Utiliser .NET pour Apache Spark avec Azure Synapse Analytics
.NET pour Apache Spark fournit un support .NET gratuit, open source et multiplateforme pour Spark.
Il fournit des liaisons .NET pour Spark qui vous permettent d’accéder aux API Spark à l’aide des langages C# et F#. .NET pour Apache Spark vous permet également d’écrire et d’exécuter des fonctions définies par l’utilisateur pour Spark écrites en .NET. Les API .NET pour Spark vous donnent accès à tous les aspects des DataFrames Spark qui vous aident à analyser vos données, dont Spark SQL, Delta Lake et Diffusion en continu structurée.
Vous pouvez analyser des données avec .NET pour Apache Spark par le biais de définitions de programmes de traitement par lots Spark ou avec des blocs-notes Azure Synapse Analytics interactifs. Cet article explique comment utiliser .NET pour Apache Spark avec Azure Synapse à l’aide des deux techniques.
Important
NET pour Apache Spark est un projet open source sous .NET Foundation qui nécessite actuellement la bibliothèque .NET 3.1 qui a atteint l’état de non prise en charge. Nous tenons à informer les utilisateurs d’Azure Synapse Spark de la suppression de la bibliothèque .NET pour Apache Spark dans Runtime Azure Synapse pour Apache Spark version 3.3. Les utilisateurs peuvent se référer à la Stratégie de prise en charge .NET pour obtenir d’autres informations à ce sujet.
Par conséquent, il ne sera plus possible pour les utilisateurs d’utiliser les API Apache Spark via C# et F# ou d’exécuter du code C# dans des notebooks dans Synapse ou via des définitions de tâche Apache Spark dans Synapse. Il est important de noter que cette modification affecte uniquement Runtime Azure Synapse pour Apache Spark 3.3 et versions ultérieures.
Nous continuerons à prendre en charge .NET pour Apache Spark dans toutes les versions antérieures de Runtime Azure Synapse en fonction de leurs phases de cycle de vie. Toutefois, nous ne prévoyons pas de prendre en charge .NET pour Apache Spark dans Runtime Azure Synapse pour Apache Spark 3.3 et versions ultérieures. Nous recommandons aux utilisateurs disposant de charges de travail existantes écrites en C# ou F# de migrer vers Python ou Scala. Nous invitons les utilisateurs à prendre note de ces informations et à planifier en conséquence.
Envoyer des programmes de traitement par lots à l’aide de la définition de travail Spark
Consultez le tutoriel pour apprendre à utiliser Azure Synapse Analytics pour créer des définitions de travaux Apache Spark pour des pools Synapse Spark. Si vous n’avez pas empaqueté votre application pour l’envoyer à Azure Synapse, effectuez les étapes suivantes.
Configurez vos dépendances d’application
dotnetpour la compatibilité avec Synapse Spark. La version .NET Spark requise est notée dans l’interface Synapse Studio sous la configuration du pool Apache Spark, sous la boîte à outils Gérer.
Créez votre projet en tant qu’application console .NET qui génère un exécutable Ubuntu x86.
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.Spark" Version="2.1.0" /> </ItemGroup> </Project>Exécutez les commandes suivantes pour publier votre application. Veillez à remplacer mySparkApp par le chemin d’accès de votre application.
cd mySparkApp dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.18.04-x64Compressez le contenu du dossier de publication,
publish.zippar exemple, qui a été créé à la suite de l’étape 1. Tous les assemblys doivent se trouver à la racine du fichier zip et il ne doit y avoir aucune couche de dossier intermédiaire. Cela signifie que lorsque vous décompressezpublish.zip, tous les assemblys sont extraits dans votre répertoire de travail actuel.Sur Windows :
En utilisant Windows PowerShell ou PowerShell 7, créez un fichier .zip à partir du contenu de votre répertoire de publication.
