Sauvegarder et récupérer Oracle Database sur une machine virtuelle Azure Linux à l’aide du service Sauvegarde Azure
S’applique à : ✔️ Machines virtuelles Linux
Cet article explique comment utiliser le service Sauvegarde Azure pour prendre des captures instantanées des disques d’une machine virtuelle, y compris les fichiers Oracle Database et la zone de récupération rapide Oracle. Le service Sauvegarde Azure permet de prendre des captures instantanées complètes des disques. Celles-ci font office de sauvegardes et sont stockées dans un coffre Recovery Services.
Le service Sauvegarde Azure fournit également des sauvegardes cohérentes avec les applications : aucun correctif supplémentaire n’est requis pour restaurer les données. Les sauvegardes cohérentes avec les applications fonctionnent avec un système de fichiers et des bases de données Oracle Automatic Storage Management (ASM).
La restauration de données cohérentes avec les applications réduit le délai de restauration et permet ainsi de rétablir rapidement le fonctionnement normal. La récupération d’Oracle Database est toujours nécessaire après la restauration. Vous pouvez faciliter la récupération à l’aide des fichiers journaux de restauration par progression archivés Oracle qui sont capturés et stockés dans un partage de fichiers Azure distinct.
Cet article permet de se familiariser avec les tâches suivantes :
- Sauvegarder la base de données en bénéficiant d’une sauvegarde cohérente avec les applications.
- Restaurer et récupérer la base de données à partir d’un point de récupération.
- Restaurer la machine virtuelle à partir d’un point de récupération.
Prérequis
Utilisez l’environnement Bash dans Azure Cloud Shell. Pour plus d’informations, consultez Démarrage rapide pour Bash dans Azure Cloud Shell.

Si vous préférez exécuter les commandes de référence de l’interface de ligne de commande localement, installez l’interface Azure CLI. Si vous exécutez sur Windows ou macOS, envisagez d’exécuter Azure CLI dans un conteneur Docker. Pour plus d’informations, consultez Guide pratique pour exécuter Azure CLI dans un conteneur Docker.
Si vous utilisez une installation locale, connectez-vous à Azure CLI à l’aide de la commande az login. Pour finir le processus d’authentification, suivez les étapes affichées dans votre terminal. Pour connaître les autres options de connexion, consultez Se connecter avec Azure CLI.
Lorsque vous y êtes invité, installez l’extension Azure CLI lors de la première utilisation. Pour plus d’informations sur les extensions, consultez Utiliser des extensions avec Azure CLI.
Exécutez az version pour rechercher la version et les bibliothèques dépendantes installées. Pour effectuer une mise à niveau vers la dernière version, exécutez az upgrade.
Pour accomplir le processus de sauvegarde et de récupération, vous devez commencer par créer une machine virtuelle Linux sur laquelle est installée une instance d’Oracle Database 12.1 ou version ultérieure.
Créez une instance Oracle Database en suivant la procédure de l’article Créer une base de données Oracle dans une machine virtuelle Azure.
Préparer l’environnement
Pour préparer l'environnement, procédez comme suit :
- Connectez-vous à la machine virtuelle.
- Configurez le service Stockage Azure Files.
- Préparer les bases de données.
Connexion à la machine virtuelle
Pour créer une session Secure Shell (SSH) avec la machine virtuelle, utilisez la commande suivante. Remplacez
<publicIpAddress>par l’adresse publique de la machine virtuelle.ssh azureuser@<publicIpAddress>Basculez vers l'utilisateur racine :
sudo su -Ajoutez l’utilisateur
oracleau fichier /etc/sudoers :echo "oracle ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
Configurer le service Stockage Azure Files pour les fichiers journaux de restauration par progression Oracle archivés
Les fichiers journaux de restauration par progression archivés de l’instance Oracle Database jouent un rôle crucial dans la récupération de base de données. Ils stockent les transactions validées nécessaires à la restauration par progression à partir d’une capture instantanée de la base de données prise dans le passé.
En mode ARCHIVELOG, la base de données archive le contenu des fichiers journaux de restauration par progression en ligne lorsqu’ils sont saturés et basculés. En association avec une sauvegarde, ils sont nécessaires pour obtenir une récupération jusqu’à une date et heure lorsque la base de données est perdue.
Oracle offre la possibilité d’archiver les fichiers journaux de restauration par progression dans différents emplacements. La meilleure pratique du secteur d’activité est qu’au mois une de ces destinations se trouve sur un stockage distant afin qu’elle soit distincte du stockage hôte et protégée avec des instantanés indépendants. Azure Files répond à ces exigences.
Un partage de fichiers Azure est un stockage qui peut être attaché à une machine virtuelle Linux ou Windows en tant que composant standard du système de fichiers, à l’aide des protocoles SMB (Server Message Block) ou NFS (Network File System). Pour configurer un partage de fichiers Azure sur Linux (à l’aide du protocole SMB 3.0) pour une utilisation en tant que stockage des journaux d’archivage, consultez l’article Monter un partage de fichiers SMB Azure sur Linux. Une fois la configuration terminée, revenez à ce guide et effectuez toutes les étapes restantes.
Préparer les bases de données
Cette étape suppose que vous avez suivi la procédure Créer une instance Oracle Database dans une machine virtuelle Azure. Par conséquent :
- Vous disposez d’une instance Oracle nommée
oratest1qui s’exécute sur une machine virtuelle nomméevmoracle19c. - Vous utilisez le script Oracle standard
oraenvavec sa dépendance sur le fichier de configuration Oracle standard /etc/oratab pour configurer les variables d’environnement dans une session d’interpréteur de commandes.
Pour chaque base de données sur la machine virtuelle, procédez comme suit :
Passez à l’utilisateur
oracle:sudo su - oracleDéfinissez la variable d’environnement
ORACLE_SIDen exécutant le scriptoraenv. Vous êtes invité à entrer le nomORACLE_SID.. oraenvAjoutez le partage de fichiers Azure comme destination de fichier journal d’archivage de base de données supplémentaire.
Cette étape suppose que vous avez configuré et monté un partage de fichiers Azure sur la machine virtuelle Linux. Pour chaque base de données installée sur la machine virtuelle, créez un sous-répertoire nommé d’après l’identificateur de sécurité (SID) de la base de données.
Dans cet exemple, le nom du point de montage est
/backupet le SID estoratest1. Vous allez donc créer un sous-répertoire/backup/oratest1et accorder la propriété à l’utilisateuroracle. Remplacez/backup/SIDpar le nom de votre point de montage et le SID de votre base de données.sudo mkdir /backup/oratest1 sudo chown oracle:oinstall /backup/oratest1Connectez-vous à la base de données :
sqlplus / as sysdbaSi ce n'est déjà fait, démarrez la base de données :
SQL> startupDéfinissez la première destination du journal d’archivage de la base de données sur le répertoire de partage de fichiers que vous avez créé plus tôt :
SQL> alter system set log_archive_dest_1='LOCATION=/backup/oratest1' scope=both;Définissez l’objectif de point de récupération (RPO) de la base de données.
Pour obtenir un objectif de point de récupération (RPO) cohérent, tenez compte de la fréquence à laquelle les fichiers journaux de la phase de restauration par progression en ligne sont archivés. Les facteurs suivants contrôlent la fréquence :
- Taille des fichiers journaux de restauration par progression en ligne. Lorsqu’un fichier journal en ligne est plein, il est basculé et archivé. Plus le fichier journal en ligne est volumineux, plus il faut de temps pour le remplir. Le temps supplémentaire diminue la fréquence de génération de l’archive.
- La valeur du paramètre
ARCHIVE_LAG_TARGETcontrôle le nombre maximal de secondes autorisées avant que le fichier journal en ligne actuel ne soit basculé et archivé.
Pour réduire la fréquence de basculement et d’archivage, ainsi que l’opération de point de contrôle associée, les fichiers journaux de restauration par progression en ligne Oracle sont généralement de taille importante (1 024 Mo, 4 096 Mo ou 8 192 Mo). Dans un environnement de base de données occupé, des journaux sont toujours susceptibles de basculer et d’archiver toutes les quelques secondes ou minutes. Dans une base de données moins active, il peut s’écouler des heures ou des jours avant l’archivage des transactions les plus récentes, ce qui diminue considérablement la fréquence d’archivage.
Il est recommandé de définir
ARCHIVE_LAG_TARGETpour garantir la cohérence du RPO. Un paramètre de 5 minutes (300 secondes) est une valeur prudente pourARCHIVE_LAG_TARGET. Cela garantit que toutes les opérations de récupération de base de données peuvent être récupérées dans un délai inférieur ou égal à 5 minutes après une défaillance.Pour définir
ARCHIVE_LAG_TARGET, exécutez commande suivante :SQL> alter system set archive_lag_target=300 scope=both;Pour mieux comprendre comment déployer une instance Oracle Database haute disponibilité dans Azure avec un RPO de zéro, consultez Architectures de référence pour Oracle Database.
Assurez-vous que la base de données est en mode journal d'archivage pour activer les sauvegardes en ligne.
Commencez par vérifier l'état de l'archivage des journaux :
SQL> SELECT log_mode FROM v$database; LOG_MODE ------------ NOARCHIVELOGSi elle est en mode
NOARCHIVELOG, exécutez les commandes suivantes :SQL> SHUTDOWN IMMEDIATE; SQL> STARTUP MOUNT; SQL> ALTER DATABASE ARCHIVELOG; SQL> ALTER DATABASE OPEN; SQL> ALTER SYSTEM SWITCH LOGFILE;Créez une table pour tester les opérations de sauvegarde et de restauration :
SQL> create user scott identified by tiger quota 100M on users; SQL> grant create session, create table to scott; SQL> connect scott/tiger SQL> create table scott_table(col1 number, col2 varchar2(50)); SQL> insert into scott_table VALUES(1,'Line 1'); SQL> commit; SQL> quit
Sauvegarde des données avec le service Sauvegarde Azure
Le service Sauvegarde Azure fournit des solutions pour sauvegarder vos données et les récupérer à partir du cloud Microsoft Azure. Le service Sauvegarde Azure fournit des sauvegardes indépendantes et isolées pour éviter une destruction accidentelle des données d’origine. Les sauvegardes sont stockées dans un coffre Recovery Services avec gestion intégrée des points de récupération de sorte à pouvoir les restaurer quand vous en avez besoin.
