IA responsable dans les charges de travail Azure
L’objectif de l’IA responsable dans la conception de la charge de travail est de s’assurer que l’utilisation des algorithmes d’IA est équitable, transparente et inclusive. Les principes de sécurité bien conçus sont liés à une attention particulière à la confidentialité et à l’intégrité. Les mesures de sécurité doivent être en place pour maintenir la confidentialité des utilisateurs, protéger les données et protéger l’intégrité de la conception, qui ne doivent pas être utilisées à des fins inattendues.
Dans les charges de travail IA, les décisions sont prises par des modèles qui utilisent souvent une logique opaque. Les utilisateurs doivent faire confiance aux fonctionnalités du système et se sentir confiants que les décisions sont prises de manière responsable. Les comportements non éthiques, tels que la manipulation, la toxicité du contenu, l’atteinte aux adresses IP et les réponses fabriquées, doivent être évités.
Considérez un cas d’usage où une société de divertissement multimédia souhaite fournir des recommandations à l’aide de modèles IA. L’échec de l’implémentation de l’IA responsable et de la sécurité appropriée peut entraîner un mauvais acteur prenant le contrôle des modèles. Le modèle peut éventuellement recommander du contenu multimédia qui peut entraîner des résultats nocifs. Pour l’organisation, ce comportement peut entraîner des dommages de marque, des environnements dangereux et des problèmes juridiques. Par conséquent, maintenir la vigilance éthique tout au long du cycle de vie du système est essentiel et non remboursable.
Les décisions éthiques doivent hiérarchiser la gestion de la sécurité et des charges de travail avec des résultats humains à l’esprit. Familiarisez-vous avec le framework d’IA responsable de Microsoft et assurez-vous que les principes sont reflétés et mesurés dans votre conception. Cette image montre les concepts fondamentaux de l’infrastructure.
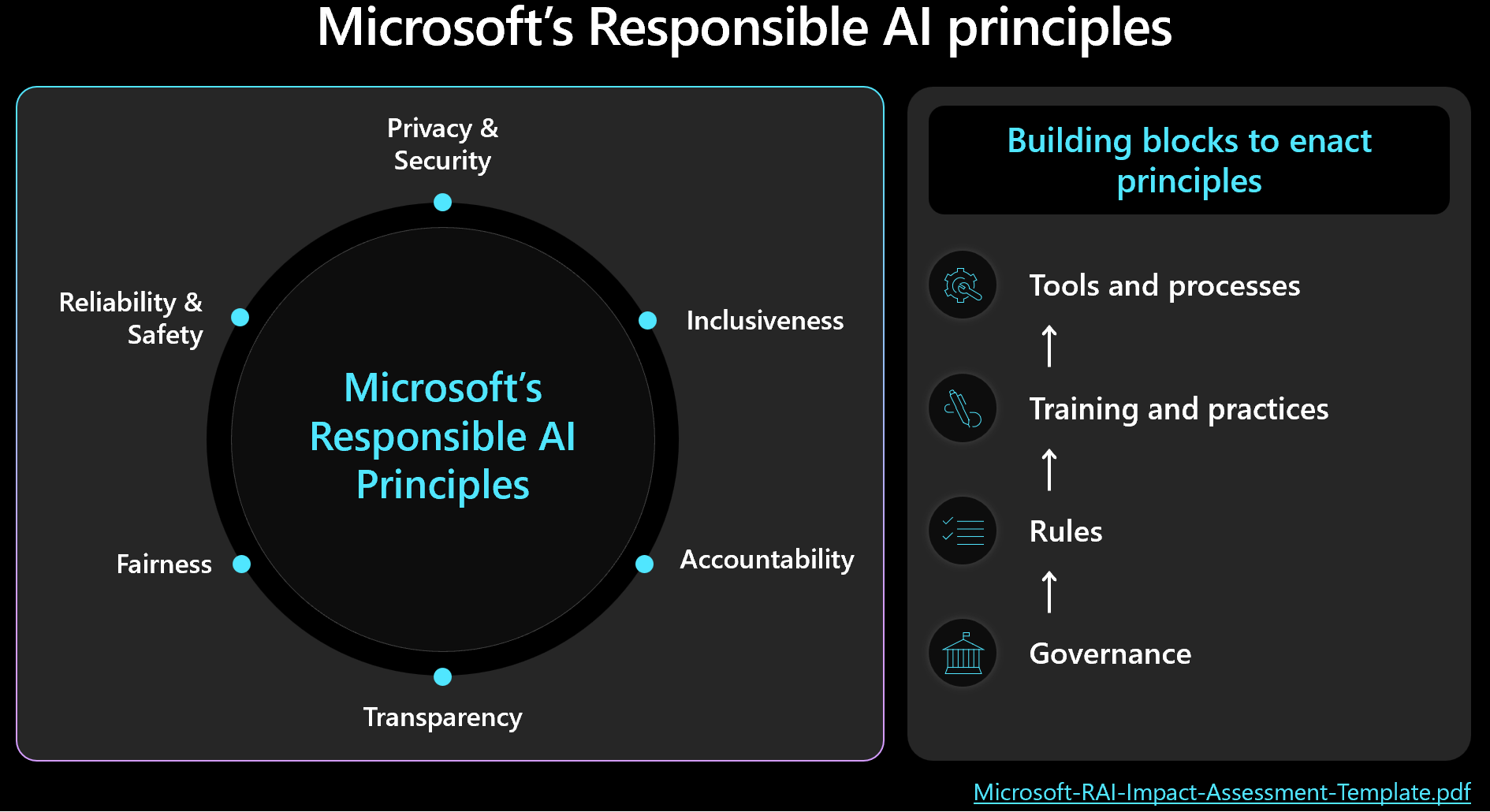
Important
La précision des métriques de prédiction et d’IA responsable est souvent interconnectée. L’amélioration de la précision d’un modèle peut améliorer son équité et son alignement avec la réalité. Toutefois, bien que l’IA éthique s’aligne fréquemment sur la précision, la précision seule n’inclut pas toutes les considérations éthiques. Il est essentiel de valider ces principes éthiques de manière responsable.
