Gérer la configuration Apache Spark
Découvrez dans cet article comment créer une configuration Apache Spark pour votre Synapse Studio. La configuration Apache Spark créée peut être gérée de manière normalisée et lorsque vous créez un bloc-notes ou une définition de travail Apache Spark, vous pouvez sélectionner la configuration Apache Spark que vous souhaitez utiliser avec votre pool Apache Spark. Lorsque vous le sélectionnez, les détails de la configuration s’affichent.
Créer une configuration pour Apache Spark
Vous pouvez créer des configurations personnalisées à partir de différents points d’entrée, comme à partir de la page de configuration Apache Spark d’un pool Spark existant.
Créer des configurations personnalisées dans les configurations Apache Spark
Suivez les étapes ci-dessous pour créer une configuration Apache Spark dans Synapse Studio.
Sélectionnez Gérer>Configurations Apache Spark.
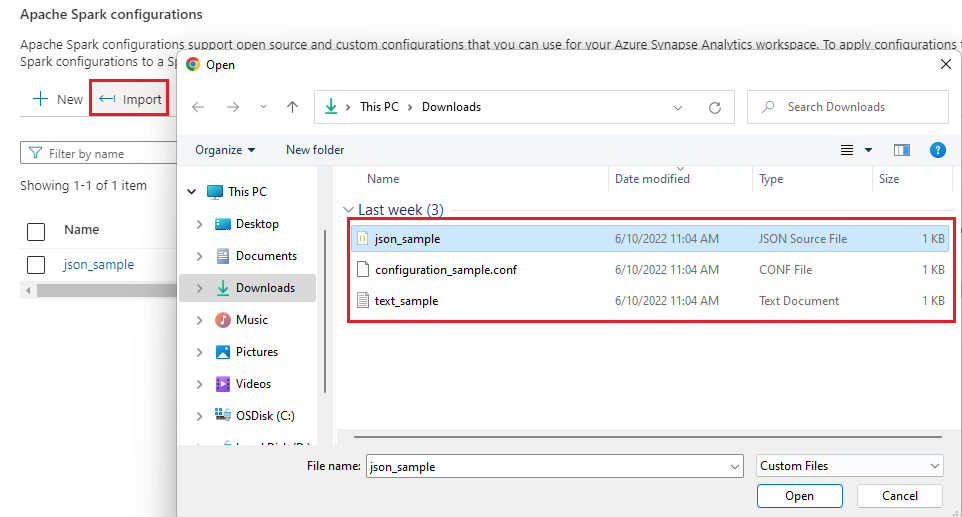
Sélectionnez le bouton Nouveau pour créer une configuration Apache Spark, ou sélectionnez Importer pour un fichier .json local dans votre espace de travail.
La page Nouvelle configuration Apache Spark s’ouvre une fois que vous avez sélectionné le bouton Nouveau.
Pour Nom, vous pouvez entrer votre nom préféré valide.
Pour Description, vous pouvez entrer une description.
Pour Annotations, vous pouvez ajouter des annotations en cliquant sur le bouton Nouveau, et vous pouvez également supprimer des annotations existantes en sélectionnant et en cliquant sur le bouton Supprimer.
Pour les Propriétés de configuration, personnalisez la configuration en cliquant sur le bouton Ajouter afin d’ajouter des propriétés. Si vous n’ajoutez pas de propriété, Azure Synapse utilise la valeur par défaut, le cas échéant.
