Transformer des données en exécutant un notebook Synapse
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
L’activité du notebook Azure Synapse dans un pipeline Synapse exécute un notebook Synapse. Cet article s'appuie sur l'article Activités de transformation des données qui présente une vue d'ensemble de la transformation des données et les activités de transformation prises en charge.
Créer une activité de notebook Synapse
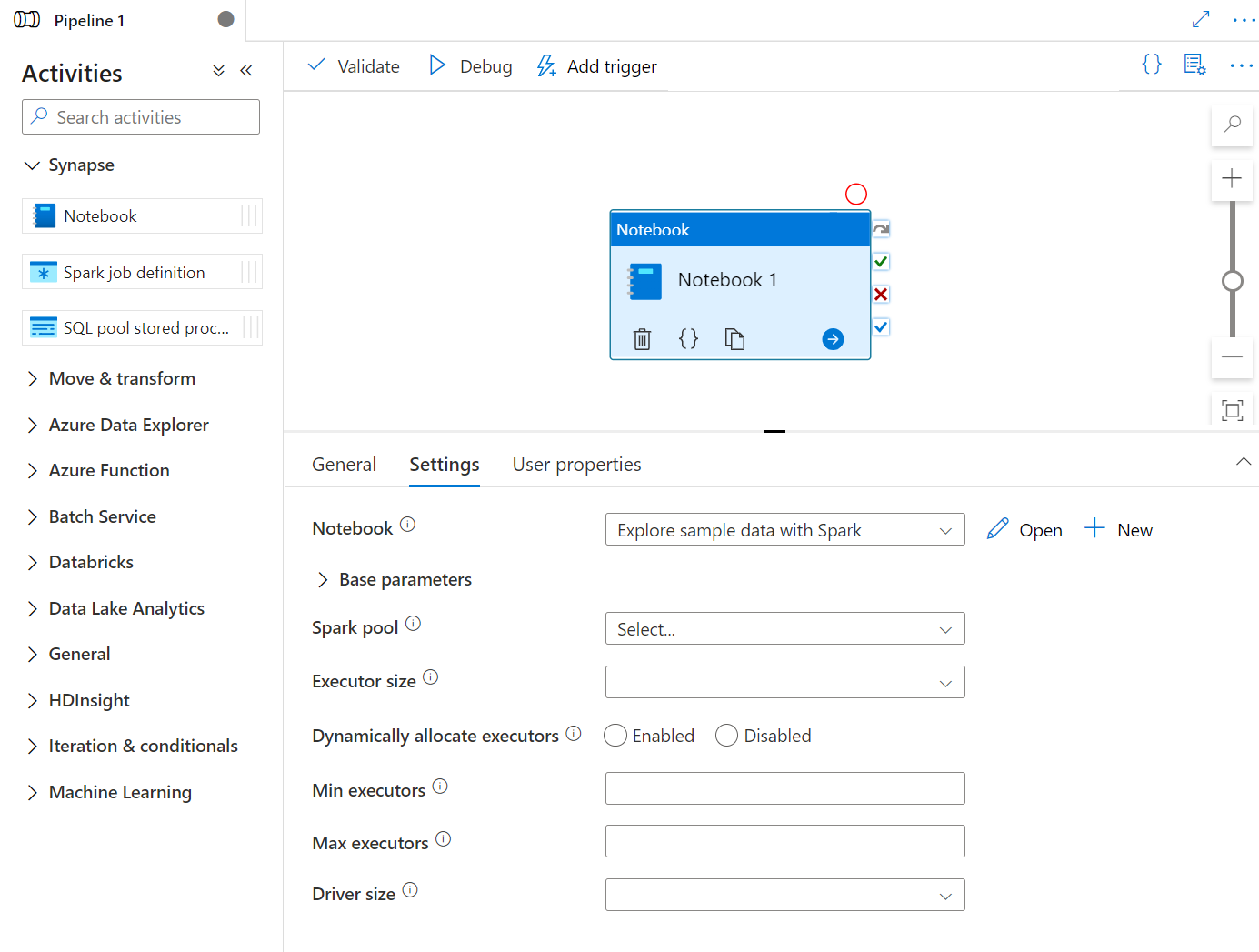
Vous pouvez créer une activité de bloc-notes Synapse directement à partir du canevas de pipeline Synapse ou de l’éditeur de bloc-notes. L’activité de bloc-notes Synapse s’exécute sur le pool Spark qui est choisi dans le bloc-notes Synapse.