Compress-Archive publish/* publish.zip -UpdateSur Linux :
Ouvrez un interpréteur de commandes bash et exécutez une commande cd dans le répertoire bin qui contient tous les fichiers binaires publiés, puis exécutez la commande suivante.
zip -r publish.zip
.NET pour Apache Spark dans des blocs-notes Azure Synapse Analytics
Les blocs-notes constituent une excellente option pour le prototypage de vos pipelines et scénarios .NET pour Apache Spark. Vous pouvez commencer à utiliser, comprendre, filtrer, afficher et visualiser vos données rapidement et efficacement.
Les ingénieurs de données, chercheurs de données, analystes d’entreprise et ingénieurs Machine Learning sont tous en mesure de collaborer sur un document interactif partagé. Vous voyez les résultats immédiats de l’exploration de données et pouvez visualiser vos données dans le même bloc-notes.
Comment utiliser .NET pour les blocs-notes Apache Spark
Lorsque vous créez un bloc-notes, vous choisissez un noyau de langage pour exprimer votre logique métier. La prise en charge du noyau est disponible pour plusieurs langages, dont C#.
Pour utiliser .NET pour Apache Spark dans votre notebook Azure Synapse Analytics, sélectionnez .NET Spark (C#) en tant que noyau, puis attachez le notebook à un pool Apache Spark serverless existant.
Le notebook .NET Spark est basé sur des expériences .NET interactives et fournit des expériences C# interactives avec la possibilité d’utiliser .NET pour Spark sans configuration avec la variable de session Spark spark prédéfinie.
Installer des packages NuGet dans des notebooks
Vous pouvez installer les packages NuGet de votre choix dans votre notebook en utilisant la commande magique #r nuget avant le nom du package NuGet. Le diagramme suivant montre un exemple :
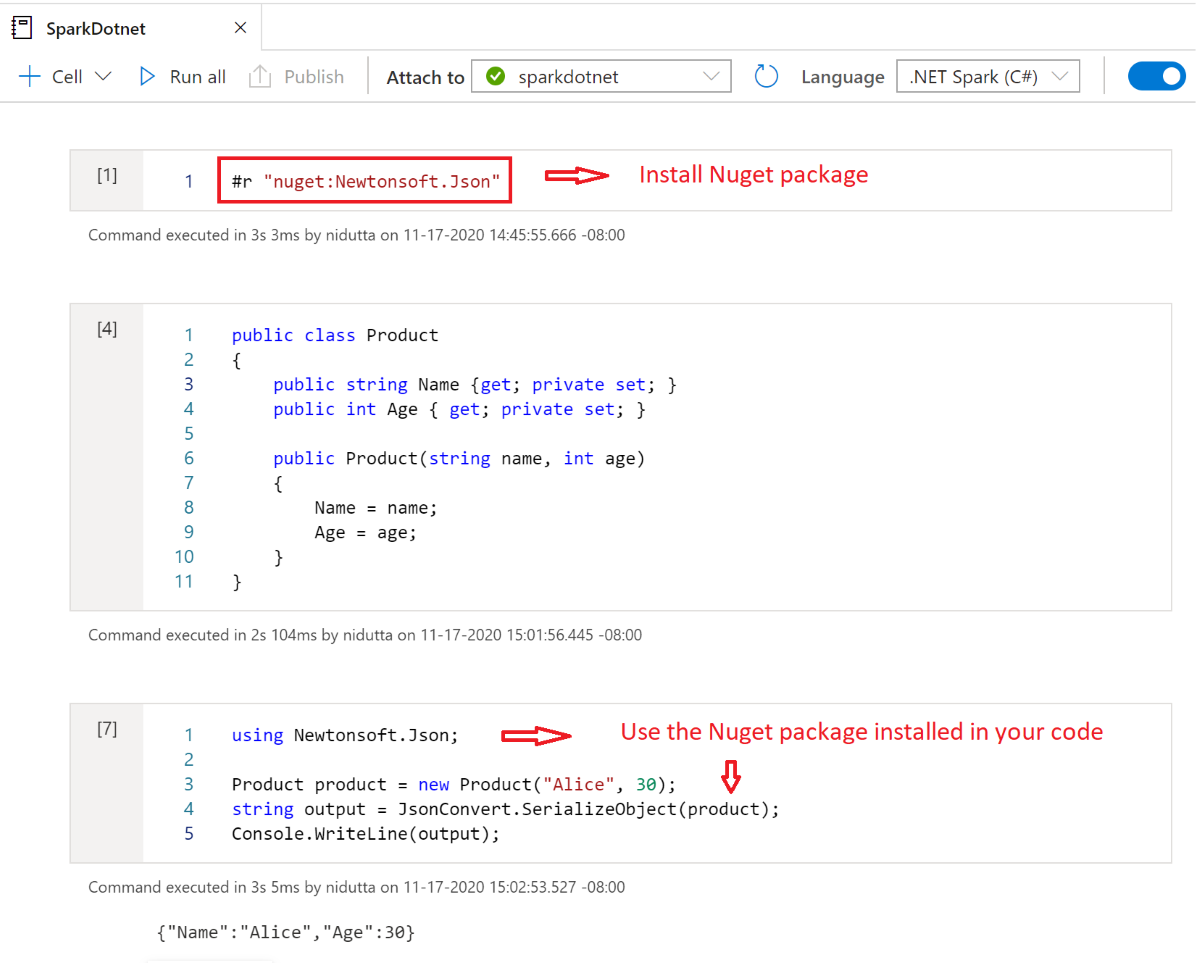
Pour en savoir plus sur l’utilisation des packages NuGet dans des notebooks, consultez la documentation .NET interactive.
.NET pour les fonctionnalités du noyau c# Apache Spark
