Réplication des messages et fédération interrégionale
Dans les espaces de noms, Azure Service Bus prend en charge la création de topologies de files d’attente chaînées et d’abonnements de rubriques à l’aide du transfert automatique, permettant l’implémentation de différents modèles de routage. Par exemple, vous pouvez fournir aux partenaires des files d’attente dédiées pour lesquelles ils disposent d’autorisations d’envoi ou de réception, pouvant être temporairement suspendues si nécessaire, et qu’ils peuvent connecter de manière flexible à d’autres entités privées de l’application. Vous pouvez également créer des topologies de routage à plusieurs étapes complexes, ou créer des files d’attente de type boîte aux lettres, qui drainent les abonnements de type file d’attente et permettent d’augmenter la capacité de stockage par abonné.
De nombreuses solutions sophistiquées nécessitent également la réplication des messages entre les limites de l’espace de noms afin d’implémenter ces modèles et d’autres. Il peut être nécessaire de transmettre les messages entre les espaces de noms associés avec plusieurs clients d’application différents, ou entre plusieurs régions Azure différentes.
Votre solution gérera plusieurs espaces de noms de Service Bus dans différentes régions, et répliquera des messages entre les files d’attente et les rubriques, et/ou vous échangerez des messages avec des sources et des cibles comme Azure Event Hubs, Azure IoT Hub ou Apache Kafka.
Ces scénarios sont présentés dans cet article.
Modèles de fédération
Il existe de nombreuses raisons pour lesquelles vous souhaiterez déplacer des messages entre des entités Service Bus telles que des files d’attente ou des rubriques, ou entre Service Bus et d’autres sources et cibles.
Comparée à l’ensemble similaire de modèles pour Event Hubs, la fédération pour les entités de type file d’attente est plus complexe, car les files d’attente de messages promettent à leurs consommateurs la propriété exclusive sur un message unique, sont censées conserver l’ordre de remise des messages, et permettent au répartiteur de coordonner la distribution équitable des messages entre des consommateurs concurrents.
Il existe des obstacles pratiques, y compris les contraintes du théorème CAP, qui rendent difficile la création d’une vue unifiée d’une file d’attente disponible simultanément dans plusieurs régions et permettant une distribution régionale afin que des consommateurs concurrents disposent de la propriété exclusive des messages. Une telle file d’attente géodistribuée nécessiterait une réplication totalement cohérente non seulement des messages, mais également de l’état de remise de chaque message avant que des messages puissent être mis à la disposition des consommateurs. L’objectif d’une cohérence totale pour une file d’attente hypothétique et distribuée dans le secteur rentre en conflit direct avec l’objectif clé de la plupart des clients Azure Service Bus dans le cadre de scénarios de fédération : une disponibilité et une fiabilité maximales pour leurs solutions.
Les modèles présentés ici s’intéressent donc à la disponibilité et à la fiabilité, tout en cherchant à mieux éviter la perte d’informations et la gestion des messages en double.
Résilience face aux événements de disponibilité régionale
Bien que la disponibilité et la fiabilité maximales soient les principales priorités opérationnelles de Service Bus, il existe néanmoins de nombreuses raisons pour lesquelles un producteur ou un consommateur peut être incapable de communiquer avec le « principal » Service Bus qui lui a été attribué, en raison de problèmes de mise en réseau ou de résolution de noms, ou pour lesquelles une entité Service Bus ne répond temporairement plus ou renvoie des erreurs. Le processeur de messages désigné peut également devenir indisponible.
De telles conditions ne sont pas « désastreuses » au point de vouloir abandonner complètement le déploiement régional comme vous pourriez le faire dans une situation de récupération d’urgence, mais le scénario d’entreprise de certaines applications pourrait déjà être concerné par des événements de disponibilité qui ne durent pas plus de quelques minutes voire quelques secondes. Azure Service Bus est souvent utilisé dans les environnements cloud hybrides et avec des clients qui résident à la périphérie du réseau, par exemple dans les magasins de vente au détail, les restaurants, les succursales de banques, les sites de production, les infrastructures logistiques et les aéroports. Un problème de routage ou de congestion du réseau peut impacter la capacité d’un site à atteindre son point de terminaison Service Bus attribué, alors qu’un point de terminaison secondaire dans une autre région peut être accessible. Parallèlement, les systèmes qui traitent les messages provenant de ces sites peuvent toujours avoir un accès sans entrave aux points de terminaison Service Bus principal et secondaire.
Il existe de nombreux exemples pratiques de ce cloud hybride et d’applications de périphérie, avec une faible tolérance de l’entreprise pour l’impact des problèmes de routage réseau ou des problèmes de disponibilité temporaire d’une entité Service Bus. Cela inclut le traitement des paiements sur des sites de vente au détail, l’embarquement à des portes d’aéroport, et les commandes par téléphone mobile dans des restaurants, des événements qui arrivent touts à un instant précis et s’arrêtent dès que le chemin de communication fiable n’est pas disponible.
Dans cette catégorie, nous aborderons trois modèles distribués distincts : la réplication « active », la réplication « active-passive » et la réplication « débordement ».
Réplication active
Le modèle de réplication « active » permet à un réplica actif de la même rubrique logique (ou file d’attente) d’être disponible dans plusieurs espaces de noms (et régions), et à tous les messages d’être disponibles dans tous les réplicas, quel que soit l’endroit où ils ont été mis en file d’attente. Le modèle conserve généralement l’ordre des messages par rapport à un serveur de publication.
