Optimiser les performances des partages de fichiers lors de l’accès à des répertoires de grande taille depuis des clients Linux
Cet article fournit des recommandations sur l’utilisation de répertoires qui contiennent un grand nombre de fichiers. Il est généralement recommandé de réduire le nombre de fichiers dans un répertoire unique en répartissant les fichiers sur plusieurs répertoires. Toutefois, il existe des situations dans lesquelles les grands répertoires ne peuvent pas être évités. Prenez en compte les suggestions suivantes lors de l’utilisation de répertoires de grande taille sur des partages de fichiers Azure montés sur des clients Linux.
S’applique à
| Type de partage de fichiers | SMB | NFS |
|---|---|---|
| Partages de fichiers Standard (GPv2), LRS/ZRS |
|
|
| Partages de fichiers Standard (GPv2), GRS/GZRS |
|
|
| Partages de fichiers Premium (FileStorage), LRS/ZRS |
|
|
Options de montage recommandées
Les options de montage suivantes sont spécifiques à l’énumération et peuvent réduire la latence lors de l’utilisation de répertoires volumineux.
actimeo
La spécification de actimeo définit tous les paramètres acregmin, acregmax, acdirmin et acdirmax sur la même valeur. Si actimeo n’est pas spécifié, le client utilise les valeurs par défaut pour chacune de ces options.
Nous vous recommandons de définir actimeo entre 30 et 60 secondes lors de l’utilisation de répertoires volumineux. La définition d’une valeur dans cette plage rend les attributs valides pendant une période plus longue dans le cache d’attributs du client, ce qui permet aux opérations d’obtenir des attributs de fichier à partir du cache au lieu de les extraire sur le réseau. Cela peut réduire la latence dans les situations où les attributs mis en cache expirent pendant l’exécution de l’opération.
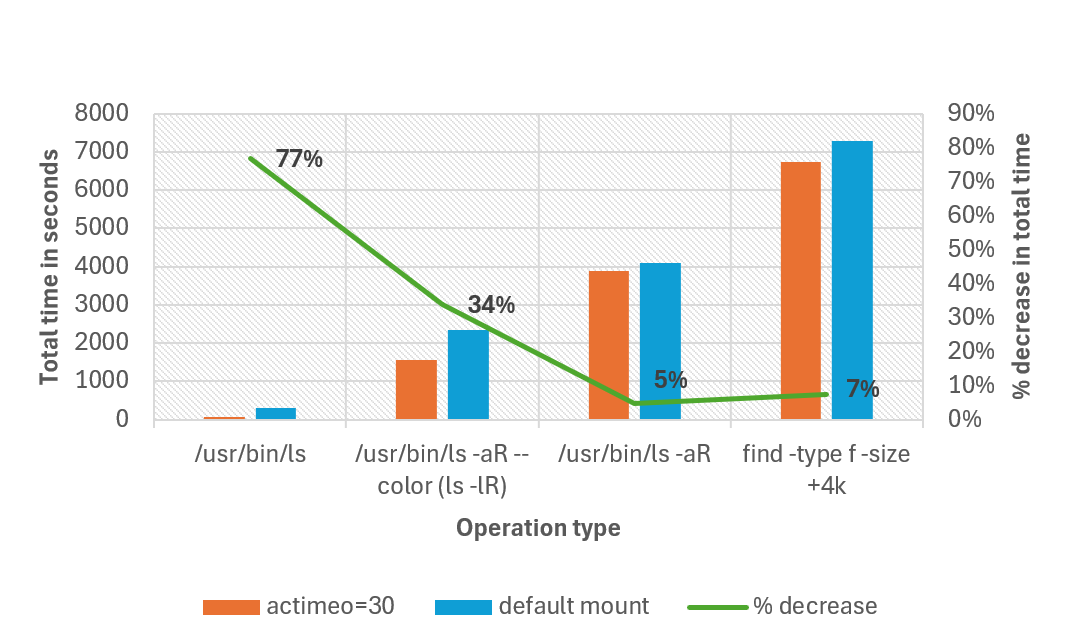
Le graphique suivant compare le temps total nécessaire pour terminer différentes opérations avec le montage par défaut par rapport à la définition d’une valeur actimeo de 30 pour une charge de travail qui a 1 million de fichiers dans un seul répertoire. Dans nos tests, le temps d’achèvement total a diminué de 77 % pour certaines opérations. Toutes les opérations ont été effectuées avec ls nonalias.
nconnect
Nconnect est une option de montage côté client pour les partages de fichiers NFS qui vous permet d’utiliser plusieurs connexions TCP entre le client et le service Azure Premium Files pour NFSv4.1. Nous recommandons le paramètre optimal de nconnect=4 pour réduire la latence et améliorer les performances.
Nconnect peut être particulièrement utile pour les charges de travail qui utilisent des E/S asynchrones ou synchrones à partir de plusieurs threads.