Lorsque vous utilisez .NET pour Apache Spark dans le bloc-notes Azure Synapse Analytics, vous disposez des fonctionnalités suivantes :
- CODE HTML déclaratif : Générez une sortie à partir de vos cellules à l’aide de la syntaxe HTML, par exemple, des en-têtes, des listes à puces, voire l’affichage d’images.
- Instructions C# simples (affectations, impression sur la console, levée d’exceptions, etc.).
- Blocs de code C# multilignes (instructions if, boucles foreach, définitions de classe, etc.).
- Accès à la bibliothèque C# standard (System, LINQ, Enumerables, etc.).
- Prise en charge de caractéristiques du langage C# 8.0.
sparken tant que variable prédéfinie pour vous donner accès à votre session Apache Spark.- Prise en charge de la définition de fonctions .NET définies par l’utilisateur qui peuvent s’exécuter dans Apache Spark. Nous vous recommandons de lire Écrire et appeler des fonctions définies par l’utilisateur dans des environnements interactifs .NET pour Apache Spark pour apprendre à utiliser les fonctions définies par l’utilisateur dans des expériences interactives .NET pour Apache Spark.
- Prise en charge de la visualisation de la sortie de vos travaux Spark à l’aide de différents graphiques (en courbes, à barres, etc.) et dispositions (simple, superposée, etc.) à l’aide de la bibliothèque
XPlot.Plotly. - Possibilité d’inclure des packages NuGet dans votre bloc-notes C#.
Dépannage
DotNetRunner: null / Futures timeout dans l’exécution d’une définition de travail Synapse Spark
Les définitions de travaux Synapse Spark sur les pools Spark avec Spark 2.4 nécessitent Microsoft.Spark 1.0.0. Effacez vos répertoires bin et obj publiez le projet en utilisant la version 1.0.0.
OutOfMemoryError : espace de tas java à org.apache.spark
Dotnet Spark 1.0.0 utilise une architecture de débogage différente de la version 1.1.1+. Vous devez utiliser 1.0.0 pour votre version publiée et 1.1.1+ pour le débogage local.