Dans cette section, vous allez utiliser le service Sauvegarde Azure pour prendre des captures instantanées cohérentes avec la machine virtuelle exécutée et les instances Oracle Database. Les bases de données sont placées en mode de sauvegarde. Cela permet d’effectuer une sauvegarde en ligne cohérente sur le plan transactionnel pendant que le service Sauvegarde Azure prend une capture instantanée des disques de la machine virtuelle. La capture instantanée est une copie complète du stockage, et non un instantané incrémentiel ou de copie sur écriture. Il s’agit donc d’un support efficace à partir duquel restaurer votre base de données.
L’avantage des captures instantanées cohérentes avec les applications Sauvegarde Azure est qu’elles sont prises rapidement, quelle que soit la taille de la base de données. Vous pouvez utiliser une capture instantanée pour les opérations de restauration dès qu’elle est prise, sans devoir attendre qu’elle soit transférée vers le coffre Recovery Services.
Pour utiliser le service Sauvegarde Azure afin de sauvegarder la base de données, procédez comme suit :
- Comprendre l’infrastructure du service Sauvegarde Azure.
- Préparez l’environnement pour une sauvegarde cohérente avec les applications.
- Configurez des sauvegardes cohérentes avec les applications.
- Déclenchez une sauvegarde cohérente avec les applications de la machine virtuelle.
Comprendre l’infrastructure du service Sauvegarde Azure
Le service Sauvegarde Azure fournit une infrastructure qui permet d’assurer la cohérence des applications lors des sauvegardes de machines virtuelles Windows et Linux pour diverses applications. Cette infrastructure implique l’appel d’un pré-script pour suspendre les applications avant la capture instantanée des disques. Elle appelle un post-script pour libérer les applications une fois la capture instantanée terminée.
Microsoft a amélioré l’infrastructure afin que le service Sauvegarde Azure fournisse les pré-scripts et les post-scripts empaquetés pour les applications sélectionnées. Ces pré-scripts et post-scripts étant déjà chargés sur l’image Linux, vous n’avez rien à installer. Il suffit de nommer l’application après quoi le service Sauvegarde Azure appelle automatiquement les scripts appropriés. Microsoft gère les pré-scripts et les post-scripts empaquetés, garantissant ainsi la prise en charge, la propriété et la validité de ces scripts.
Les applications actuellement prises en charge pour l’infrastructure améliorée sont Oracle 12.x (ou version supérieure) et MySQL. Pour plus d’informations, consultez l’article Matrice de prise en charge des sauvegardes de machine virtuelle Azure.
Vous pouvez créer vos propres scripts pour le service Sauvegarde Azure, utilisables avec des bases de données antérieures à la version 12.x. Vous trouverez des exemples de scripts sur GitHub.
Chaque fois que vous effectuez une sauvegarde, l’infrastructure améliorée exécute les pré-scripts et les post-scripts sur toutes les instances Oracle Database installées sur la machine virtuelle. Le paramètre configuration_path dans le fichier workload.conf pointe vers l’emplacement du fichier Oracle /etc/oratab (ou d’un fichier défini par l’utilisateur qui suit la syntaxe oratab). Pour plus d’informations, consultez la rubrique Configurer des sauvegardes cohérentes avec les applications.
Le service Sauvegarde Azure exécute les pré-scripts et les post-scripts pour chaque base de données listée dans le fichier désigné par configuration_path, à l’exception des lignes qui commencent par # (traitées comme des commentaires) ou +ASM (instance Oracle ASM).
L’infrastructure améliorée du service Sauvegarde Azure effectue des sauvegardes en ligne des instances Oracle Database fonctionnant en mode ARCHIVELOG. Les pré-scripts et les post-scripts utilisent les commandes ALTER DATABASE BEGIN et END BACKUP pour assurer la cohérence des applications.
Pour que la sauvegarde de base de données soit cohérente, les bases de données en mode NOARCHIVELOG doivent être arrêtées proprement avant que la capture instantanée ne commence.
Préparer l'environnement pour une sauvegarde cohérente avec les applications
Oracle Database utilise la séparation des rôles de travail pour assurer la séparation des tâches avec le moindre privilège. Il associe des groupes de systèmes d’exploitation distincts à des rôles d’administration de base de données distincts. Vous pouvez accorder des privilèges de base de données différents aux utilisateurs, en fonction de leur appartenance aux groupes de systèmes d’exploitation.
Le rôle de base de données SYSBACKUP (nom générique OSBACKUPDBA) fournit des privilèges limités, afin d’effectuer les opérations de sauvegarde dans la base de données. Il est requis par le service Sauvegarde Azure.
Lors de l’installation d’Oracle, il est recommandé d’utiliser backupdba comme nom de groupe de systèmes d’exploitation à associer au rôle SYSBACKUP. Cependant, vous pouvez utiliser n’importe quel nom pour déterminer le nom du groupe de systèmes d’exploitation représentant le rôle Oracle SYSBACKUP en premier.
Passez à l’utilisateur
oracle:sudo su - oracleDéfinissez l’environnement Oracle :
export ORACLE_SID=oratest1 export ORAENV_ASK=NO . oraenvDéterminez le nom du groupe de systèmes d’exploitation représentant le rôle Oracle
SYSBACKUP:grep "define SS_BKP" $ORACLE_HOME/rdbms/lib/config.cLa sortie doit ressembler à celle-ci :
#define SS_BKP_GRP "backupdba"Dans la sortie, la valeur placée entre guillemets doubles correspond au nom du groupe de systèmes d’exploitation Linux sur lequel le rôle Oracle
SYSBACKUPest authentifié en externe. Dans cet exemple, il s’agit debackupdba. Notez la valeur réelle.Vérifiez si le groupe de systèmes d’exploitation existe en exécutant la commande suivante. Remplacez
<group name>par la valeur retournée par la commande précédente (sans les guillemets).grep <group name> /etc/groupLa sortie doit ressembler à celle-ci :
backupdba:x:54324:oracleImportant
Si la sortie ne correspond pas à la valeur du groupe de systèmes d’exploitation Oracle récupérée à l’étape 3, utilisez la commande suivante pour créer le groupe de systèmes d’exploitation représentant le rôle Oracle
SYSBACKUP. Remplacez<group name>par le nom du groupe récupéré à l’étape 3.sudo groupadd <group name>Créez un utilisateur de sauvegarde nommé
azbackupqui appartient au groupe de systèmes d’exploitation que vous avez vérifié ou créé lors des étapes précédentes. Remplacez<group name>par le nom du groupe vérifié. L’utilisateur est également ajouté au groupeoinstallpour lui permettre d’ouvrir des disques ASM.sudo useradd -g <group name> -G oinstall azbackupConfigurez l'authentification externe pour le nouvel utilisateur de sauvegarde.
L’utilisateur de sauvegarde
azbackupdoit avoir accès à la base de données à l’aide de l’authentification externe, afin de ne pas devoir utiliser de mot de passe. Pour octroyer l’accès, vous devez créer un utilisateur de base de données qui s’authentifie en externe avecazbackup. La base de données utilise un préfixe pour le nom d’utilisateur que vous devez rechercher.Sur chaque base de données installée sur la machine virtuelle, procédez comme suit :
Connectez-vous à la base de données avec SQL Plus, puis vérifiez les paramètres par défaut de l’authentification externe :
sqlplus / as sysdba SQL> show parameter os_authent_prefix SQL> show parameter remote_os_authentLa sortie doit ressembler à cet exemple, qui affiche
ops$comme préfixe du nom d’utilisateur de la base de données :NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ os_authent_prefix string ops$ remote_os_authent boolean FALSECréez un utilisateur de base de données
ops$azbackuppour l’authentification externe de l’utilisateurazbackupet accordez-lui des privilègesSYSBACKUP:SQL> CREATE USER ops$azbackup IDENTIFIED EXTERNALLY; SQL> GRANT CREATE SESSION, ALTER SESSION, SYSBACKUP TO ops$azbackup;
Si vous rencontrez une erreur
ORA-46953: The password file is not in the 12.2 formatlors de l’exécution de l’instructionGRANT, procédez comme suit pour migrer le fichier orapwd vers le format 12.2. Appliquez cette procédure pour chaque instance Oracle Database de la machine virtuelle.Quittez SQL Plus.
Déplacez le fichier de mot de passe disposant de l'ancien format vers un nouveau nom.
Migrez le fichier de mot de passe.
Supprimez l'ancien fichier.
Exécutez les commandes suivantes :
mv $ORACLE_HOME/dbs/orapworatest1 $ORACLE_HOME/dbs/orapworatest1.tmp orapwd file=$ORACLE_HOME/dbs/orapworatest1 input_file=$ORACLE_HOME/dbs/orapworatest1.tmp rm $ORACLE_HOME/dbs/orapworatest1.tmpRéexécutez l’opération
GRANTdans SQL Plus.