Cet article fournit des recommandations sur la prise de décision éthique, la validation des entrées utilisateur et la garantie d’une expérience utilisateur sécurisée. Il fournit également des conseils sur la sécurité des données pour vous assurer que les données utilisateur sont protégées.
Recommandations
Voici le résumé des recommandations fournies dans cet article.
| Recommandation | Description |
|---|---|
| Développez des politiques qui appliquent des pratiques éthiques à chaque étape du cycle de vie. | Incluez des éléments de liste de contrôle qui indiquent explicitement les exigences éthiques, adaptées au contexte de charge de travail. Par exemple, la transparence des données utilisateur, la configuration du consentement et les procédures de gestion du « Droit d’être oublié ». ▪ Développer vos stratégies d’IA responsable ▪ Appliquer la gouvernance sur les stratégies d’IA responsable |
| Protégez les données utilisateur avec l’objectif d’optimiser la confidentialité. | Collectez uniquement ce qui est nécessaire et avec le consentement de l’utilisateur approprié. Appliquez des contrôles techniques pour protéger les profils utilisateur, leurs données et l’accès à ces données. ▪ Gérer les données utilisateur de manière éthique ▪ Inspecter les données entrantes et sortantes |
| Gardez les décisions d’IA claires et compréhensibles. | Conservez des explications claires sur le fonctionnement des algorithmes de recommandation et offrez aux utilisateurs des insights sur l’utilisation des données et la prise de décision algorithmique pour s’assurer qu’ils comprennent et approuvent le processus. ▪ Sécuriser l’expérience utilisateur |
Développer des stratégies d’IA responsable
Documentez votre approche de l’utilisation éthique et responsable de l’IA. Les stratégies d’état explicitement appliquées à chaque étape du cycle de vie afin que l’équipe de charge de travail comprenne ses responsabilités. Bien que les normes d’IA responsable de Microsoft fournissent des instructions, vous devez définir ce que cela signifie spécifiquement pour votre contexte.
