Tutoriel : Analyse de texte avec Azure AI services
Dans ce didacticiel, vous apprendrez à utiliser l’analyse de texte pour analyser du texte non structuré sur Azure Synapse Analytics. Analyse de texte est un service Azure AI services qui vous permet de réaliser des opérations d’exploration de texte et d’analyse de texte avec des fonctionnalités de traitement du langage naturel (NLP).
Ce tutoriel montre comment utiliser l’analyse de texte avec SynapseML pour :
- Détecter les étiquettes de sentiment au niveau de la phrase ou du document
- Identifier la langue pour une entrée de texte donnée
- Reconnaître les entités d’un texte avec des liens vers une base de connaissances connue
- Extraire les phrases clés d’un texte
- Identifier des entités différentes dans le texte et les classer dans des classes ou des types prédéfinis
- Identifier et éditer des entités sensibles dans un texte donné
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
- Espace de travail Azure Synapse Analytics avec un compte de stockage Azure Data Lake Storage Gen2 configuré comme stockage par défaut. Vous devez être le contributeur aux données Blob de stockage du système de fichiers Data Lake Storage Gen2 que vous utilisez.
- Pool Spark dans votre espace de travail Azure Synapse Analytics. Pour plus d’informations, consultez Créer un pool Spark dans Azure Synapse.
- Étapes de préconfiguration décrites dans le didacticiel Configurer Azure AI services dans Azure Synapse.
Démarrage
Ouvrez Synapse Studio et créez un nouveau notebook. Pour commencer, importez SynapseML.
import synapse.ml
from synapse.ml.services import *
from pyspark.sql.functions import col
Configurer l’analyse de texte
Utilisez l’analyse de texte liée que vous avez configurée dans les étapes de préconfiguration.
linked_service_name = "<Your linked service for text analytics>"
Sentiment du texte
Avec l’analyse textuelle des sentiments, vous pouvez obtenir des étiquettes de sentiment (telles que « négatif », « neutre » et « positif ») et des scores de confiance au niveau de la phrase et du document. Consultez les langues prises en charge dans l’API Analyse de texte pour obtenir la liste des langages activés.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("I am so happy today, it's sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The Azure AI services on spark aint bad", "en-US"),
], ["text", "language"])
# Run the Text Analytics service with options
sentiment = (TextSentiment()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
# Show the results of your text query in a table format
results = sentiment.transform(df)
display(results
.withColumn("sentiment", col("sentiment").getItem("document").getItem("sentences")[0].getItem("sentiment"))
.select("text", "sentiment"))
Résultats attendus
| texte | sentiment |
|---|---|
| Je suis tellement heureux qu’il fasse beau aujourd’hui ! | positif |
| Cette circulation aux heures de pointe est insupportable | négatif |
| Azure AI services sur Spark n’est pas mauvais | neutre |
Détecteur de langage
Le Détecteur de langage évalue l’entrée de texte pour chaque document de texte et retourne les identificateurs de langage avec un score qui indique la puissance de l’analyse. Cette capacité est utile pour les magasins de contenu qui collectent du texte arbitraire dont la langue est inconnue. Consultez les langues prises en charge dans l’API Analyse de texte pour obtenir la liste des langages activés.
# Create a dataframe that's tied to it's column names
df = spark.createDataFrame([
("Hello World",),
("Bonjour tout le monde",),
("La carretera estaba atascada. Había mucho tráfico el día de ayer.",),
("你好",),
("こんにちは",),
(":) :( :D",)
], ["text",])
# Run the Text Analytics service with options
language = (LanguageDetector()
.setLinkedService(linked_service_name)
.setTextCol("text")
.setOutputCol("language")
.setErrorCol("error"))
# Show the results of your text query in a table format
display(language.transform(df))
Résultats attendus
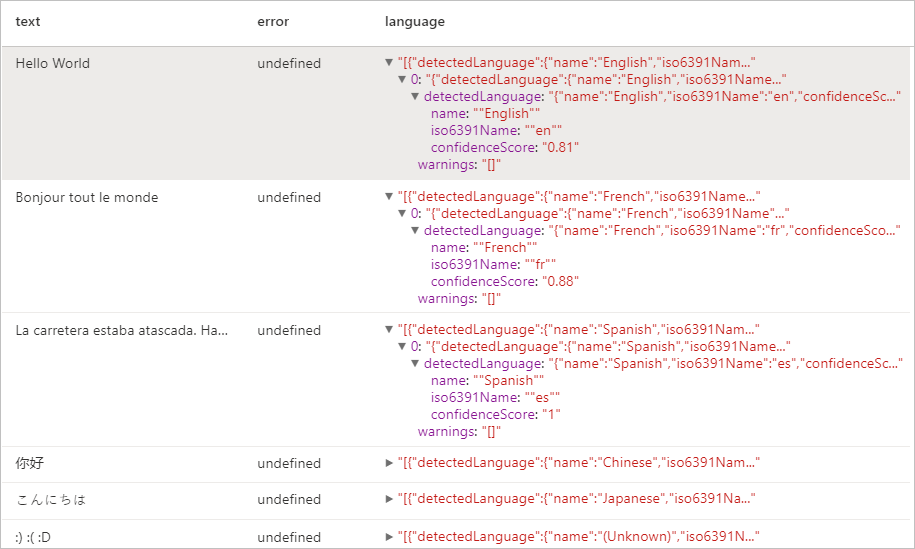
Détecteur d’entité
Le Détecteur d’entité retourne une liste d’entités reconnues avec des liens vers une base de connaissances connue. Consultez les langues prises en charge dans l’API Analyse de texte pour obtenir la liste des langages activés.