Créez une procédure stockée pour consigner les messages de sauvegarde de fichier journal dans le journal des alertes de la base de données. Utilisez le code suivant pour chaque base de données installée sur la machine virtuelle :
sqlplus / as sysdba SQL> GRANT EXECUTE ON DBMS_SYSTEM TO SYSBACKUP; SQL> CREATE PROCEDURE sysbackup.azmessage(in_msg IN VARCHAR2) AS v_timestamp VARCHAR2(32); BEGIN SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD HH24:MI:SS') INTO v_timestamp FROM DUAL; DBMS_OUTPUT.PUT_LINE(v_timestamp || ' - ' || in_msg); SYS.DBMS_SYSTEM.KSDWRT(SYS.DBMS_SYSTEM.ALERT_FILE, in_msg); END azmessage; / SQL> SHOW ERRORS SQL> QUIT
Configurer des sauvegardes cohérentes avec les applications
Basculez vers l'utilisateur racine :
sudo su -Recherchez le dossier /etc/azure. S’il est absent, créez un répertoire de travail pour les sauvegardes de cohérence des applications :
if [ ! -d "/etc/azure" ]; then mkdir /etc/azure fiRecherchez le fichier workload.conf dans le dossier. S’il est absent, créez-le dans le répertoire /etc/azure avec le contenu suivant. Les commentaires doivent commencer par
[workload]. Si le fichier est déjà présent, modifiez les champs conformément au contenu suivant. Sinon, la commande suivante peut créer le fichier et renseigner le contenu :echo "[workload] workload_name = oracle configuration_path = /etc/oratab timeout = 90 linux_user = azbackup" > /etc/azure/workload.confLe fichier workload.conf utilise le format suivant :
- Le paramètre
workload_nameindique le type de charge de travail de base de données. Dans ce cas, le paramètre est défini surOracle, ce qui permet au service Sauvegarde Azure d’exécuter les pré-scripts et les post-scripts (commandes de cohérence) qui conviennent pour les instances Oracle Database. - Le paramètre
timeoutindique la durée maximale en secondes nécessaire à chaque base de données pour effectuer des captures instantanées de stockage. - Le paramètre
linux_userindique le compte d’utilisateur Linux utilisé par le service Sauvegarde Azure pour exécuter les opérations de mise en suspens de la base de données. Vous avez créé cet utilisateur,azbackup, précédemment. - Le paramètre
configuration_pathindique le nom de chemin d’accès absolu d’un fichier texte sur la machine virtuelle. Chaque ligne répertorie une instance de la base de données en cours d’exécution sur la machine virtuelle. Il s’agit généralement du fichier /etc/oratab généré par Oracle au cours de l’installation de la base de données, mais il peut s’agir de n’importe quel fichier portant le nom de votre choix. Il doit respecter les règles de format suivantes :- Le fichier doit être un fichier texte. Chaque champ est délimité par le caractère deux-points (
:). - Le premier champ de chaque ligne est le nom d’une instance
ORACLE_SID. - Le deuxième champ de chaque ligne correspond au nom de chemin d’accès absolu d’
ORACLE_HOMEpour cette instanceORACLE_SID. - Tout le texte qui suit ces deux premiers champs est ignoré.
- Si la ligne commence par un signe dièse (
#), la ligne entière est ignorée en tant que commentaire. - Si le premier champ a la valeur
+ASM(ce qui indique une instance Oracle ASM), il est ignoré.
- Le fichier doit être un fichier texte. Chaque champ est délimité par le caractère deux-points (
- Le paramètre
Déclencher une sauvegarde cohérente avec les applications de la machine virtuelle
Sur le portail Azure, accédez à votre groupe de ressources rg-oracle et sélectionnez votre machine virtuelle vmoracle19c.
Dans le volet Sauvegarde :
- Sous Coffre Recovery Services, sélectionnez Créer.
- Pour le nom du coffre, utilisez myVault.
- Pour Groupe de ressources, sélectionnez rg-oracle.
- Sous Choisir une stratégie de sauvegarde, utilisez (Nouveau) DailyPolicy. Si vous souhaitez modifier la fréquence de sauvegarde ou la durée de rétention, sélectionnez Créer une stratégie.
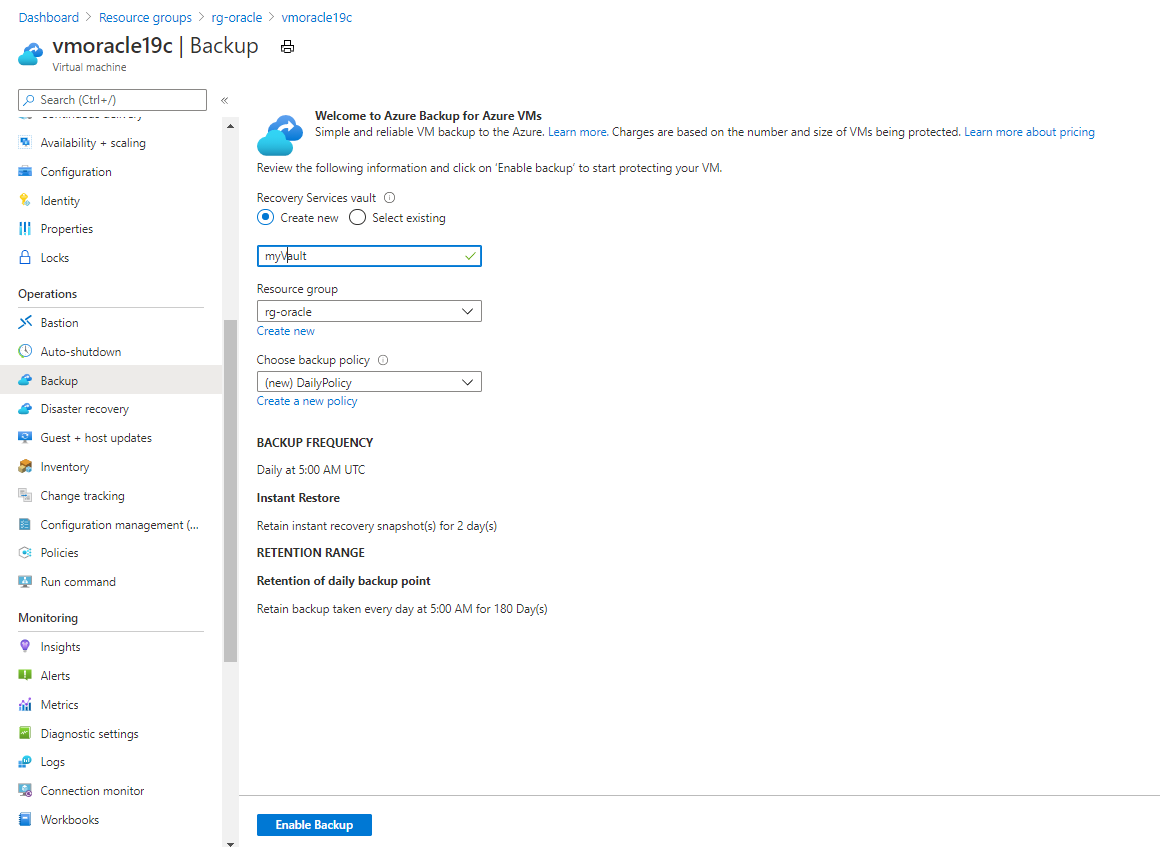
Sélectionnez Activer la Sauvegarde Azure.
Le processus de sauvegarde ne démarre pas avant l’expiration de l’heure planifiée. Pour configurer une sauvegarde immédiate, procédez comme suit.
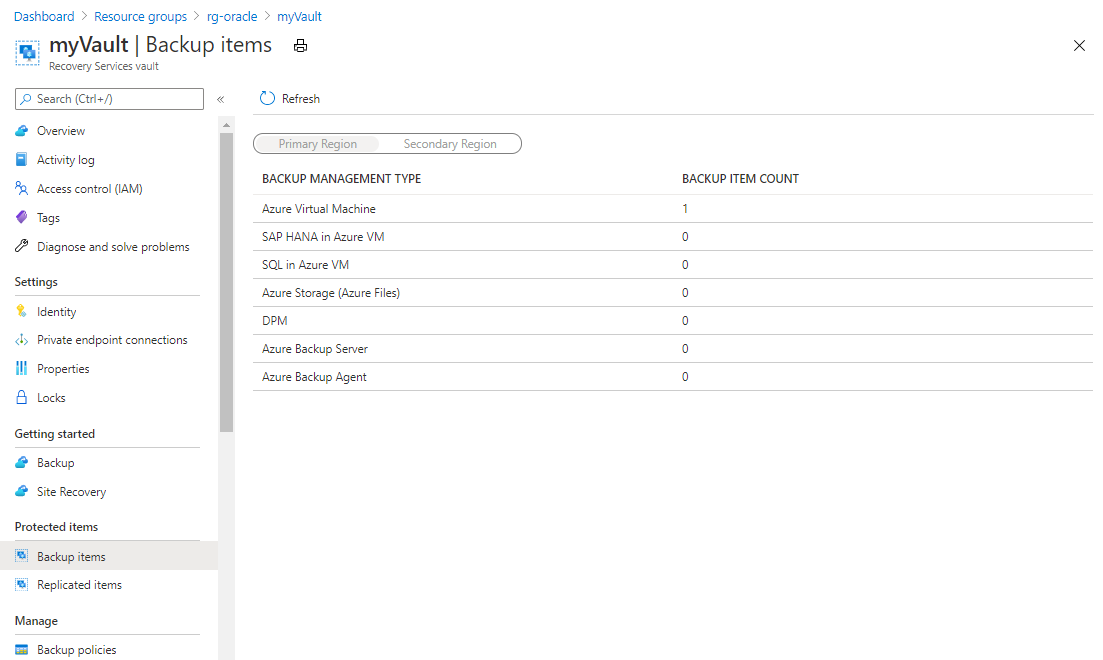
Sur la page du groupe de ressources, sélectionnez le coffre Recovery Services nommé myVault que vous venez de créer. Il peut être nécessaire d’actualiser la page pour le voir.
Dans le volet myVault – Éléments de sauvegarde, sous NOMBRE D’ÉLÉMENTS DE SAUVEGARDE, sélectionnez le nombre d’éléments de sauvegarde.
Dans le volet Éléments de sauvegarde (machine virtuelle Azure), cliquez sur le bouton de sélection (…), puis sur Sauvegarder maintenant.
