Présentation d’Apache Spark dans Azure Synapse Analytics
Apache Spark est une infrastructure de traitement parallèle qui prend en charge le traitement en mémoire pour améliorer les performances des applications d’analytique du Big Data. Apache Spark dans Azure Synapse Analytics est l’une des implémentations par Microsoft d’Apache Spark dans le cloud. Azure Synapse facilite la création et la configuration d’un pool Apache Spark serverless dans Azure. Les pools Spark dans Azure Synapse sont compatibles avec Stockage Azure et le stockage Azure Data Lake Generation 2. Vous pouvez donc utiliser des pools Spark pour traiter vos données stockées dans Azure.
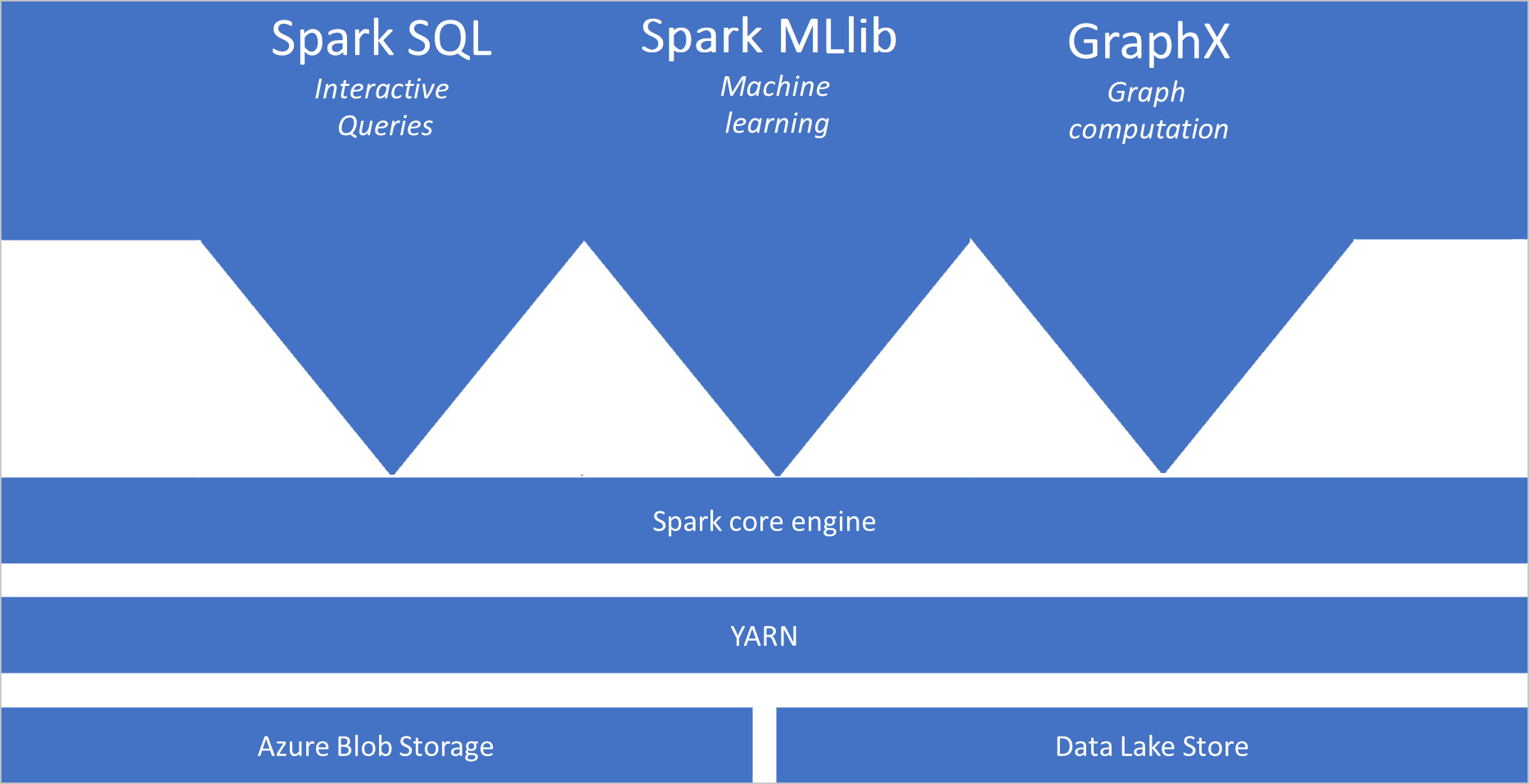
Qu’est-ce qu’Apache Spark ?
