’alerte filtre les signaux à faible fidélité et se concentre sur les alertes haute fidélité susceptibles d’indiquer un incident réel.
Désigner des contacts de notification d’incident
Les alertes de sécurité doivent atteindre les personnes appropriées de votre équipe et de votre organisation. Établissez un point de contact désigné sur votre équipe de charge de travail pour recevoir des notifications d’incident. Ces notifications doivent inclure autant d’informations que possible sur la ressource compromise et le système. L’alerte doit inclure les étapes suivantes afin que votre équipe puisse accélérer les actions.
Nous vous recommandons de consigner et de gérer les notifications d’incident et les actions à l’aide d’outils spécialisés qui conservent une piste d’audit. En utilisant des outils standard, vous pouvez conserver les preuves qui peuvent être requises pour les enquêtes juridiques potentielles. Recherchez les opportunités d’implémenter l’automatisation qui peut envoyer des notifications en fonction des responsabilités des parties responsables. Gardez une chaîne claire de communication et de création de rapports pendant un incident.
Tirez parti des solutions SIEM (Security Information Event Management) et des solutions de réponse automatisée de l’orchestration de la sécurité (SOAR) fournies par votre organisation. Vous pouvez également obtenir des outils de gestion des incidents et encourager votre organisation à les normaliser pour toutes les équipes de charge de travail.
Examiner avec une équipe de triage
Le membre de l’équipe qui reçoit une notification d’incident est chargé de configurer un processus de triage qui implique les personnes appropriées en fonction des données disponibles. L’équipe de triage, souvent appelée équipe de pont, doit s’entendre sur le mode et le processus de communication. Cet incident nécessite-t-il des discussions asynchrones ou des appels de pont ? Comment l’équipe doit-elle suivre et communiquer les progrès des enquêtes ? Où l’équipe peut-elle accéder aux ressources d’incident ?
La réponse aux incidents est une raison cruciale pour maintenir la documentation à jour, comme la disposition architecturale du système, les informations au niveau du composant, la confidentialité ou la classification de sécurité, les propriétaires et les points de contact clés. Si les informations sont inexactes ou obsolètes, l’équipe de pont perd du temps précieux pour essayer de comprendre le fonctionnement du système, qui est responsable de chaque zone et quel est l’effet de l’événement.
Pour d’autres enquêtes, impliquez les personnes appropriées. Vous pouvez inclure un responsable des incidents, un agent de sécurité ou des prospects centrés sur la charge de travail. Pour garder le triage ciblé, excluez les personnes qui ne sont pas au-delà de l’étendue du problème. Parfois, des équipes distinctes examinent l’incident. Il peut y avoir une équipe qui examine initialement le problème et tente d’atténuer l’incident, ainsi qu’une autre équipe spécialisée susceptible d’effectuer une enquête approfondie afin de déterminer les grands problèmes. Vous pouvez mettre en quarantaine l’environnement de charge de travail pour permettre à l’équipe d’investigation d’effectuer leurs enquêtes. Dans certains cas, la même équipe peut gérer toute l’enquête.
Dans la phase initiale, l’équipe de triage est chargée de déterminer le vecteur potentiel et son effet sur la confidentialité, l’intégrité et la disponibilité (également appelée CIA) du système.
Dans les catégories de la CIA, attribuez un niveau de gravité initial qui indique la profondeur des dommages et l’urgence de la correction. Ce niveau devrait changer au fil du temps, car plus d’informations sont découvertes dans les niveaux de triage.
Dans la phase de découverte, il est important de déterminer un cours immédiat d’action et de communication. Existe-t-il des modifications apportées à l’état d’exécution du système ? Comment l’attaque peut-elle être contenue pour arrêter d’autres exploitations ? L’équipe doit-elle envoyer une communication interne ou externe, telle qu’une divulgation responsable ? Envisagez la détection et le temps de réponse. Vous serez peut-être légalement obligé de signaler certains types de violations à une autorité réglementaire dans un délai spécifique, ce qui est souvent des heures ou des jours.
Si vous décidez d’arrêter le système, les étapes suivantes mènent au processus de récupération d’urgence de la charge de travail.
Si vous n’arrêtez pas le système, déterminez comment corriger l’incident sans affecter les fonctionnalités du système.
Récupérer à partir d’un incident
Traitez un incident de sécurité comme un sinistre. Si la correction nécessite une récupération complète, utilisez des mécanismes de récupération d’urgence appropriés du point de vue de la sécurité. Le processus de récupération doit empêcher la périodicité. Sinon, la récupération à partir d’une sauvegarde endommagée réintroduit le problème. Le redéploiement d’un système avec la même vulnérabilité entraîne le même incident. Valider les étapes et processus de basculement et de restauration automatique.
Si le système reste opérationnel, évaluez l’effet sur les parties en cours d’exécution du système. Continuez à surveiller le système pour vous assurer que d’autres cibles de fiabilité et de performances sont respectées ou réajustées en implémentant des processus de dégradation appropriés. Ne pas compromettre la confidentialité en raison de l’atténuation.
Le diagnostic est un processus interactif jusqu’à ce que le vecteur, et un correctif potentiel et un secours, soit identifié. Après le diagnostic, l’équipe travaille sur la correction, qui identifie et applique le correctif requis dans un délai acceptable.