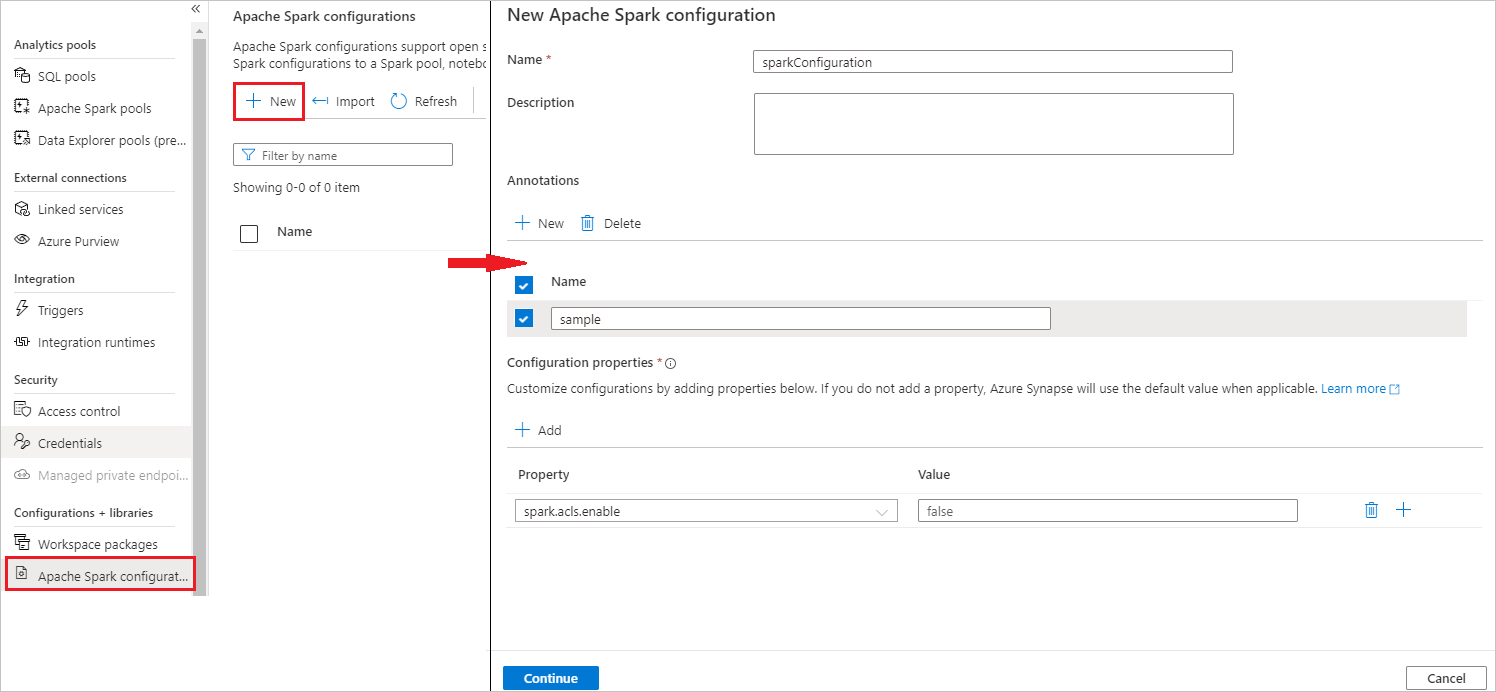
Sélectionnez le bouton Continuer.
Sélectionnez le bouton Créer lorsque la validation a réussi.
Publier tout.
Remarque
La fonctionnalité Charger la configuration Apache Spark a été supprimée.
Les pools utilisant une configuration chargée doivent être mis à jour. Mettez à jour la configuration de votre pool en sélectionnant une configuration existante ou en créant une nouvelle configuration dans le menu Configuration Apache Spark pour le pool. Si aucune nouvelle configuration n’est sélectionnée, les travaux de ces pools sont exécutés à l’aide de la configuration par défaut dans les paramètres système de Spark.
Créer une configuration Apache Spark dans un pool Apache Spark existant
Suivez les étapes ci-dessous pour créer une configuration Apache Spark dans un pool Apache Spark existant.
Sélectionnez un pool Apache Spark existant, puis sélectionnez le bouton d’action « ... ».
Sélectionnez la configuration Apache Spark dans la liste de contenu.
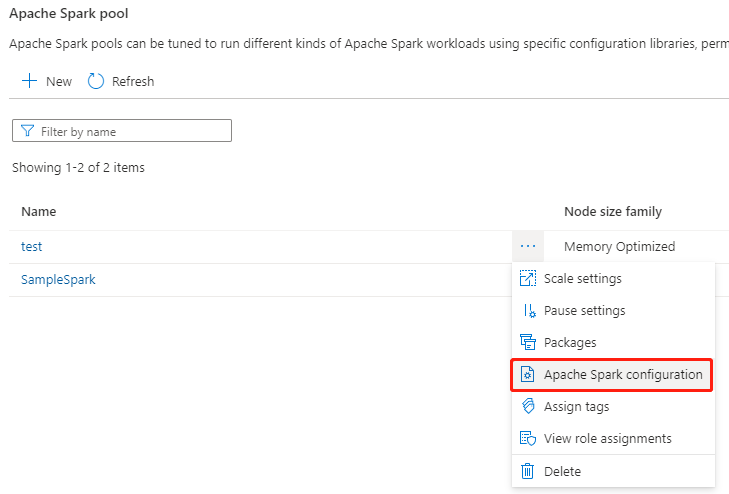
Pour la configuration d’Apache Spark, vous pouvez sélectionner une configuration déjà créée dans la liste déroulante, ou sélectionner +Nouveau pour créer une configuration.