Apache Spark fournit des primitives pour le calcul de cluster en mémoire. Un travail Spark peut charger et mettre en cache des données en mémoire et les interroger à plusieurs reprises. Le calcul en mémoire est plus rapide que les applications sur disque. Spark s’intègre également à plusieurs langages de programmation pour vous permettre de manipuler des jeux de données distribués tels que des collections locales. Il n’est pas nécessaire de tout structurer comme des opérations de réduction et de mappage. Pour en savoir plus, consultez la vidéo Apache Spark pour Synapse.
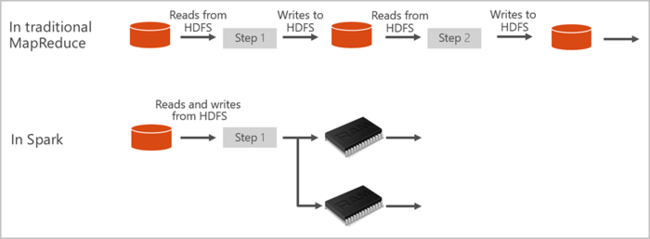
Les pools Spark dans Azure Synapse offrent un service Spark complètement managé. Les avantages de la création d’un pool Spark dans Azure Synapse Analytics sont listés ici.
| Fonctionnalité | Description |
|---|---|
| Vitesse et efficacité | Les instances Spark démarrent en environ deux minutes pour moins de 60 nœuds, et environ cinq minutes pour plus de 60 nœuds. Par défaut, l’instance s’arrête cinq minutes après l’exécution du dernier travail, sauf si elle est maintenue active par une connexion de notebook. |
| Facilité de création | Vous pouvez créer un pool Spark dans Azure Synapse en quelques minutes à l’aide du portail Azure, d’Azure PowerShell ou du SDK .NET Synapse Analytics. Consultez Bien démarrer avec les pools Spark dans Azure Synapse Analytics. |
| Simplicité d'utilisation | Synapse Analytics comprend un notebook personnalisé dérivé de nteract. Vous pouvez utiliser les blocs-notes pour le traitement interactif et la visualisation des données. |
| API REST | Spark dans Azure Synapse Analytics comprend Apache Livy, serveur de travaux Spark basé sur une API REST qui permet de soumettre et de superviser à distance des travaux. |
| Prise en charge d’Azure Data Lake Storage Generation 2 | Les pools Spark dans Azure Synapse peuvent utiliser Azure Data Lake Storage Generation 2 et le stockage d’objets blob. Pour plus d’informations sur Data Lake Storage, consultez Vue d’ensemble d’Azure Data Lake Storage. |
| Intégration à des environnements de développement intégrés tiers | Azure Synapse fournit un plug-in d’IDE pour IntelliJ IDEA de JetBrains, qui est utile pour créer et soumettre des applications à un pool Spark. |
| Bibliothèques Anaconda préchargées | Les pools Spark dans Azure Synapse sont fournis avec des bibliothèques Anaconda préinstallées. Anaconda fournit près de 200 bibliothèques pour l’apprentissage automatique, l’analyse des données, la visualisation, et d’autres technologies. |
| Extensibilité | La mise à l’échelle automatique peut être activée pour les pools Apache Spark dans Azure Synapse. Ils peuvent ainsi être adaptés par ajout ou suppression de nœuds en fonction des besoins. De plus, les pools Spark peuvent être arrêtés sans perte de données puisque toutes les données sont stockées dans Stockage Azure ou Data Lake Storage. |
Les pools Spark dans Azure Synapse incluent les composants suivants qui sont disponibles sur les pools par défaut :
- Spark Core. Comprend Spark Core, Spark SQL, GraphX et MLlib.