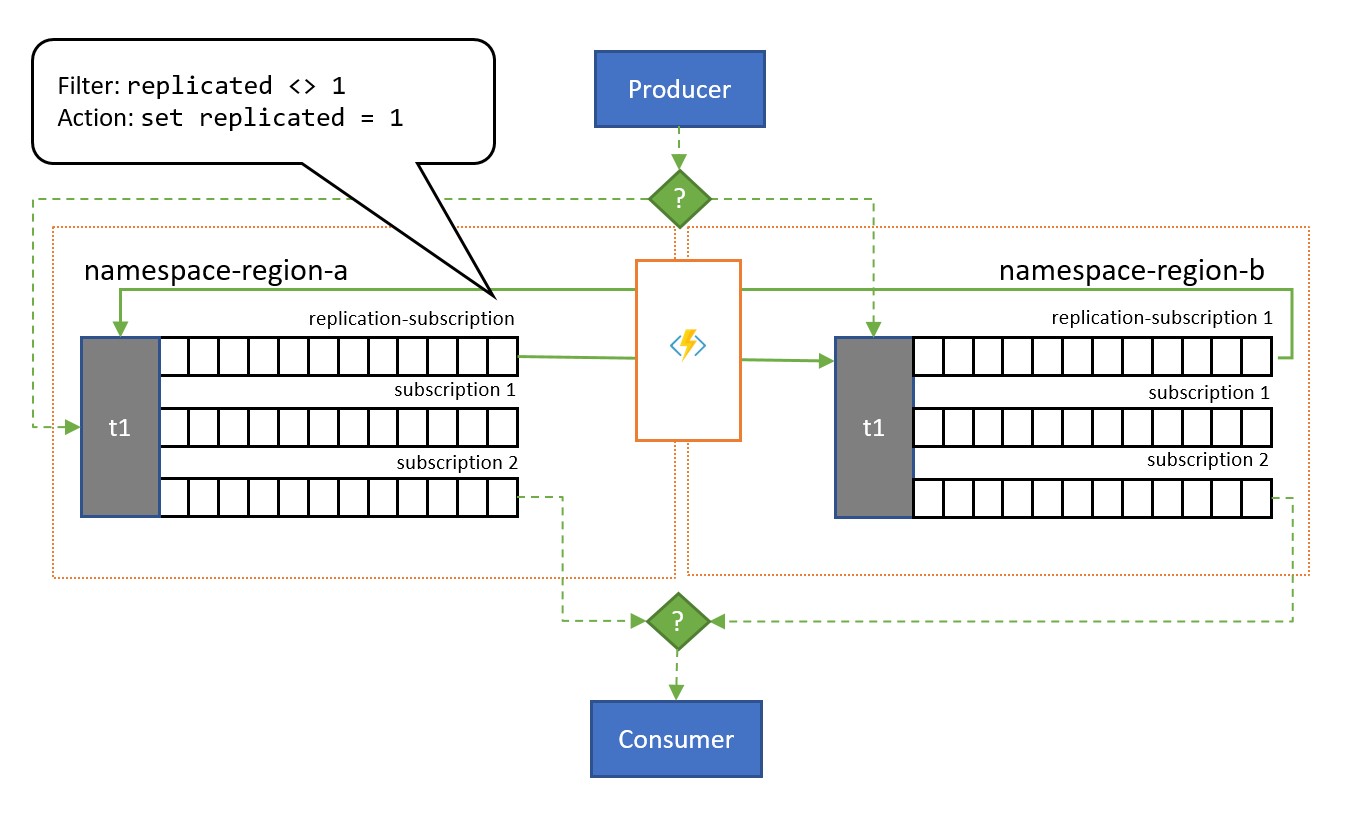
Comme indiqué dans l’illustration, le modèle s’appuie généralement sur des rubriques Service Bus. Une rubrique pour chaque espace de noms qui doit participer au schéma de réplication. Chacune de ces rubriques possède un « abonnement de réplication » pour les autres rubriques vers lesquelles les messages doivent être répliqués. Dans l’illustration ci-dessus, nous avons simplement une paire de rubriques et, par conséquent, un seul abonnement de réplication pour l’autre rubrique correspondante. Dans un scénario avec trois espaces de noms {n1, n2, n3} , une rubrique de l’espace de noms n1 aura deux abonnements de réplication, un pour la rubrique correspondante dans n2 et un pour la rubrique correspondante dans n3.
Chaque abonnement de réplication comporte une règle qui associe une expression de filtre SQL (replicated <> 1) et une action SQL (set replicated = 1). Le filtre de la règle garantit que seuls les messages dans lesquels la propriété personnalisée replication n’est pas définie ou n’ont pas la valeur 1 deviennent éligibles à cet abonnement, et l’action définit cette propriété sur la valeur 1 pour chaque message sélectionné par la suite. Ainsi, que lorsque le message est copié dans la rubrique correspondante, il n’est plus éligible à la réplication dans le sens inverse et, par conséquent, nous évitons les messages qui rebondissent entre les réplicas.
Un abonnement avec une règle respective peut être facilement ajouté à n’importe quelle rubrique à l’aide de l’interface de ligne de commande Azure CLI, comme ceci.
az servicebus topic subscription rule create --resource-group myresourcegroup \
--namespace mynamespace --topic-name mytopic \
--subscription-name replication --name replication \
--action-sql-expression "set replication = 1" \
--filter-sql-expression "replication IS NULL"
Pour modéliser une file d’attente, chaque rubrique est limitée à un seul abonnement standard (autre que les abonnements de réplication) partagé par tous les consommateurs.
Le modèle de réplication active place une copie de chaque message envoyé dans chacune des rubriques. Cela signifie que votre code d’application dans chaque région verra et traitera tous les messages. Ce modèle est adapté aux scénarios dans lesquels les données sont partagées dans plusieurs régions ou si un traitement redondant est généralement souhaité. Si vous devez traiter chaque message une seule fois, comme avec une file d’attente normale, vous devez prendre en compte l’un des deux modèles suivants.
Réplication active-passive
Le modèle de réplication « active/passive » est une variation du modèle précédent, dans lequel une seule des rubriques (la « principale ») est utilisée activement par l’application pour envoyer et recevoir des messages, et les messages sont répliqués dans une rubrique secondaire pour le cas où la rubrique principale devient indisponible ou inaccessible.