Plus d’informations
Augmenter le nombre de compartiments de hachage
La quantité totale de RAM présente sur le système effectuant l’énumération influence le travail interne des protocoles de système de fichiers tels que NFS et SMB. Même si les utilisateurs ne sont pas confrontés à une utilisation élevée de la mémoire, la quantité de mémoire disponible influence le nombre de compartiments de hachage inode dont dispose le système, ce qui a un impact/améliore les performances de l’énumération pour les répertoires de grande taille. Vous pouvez modifier le nombre de compartiments de hachage inode dont dispose le système pour réduire les collisions de hachage qui peuvent se produire lors des charges de travail d’énumération de grande taille.
Pour cela, vous devez modifier le paramètres de votre configuration de démarrage en fournissant une commande de noyau supplémentaire qui prend effet lors du démarrage pour augmenter le nombre de compartiments de hachage de nœud. Procédez comme suit.
En utilisant un éditeur de texte, ouvrez le fichier
/etc/default/grub.sudo vim /etc/default/grubAjoutez le texte suivant au fichier
/etc/default/grub. Cette commande va réserver 128 Mo pour la taille de la table de hachage inode, ce qui augmente la consommation de mémoire système d’un maximum de 128 Mo.GRUB_CMDLINE_LINUX="ihash_entries=16777216"Si
GRUB_CMDLINE_LINUXexiste déjà, ajoutezihash_entries=16777216séparé par un espace, comme suit :GRUB_CMDLINE_LINUX="<previous commands> ihash_entries=16777216"Pour appliquer les modifications, exécutez :
sudo update-grub2Redémarrez le système :
sudo rebootPour vérifier que les modifications ont pris effet, une fois le système redémarré, vérifiez les commandes cmdline du noyau :
cat /proc/cmdlineSi
ihash_entriesest visible, cela signifie que le système a appliqué le paramètre : les performances de l’énumération devraient donc s’améliorer de façon exponentielle.Vous pouvez également vérifier la sortie de dmesg pour voir si la cmdline du noyau a été appliquée :
dmesg | grep "Inode-cache hash table" Inode-cache hash table entries: 16777216 (order: 15, 134217728 bytes, linear)
Commandes et opérations
La façon dont les commandes et les opérations sont spécifiées peut également affecter les performances. La liste de tous les fichiers d’un répertoire volumineux à l’aide de la commande ls est un bon exemple.
Remarque
Certaines opérations telles que les lsrécursives, les findet les du ont besoin à la fois de noms de fichiers et d’attributs de fichier, de sorte qu’elles combinent des énumérations de répertoire (pour obtenir les entrées) avec une statistique sur chaque entrée (pour obtenir les attributs). Nous vous suggérons d’utiliser une valeur plus élevée pour actimeo sur les points de montage où vous êtes susceptible d’exécuter ces commandes.
Utiliser ls nonalias
Dans certaines distributions Linux, l’interpréteur de commandes définit automatiquement les options par défaut de la commande ls, comme ls --color=auto. Cela modifie le fonctionnement de ls sur le réseau et ajoute d’autres opérations à l’exécution ls. Pour éviter la dégradation des performances, nous vous recommandons d’utiliser des ls sans alias. Vous pouvez effectuer l’une des trois manières suivantes :
Supprimez l’alias à l’aide de la commande
unalias ls. Il s’agit uniquement d’une solution temporaire pour la session active.Pour une modification permanente, vous pouvez modifier l’alias
lsdans le fichierbashrc/bash_aliasesde l’utilisateur. Dans Ubuntu, modifiez~/.bashrcpour supprimer l’alias dels.Au lieu d’appeler
ls, vous pouvez appeler directement lelsbinaire, par exemple/usr/bin/ls. Cela vous permet d’utiliserlssans aucune option susceptible d’être dans l’alias. Vous pouvez trouver l’emplacement du fichier binaire en exécutant la commandewhich ls.