Par exemple, les stratégies doivent inclure des éléments de liste de contrôle pour les mécanismes relatifs à la transparence des données utilisateur et à la configuration du consentement, ce qui permet idéalement aux utilisateurs de refuser l’inclusion des données. Les pipelines de données, l’analyse, l’entraînement du modèle et d’autres étapes doivent tous respecter ce choix. Un autre exemple est la gestion du « Droit d’être oublié ». Consultez le service d’éthique de votre organisation et l’équipe juridique pour prendre des décisions éclairées.
Créez des stratégies transparentes autour de l’utilisation des données et de la prise de décision algorithmique pour vous assurer que les utilisateurs comprennent et approuvent le processus. Documentez ces décisions pour conserver un historique clair pour les litiges futurs potentiels.
L’implémentation de l’IA éthique implique trois rôles clés : l’équipe de recherche, l’équipe de stratégie et l’équipe d’ingénierie. La collaboration entre ces équipes doit être opérationnelle. Si votre organisation dispose d’une équipe existante, tirez parti de leur travail ; sinon, établissez vous-même ces pratiques.
Avoir des responsabilités sur la séparation des tâches :
L’équipe de recherche effectue une découverte des risques en consultant des directives organisationnelles, des normes industrielles, des lois, des réglementations et des tactiques d’équipe rouges connues.
L’équipe de stratégie développe des stratégies spécifiques à la charge de travail, en incorporant des directives de l’organisation parente et des réglementations gouvernementales.
L’équipe d’ingénierie implémente les stratégies dans leurs processus et livrables, en s’assurant qu’elles valident et testent l’adhésion.
Chaque équipe formalise ses directives, mais l’équipe de charge de travail doit être responsable de ses propres pratiques documentées. L’équipe doit clairement documenter les étapes supplémentaires ou les écarts intentionnels, en s’assurant qu’il n’y a aucune ambiguïté quant à ce qui est autorisé. En outre, soyez transparent sur les lacunes potentielles ou les résultats inattendus dans la solution.
Appliquer la gouvernance sur les stratégies d’IA responsable
Concevez votre charge de travail pour vous conformer à la gouvernance organisationnelle et réglementaire. Par exemple, si la transparence est une exigence organisationnelle, déterminez comment elle s’applique à votre charge de travail. Identifiez les domaines de votre conception, cycle de vie, code ou d’autres composants, où les fonctionnalités de transparence doivent être introduites pour répondre à cette norme.
Comprendre les mandats de gouvernance, de responsabilité, de révision et de création de rapports requis. Assurez-vous que les conceptions de charge de travail sont approuvées et signées par votre conseil de gouvernance pour éviter les refontes et atténuer les préoccupations éthiques ou de confidentialité. Vous devrez peut-être parcourir plusieurs couches d’approbation. Voici une structure classique pour la gouvernance.