Si vous sélectionnez +Nouveau, la page Configuration d’Apache Spark s’ouvre et vous pouvez créer une nouvelle configuration en suivant les étapes décrites dans Créer des configurations personnalisées dans les configurations Apache Spark.
Si vous sélectionnez une configuration existante, les détails de la configuration s’affichent en bas de la page, vous pouvez également sélectionner le bouton Modifier pour modifier la configuration existante.
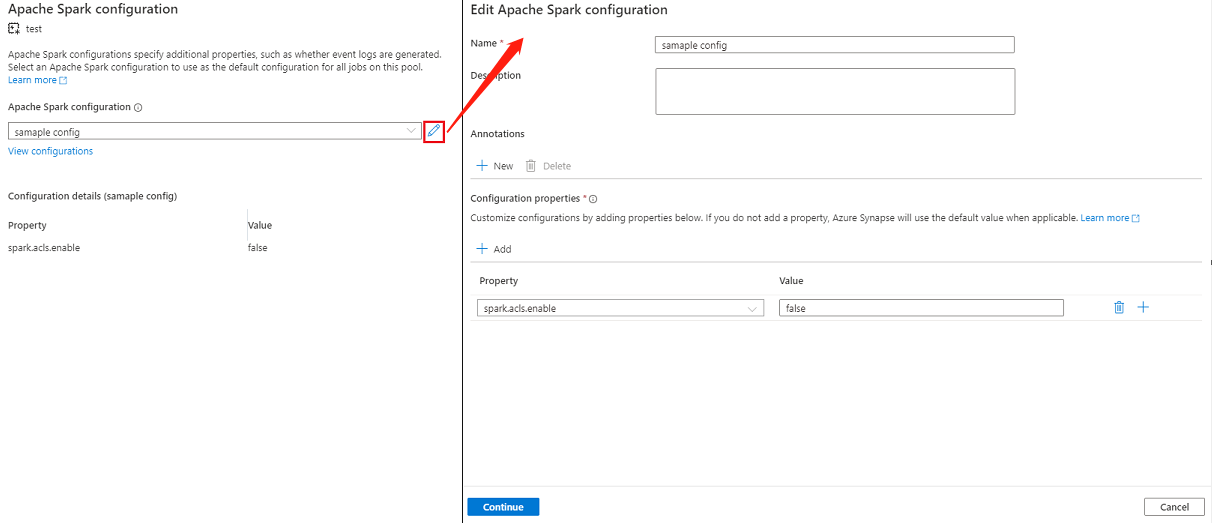
Sélectionnez Afficher les configurations pour ouvrir la page Sélectionner une configuration. Toutes les configurations s’affichent sur cette page. Vous pouvez sélectionner une configuration que vous souhaitez utiliser sur ce pool Apache Spark.
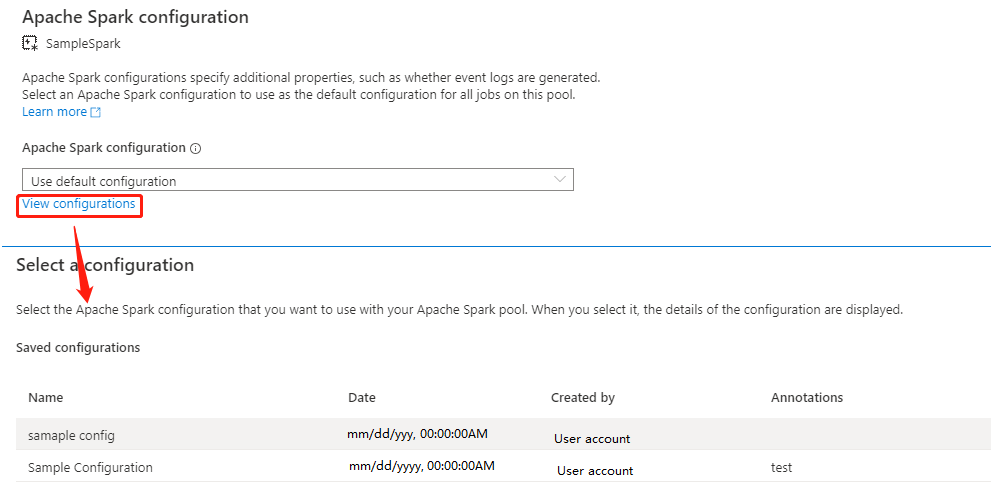
Sélectionnez le bouton Appliquer pour enregistrer vos actions.