Empêcher ls de trier sa sortie
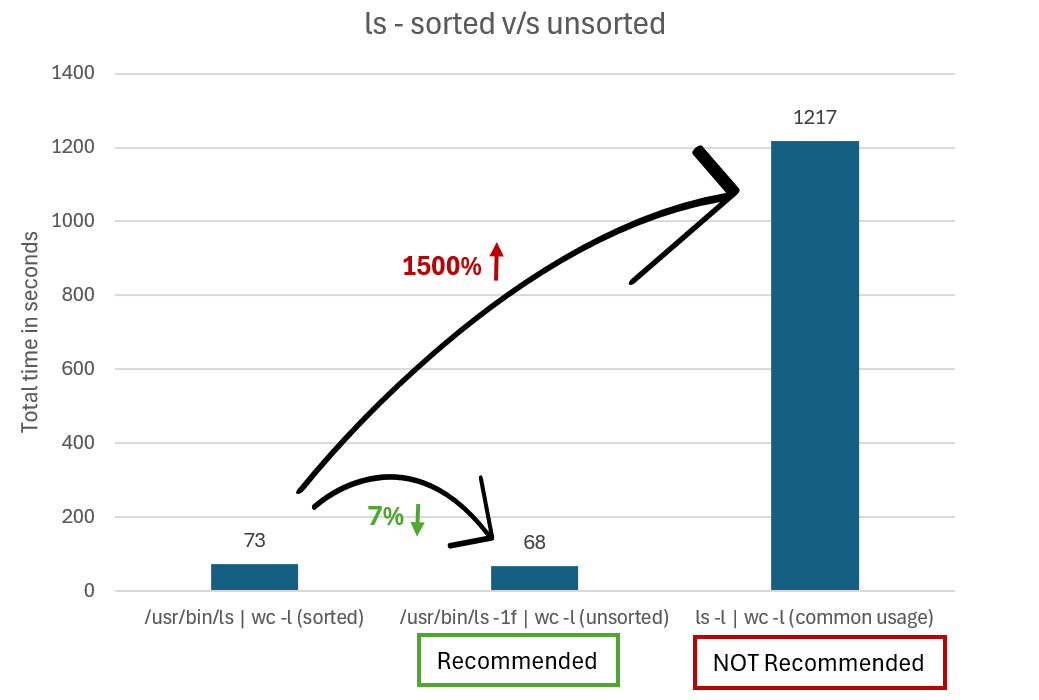
Lorsque vous utilisez ls avec d’autres commandes, vous pouvez améliorer les performances en empêchant ls de trier sa sortie dans les situations où vous ne vous souciez pas de l’ordre dans lequel ls retourne les fichiers. Le tri de la sortie ajoute une surcharge significative.
Au lieu d’exécuter ls -l | wc -l pour obtenir le nombre total de fichiers, vous pouvez utiliser les options -f ou -U avec ls pour empêcher la sortie d’être triée. La différence est que -f affiche également les fichiers masqués et -U ne le fera pas.
Par exemple, si vous appelez directement le binaire ls dans Ubuntu, vous exécutez /usr/bin/ls -1f | wc -l ou /usr/bin/ls -1U | wc -l.
Le graphique suivant compare le temps nécessaire pour générer des résultats à l’aide de ls non trié et ls non trié.
Opérations de copie et de sauvegarde de fichiers
Lors de la copie de données depuis un partage de fichiers ou de la sauvegarde depuis des partages de fichiers vers un autre emplacement, nous vous recommandons d’utiliser comme source un instantané du partage au lieu du partage de fichiers en direct avec des E/S actives. Les applications de sauvegarde doivent exécuter des commandes directement sur l’instantané. Pour plus d’informations, consultez Utiliser des instantanés de partage avec Azure Files.
Recommandations au niveau de l’application
Quand vous développez des applications qui utilisent des répertoires de grande taille, suivez ces recommandations.
Ignorez les attributs de fichier. Si l’application a uniquement besoin du nom de fichier et non des attributs de fichier comme le type de fichier ou l’heure de dernière modification, vous pouvez utiliser plusieurs appels aux appels système tels que
getdents64avec une bonne taille de mémoire tampon. Cela permet d’obtenir les entrées dans le répertoire spécifié sans le type de fichier, ce qui accélère l’opération en évitant les opérations supplémentaires qui ne sont pas nécessaires.Entrelacer les appels statistiques. Si l’application a besoin d’attributs et du nom de fichier, nous vous recommandons d’entrelacer les appels statistiques avec
getdents64au lieu d’obtenir toutes les entrées jusqu’à la fin du fichier avecgetdents64, puis d’effectuer un statx sur toutes les entrées retournées. L’entrelacement des appels de la commande stat indique au client de demander en même temps à la fois le fichier et ses attributs, ce qui réduit le nombre d’appels au serveur. En cas de combinaison avec une valeur deactimeoélevée, cela peut améliorer considérablement les performances. Par exemple, au lieu de[ getdents64, getdents64, ... , getdents64, statx (entry1), ... , statx(n) ], placez les appels statx après chaquegetdents64comme suit :[ getdents64, (statx, statx, ... , statx), getdents64, (statx, statx, ... , statx), ... ].Augmentez la profondeur d’E/S. Si possible, nous vous suggérons de configurer
nconnectsur une valeur différente de zéro (supérieure à 1) et de distribuer l’opération entre plusieurs threads ou à l’aide d’E/S asynchrones. Cela permet aux opérations qui peuvent être asynchrones pour tirer parti de plusieurs connexions simultanées au partage de fichiers.Cache d’utilisation forcée. Si l’application interroge les attributs de fichier sur un partage de fichiers que seul un client a monté, utilisez l’appel système statx avec l’indicateur de
AT_STATX_DONT_SYNC. Cet indicateur garantit que les attributs mis en cache sont récupérés à partir du cache sans synchroniser avec le serveur, ce qui évite les allers-retours réseau supplémentaires pour obtenir les données les plus récentes.