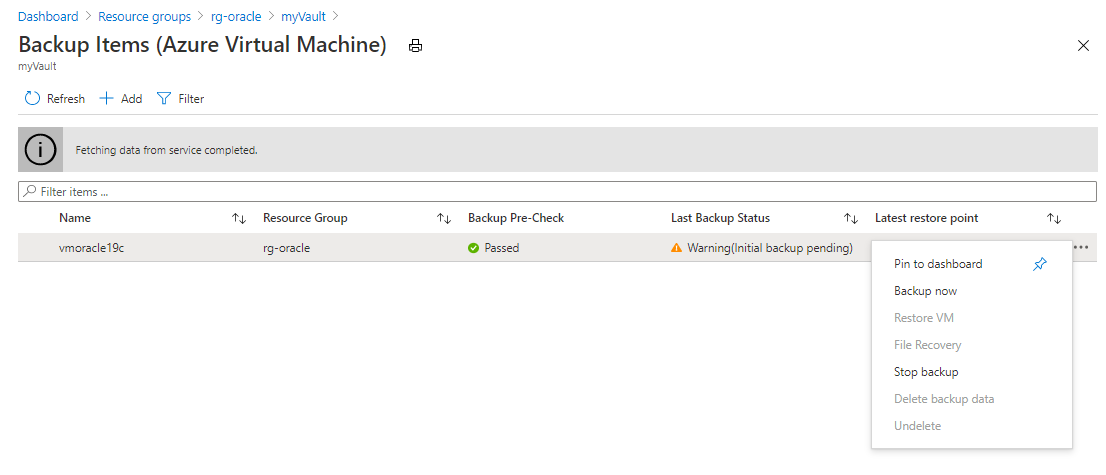
Acceptez la valeur par défaut du champ Conserver la sauvegarde jusqu’au, puis cliquez sur le bouton OK. Attendez que le processus de sauvegarde se termine.
Pour consulter l’état du travail de sauvegarde, sélectionnez Travaux de sauvegarde.
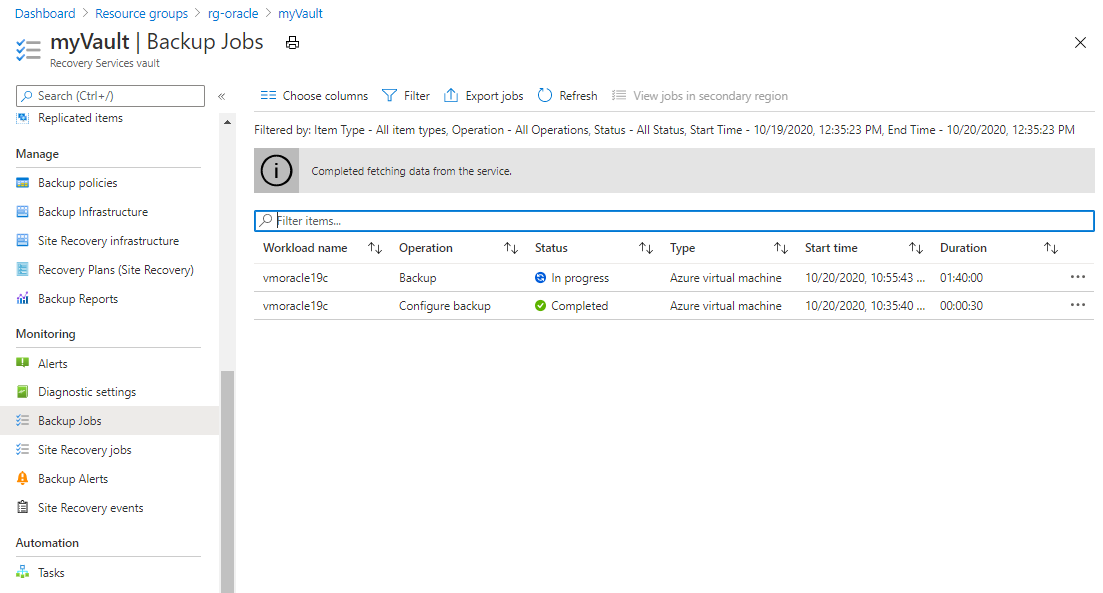
Sélectionnez le travail de sauvegarde pour consulter son état.
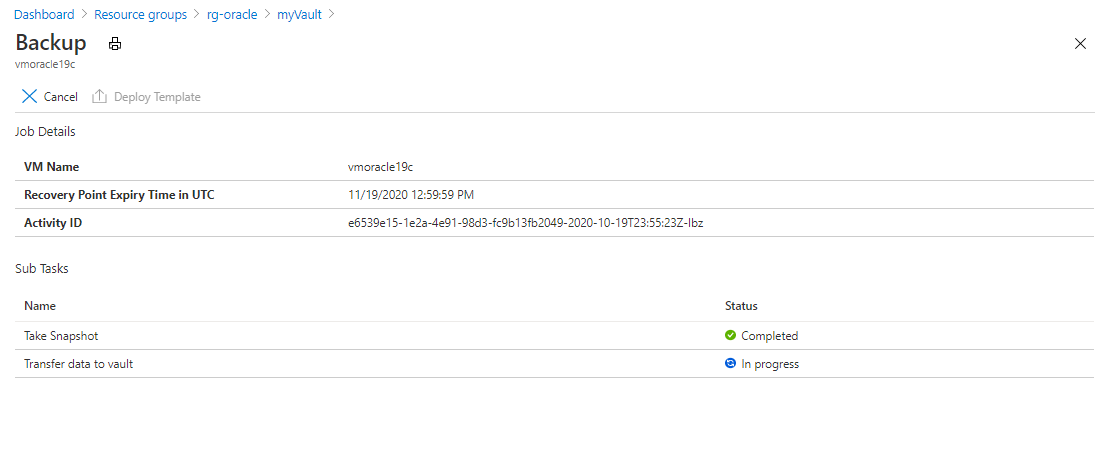
Bien que l’exécution de la capture instantanée ne prenne que quelques secondes, son transfert vers le coffre peut prendre plus de temps. Le travail de sauvegarde n’est pas terminé tant que le transfert n’est pas finalisé.
Pour une sauvegarde cohérente avec les applications, résolvez les éventuelles erreurs présentes dans le fichier journal qui se trouve sous /var/log/azure/Microsoft.Azure.RecoveryServices.VMSnapshotLinux/extension.log.
Restaurer la machine virtuelle
La restauration d’une machine virtuelle dans son intégralité permet de restaurer ladite machine et les disques qui y sont attachés sur une nouvelle machine virtuelle à partir d’un point de restauration sélectionné. Cette action restaure également toutes les bases de données qui s’exécutent sur la machine virtuelle. Après quoi, vous devez récupérer chaque base de données.
Pour restaurer une machine virtuelle dans son intégralité, procédez comme suit :
- Arrêtez et supprimez la machine virtuelle.
- Récupérez la machine virtuelle.
- Définissez l’adresse IP publique.
- Récupérez la base de données.
Deux options principales s’offrent à vous lors de la restauration d’une machine virtuelle :
- Restaurer la machine virtuelle à partir de laquelle les sauvegardes ont été effectuées à l’origine.
- Restaurer (cloner) une nouvelle machine virtuelle sans affecter la machine virtuelle à partir de laquelle les sauvegardes ont été effectuées à l’origine.
Les premières étapes de cet exercice (arrêt, suppression, puis récupération de la machine virtuelle) simulent le premier cas d’usage.
Arrêter et supprimer la machine virtuelle
Sur le portail Azure, accédez à la machine virtuelle vmoracle19c, puis sélectionnez Arrêter.
Une fois la machine virtuelle arrêtée, sélectionnez Supprimer, puis Oui.
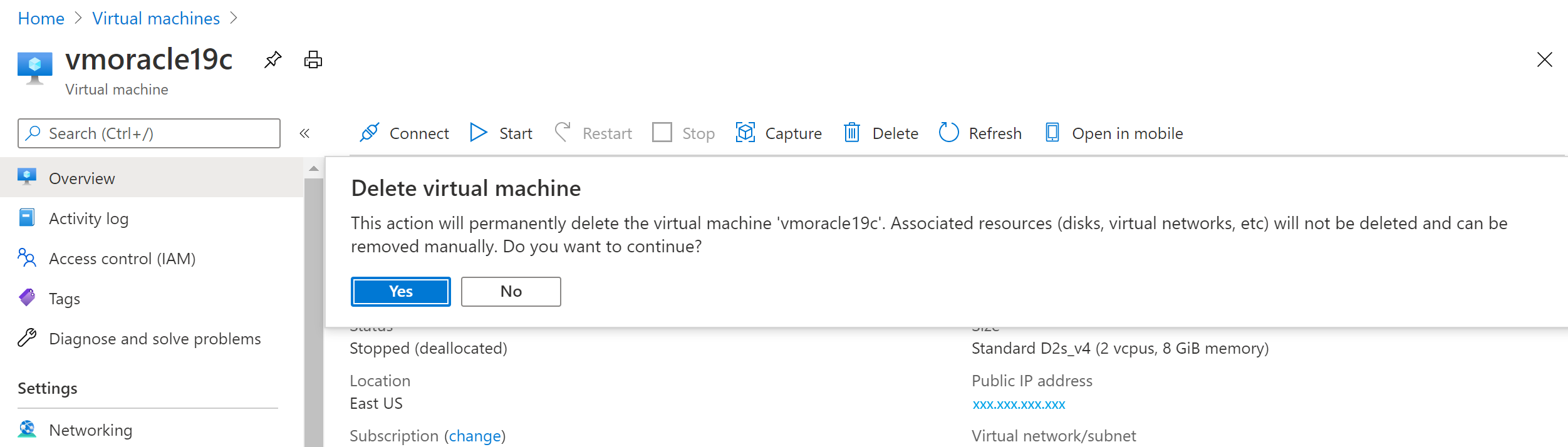
Récupération de la machine virtuelle
Créez un compte de stockage pour la mise en lots sur le portail Azure :
Sur le portail Azure, sélectionnez + Créer une ressource, puis recherchez et sélectionnez Compte de stockage.