Les métriques de récupération mesurent le temps nécessaire pour résoudre un problème. En cas d’arrêt, il peut y avoir une urgence concernant les temps de correction. Pour stabiliser le système, il faut du temps pour appliquer des correctifs, des correctifs et des tests, et déployer des mises à jour. Déterminez les stratégies d’isolement pour éviter d’autres dommages et la propagation de l’incident. Développez des procédures d’éradication pour éliminer complètement la menace de l’environnement.
Compromis : Il existe un compromis entre les objectifs de fiabilité et les temps de correction. Pendant un incident, il est probable que vous ne répondiez pas à d’autres exigences non fonctionnelles ou fonctionnelles. Par exemple, vous devrez peut-être désactiver des parties de votre système pendant que vous examinez l’incident, ou vous devrez peut-être même mettre tout le système hors connexion jusqu’à ce que vous déterminiez l’étendue de l’incident. Les décideurs d’entreprise doivent décider explicitement quels sont les cibles acceptables pendant l’incident. Spécifiez clairement la personne responsable de cette décision.
Découvrir à partir d’un incident
Un incident détecte des lacunes ou des points vulnérables dans une conception ou une implémentation. Il s’agit d’une opportunité d’amélioration qui est pilotée par des leçons sur les aspects de conception technique, l’automatisation, les processus de développement de produits qui incluent les tests et l’efficacité du processus de réponse aux incidents. Conservez des enregistrements d’incident détaillés, notamment les actions effectuées, les chronologies et les résultats.
Nous vous recommandons vivement d’effectuer des révisions post-incident structurées, telles que l’analyse de la cause racine et les rétrospectives. Suivez et hiérarchisez les résultats de ces révisions et envisagez d’utiliser ce que vous apprenez dans les futures conceptions de charge de travail.
Les plans d’amélioration doivent inclure des mises à jour des exercices de sécurité et des tests, comme les exercices de continuité d’activité et de reprise d’activité (BCDR). Utilisez la compromission de sécurité comme scénario pour effectuer une extraction BCDR. Les exercices peuvent valider le fonctionnement des processus documentés. Il ne doit pas y avoir plusieurs playbooks de réponse aux incidents. Utilisez une seule source que vous pouvez ajuster en fonction de la taille de l’incident et de l’étendue ou de la localisation de l’effet. Les exercices sont basés sur des situations hypothétiques. Effectuer des exercices dans un environnement à faible risque et inclure la phase d’apprentissage dans les exercices.
Effectuez des examens post-incidents, ou postmortems, afin d’identifier les faiblesses du processus de réponse et des domaines d’amélioration. En fonction des leçons que vous tirez de l’incident, mettez à jour le plan de réponse aux incidents (IRP) et les contrôles de sécurité.
Définir un plan de communication
Implémentez un plan de communication pour informer les utilisateurs d’une interruption et informer les parties prenantes internes de la correction et des améliorations. D’autres personnes de votre organisation doivent être averties des modifications apportées à la base de référence de sécurité de la charge de travail pour éviter les incidents futurs.
Générez des rapports d’incident pour une utilisation interne et, si nécessaire, à des fins réglementaires ou légales. En outre, adoptez un rapport de format standard (un modèle de document avec des sections définies) que l’équipe SOC utilise pour tous les incidents. Assurez-vous que chaque incident a un rapport associé à celui-ci avant de fermer l’enquête.
Facilitation Azure
Microsoft Sentinel est une solution SIEM et SOAR. Il s’agit d’une solution unique pour la détection des alertes, la visibilité des menaces, la chasse proactive et la réponse aux menaces. Pour plus d’informations, consultez Présentation de Microsoft Sentinel
Vérifiez que le portail d’inscription Azure inclut des informations de contact d’administrateur afin que les opérations de sécurité puissent être averties directement via un processus interne. Pour plus d’informations, consultez Mettre à jour les paramètres de notification.
Pour en savoir plus sur l’établissement d’un point de contact désigné qui reçoit des notifications d’incident Azure à partir de Microsoft Defender pour le cloud, consultez Configurer Notifications par e-mail pour les alertes de sécurité.
Alignement organisationnel
Cloud Adoption Framework pour Azure fournit des conseils sur la planification de la réponse aux incidents et les opérations de sécurité. Pour plus d’informations, consultez Opérations de sécurité.
Liens connexes
- Créer automatiquement des incidents à partir d’alertes de sécurité Microsoft
- Effectuer une chasse aux menaces de bout en bout à l’aide de la fonctionnalité de chasse
- Configurer Notifications par e-mail pour les alertes de sécurité
- Vue d’ensemble des réponse aux incidents
- Préparation aux incidents Microsoft Azure
- Naviguer et examiner les incidents dans Microsoft Sentinel
- Contrôle de sécurité : réponse aux incidents
- Solutions SOAR dans Microsoft Sentinel
- Formation : Présentation de la préparation aux incidents Azure
- Mettre à jour les paramètres de notification Portail Azure
- Qu’est-ce qu’un SOC ?
- Qu’est-ce que Microsoft Sentinel ?
Liste de contrôle de sécurité
Reportez-vous à l’ensemble complet de recommandations.