Démarrage rapide : Transformer des données à l’aide d’une définition de travail Apache Spark
Dans ce guide de démarrage rapide, vous vous servez d’Azure Synapse Analytics pour créer un pipeline au moyen d’une définition de travail Apache Spark.
Prérequis
- Abonnement Azure : Si vous n’avez pas d’abonnement Azure, créez un compte Azure gratuit avant de commencer.
- Espace de travail Azure Synapse : créez un espace de travail Synapse à l’aide du portail Azure en suivant les instructions fournies dans Démarrage rapide : Créer un espace de travail Synapse.
- Définition de travail Apache Spark : créez une définition de travail Apache Spark dans l’espace de travail Synapse en suivant les instructions du Tutoriel : Créer une définition de travail Apache Spark dans Synapse Studio.
Accéder à Synapse Studio
Après avoir créé votre espace de travail Azure Synapse, vous pouvez ouvrir Synapse Studio de deux manières :
- Ouvrez votre espace de travail Synapse dans le Portail Azure. Sélectionnez Ouvrir sur la carte Ouvrir Synapse Studio dans la section Démarrage.
- Ouvrez Azure Synapse Analytics et connectez-vous à votre espace de travail.
Dans ce guide de démarrage rapide, nous utilisons l’espace de travail nommé « sampletest » comme exemple.
Créer un pipeline avec une définition de travail Apache Spark
Un pipeline contient le flux logique pour l’exécution d’un ensemble d’activités. Dans cette section, vous créez un pipeline qui contient une activité de définition de travail Apache Spark.
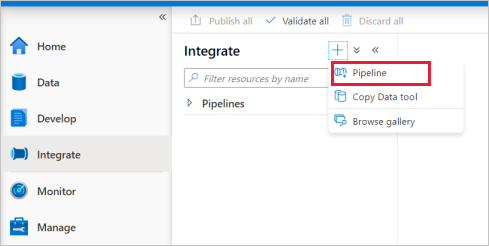
Accédez à l’onglet Intégrer. Sélectionnez l’icône plus (+) située en regard de l’en-tête Pipelines, puis sélectionnez Pipeline.
Dans la page des paramètres Propriétés du pipeline, entrez demo en guise de Nom.
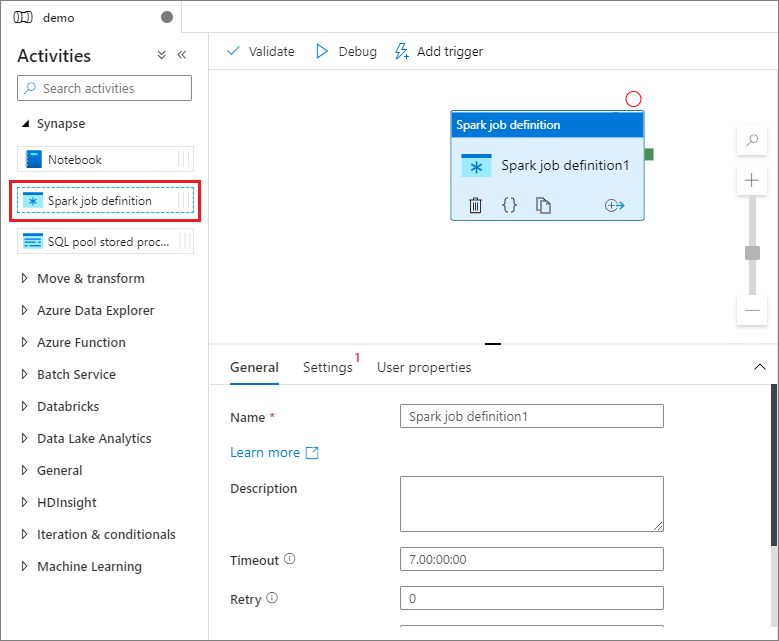
Sous Synapse, dans le volet Activités, faites glisser la Définition de travail Spark jusqu’au canevas du pipeline.
Définir le canevas de définition de travail Apache Spark
Après avoir créé votre définition de travail Apache Spark, vous accédez automatiquement au canevas de définition de travail Spark.
Paramètres généraux :
Sélectionnez le module de définition de travail Spark sur le canevas.
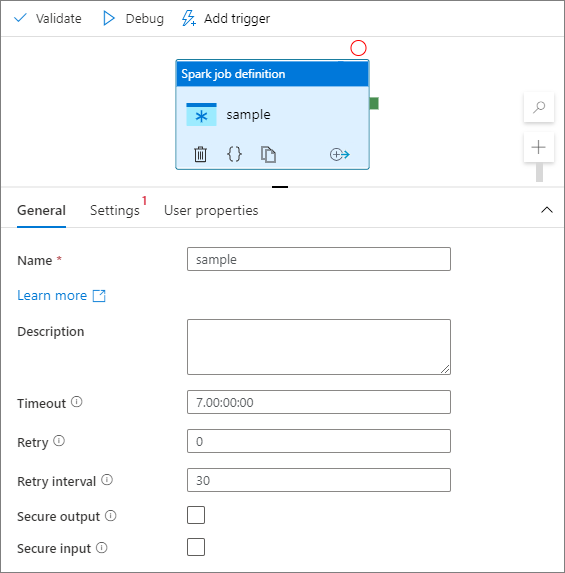
Sous l’onglet Général, entrez sample en guise de Nom.