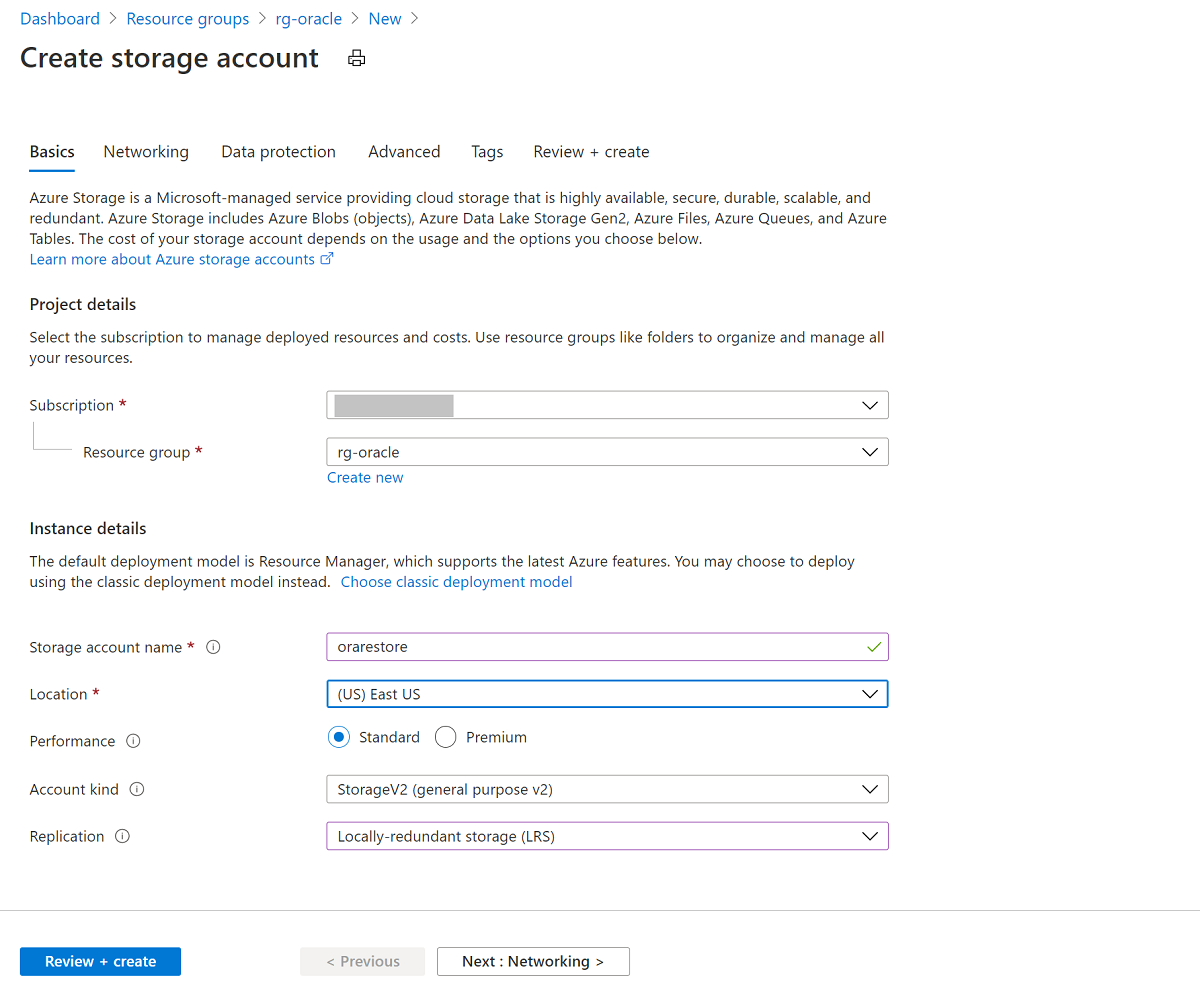
Dans le volet Créer un compte de stockage :
- Pour Groupe de ressources, sélectionnez votre groupe de ressources existant, rg-oracle.
- Pour Nom du compte de stockage, saisissez oracrestore.
- Assurez-vous que l’Emplacement est défini sur la même région que toutes les autres ressources du groupe de ressources.
- Paramétrez les Performances sur Standard.
- Pour Type de compte, sélectionnez StockageV2 (usage général v2).
- Pour Réplication, sélectionnez Stockage localement redondant (LRS) .
Sélectionnez Vérifier + créer, puis Créer.
Sur le portail Azure, recherchez le coffre Recovery Services myVault et sélectionnez-le.
Dans le volet Vue d’ensemble, sélectionnez Éléments de sauvegarde. Sélectionnez ensuite Machine virtuelle Azure, qui doit avoir un NOMBRE D’ÉLÉMENTS DE SAUVEGARDE non nul.
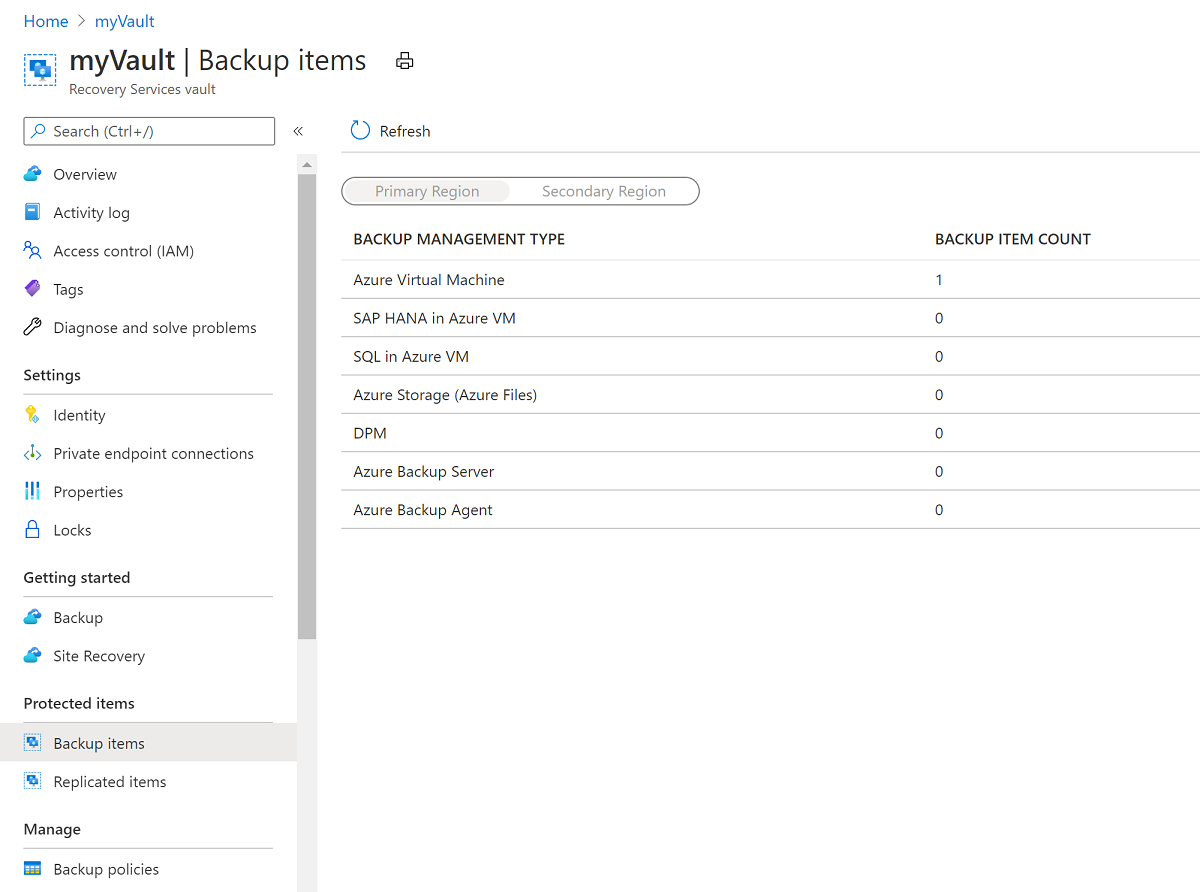
Dans le volet Éléments de sauvegarde (machine virtuelle Azure), sélectionnez la machine virtuelle vmoracle19c.
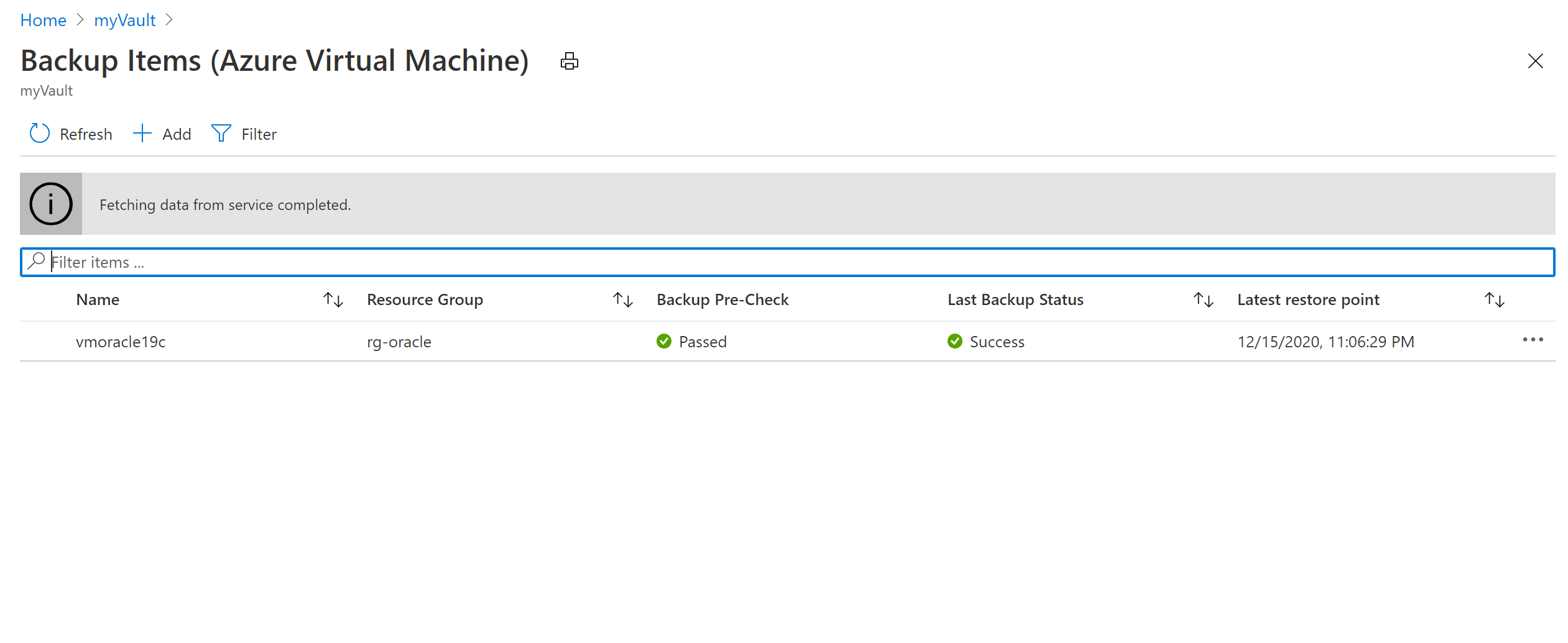
Dans le volet vmoracle19c, choisissez un point de restauration dont le type de cohérence est Cohérence avec les applications. Cliquez sur le bouton de sélection (…), puis sélectionnez Restaurer la machine virtuelle.