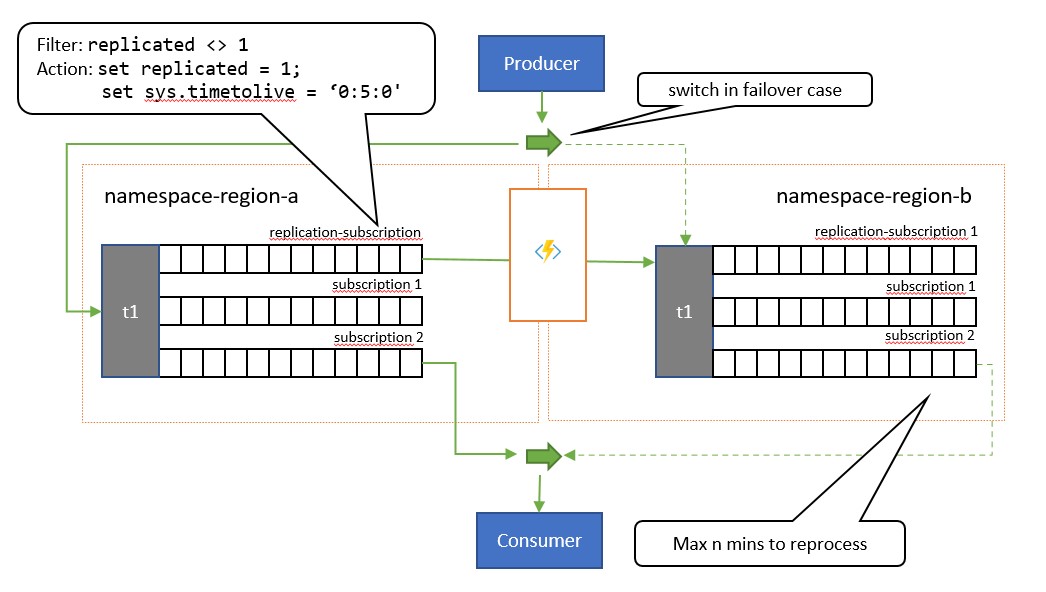
La principale différence entre ce modèle et le modèle précédent réside dans le fait que la réplication est unidirectionnelle de la rubrique principale vers la rubrique secondaire. La rubrique secondaire ne devient jamais la rubrique principale, mais constitue une option de sauvegarde lorsque la rubrique principale est momentanément inutilisable.
L'avantage de ce modèle est qu'il permet de réduire de traitement des doublons. Pendant la réplication, la propriété de message TimeToLive est définie sur une durée sur les messages répliqués, qui reflète le temps prévu pendant lequel une défaillance de la rubrique principale déclenche un basculement. Par exemple, si votre scénario d’utilisation nécessite un basculement du consommateur vers la rubrique secondaire dans un délai de 1 minute au maximum lorsque la récupération des messages de la rubrique principale présente des problèmes, la rubrique secondaire doit idéalement avoir tous les messages disponibles auxquels vous n’avez pas accès dans la rubrique principale, mais un nombre minimal de messages que vous avez déjà traités à partir de la rubrique principale quand ces problèmes sont apparus. Si nous définissons la valeur TimeToLive à deux fois cette période, soit 2 minutes, pendant la réplication (set sys.TimeToLive = '0:2:0' dans l’action de règle), la rubrique secondaire conserve uniquement les messages pendant 2 minutes puis rejette les messages plus anciens. Cela signifie que lorsque le destinataire bascule vers la rubrique secondaire, il peut rapidement lire et ignorer les messages plus anciens que le dernier message traité, puis reprendre le traitement à partir du premier message qu’il n’a pas encore vu. La durée réelle de rétention dépend du cas d’utilisation spécifique et de la rapidité à laquelle vous souhaitez et pouvez basculer vers la rubrique secondaire dans votre application. Le paramètre TimeToLive est respecté dans la plage de quelques secondes à plusieurs jours.
Lorsque l’application utilise la rubrique secondaire, elle peut également publier directement sur la rubrique secondaire, qui agit ensuite comme n’importe quelle rubrique standard. Après le basculement vers la rubrique secondaire, le consommateur voit donc une combinaison de messages répliqués et de messages publiés directement sur la rubrique secondaire. Par conséquent, l’application doit d’abord basculer la publication sur la rubrique principale tout en autorisant le drainage des messages publiés localement avant de rebasculer le consommateur vers la rubrique secondaire. En raison de la reprise automatique de la réplication une fois que la rubrique principale est à nouveau disponible, le consommateur obtient également parallèlement les nouveaux messages publiés sur la rubrique principale, mais avec une latence légèrement supérieure.
Ce modèle est adapté aux scénarios où les messages ne doivent être traités qu’une seule fois. L’application doit coopérer pour assurer le suivi des messages qu’elle a traités à partir de la rubrique principale, car elle trouvera des doublons pendant la fenêtre de basculement dans la rubrique secondaire, puis recherchera les doublons lors du basculement. Le critère de déduplication doit être la meilleure valeur
MessageIdfournie par l’application. La valeurEnqueuedTimeUtcest également appropriée en tant qu’indicateur de filigrane, mais l’application doit autoriser un certain décalage d’horloge (plusieurs secondes) entre la rubrique principale et la rubrique secondaire, comme avec n’importe quel système distribué.
Réplication de débordement
Le modèle de réplication « débordement » permet l’utilisation active/active de plusieurs entités Service Bus dans plusieurs régions pour gérer le scénario dans lequel Service Bus est sain, mais le consommateur est submergé par le nombre de messages en attente ou n’est pas disponible. Cela peut être dû au fait qu’une base de données de sauvegarde du processus consommateur peut être lente ou non disponible. Ce modèle fonctionne avec les files d’attente ordinaires et les abonnements aux rubriques.