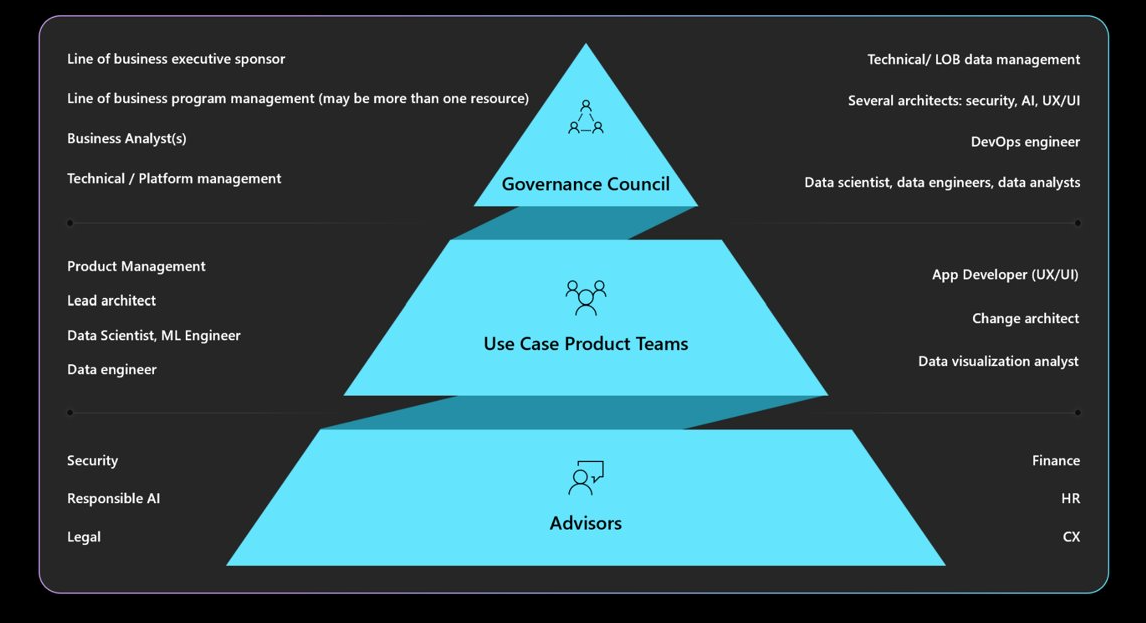
Pour plus d’informations sur les stratégies d’organisation et les approbateurs, consultez Cloud Adoption Framework : Définir une stratégie d’IA responsable.
Sécuriser l’expérience utilisateur
Les expériences utilisateur doivent être basées sur les instructions du secteur. Tirez parti de la bibliothèque de conception d’expériences Microsoft Human-AI qui inclut des principes et fournit des implémentations et ne le font pas, avec des exemples de produits Microsoft et d’autres sources du secteur.
Il existe des responsabilités de charge de travail tout au long du cycle de vie de l’interaction utilisateur à partir de l’intention de l’utilisateur d’utiliser le système, pendant une session et des interruptions en raison d’erreurs système. Voici quelques pratiques à prendre en compte :
Générez la transparence. Faites en sorte que les utilisateurs sachent comment le système a généré la réponse à leur requête.
Incluez des liens vers des sources de données consultées par le modèle pour améliorer la confiance des utilisateurs en affichant les origines des informations. La conception des données doit s’assurer que ces sources sont incluses dans les métadonnées. Lorsque l’orchestrateur dans une application augmentée de récupération effectue une recherche, il récupère, par exemple, 20 blocs de document et envoie les 10 premiers blocs, appartenant à trois documents différents, au modèle en tant que contexte. L’interface utilisateur peut ensuite référencer ces trois documents sources lors de l’affichage de la réponse du modèle, ce qui améliore la transparence et la confiance des utilisateurs.
La transparence devient plus importante lors de l’utilisation d’agents, qui agissent en tant qu’intermédiaires entre les interfaces front-end et les systèmes back-end. Par exemple, dans un système de tickets, le code d’orchestration interprète l’intention de l’utilisateur et effectue des appels d’API aux agents pour récupérer les informations nécessaires. L’exposition de ces interactions peut rendre l’utilisateur conscient des actions du système.
Pour les workflows automatisés avec plusieurs agents impliqués, créez des fichiers journaux qui enregistrent chaque étape. Cette fonctionnalité permet d’identifier et de corriger les erreurs. En outre, il peut fournir aux utilisateurs des explications sur les décisions, ce qui opérationnalise la transparence.
Attention
Lors de l’implémentation de recommandations de transparence, évitez d’accablant l’utilisateur avec trop d’informations. Utilisez une approche progressive, où vous commencez par des méthodes d’interface utilisateur minimalement perturbatrices.
Par exemple, affichez une info-bulle avec un score de confiance à partir du modèle. Vous pouvez incorporer un lien que les utilisateurs peuvent cliquer pour obtenir plus de détails, tels que des liens vers des documents sources. Cette méthode initiée par l’utilisateur conserve l’interface utilisateur non perturbatrice et permet aux utilisateurs de rechercher des informations supplémentaires uniquement s’ils choisissent de le faire.