(Facultatif) Vous pouvez également indiquer une description.
Délai : durée maximale pendant laquelle une activité peut s’exécuter. La valeur par défaut est de sept jours, ce qui correspond également à la durée maximale autorisée. Le format est J.HH:MM:SS.
Réessayer : nombre maximal de nouvelles tentatives.
Intervalle avant nouvelle tentative : nombre de secondes entre les nouvelles tentatives.
Sortie sécurisée : quand cette option est cochée, la sortie de l’activité n’est pas capturée dans la journalisation.
Entrée sécurisée : quand cette option est cochée, l’entrée de l’activité n’est pas capturée dans la journalisation.
Onglet Paramètres
Dans ce panneau, vous pouvez référencer la définition de travail Spark à exécuter.
Développez la liste des définitions de travail Spark, vous pouvez choisir une définition de travail Apache Spark existante. Vous pouvez également créer une définition de travail Apache Spark en sélectionnant le bouton Nouveau pour référencer la définition de travail Spark à exécuter.
(Facultatif) Renseignez les informations pour la définition de travail Apache Spark. Si les paramètres suivants sont vides, les paramètres de la définition de travail Spark lui-même sont utilisés pour l’exécution. Si les paramètres suivants ne sont pas vides, ils remplacent ceux de la définition de travail Spark elle-même.
Propriété Description Fichier de définition principal Fichier principal utilisé pour le travail. Sélectionnez un fichier PY/JAR/ZIP à partir de votre stockage. Vous pouvez sélectionner Charger le fichier pour charger le fichier sur un compte de stockage.
Exemple :abfss://…/path/to/wordcount.jarRéférences des sous-dossiers En analysant les sous-dossiers à partir du dossier racine du fichier de définition principal, ces fichiers sont ajoutés en tant que fichiers de référence. Les dossiers nommés « jars », « pyFiles », « files » ou « archives » sont analysés. Le nom des dossiers respecte la casse. Main class name Identificateur complet ou classe principale qui se trouve dans le fichier de définition principal.