Ajouter une activité de bloc-notes Synapse à partir du canevas de pipeline
Glisser-déplacer un bloc-notes Synapse sous Activités dans le canevas de pipeline Synapse. Sélectionnez dans la zone activité du bloc-notes Synapse et configurez le contenu du bloc-notes pour l’activité en cours dans les paramètres. Vous pouvez sélectionner un bloc-notes existant à partir de l’espace de travail actuel ou en ajouter un nouveau.
Si vous sélectionnez un notebook existant dans l’espace de travail actuel, vous pouvez cliquer sur le bouton Ouvrir pour ouvrir directement la page du notebook.
(Facultatif) Vous pouvez également reconfigurer Pool Spark\Taille de l’exécuteur\Allouer dynamiquement des exécuteurs\Nombre minimal d’exécuteurs\Nombre maximal d’exécuteurs\Taille du pilote dans les paramètres. Notez que les paramètres reconfigurés ici remplacent les paramètres de la session de configuration dans le Notebook. Si les paramètres de l’activité actuelle du notebook ne sont pas définis, il s’exécute avec les paramètres de la session de configuration dans ce notebook.
| Propriété | Description | Obligatoire |
|---|---|---|
| Pool Spark | Référence au pool Spark. Vous pouvez sélectionner un pool Apache Spark dans la liste. Si ce paramètre est vide, il s’exécute dans le pool Spark du notebook lui-même. | Non |
| Taille de l’exécuteur | Nombre de cœurs et mémoire à utiliser pour les exécuteurs alloués dans le pool Apache Spark spécifié pour la session. | Non |
| Allouer dynamiquement des exécuteurs | Ce paramètre correspond à la propriété d’allocation dynamique dans la configuration Spark pour allouer des exécuteurs d’application Spark. | Non |
| Nombre minimal d’exécuteurs | Nombre minimal d'exécuteurs à allouer dans le pool Spark spécifié pour le travail. | Non |
| Nombre maximal d’exécuteurs | Nombre maximal d'exécuteurs à allouer dans le pool Spark spécifié pour le travail. | Non |
| Taille du pilote | Nombre de cœurs et mémoire à utiliser pour le pilote dans le pool Apache Spark spécifié du travail. | Non |
Notes
L’exécution de blocs-notes Spark parallèles dans les pipelines Azure Synapse est mise en file d’attente et exécutée de manière FIFO, l’ordre des travaux dans la file d’attente est défini en fonction de la séquence temporelle, le délai d’expiration d’un travail dans la file d’attente est de 3 jours. Notez que la file d’attente pour les bloc-notes fonctionne uniquement dans un pipeline Synapse.
Ajouter un bloc-notes à un pipeline Synapse
Sélectionnez le bouton Ajouter au pipeline dans le coin supérieur droit pour ajouter un notebook à un pipeline existant ou créer un pipeline.

Passage de paramètres
Désigner une cellule de paramètres
Pour paramétrer votre notebook, sélectionnez le bouton de sélection (…) pour accéder au menu Plus de commandes au niveau de la barre d’outils de la cellule. Sélectionnez ensuite Activer/désactiver la cellule Paramètres pour désigner la cellule comme cellule de paramètre.

Définissez vos paramètres dans cette cellule. Cela peut être un élément aussi simple que :
a = 1
b = 3
c = "Default Value"
Vous pouvez référencer ces paramètres dans d’autres cellules et, quand vous exécutez le bloc-notes, utilisez les valeurs par défaut que vous spécifiez dans la cellule de paramètres.
Quand vous exécutez ce bloc-notes à partir d’un pipeline, Azure Data Factory recherche la cellule de paramètres et utilise les valeurs que vous avez fournies comme valeurs par défaut pour les paramètres transmis au moment de l’exécution. Si vous attribuez des valeurs de paramètres à partir d’un pipeline, le moteur d’exécution ajoute une nouvelle cellule sous la cellule de paramètres avec des paramètres d’entrée pour remplacer les valeurs par défaut.