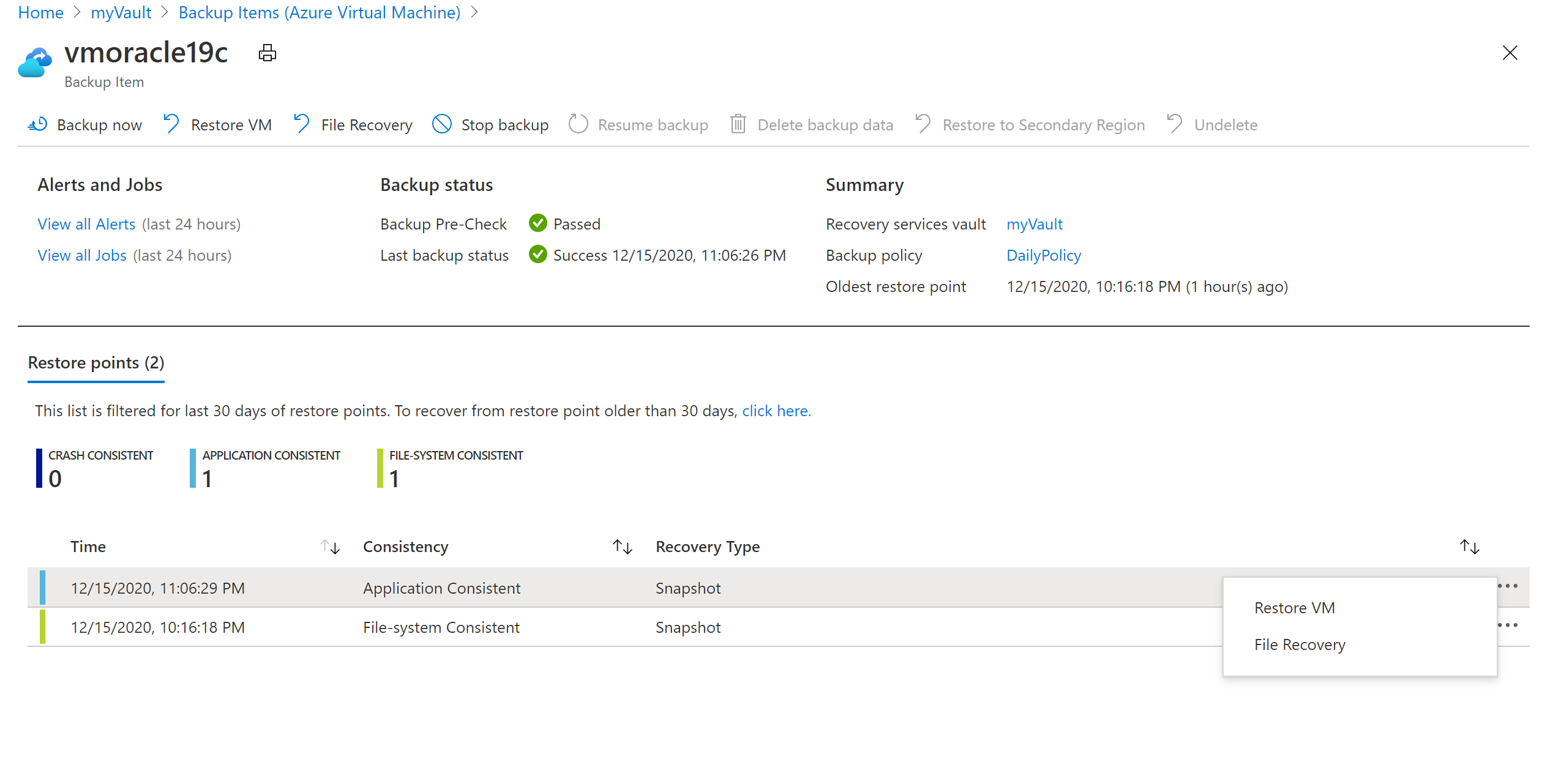
Dans le volet Restaurer une machine virtuelle :
Sélectionnez Créer.
Dans Type de restauration, sélectionnez Créer une machine virtuelle.
Dans Nom de la machine virtuelle, saisissez vmoracle19c.
Pour Réseau virtuel, sélectionnez vmoracle19cVNET.
Le sous-réseau est automatiquement renseigné en fonction du réseau virtuel que vous sélectionnez.
Pour Emplacement intermédiaire, le processus de restauration de la machine virtuelle requiert un compte de stockage Azure situé dans le même groupe de ressources et dans la même région. Vous pouvez choisir le compte de stockage ou une restauration configurée précédemment.
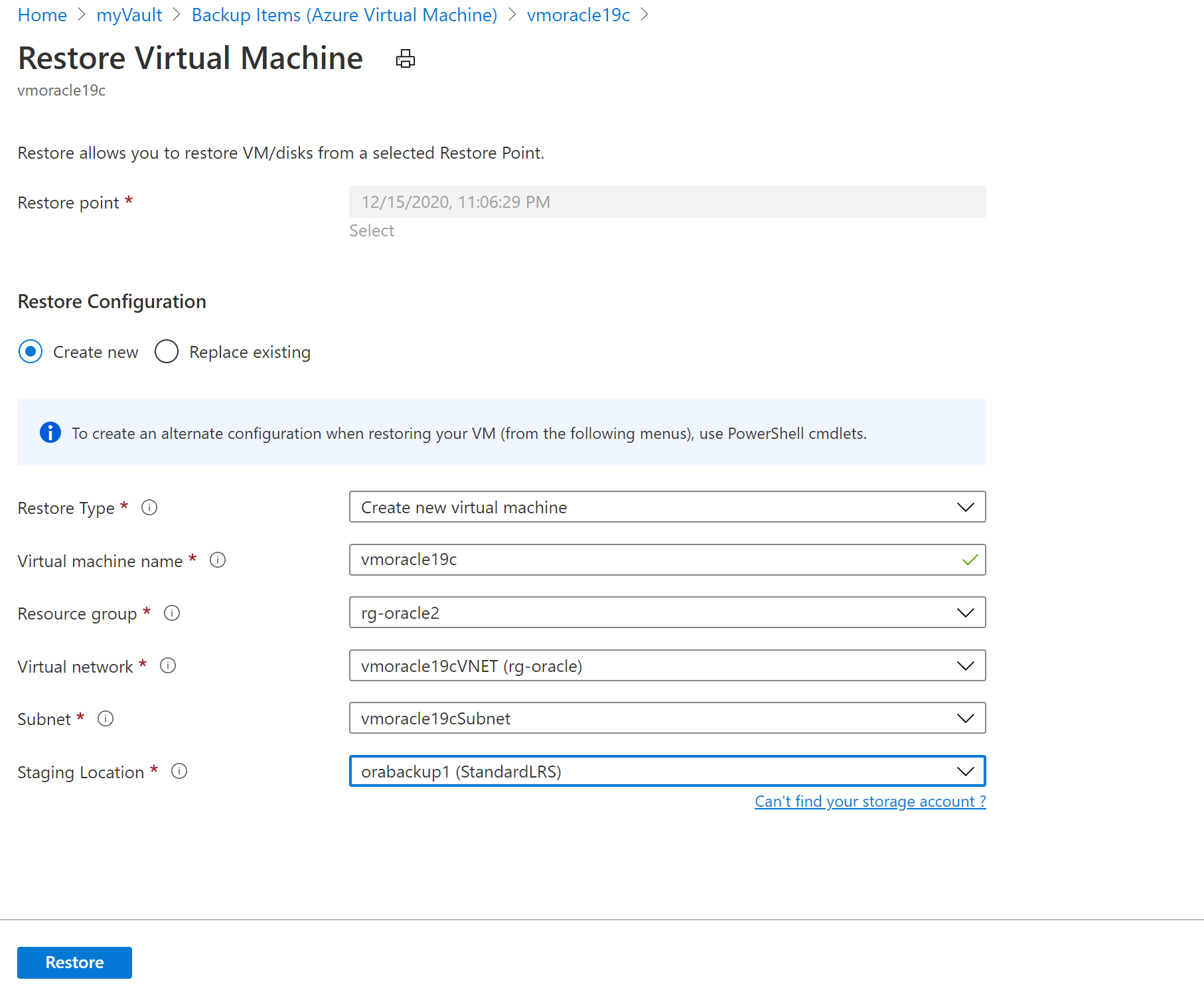
Pour restaurer la machine virtuelle, cliquez sur le bouton Restaurer.
Pour afficher l’état du processus de restauration, cliquez sur Travaux, puis sur Travaux de sauvegarde.