Recueillir des commentaires. Implémenter des mécanismes de retour d’expérience.
Évitez d’accabler les utilisateurs avec des questionnaires complets après chaque réponse. Au lieu de cela, utilisez des mécanismes de commentaires rapides simples comme les pouces vers le haut/bas ou les systèmes d’évaluation pour des aspects spécifiques de la réponse sur une échelle de 1 à 5. Cette méthode permet un retour précis sans être intrusif, ce qui permet d’améliorer le système au fil du temps. Gardez à l’esprit les préjugés potentiels dans les commentaires, car il peut y avoir des raisons secondaires derrière les réponses des utilisateurs.
L’implémentation d’un mécanisme de commentaires affecte l’architecture en raison de la nécessité de stockage des données. Traitez-le en tant que données utilisateur et appliquez des niveaux de contrôle de confidentialité, selon les besoins.
En plus des commentaires de réponse, collectez des commentaires sur l’efficacité de l’expérience utilisateur. Pour ce faire, collectez des métriques d’engagement par le biais de votre pile de surveillance du système.
Opérationnaliser les mesures de sécurité du contenu
Intégrez la sécurité du contenu à chaque étape du cycle de vie de l’IA à l’aide de code de solution personnalisé, d’outils appropriés et de pratiques de sécurité efficaces. Voici quelques stratégies.
Anonymisation des données. À mesure que les données passent de l’ingestion à l’entraînement ou à l’évaluation, les contrôles permettent de réduire le risque de fuite d’informations personnelles et d’éviter l’exposition des données utilisateur brutes.
Con mode tente ration. Utilisez l’API de sécurité du contenu qui évalue les demandes et les réponses en temps réel et vérifiez que ces API sont accessibles.
Identifier et atténuer les menaces. Appliquez des pratiques de sécurité connues à vos scénarios IA. Par exemple, effectuez la modélisation des menaces et documentez les menaces et leur atténuation. Les pratiques de sécurité courantes telles que les exercices Red Team s’appliquent aux charges de travail IA. Les équipes rouges peuvent tester si les modèles peuvent être manipulés pour générer du contenu dangereux. Ces activités doivent être intégrées aux opérations IA.
Pour plus d’informations sur la réalisation de tests d’équipe rouge, consultez Planification de l’association rouge pour les modèles de langage volumineux (LLM) et leurs applications.
Utilisez les mesures appropriées. Utilisez les métriques appropriées qui sont efficaces pour mesurer le comportement éthique du modèle. Les métriques varient en fonction du type de modèle IA. La mesure des modèles génératifs peut ne pas s’appliquer aux modèles de régression. Considérez un modèle qui prédit l’espérance de vie et les résultats impactent les taux d’assurance. Le biais dans ce modèle peut entraîner des problèmes éthiques, mais ce problème provient de l’écart dans les tests de métriques de base. L’amélioration de la précision peut réduire les problèmes éthiques, car les métriques éthiques et de précision sont souvent interconnectées.
Ajouter une instrumentation éthique. Les résultats du modèle IA doivent être expliqués. Vous devez justifier et tracer la façon dont les inférences sont effectuées, y compris les données utilisées pour l’entraînement, les fonctionnalités calculées et les données de base. Dans l’IA discriminatoire, vous pouvez justifier les décisions pas à pas. Toutefois, pour les modèles génératifs, l’explication des résultats peut être complexe. Documentez le processus décisionnel pour répondre aux implications juridiques potentielles et assurer la transparence.
Cet aspect d’explication doit être implémenté tout au long du cycle de vie de l’IA. Le nettoyage, la traçabilité, les critères de sélection et le traitement des données sont des étapes critiques où les décisions doivent être suivies.