Attribuer des valeurs de paramètres à partir d’un pipeline
Une fois que vous avez créé un bloc-notes avec les paramètres, vous pouvez l’exécuter depuis un pipeline à l’aide de l’activité de bloc-notes Synapse. Après avoir ajouté l’activité à votre canevas de pipeline, vous serez en mesure de définir les valeurs des paramètres dans la section Paramètres de base de l’onglet Paramètres.

Conseil
Data Factory ne remplit pas automatiquement les paramètres. Vous devez les ajouter manuellement. Veillez à utiliser exactement le même nom dans la cellule de paramètres de votre bloc-notes que dans le paramètre de base de votre pipeline.
Une fois vos paramètres ajoutés à votre activité, Data Factory transmet les valeurs que vous spécifiez dans votre activité à votre bloc-notes. Celui-ci s’exécute avec ces nouvelles valeurs de paramètres, au lieu des valeurs par défaut que vous avez spécifiées dans la cellule de paramètres.
Lors de l’attribution des valeurs de paramètre, vous pouvez utiliser le langage d’expression du pipeline ou des variables système.
Lire la valeur de sortie de la cellule du bloc-notes Synapse
Vous pouvez lire la valeur de sortie de la cellule du bloc-notes dans les activités suivantes en suivant les étapes ci-dessous :
Appelez l’API mssparkutils.notebook.exit dans votre activité de bloc-notes Synapse pour retourner la valeur que vous souhaitez afficher dans la sortie de l’activité, par exemple :
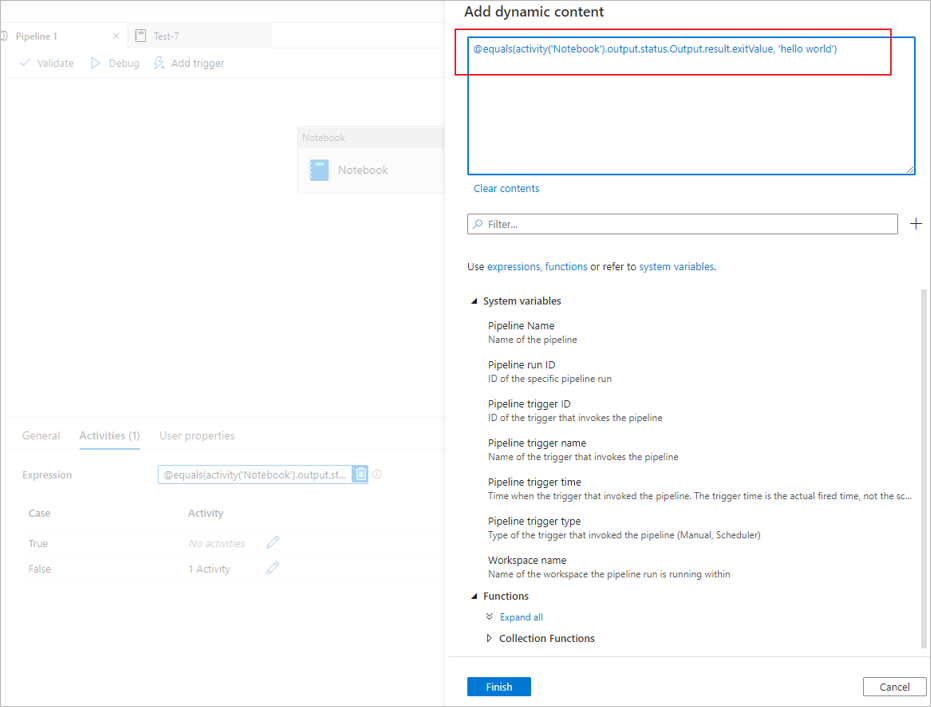
mssparkutils.notebook.exit("hello world")En enregistrant le contenu du bloc-notes et en redéclenchant le pipeline, la sortie de l’activité du bloc-notes contient les exitValue qui peuvent être utilisés pour les activités suivantes à l’étape 2.