df = spark.createDataFrame([
("1", "Microsoft released Windows 10"),
("2", "In 1975, Bill Gates III and Paul Allen founded the company.")
], ["if", "text"])
entity = (EntityDetector()
.setLinkedService(linked_service_name)
.setLanguage("en")
.setOutputCol("replies")
.setErrorCol("error"))
display(entity.transform(df).select("if", "text", col("replies").getItem("document").getItem("entities").alias("entities")))
Résultats attendus
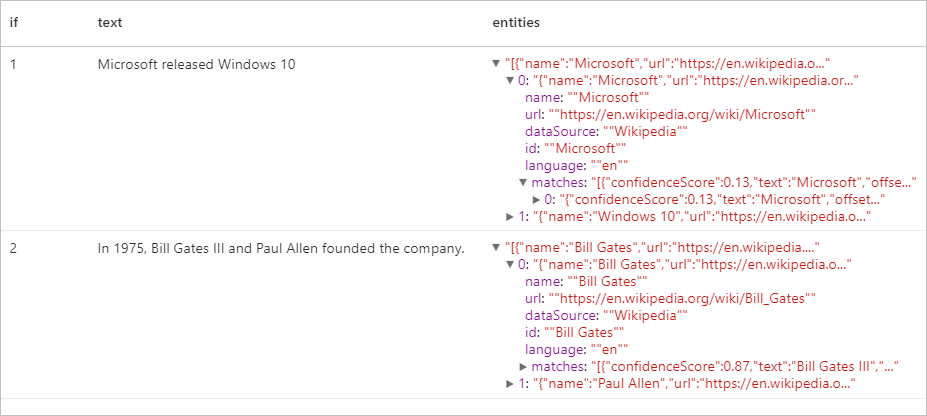
Extraction de phrases clés
L’Extraction de phrases clés évalue un texte non structuré et retourne une liste de phrases clés. Cette fonctionnalité est utile si vous avez besoin d’identifier rapidement les principaux points d’une collection de documents. Consultez les langues prises en charge dans l’API Analyse de texte pour obtenir la liste des langages activés.
df = spark.createDataFrame([
("en", "Hello world. This is some input text that I love."),
("fr", "Bonjour tout le monde"),
("es", "La carretera estaba atascada. Había mucho tráfico el día de ayer.")
], ["lang", "text"])
keyPhrase = (KeyPhraseExtractor()
.setLinkedService(linked_service_name)
.setLanguageCol("lang")
.setOutputCol("replies")
.setErrorCol("error"))
display(keyPhrase.transform(df).select("text", col("replies").getItem("document").getItem("keyPhrases").alias("keyPhrases")))
Résultats attendus
| texte | keyPhrases |
|---|---|
| Hello World. Il s’agit d’un texte d’entrée que j’aime. | "["Hello world","input text"]" |
| Bonjour tout le monde | "["Bonjour","monde"]" |
| La carretera estaba atascada. Había mucho tráfico el día de ayer. | "["mucho tráfico","día","carretera","ayer"]" |
Reconnaissance d’entité nommée (NER)
La reconnaissance d’entité nommée (NER) est la capacité d’identifier différentes entités dans du texte et de les catégoriser en classes ou types prédéfinis tels que : personne, lieu, événement, produit et organisation. Consultez les langues prises en charge dans l’API Analyse de texte pour obtenir la liste des langages activés.
df = spark.createDataFrame([
("1", "en", "I had a wonderful trip to Seattle last week."),
("2", "en", "I visited Space Needle 2 times.")