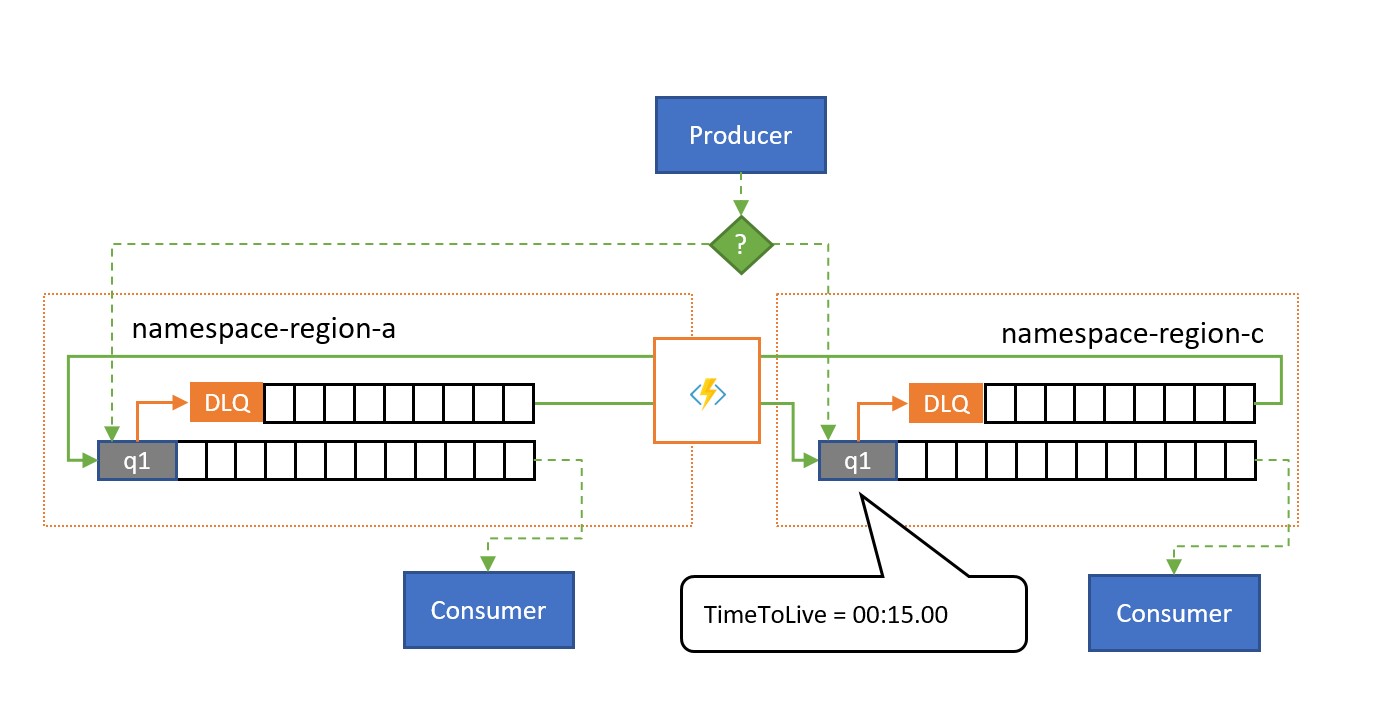
Comme indiqué dans l’illustration, le modèle de réplication de débordement réplique les messages de la file d’attente de lettres mortes d’une file d’attente ou d’un abonnement vers une file d’attente ou une rubrique associée dans un espace de noms différent.
Sans aucune situation d’échec, les deux espaces de noms sont utilisés en parallèle, chacun recevant un sous-ensemble du trafic global des messages et les consommateurs associés qui gèrent ce sous-ensemble. Dès que l’un des consommateurs commence à afficher des taux d’échec élevés ou s’arrête, les messages respectifs finissent dans la file d’attente de lettres mortes, soit en dépassant le nombre de remises, soit en raison de son expiration. Les tâches de réplication les récupèrent puis les replacent dans la file d’attente associée, où elles sont ensuite présentées au consommateur sain.
Si le traitement doit intervenir dans un délai donné, la valeur TimeToLive de la file d’attente et/ou des messages doit être définie de sorte que le traitement puisse toujours avoir lieu dans le délai défini par le débordement secondaire, par exemple TimeToLive peut être définie à la moitié du temps autorisé.
Comme avec le modèle actif, l’application peut ajouter un indicateur au message, que le message ait déjà été répliqué une seule fois de façon à ne pas rebondir entre les deux files d’attente, mais soit publié dans une file d’attente auxiliaire qui joue le rôle de file d’attente de lettres mortes pour le modèle composite.
Ce modèle est adapté aux scénarios dans lesquels la principale préoccupation consiste à empêcher les problèmes de disponibilité des consommateurs ou des ressources sur lesquels les consommateurs s’appuient, ainsi qu’à redistribuer les pics de trafic vers l’une des files d’attente associées. Il fournit également une protection contre l’indisponibilité de l’un des espaces de noms si les consommateurs lisent les données à partir des deux files d’attente, mais que le décalage de réplication imposé par l’expiration de
TimeToLivepeut entraîner l’indisponibilité des messages dans cette fenêtre de temps dans l’espace de noms indisponible.
Optimisation de la latence
Les rubriques servent à distribuer des informations à plusieurs consommateurs. Dans certains cas, en particulier pour les consommateurs avec une répartition géographique étendue, il peut être avantageux de répliquer les messages d’une rubrique dans un espace de noms secondaire plus proche des consommateurs.