Outils
Les outils de sécurité du contenu et de traçabilité des données, comme Microsoft Purview, doivent être intégrés. Les API Azure AI Content Safety peuvent être appelées à partir de vos tests pour faciliter les tests de sécurité du contenu.
Azure AI Foundry fournit des métriques qui évaluent le comportement du modèle. Pour plus d’informations, consultez Évaluation et surveillance des métriques pour l’IA générative.
Pour les modèles d’apprentissage, nous vous recommandons d’examiner les métriques fournies par Azure Machine Learning.
Inspecter les données entrantes et sortantes
Les attaques par injection rapide, telles que le jailbreakage, sont un problème courant pour les charges de travail IA. Dans ce cas, certains utilisateurs peuvent tenter d’utiliser le modèle à des fins inattendues. Pour garantir la sécurité, inspectez les données pour empêcher les attaques et filtrer le contenu inapproprié. Cette analyse doit être appliquée à l’entrée de l’utilisateur et aux réponses du système pour s’assurer qu’il existe une con mode tente ration complète dans les flux entrants et sortants.
Dans les scénarios où vous effectuez plusieurs appels de modèle, comme par le biais d’Azure OpenAI, pour traiter une requête client unique, l’application de contrôles de sécurité de contenu à chaque appel peut être coûteuse et inutile. Envisagez de centraliser ce travail dans l’architecture tout en conservant la sécurité en tant que responsabilité côté serveur. Supposons qu’une architecture dispose d’une passerelle devant le point de terminaison d’inférence du modèle pour décharger certaines fonctionnalités back-end. Cette passerelle peut être conçue pour gérer les vérifications de sécurité du contenu pour les demandes et les réponses que le back-end peut ne pas prendre en charge en mode natif. Bien qu’une passerelle soit une solution courante, une couche d’orchestration peut gérer ces tâches efficacement dans des architectures plus simples. Dans les deux cas, vous pouvez appliquer ces vérifications de manière sélective si nécessaire, en optimisant les performances et les coûts.
Les inspections doivent être modales, couvrant différents formats. Lorsque vous utilisez des entrées modales, telles que des images, il est important de les analyser pour les messages masqués susceptibles d’être dangereux ou violents. Ces messages peuvent ne pas être immédiatement visibles, similaires à l’encre invisible et exiger une inspection minutieuse. Utilisez des outils tels que les API Content Safety à cet effet.
Pour appliquer des stratégies de confidentialité et de sécurité des données, inspectez les données utilisateur et placez les données de base pour la conformité aux réglementations en matière de confidentialité. Assurez-vous que les données sont nettoyées ou filtrées au fur et à mesure qu’elles transitent par le système. Par exemple, les données des conversations précédentes du support client peuvent servir de données de base. Elle doit être nettoyée avant la réutilisation.
Gérer les données utilisateur de manière éthique
Les pratiques éthiques impliquent une gestion minutieuse de la gestion des données utilisateur. Cela inclut la connaissance du moment où utiliser des données et quand éviter de s’appuyer sur des données utilisateur.
Inférence sans partager les données utilisateur. Pour partager en toute sécurité des données utilisateur avec d’autres organisations pour obtenir des insights, utilisez un modèle de centre d’échange. Dans ce scénario, les organisations fournissent des données à un tiers approuvé, qui entraîne un modèle à l’aide des données agrégées. Ce modèle peut ensuite être utilisé par toutes les institutions, ce qui permet des insights partagés sans exposer des jeux de données individuels. L’objectif est d’utiliser les fonctionnalités d’inférence du modèle sans partager de données d’apprentissage détaillées.
Promouvoir la diversité et l’inclusivité. Lorsque des données utilisateur sont nécessaires, utilisez une variété de données, y compris des genres et des créateurs sous-représentés, pour réduire le biais. Implémentez des fonctionnalités qui encouragent les utilisateurs à explorer du contenu nouveau et varié. Effectuez une surveillance continue de l’utilisation et ajustez les recommandations pour éviter tout type de contenu unique.