Créer une configuration Apache Spark dans la session de configuration du notebook
Si vous devez utiliser une configuration Apache Spark personnalisée lors de la création d’un notebook, vous pouvez la créer et la configurer dans la session de configuration en suivant les étapes ci-dessous.
Ouvrez/créez un notebook.
Ouvrez les propriétés de ce notebook.
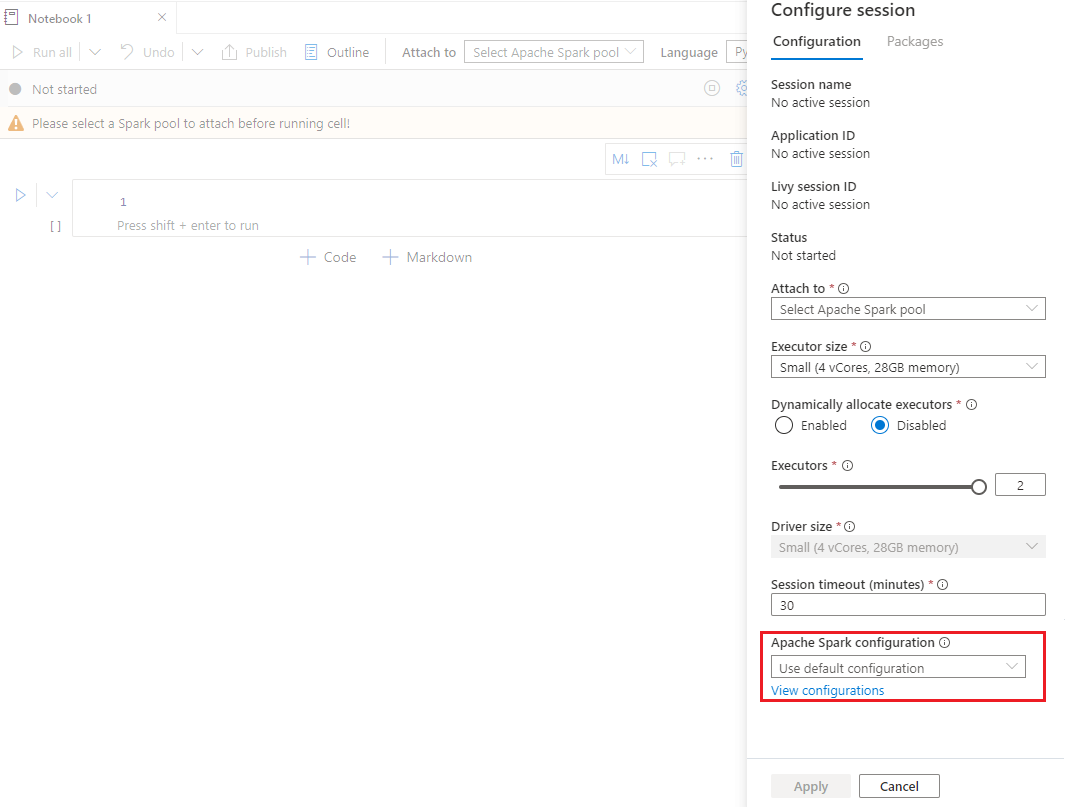
Sélectionnez Configurer la session pour ouvrir la page Configurer la session.
Faites défiler la page Configurer la session, pour la configuration d’Apache Spark et développez le menu déroulant. Vous pouvez sélectionner le bouton Nouveau pour créer une nouvelle configuration. Sinon, sélectionnez une configuration existante. Si vous sélectionnez une configuration existante, sélectionnez l’icône Modifier pour accéder à la page de configuration Modifier Apache Spark pour modifier la configuration.
Sélectionnez Afficher les configurations pour ouvrir la page Sélectionner une configuration. Toutes les configurations s’affichent sur cette page. Vous pouvez sélectionner une configuration que vous souhaitez utiliser.