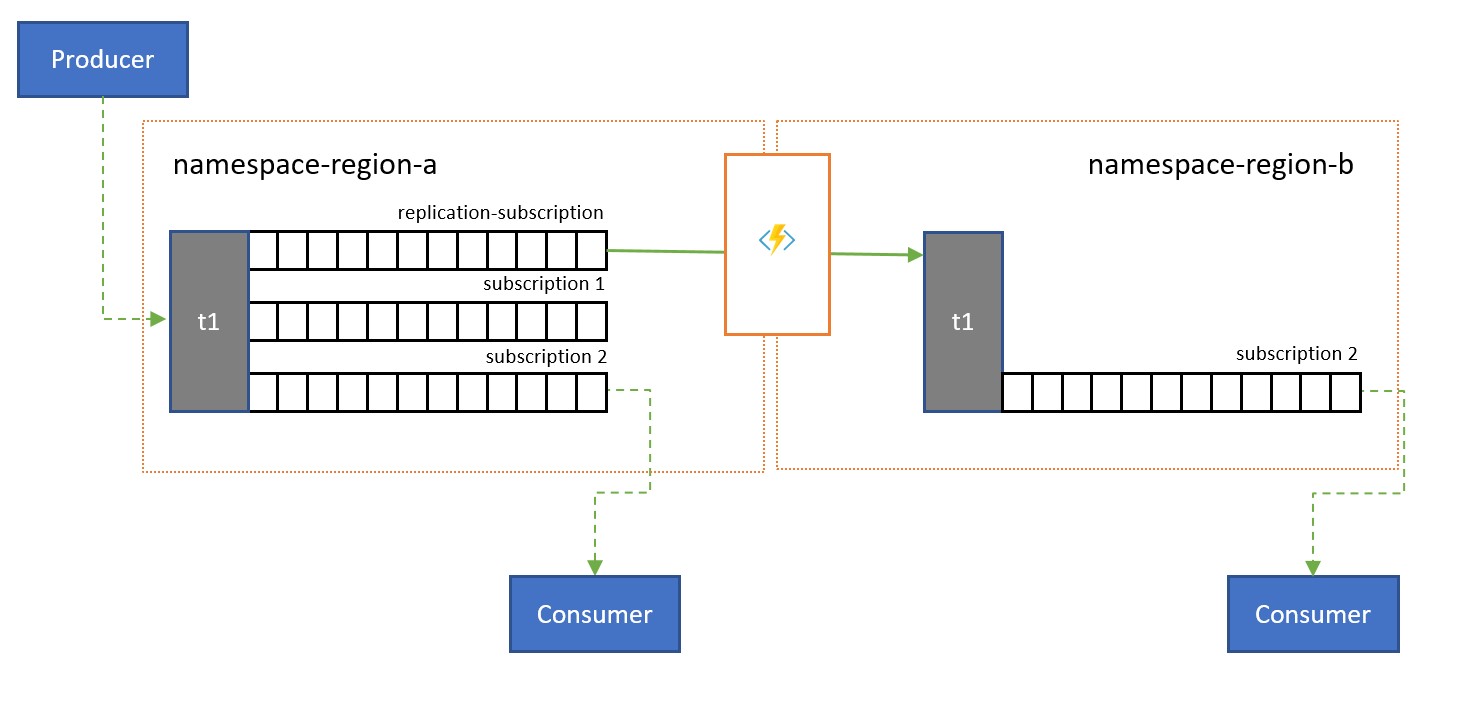
Par exemple, lors du partage de données entre des hubs régionaux continentaux, il est plus efficace de transférer des informations une seule fois entre les concentrateurs et de faire en sorte que les consommateurs obtiennent leur copie des données à partir de ces hubs.
Les transferts de réplication peuvent être effectués par lots, et les consommateurs obtiennent et ferment souvent les messages un par un. Avec une latence de réseau de base de 100 ms entre, disons, l’Amérique du Nord et l’Europe, chaque message met 200 ms plus longtemps à traiter les deux allers-retours vers une entité distante pour acquérir et régler les messages, par rapport à une entité dans la même région.
Validation, réduction et enrichissement
Les messages peuvent être envoyés dans une file d’attente ou une rubrique Service Bus par des clients externes à votre propre solution.
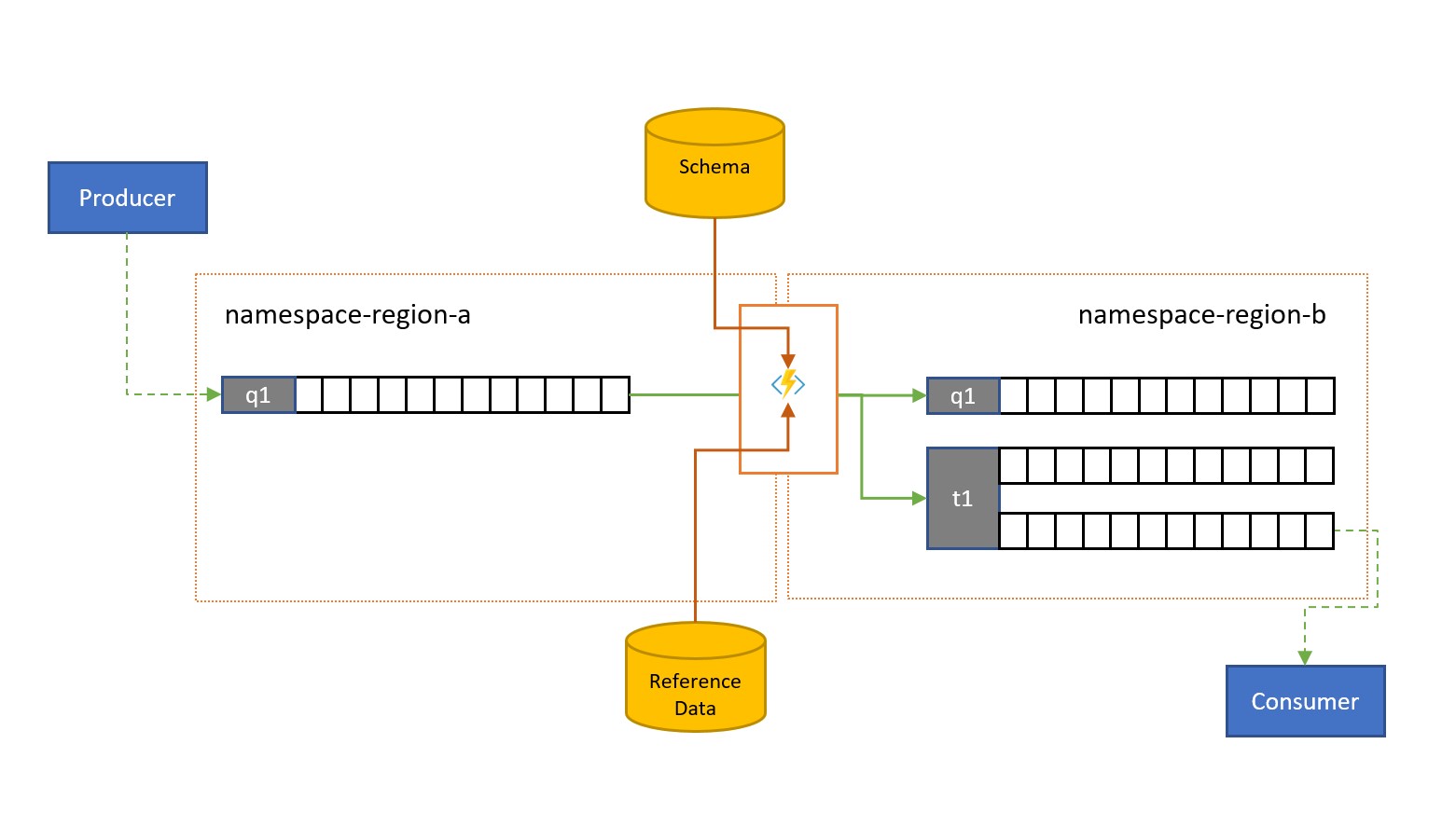
De tels messages peuvent nécessiter une vérification de la conformité avec un schéma donné, et les messages non conformes devront être supprimés ou placés dans la file d’attente de lettres mortes. Il peut être nécessaire de réduire la complexité de certains messages en omettant des données, et