], ["id", "language", "text"])
ner = (NER()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(ner.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Résultats attendus
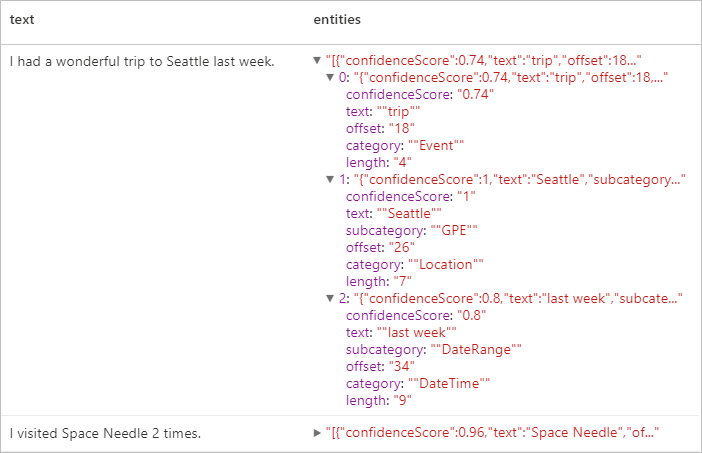
Informations d’identification personnelle (PII) v3.1
La fonctionnalité PII fait partie de la reconnaissance d’entité nommée et peut identifier et éditer des entités sensibles dans du texte qui sont associées à un individu comme les suivantes : numéro de téléphone, adresse e-mail, adresse postale, numéro de passeport. Consultez les langues prises en charge dans l’API Analyse de texte pour obtenir la liste des langages activés.
df = spark.createDataFrame([
("1", "en", "My SSN is 859-98-0987"),
("2", "en", "Your ABA number - 111000025 - is the first 9 digits in the lower left hand corner of your personal check."),
("3", "en", "Is 998.214.865-68 your Brazilian CPF number?")
], ["id", "language", "text"])
pii = (PII()
.setLinkedService(linked_service_name)
.setLanguageCol("language")
.setOutputCol("replies")
.setErrorCol("error"))
display(pii.transform(df).select("text", col("replies").getItem("document").getItem("entities").alias("entities")))
Résultats attendus
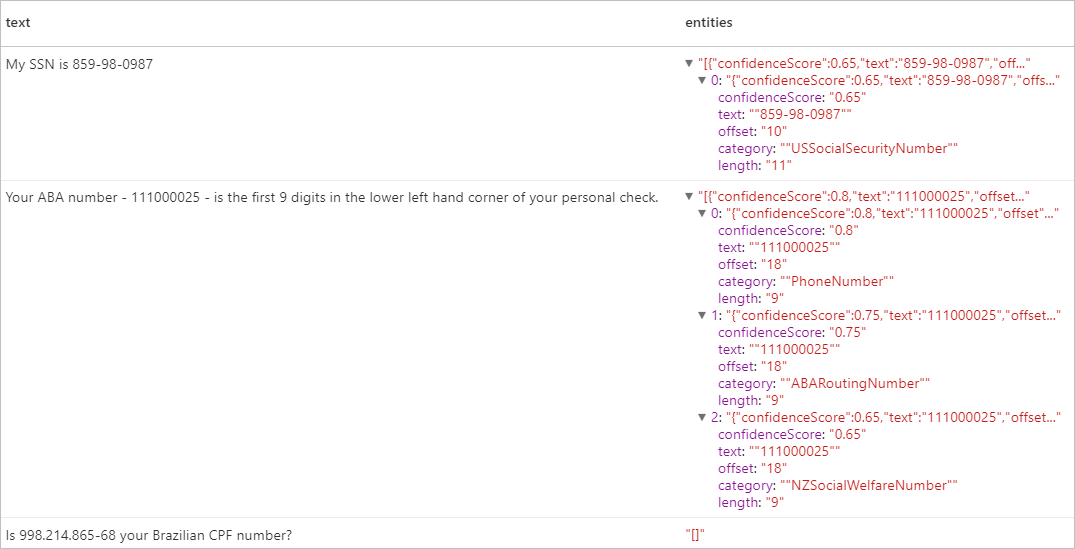
Nettoyer les ressources
Pour vous assurer que l’instance Spark est arrêtée, mettez fin aux sessions connectées (notebooks). Le pool s’arrête quand la durée d’inactivité spécifiée dans le pool Apache Spark est atteinte. Vous pouvez également sélectionner Arrêter la session dans la barre d’état en haut à droite du notebook.