Lit la propriété exitValue de la sortie de l’activité du bloc-notes. Voici un exemple d’expression qui est utilisé pour vérifier si le exitValue extrait de la sortie d’activité du bloc-notes est égal à « Hello World » :

Exécuter un autre bloc-notes Synapse
Vous pouvez référencer d’autres bloc-notes dans une activité de bloc-notes Synapse en appelant %run magic ou les utilitaires de bloc-notes mssparkutils. Les deux prennent en charge l’imbrication des appels de fonction. Les principales différences entre ces deux méthodes que vous devez prendre en compte en fonction de votre scénario sont les suivantes :
- %run magic copie toutes les cellules du bloc-notes référencé dans la cellule %run et partage le contexte de la variable. Lorsque notebook1 fait référence notebook2 via
%run notebook2et que notebook2 appelle une fonction mssparkutils.notebook.exit, l’exécution de la cellule dans notebook1 cesse. Nous vous recommandons d’utiliser %run magic quand vous souhaitez « inclure » un fichier de bloc-notes. - Les utilitaires de bloc-notes mssparkutils appellent le bloc-notes référencé comme une méthode ou une fonction. Le contexte de la variable n’est pas partagé. Lorsque notebook1 fait référence notebook2 via
mssparkutils.notebook.run("notebook2")et que notebook2 appelle une fonction mssparkutils.notebook.exit, l’exécution de la cellule dans notebook1 se poursuit. Nous vous recommandons d’utiliser les utilitaires de bloc-notes mssparkutils lorsque vous souhaitez « importer » un bloc-notes.
Consulter l’historique des exécutions d’activité du bloc-notes
Consultez Exécutions de pipeline sous l’onglet Surveillance, vous visualiserez le pipeline que vous avez déclenché. Ouvrez le pipeline qui contient l’activité du bloc-notes pour afficher l’historique des exécutions.
Vous pouvez visualiser la dernière capture instantanée d’exécution de bloc-notes, y compris les deux cellules d’entrée et de sortie en sélectionnant le bouton ouvrir le bloc-notes.
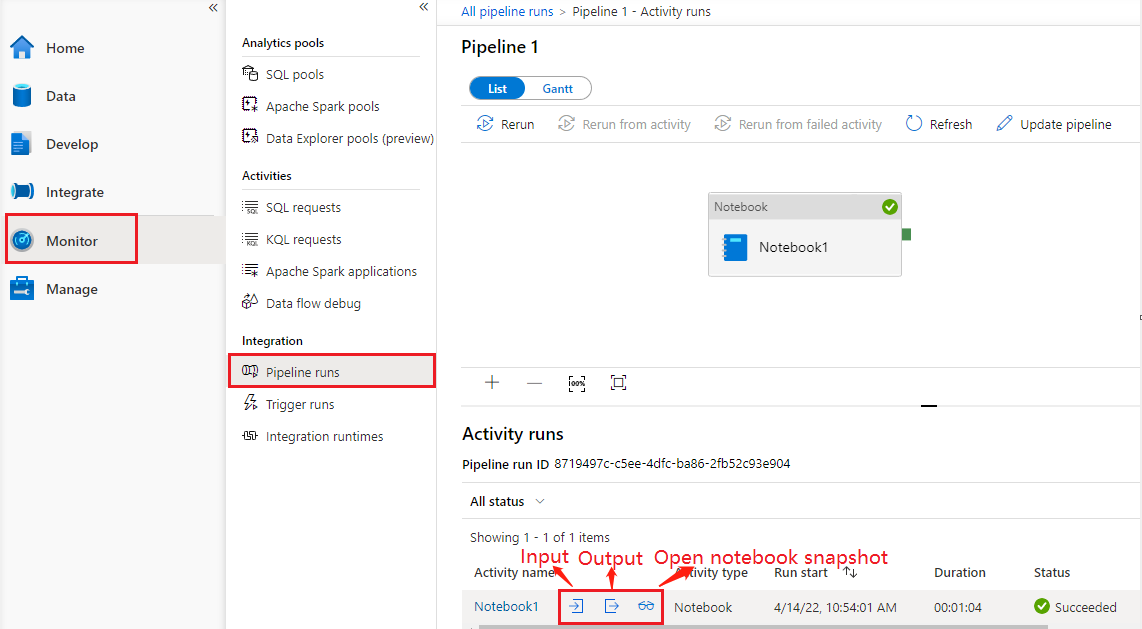