Exemple :WordCountArguments de ligne de commande Vous pouvez ajouter des arguments de ligne de commande en cliquant sur le bouton Nouveau. Notez que l’ajout d’arguments de ligne de commande remplace ceux définis par la définition de travail Spark.
Exemple :abfss://…/path/to/shakespeare.txtabfss://…/path/to/resultPool Apache Spark Vous pouvez sélectionner un pool Apache Spark dans la liste. Informations de référence sur le code Python Autres fichiers de code Python utilisés pour référence dans le fichier de définition principal.
Il prend en charge le passage de fichiers (.py, .py3, .zip) à la propriété « pyFiles ». Il remplace la propriété « pyFiles » définie dans la définition de travail Spark.Fichiers de référence Autres fichiers utilisés pour référence dans le fichier de définition principal. Allouer dynamiquement des exécuteurs Ce paramètre correspond à la propriété d’allocation dynamique dans la configuration Spark pour allouer des exécuteurs d’application Spark. Nombre minimal d’exécuteurs Nombre minimal d'exécuteurs à allouer dans le pool Spark spécifié pour le travail. Nombre maximal d’exécuteurs Nombre maximal d'exécuteurs à allouer dans le pool Spark spécifié pour le travail. Taille du pilote Nombre de cœurs et mémoire à utiliser pour le pilote dans le pool Apache Spark spécifié du travail. Configuration Spark Spécifiez les valeurs des propriétés de configuration de Spark listées dans l’article suivant : Configuration de Spark – Propriétés de l’application. Les utilisateurs peuvent utiliser la configuration par défaut et la configuration personnalisée. 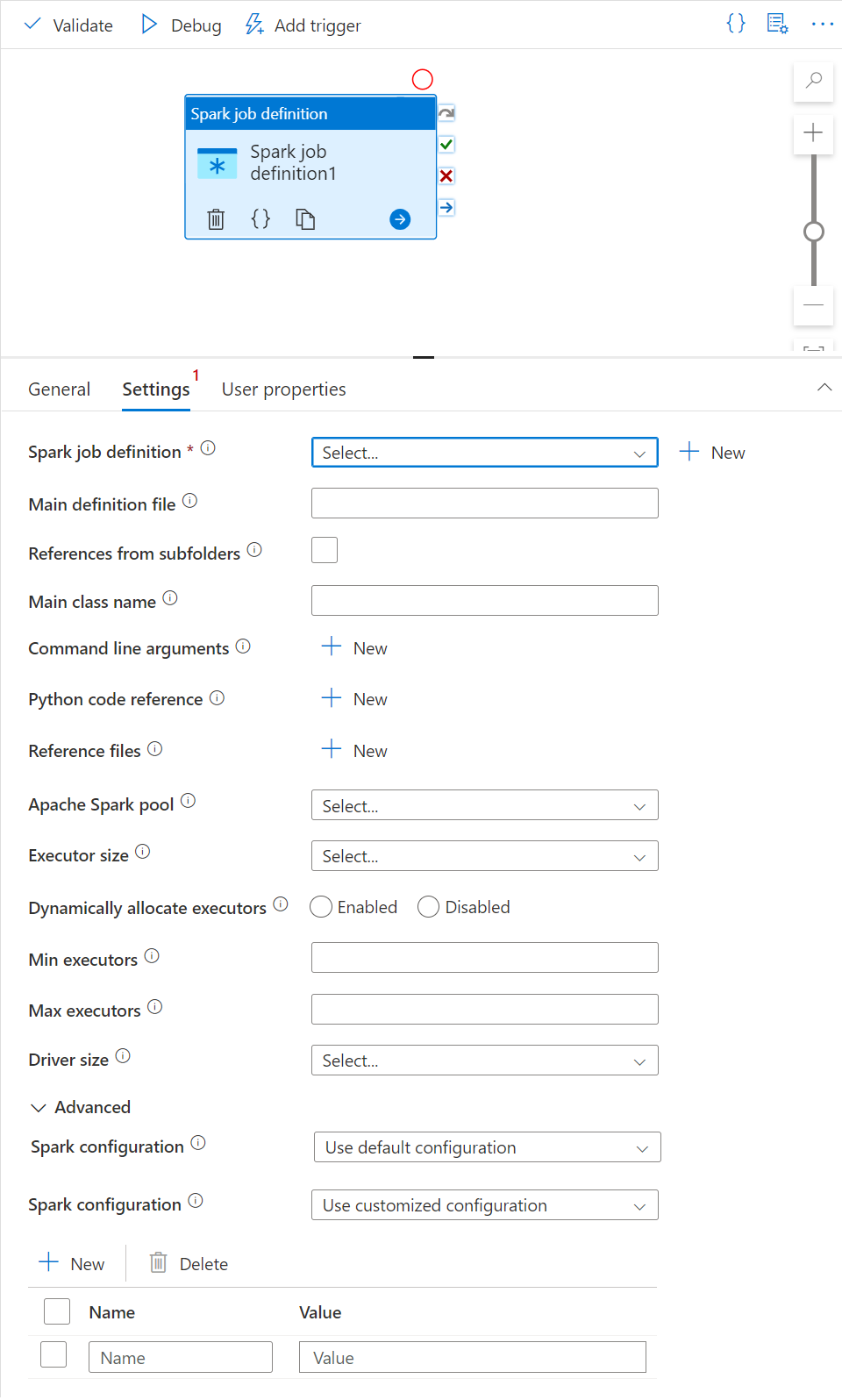
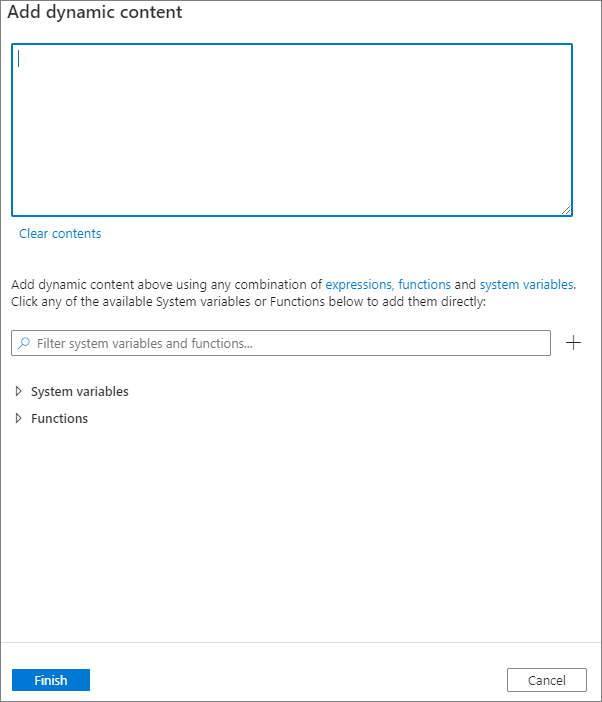
Vous pouvez ajouter du contenu dynamique en cliquant sur le bouton Ajouter du contenu dynamique ou en appuyant sur la touche de raccourci Alt+Maj+D. Dans la page Ajouter du contenu dynamique, vous pouvez utiliser n’importe quelle combinaison d’expressions, de fonctions et de variables système à ajouter au contenu dynamique.
Onglet Propriétés de l’utilisateur
Dans ce panneau, vous pouvez ajouter des propriétés pour une activité de définition de travail Apache Spark.

Contenu connexe
Lisez les articles suivant pour en savoir plus sur la prise en charge d’Azure Synapse Analytics :