de les enrichir en ajoutant des données basées sur des recherches de données de référence. Les opérations peuvent être effectuées avec des fonctionnalités personnalisées dans la tâche de réplication.
Réplication d’un flux vers une file d’attente
Azure Event Hubs est une solution idéale pour gérer des volumes extrêmes d’événements entrants. Mais ni Event Hubs ni les moteurs similaires comme Apache Kafka ne fournissent un modèle consommateur concurrent géré par le service, dans lequel plusieurs consommateurs peuvent gérer simultanément des messages provenant de la même source sans risquer le traitement des doublons, et enfin fermer ces messages une fois qu’ils ont été traités.
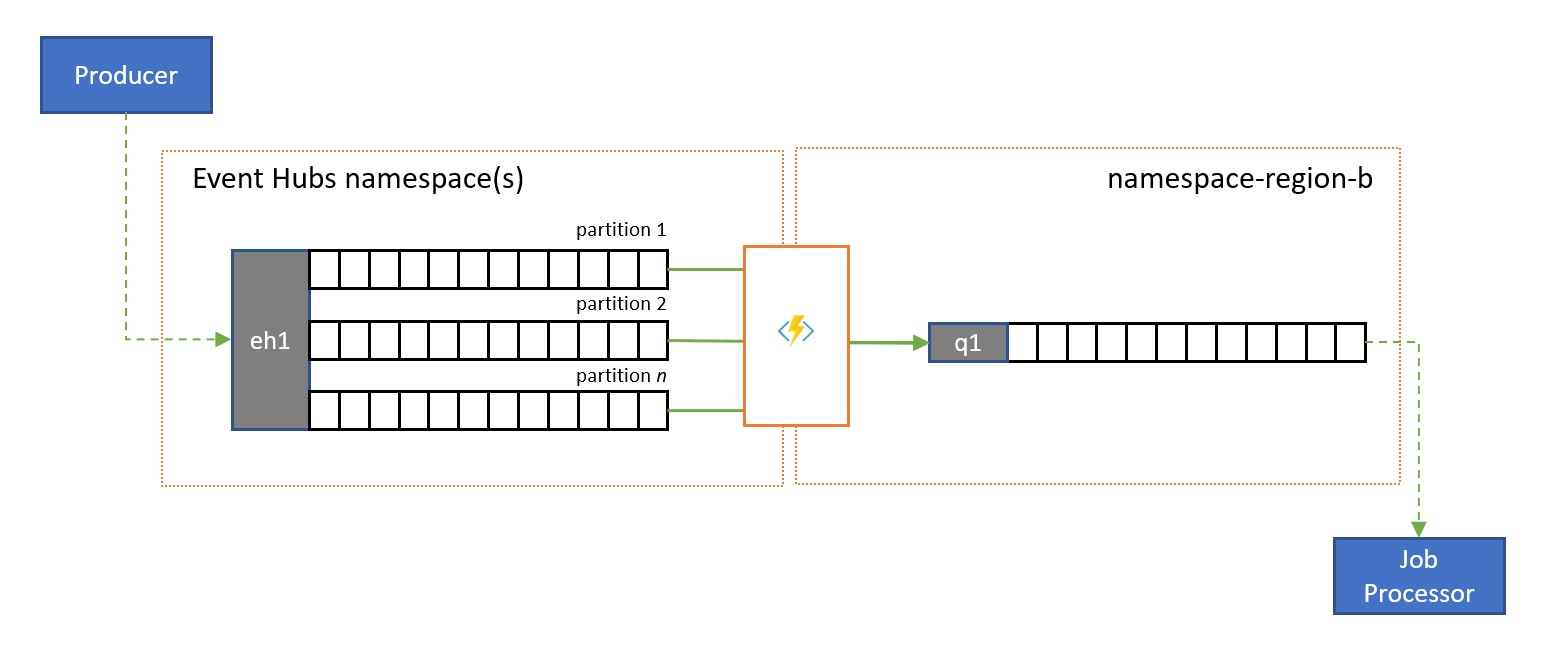
Une réplication de flux vers une file d’attente transfère le contenu d’une partition Event Hub unique ou le contenu d’un Event Hub complet vers une file d’attente Service Bus, à partir de laquelle les messages peuvent être traités en toute sécurité, de manière transactionnelle et avec des consommateurs concurrents. Cette réplication permet également d’utiliser toutes les autres fonctionnalités Service Bus pour ces messages, notamment le routage avec des rubriques et le démultiplexage basé sur une session.