- Anaconda
- Apache Livy
- Notebook nteract
Architecture de pool Spark
Les applications Spark s’exécutent sous la forme d’ensembles de processus indépendants sur un pool, coordonnées par l’objet SparkContext du programme principal (appelé programme pilote).
Le SparkContext peut se connecter au gestionnaire de cluster, qui alloue des ressources aux différentes applications. Le gestionnaire de cluster est Apache Hadoop YARN. Une fois connecté, Spark acquiert des exécuteurs sur les nœuds du pool ; il s’agit de processus qui exécutent des calculs et stockent les données de l’application. Ensuite, il envoie le code de l’application (défini par les fichiers JAR ou Python transmis à SparkContext) aux exécuteurs. Enfin, SparkContext envoie les tâches aux exécuteurs, qui les exécuteront.
Le SparkContext exécute la fonction principale de l’utilisateur et les différentes opérations parallèles sur les nœuds. Ensuite, le SparkContext collecte les résultats des opérations. Les nœuds lisent et écrivent des données dans le système de fichiers. Ils mettent également en cache les données transformées en mémoire en tant que jeux de données résilients distribués (RDD).
Le SparkContext se connecte au pool Spark et est responsable de la conversion d’une application en graphe orienté acyclique (DAG). Le graphe se compose de tâches individuelles qui s’exécutent dans un processus de l’exécuteur sur les nœuds. Chaque application obtient ses propres processus d’exécution qui restent actifs pendant l’exécution de l’application et exécutent des tâches dans plusieurs threads.
Cas d’usage Apache Spark dans Azure Synapse Analytics
Les pools Spark dans Azure Synapse Analytics autorisent les scénarios clés suivants :
- Engineering données/Préparation des données
Apache Spark comprend de nombreuses fonctionnalités de langage pour prendre en charge la préparation et le traitement de grands volumes de données, afin de leur apporter une valeur ajoutée et de les rendre consommables par d’autres services au sein d’Azure Synapse Analytics. Cela est possible grâce aux différents langages (C#, Scala, PySpark, Spark SQL) et aux bibliothèques fournies pour le traitement et la connectivité.
- Machine Learning
Apache Spark est fourni avec MLlib, bibliothèque de Machine Learning basée sur Spark que vous pouvez utiliser à partir d’un pool Spark dans Azure Synapse Analytics. Les pools Spark dans Azure Synapse Analytics incluent également Anaconda, distribution Python avec divers packages pour la science des données, dont l’apprentissage automatique. Tout ceci, combiné à la prise en charge intégrée des notebooks, vous permet de disposer d’un environnement pour créer des applications de Machine Learning.
- Diffusion en continu de données
Synapse Spark prend en charge Spark Structured Streaming tant que vous exécutez la version prise en charge du runtime Azure Synapse Spark. Tous les travaux sont pris en charge pour une durée de vie de sept jours. Ceci s’applique aux travaux de traitement par lots et de streaming. Généralement, les clients automatisent le processus de redémarrage à l’aide d’Azure Functions.
Contenu connexe
Consultez les articles suivants pour en savoir plus sur Apache Spark dans Azure Synapse Analytics :
- Démarrage rapide : Créer un pool Spark dans Azure Synapse
- Démarrage rapide : Créer un notebook Apache Spark
- Tutoriel : Machine Learning avec Apache Spark
Remarque
Une partie de la documentation Apache Spark officielle repose sur l’utilisation de la console Spark qui n’est pas disponible sur Azure Synapse Spark. Utilisez à la place les expériences notebook ou IntelliJ.