Respectez le « Droit d’être oublié ». Évitez d’utiliser des données utilisateur, dans la mesure du possible. Assurez-vous que la conformité avec le « Droit d’être oublié » en ayant des mesures nécessaires en place pour vous assurer que les données utilisateur sont supprimées avec diligence.
Pour garantir la conformité, il peut y avoir des demandes de suppression des données utilisateur du système. Pour les modèles plus petits, cela peut être obtenu en réentraînant avec des données qui excluent les informations personnelles. Pour les modèles plus volumineux, qui peuvent se composer de plusieurs modèles formés de manière indépendante, le processus est plus complexe et le coût et l’effort sont importants. Recherchez des conseils juridiques et éthiques sur la gestion de ces situations et assurez-vous que cela est inclus dans votre stratégie d’IA responsable, décrite dans Développer des stratégies d’IA responsable.
Conserver de manière responsable. Lorsque la suppression des données n’est pas possible, obtenez le consentement explicite de l’utilisateur pour la collecte de données et fournissez des stratégies de confidentialité claires. Collectez et conservez des données uniquement si nécessaire. Disposer d’opérations en place pour supprimer les données de manière agressive lorsqu’elles ne sont plus nécessaires. Par exemple, effacez l’historique des conversations dès que possible et anonymisez les données sensibles avant la rétention. Assurez-vous que les méthodes de chiffrement avancées sont utilisées pour ces données au repos.
Expliquer la prise en charge. Tracez les décisions dans le système pour prendre en charge les exigences d’explication. Développez des explications claires sur le fonctionnement des algorithmes de recommandation, en offrant aux utilisateurs des insights sur la raison pour laquelle un contenu spécifique est recommandé. L’objectif est de s’assurer que les charges de travail ia et leurs résultats sont transparents et justifiables, en détaillant la façon dont les décisions sont prises, les données utilisées et la façon dont les modèles ont été formés.
Chiffrer les données utilisateur. Les données d’entrée doivent être chiffrées à chaque étape du pipeline de traitement des données à partir du moment où l’utilisateur entre des données. Cela inclut les données qui passent d’un point à un autre, où elles sont stockées et pendant l’inférence, si nécessaire. Équilibrez la sécurité et les fonctionnalités, mais visez à maintenir les données privées tout au long de son cycle de vie.
Pour plus d’informations sur les techniques de chiffrement, consultez Conception d’application.
Fournir des contrôles d’accès robustes. Plusieurs types d’identités peuvent potentiellement accéder aux données utilisateur. Implémentez le contrôle d’accès en fonction du rôle (RBAC) pour le plan de contrôle et le plan de données, couvrant la communication entre les utilisateurs et le système.
Conservez également une segmentation appropriée des utilisateurs pour protéger la confidentialité. Par exemple, Copilot pour Microsoft 365 peut rechercher et fournir des réponses en fonction des documents et e-mails spécifiques d’un utilisateur, ce qui garantit que seul le contenu pertinent pour cet utilisateur est accessible.
Pour plus d’informations sur l’application des contrôles d’accès, consultez Conception d’application.
Réduisez la surface d’exposition. Une stratégie fondamentale du pilier De sécurité du Framework bien architecte est de réduire la surface d’attaque et de renforcer les ressources. Cette stratégie doit être appliquée aux pratiques de sécurité de point de terminaison standard en contrôlant étroitement les points de terminaison d’API, en exposant uniquement les données essentielles et en évitant les informations superflues dans les réponses. Le choix de conception doit être équilibré entre flexibilité et contrôle.
Vérifiez qu’il n’existe aucun point de terminaison anonyme. En général, évitez de donner aux clients plus de contrôle que nécessaire. Dans la plupart des scénarios, les clients n’ont pas besoin d’ajuster les hyperparamètres, sauf dans les environnements expérimentaux. Pour les cas d’usage classiques, tels que l’interaction avec un agent virtuel, les clients ne doivent contrôler que les aspects essentiels pour garantir la sécurité en limitant le contrôle inutile.
Pour plus d’informations, consultez Conception d’application.