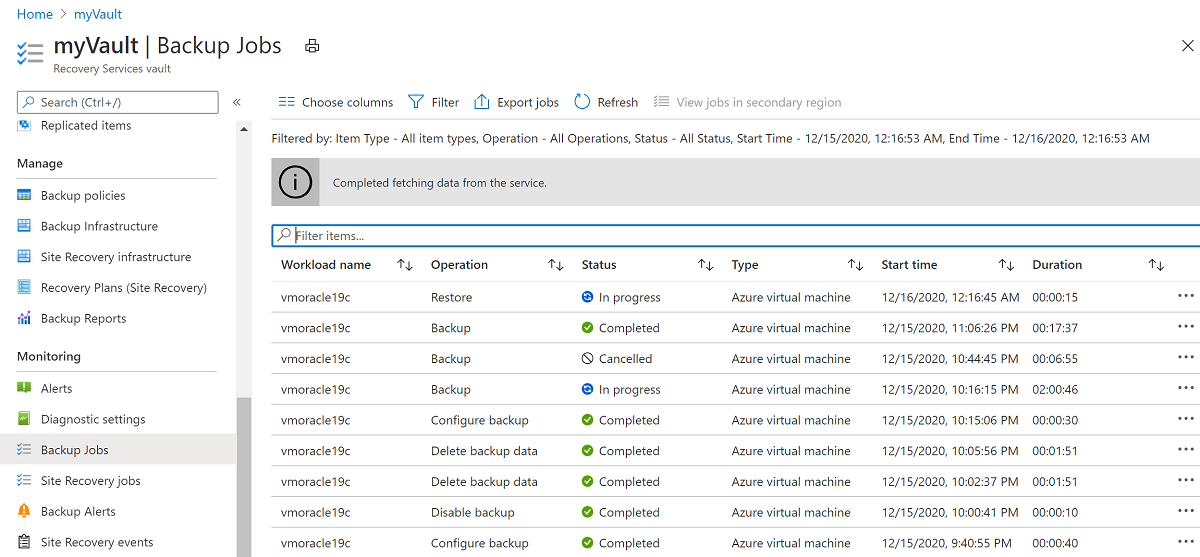
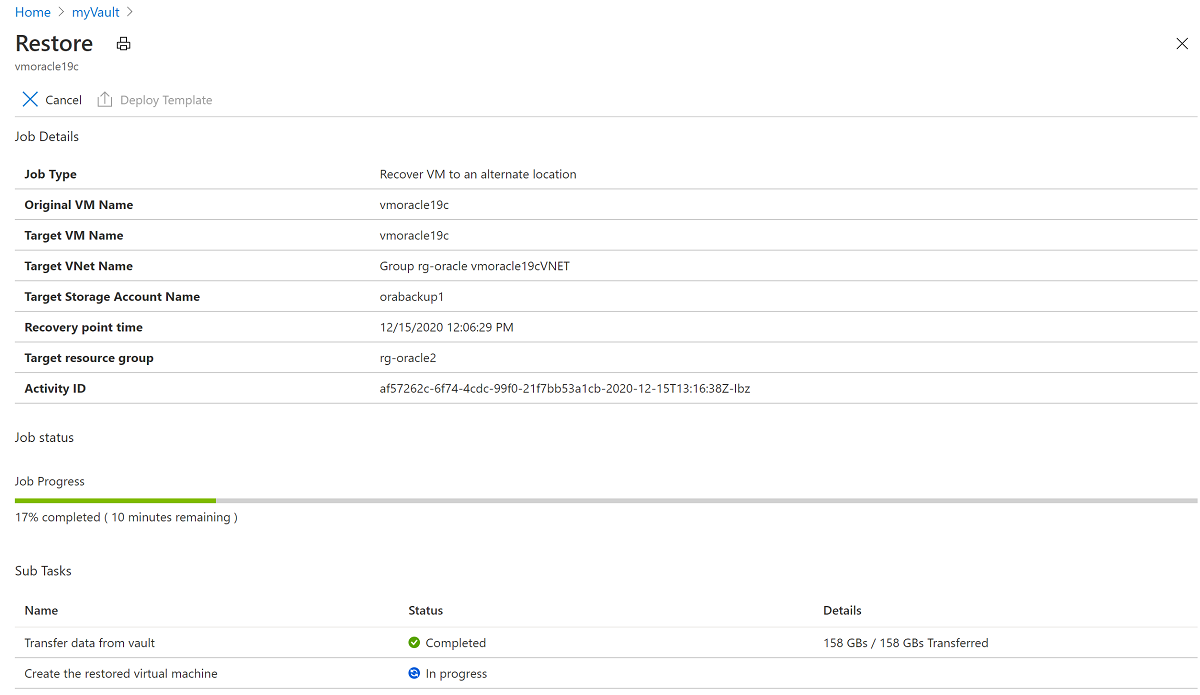
Cliquez sur l’opération de restauration En cours pour afficher des informations sur l’état du processus de restauration.
Définition de l’adresse IP publique
Une fois la machine virtuelle restaurée, vous devez réattribuer l'adresse IP d'origine à la nouvelle machine virtuelle.
Sur le portail Azure, accédez à la machine virtuelle vmoracle19c. Une nouvelle adresse IP publique et une carte réseau de type vmoracle19c-nic-XXXXXXXXXXXX lui sont attribuées, mais elle n’a pas d’adresse DNS. Lorsque la machine virtuelle d’origine a été supprimée, son adresse IP publique et sa carte réseau ont été conservées. Les étapes suivantes visent à les rattacher à la nouvelle machine virtuelle.
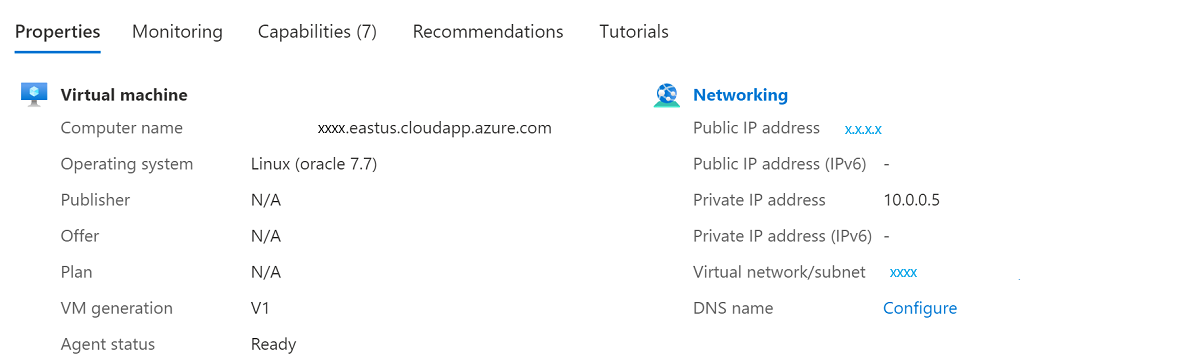
Arrêtez la machine virtuelle.
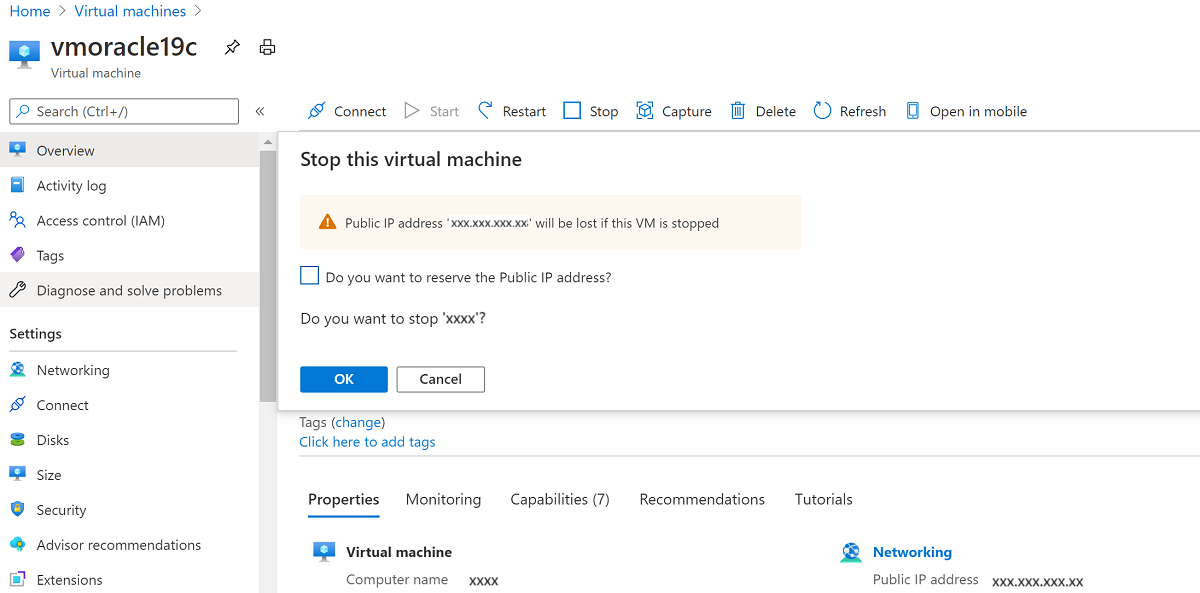
Accédez à Mise en réseau.
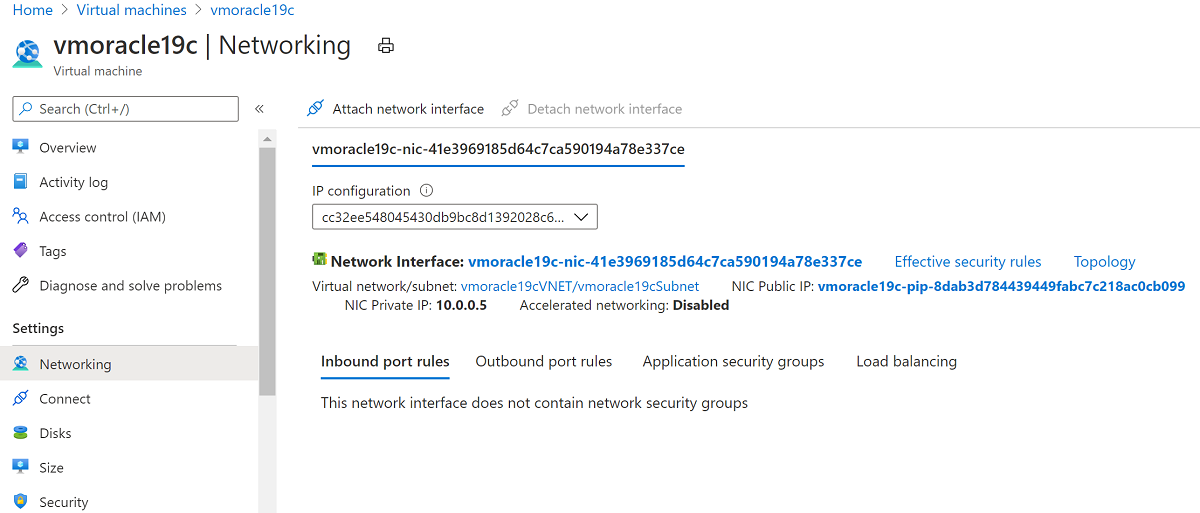
Sélectionnez Attacher l’interface réseau. Sélectionnez la carte réseau d’origine vmoracle19cVMNic, à laquelle l’adresse IP publique d’origine est toujours associée. Sélectionnez ensuite OK.