Consolidation et normalisation
Les solutions mondiales sont souvent composées d’empreintes régionales qui sont largement indépendantes et qui ont notamment leurs propres capacités d’analyse, mais les perspectives d’analyse suprarégionales et mondiales nécessiteront une perspective intégrée. C’est pourquoi il convient de procéder à une consolidation centrale des mêmes flux d’événements qui sont évalués dans les empreintes régionales respectives pour la perspective locale.
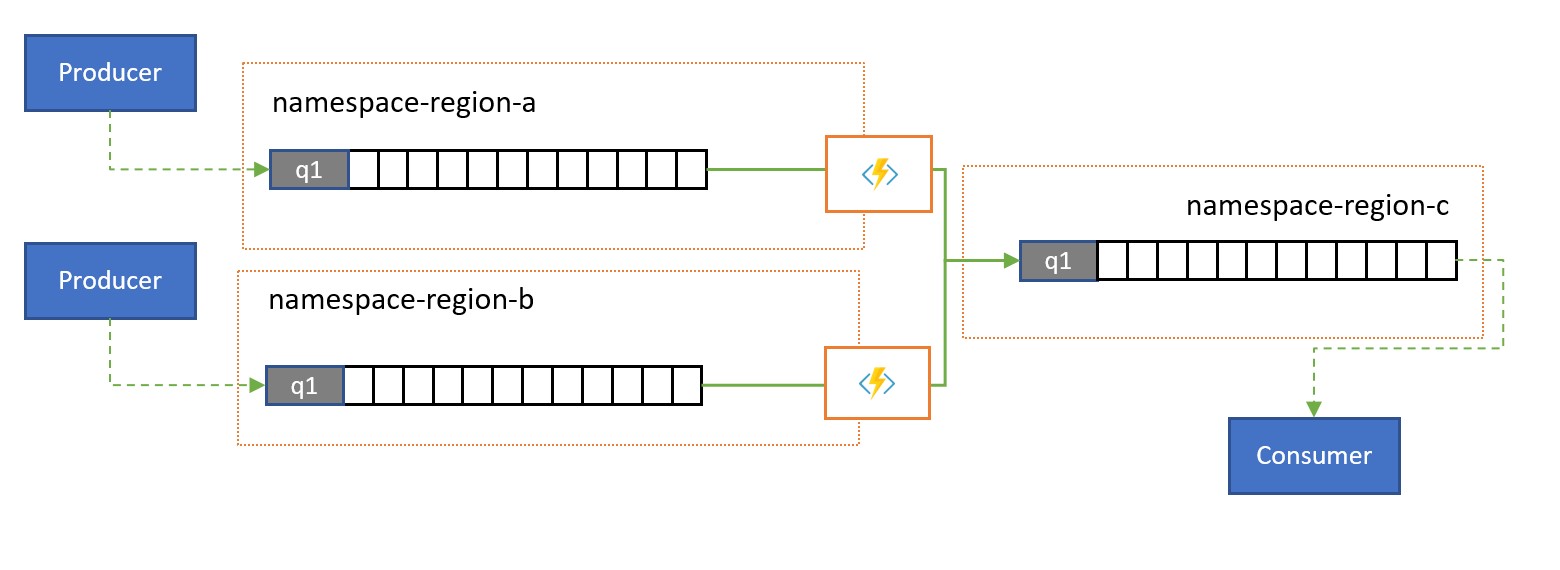
La normalisation est une variante du scénario de consolidation, dans laquelle deux ou plusieurs séquences entrantes de messages transportent le même type d’informations, mais avec des structures différentes ou des codages différents, et où les messages doivent être transcodés ou transformés avant de pouvoir être consommés.
La normalisation peut également inclure des travaux de chiffrement tels que le déchiffrement de charges utiles chiffrées de bout en bout, puis leur rechiffrement à l’aide de clés et d’algorithmes différents pour le public de consommateurs en aval.
Fractionnement et routage
Les rubriques Service Bus et leurs règles d’abonnement sont souvent utilisées afin de filtrer un flux de messages pour un public particulier, et ce public a obtenu l’ensemble filtré d’un abonnement.