Ouvrez un instantané du notebook :
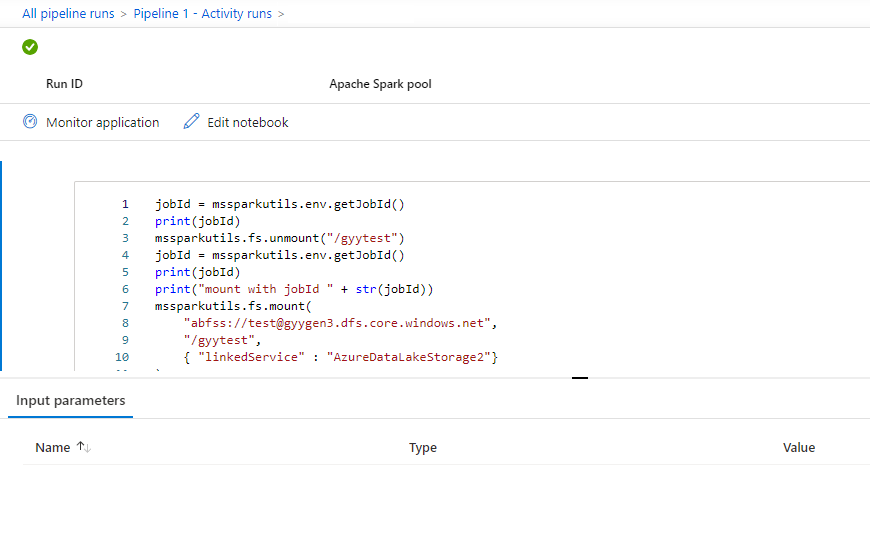
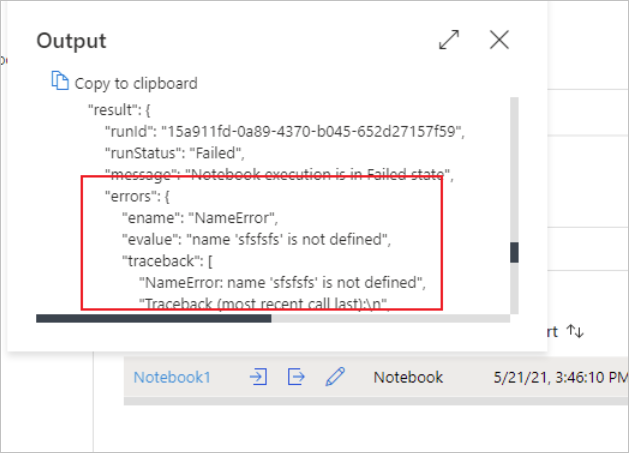
Vous pouvez visualiser les entrées ou les sorties de l’activité du bloc-notes en sélectionnant le bouton entrées ou sorties. Si votre pipeline échoue avec une erreur utilisateur, sélectionnez les sorties pour vérifier le champs résultats et visualiser le traceback détaillé des erreurs de l’utilisateur.
Définition de l’activité de bloc-notes Synapse
Voici l’exemple de définition JSON d’une activité de bloc-notes Synapse :
{
"name": "parameter_test",
"type": "SynapseNotebook",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"notebook": {
"referenceName": "parameter_test",
"type": "NotebookReference"
},
"parameters": {
"input": {
"value": {
"value": "@pipeline().parameters.input",
"type": "Expression"
}
}
}
}
}
Sortie d’activité de bloc-notes Synapse
Voici l’exemple de code JSON d’une sortie d’activité de bloc-notes Synapse :
{
{
"status": {
"Status": 1,
"Output": {
"status": <livySessionInfo>
},
"result": {
"runId": "<GUID>",
"runStatus": "Succeed",
"message": "Notebook execution is in Succeeded state",
"lastCheckedOn": "2021-03-23T00:40:10.6033333Z",
"errors": {
"ename": "",
"evalue": ""
},
"sessionId": 4,
"sparkpool": "sparkpool",
"snapshotUrl": "https://myworkspace.dev.azuresynapse.net/notebooksnapshot/{guid}",
"exitCode": "abc" // return value from user notebook via mssparkutils.notebook.exit("abc")
}
},
"Error": null,
"ExecutionDetails": {}
},
"effectiveIntegrationRuntime": "DefaultIntegrationRuntime (West US 2)",
"executionDuration": 234,
"durationInQueue": {
"integrationRuntimeQueue": 0
},
"billingReference": {
"activityType": "ExternalActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.06666666666666667,
"unit": "Hours"
}
]
}
}
Problèmes connus
Si le nom du notebook est paramétré dans l’activité Notebook de pipeline, la version du notebook dans l’état non publié ne peut pas être référencée dans les exécutions de débogage.