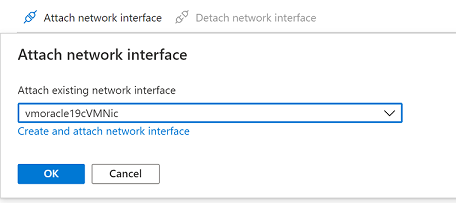
Détachez la carte réseau qui a été créée avec l’opération de restauration de la machine virtuelle, car elle est configurée en tant qu’interface principale. Sélectionnez Détacher l’interface réseau, sélectionnez la carte réseau de type vmoracle19c-nic-XXXXXXXXXXXXXXXX,, puis cliquez sur OK.
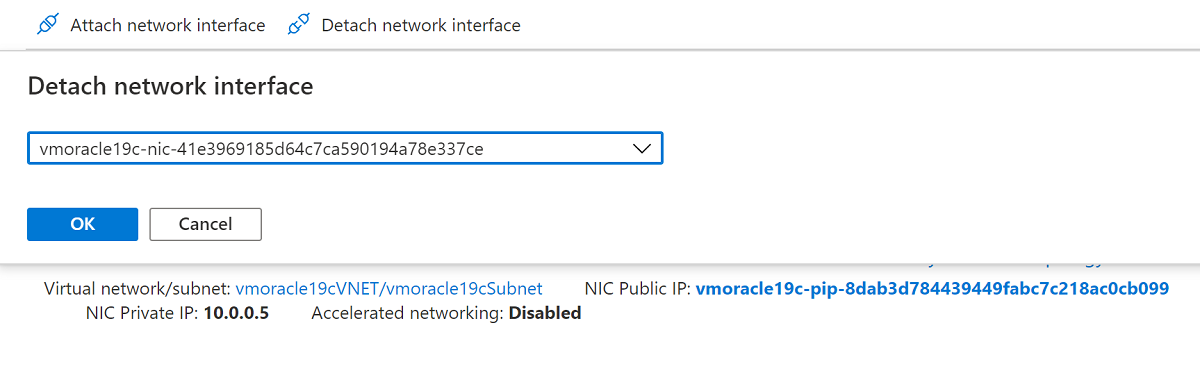
La machine virtuelle recréée dispose maintenant de la carte réseau d’origine, qui est associée à l’adresse IP et aux règles de groupe de sécurité réseau d’origine.
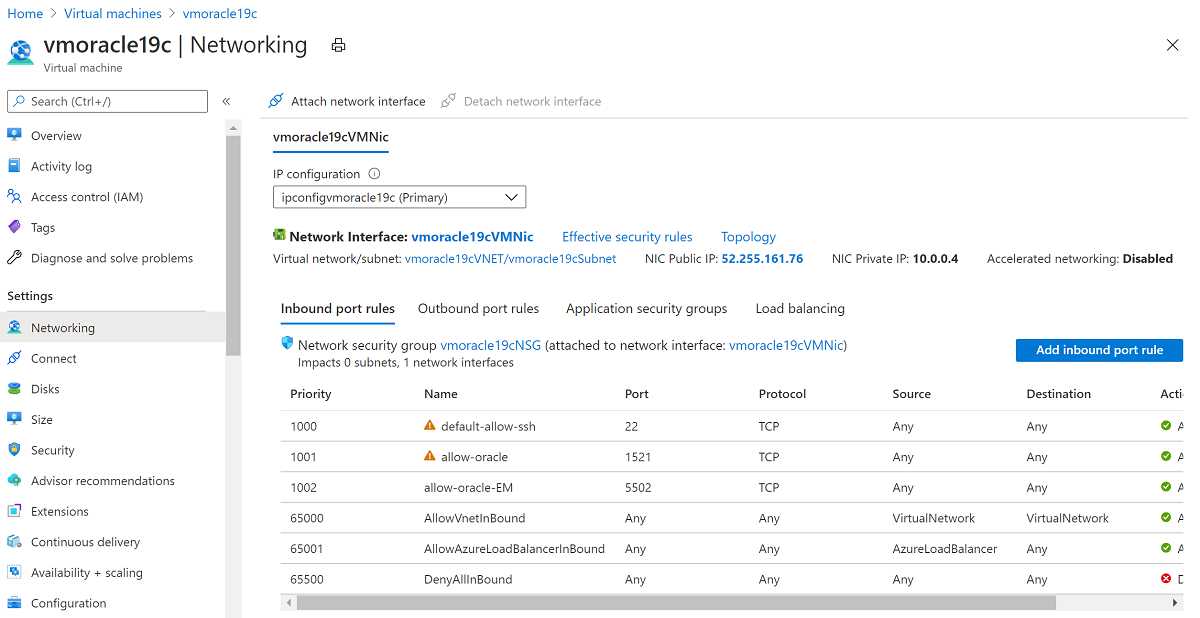
Revenez au volet Vue d’ensemble, puis sélectionnez Démarrer.
Récupération de la base de données
Pour récupérer une base de données après une restauration de machine virtuelle complète :
Reconnectez-vous à la machine virtuelle :
ssh azureuser@<publicIpAddress>Quand l’ensemble de la machine virtuelle est restauré, il est important de récupérer les bases de données sur la machine virtuelle en effectuant les étapes suivantes sur chacune d’elles.
Vous pouvez constater que l’instance est en cours d’exécution, car la fonctionnalité de démarrage automatique a tenté de lancer la base de données au démarrage de la machine virtuelle. Toutefois, la base de données doit être restaurée et n’en est probablement qu’au stade du montage. Exécutez un arrêt préparatoire avant de démarrer la phase de montage :
sudo su - oracle sqlplus / as sysdba SQL> shutdown immediate SQL> startup mountProcédez à la récupération des bases de données.
Il est important de spécifier la syntaxe
USING BACKUP CONTROLFILEpour informer la commandeRECOVER AUTOMATIC DATABASEque la récupération ne doit pas s’arrêter au numéro de modification système (SCN) Oracle enregistré dans le fichier de contrôle de la base de données restaurée.Le fichier de contrôle de la base de données restaurée était un instantané, ainsi que le reste de la base de données. Le SCN stocké dans ce fichier est dérivé de l’instant dans le passé de l’instantané. Il peut y avoir des transactions enregistrées après ce point. Vous souhaitez réaliser la récupération jusqu’au moment de la dernière transaction validée dans la base de données.
SQL> recover automatic database using backup controlfile until cancel;Quand le dernier fichier journal d’archive disponible est appliqué, entrez
CANCELpour terminer la récupération.Une fois la récupération terminée, le message
Media recovery completes’affiche.Toutefois, lorsque vous utilisez la clause
BACKUP CONTROLFILE, la commande de récupération ignore les fichiers journaux en ligne. Vous devrez peut-être apporter des modifications à l’actuel journal de restauration par progression en ligne pour terminer la récupération à un instant dans le passé. Dans ce cas, vous pouvez voir des messages de ce type :SQL> recover automatic database until cancel using backup controlfile; ORA-00279: change 2172930 generated at 04/08/2021 12:27:06 needed for thread 1 ORA-00289: suggestion : /u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc ORA-00280: change 2172930 for thread 1 is in sequence #13 ORA-00278: log file '/u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc' no longer needed for this recovery ORA-00308: cannot open archived log '/u02/fast_recovery_area/ORATEST1/archivelog/2021_04_08/o1_mf_1_13_%u_.arc' ORA-27037: unable to obtain file status Linux-x86_64 Error: 2: No such file or directory Additional information: 7 Specify log: {<RET>=suggested | filename | AUTO | CANCEL}Important
Si l’actuel journal de restauration par progression en ligne est perdu ou endommagé, et que vous ne pouvez pas l’utiliser, vous pouvez annuler la récupération à ce stade.
Pour corriger cela, vous pouvez identifier l’actuel journal en ligne qui n’a pas été archivé et fournir le nom de fichier complet à l’invite.
Ouvrez la base de données.
L’option
RESETLOGSest requise lorsque la commandeRECOVERutilise l’optionUSING BACKUP CONTROLFILE.RESETLOGScrée une incarnation de la base de données en réinitialisant l’historique de restauration par progression au point de départ dans la mesure où il n’existe aucun moyen de déterminer la part de la base de données précédente ignorée dans la récupération.SQL> alter database open resetlogs;Vérifiez que le contenu de la base de données a été récupéré :
SQL> select * from scott.scott_table;
Le processus de sauvegarde et de récupération d’Oracle Database sur une machine virtuelle Linux Azure est maintenant terminé.
Vous trouverez plus d’informations sur les commandes et les concepts Oracle dans la documentation Oracle, y compris :
- Exécution de sauvegardes gérées par les utilisateurs Oracle de l’ensemble de la base de données
- Exécution d’une récupération de base de données complète gérée par les utilisateurs
- Commande Oracle STARTUP
- Commande Oracle RECOVER
- Commande Oracle ALTER DATABASE
- Paramètre Oracle LOG_ARCHIVE_DEST_n
- Paramètre Oracle ARCHIVE_LAG_TARGET
Supprimer la machine virtuelle
Quand vous n’avez plus besoin de la machine virtuelle, vous pouvez utiliser les commandes suivantes pour supprimer le groupe de ressources, la machine virtuelle et toutes les ressources associées :
Désactiver la suppression réversible des sauvegardes dans le coffre :
az backup vault backup-properties set --name myVault --resource-group rg-oracle --soft-delete-feature-state disableArrêter la protection de la machine virtuelle et supprimer les sauvegardes :
az backup protection disable --resource-group rg-oracle --vault-name myVault --container-name vmoracle19c --item-name vmoracle19c --delete-backup-data true --yesSupprimer le groupe de ressources, y compris toutes les ressources :
az group delete --name rg-oracle
Étapes suivantes
Créer des machines virtuelles hautement disponibles
Explorer des exemples Azure CLI pour le déploiement de machines virtuelles