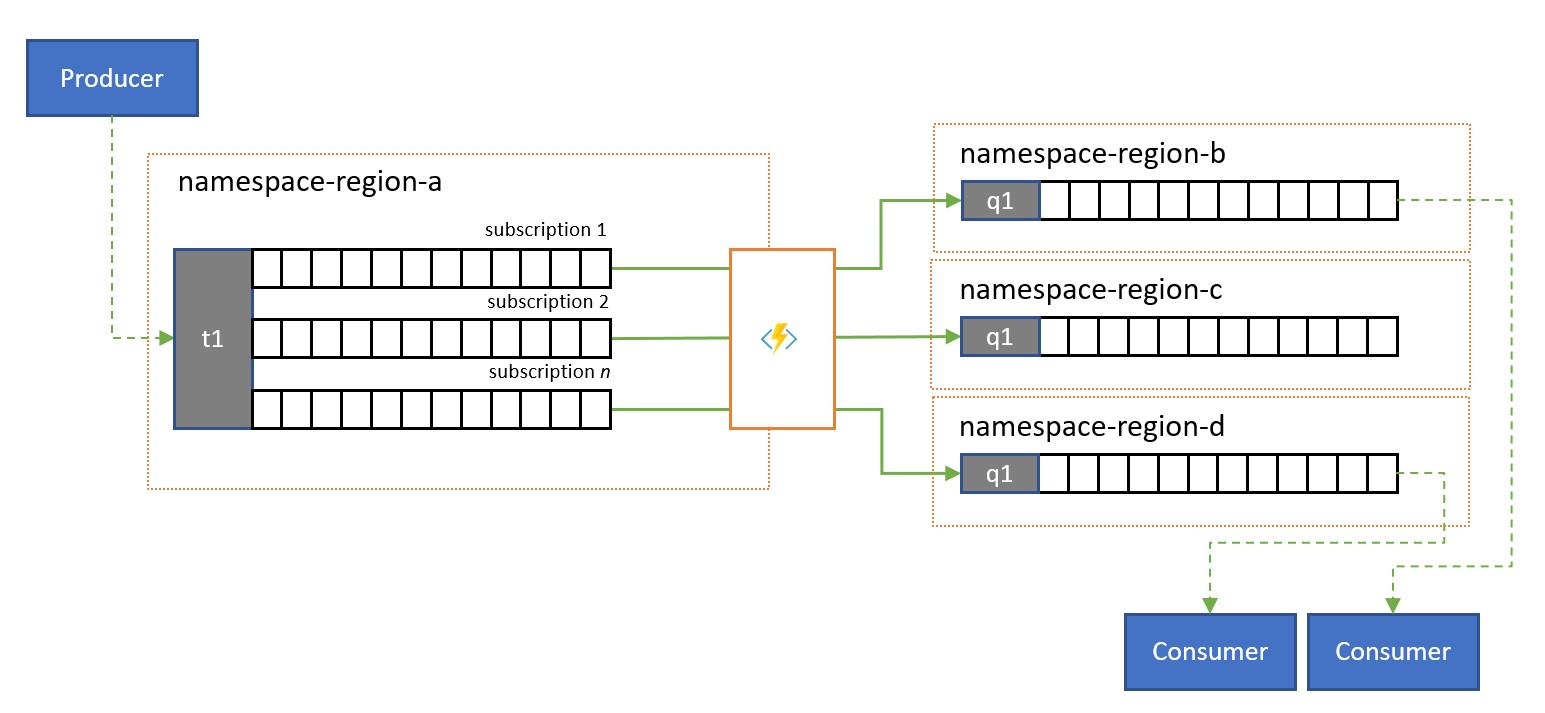
Dans un système global où le public de ces messages est distribué à l’échelle mondiale ou appartient à des applications différentes, la réplication peut être utilisée pour transférer des messages d’un abonnement de ce type vers une file d’attente ou une rubrique dans un espace de noms différent de celui où ils sont consommés.
Applications de réplication dans Azure Functions
L’implémentation des modèles ci-dessus requiert un environnement d’exécution évolutif et fiable pour les tâches de réplication que vous souhaitez configurer et exécuter. Sur Azure, l’environnement d’exécution le mieux adapté aux tâches sans état est Azure Functions.
Azure Functions peut s’exécuter sous une identité managée Azure de telle sorte que les tâches de réplication peuvent s’intégrer aux règles de contrôle d’accès en fonction du rôle des services source et cible, sans avoir à gérer les secrets durant le processus de réplication. Pour les sources et cibles de réplication qui nécessitent des informations d’identification explicites, Azure Functions peut conserver les valeurs de configuration de ces informations d’identification dans un stockage étroitement contrôlé accessible à l’intérieur d’Azure Key Vault.
De plus, Azure Functions permet aux tâches de réplication de s’intégrer directement aux réseaux virtuels Azure et aux points de terminaison de service pour tous les services de messagerie Azure, et il est facilement intégré à Azure Monitor.
Plus important encore, Azure Functions dispose de déclencheurs et de liens de sortie préconstruits et évolutifs pour Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid et Stockage File d’attente Azure, ainsi que d’extensions personnalisées pour RabbitMQ et Apache Kafka. La plupart des déclencheurs s’adaptent de manière dynamique aux besoins de débit en mettant à l’échelle le nombre d’instances exécutées simultanément sur la base des métriques documentées.
Grâce au plan de consommation d’Azure Functions, les déclencheurs prédéfinis peuvent même être réduits à zéro alors qu’aucun message n’est disponible pour la réplication, ce qui signifie qu’aucuns frais ne vous sont facturés pour garder la configuration prête à une mise à l’échelle. Le principal inconvénient de l’utilisation du plan de consommation est que la latence des tâches de réplication sortant de cet état est nettement plus élevée qu’avec les plans d’hébergement où l’infrastructure est maintenue en fonctionnement.
En revanche, la plupart des moteurs de réplication de messagerie et d’événements, tels que MirrorMaker d’Apache Kafka, nécessitent que vous fournissiez un environnement d’hébergement et que vous mettiez vous-même le moteur de réplication à l’échelle. Cela comprend la configuration et l’intégration des fonctionnalités de sécurité et de mise en réseau et la facilitation du flux des données de surveillance, et vous n’avez toujours pas la possibilité d’injecter des tâches de réplication personnalisées dans le flux.
Tâches de réplication avec Azure Logic Apps
Une alternative à Functions pour répliquer sans codage est Logic Apps. Logic Apps a des tâches de réplication prédéfinies pour Service Bus. Celles-ci peuvent vous aider à configurer la réplication entre différentes instances et peuvent être ajustées pour une personnalisation supplémentaire.
Étapes suivantes
Dans cet article, nous avons exploré un éventail de modèles de fédération et expliqué le rôle d’Azure Functions en tant que runtime de réplication d’événements et de messages dans Azure.
Ensuite, vous voudrez peut-être lire comment configurer une application de réplication avec Azure Functions, puis comment répliquer des flux d’événements entre Event Hubs et divers autres systèmes de messagerie et d’événements :