Créer une configuration Apache Spark dans les définitions de travaux Apache Spark
Lorsque vous créez une définition de tâche Spark, vous devez utiliser la configuration Apache Spark, qui peut être créée en suivant les étapes ci-dessous :
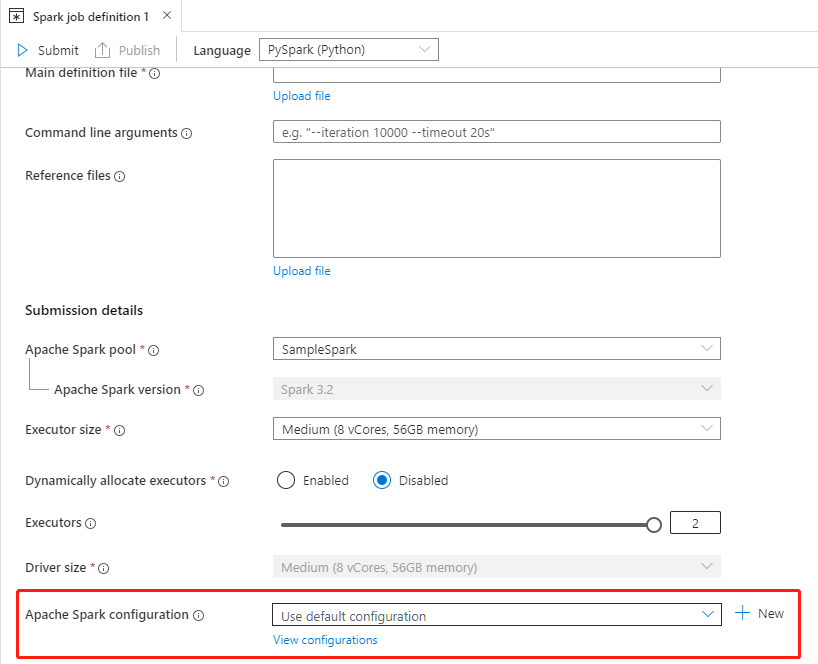
Créez/Ouvrez une définition de tâche Apache Spark existante.
Pour Configuration d’Apache Spark, vous pouvez sélectionner le bouton Nouveau pour créer une nouvelle configuration. Ou sélectionnez une configuration existante dans le menu déroulant, si vous sélectionnez une configuration existante, sélectionnez l’icône Modifier pour accéder à la page de configuration Modifier Apache Spark et modifier la configuration.
Sélectionnez Afficher les configurations pour ouvrir la page Sélectionner une configuration. Toutes les configurations s’affichent sur cette page. Vous pouvez sélectionner une configuration que vous souhaitez utiliser.
Notes
Si la configuration Apache Spark dans la définition de travail Notebook et Apache Spark ne fait rien de spécial, la configuration par défaut est utilisée lors de l’exécution du travail.
Importer et exporter une configuration Apache Spark
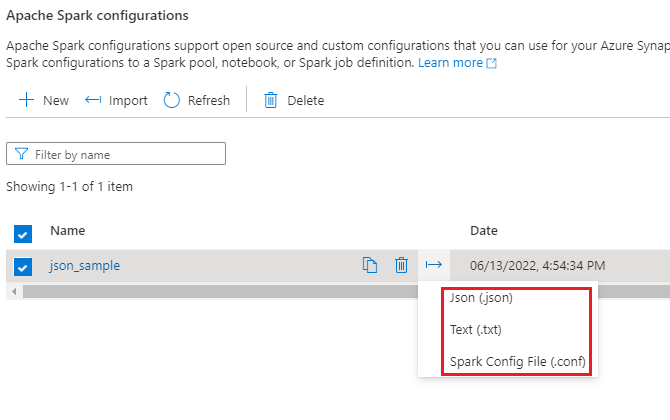
Vous pouvez importer le configuration .txt/.conf/.json dans trois formats, puis la convertir en artefact et la publier. Et peut également s’exporter vers l’un de ces trois formats.
Importez la configuration .txt/.conf/.json à partir de local.
Exportez la configuration .txt/.conf/.json vers local.
Pour le fichier de config .txt et le fichier de configuration .conf, vous pouvez consulter les exemples suivants :
spark.synapse.key1 sample
spark.synapse.key2 true
# spark.synapse.key3 sample2
Pour le fichier de config .json, vous pouvez vous référer aux exemples suivants :
{
"configs": {
"spark.synapse.key1": "hello world",
"spark.synapse.key2": "true"
},
"annotations": [
"Sample"
]
}
Remarque
Synapse Studio continuera à prendre en charge les fichiers de configuration basés sur bicep ou terraform.