Taille d’index vectoriel et respect des limites
Pour chaque champ vectoriel, Recherche Azure AI construit un index vectoriel interne à l’aide des paramètres d’algorithme spécifiés sur le champ. Étant donné que Recherche Azure AI impose des quotas sur la taille de l’index vectoriel, vous devez savoir comment estimer et surveiller la taille du vecteur afin de veiller à rester sous les limites.
Remarque
Une remarque concernant la terminologie. En interne, les structures de données physiques d’un index de recherche incluent du contenu brut (utilisé pour les modèles de récupération nécessitant du contenu non tokenisé), des index inversés (utilisés pour les champs de texte pouvant faire l’objet d’une recherche) et des index vectoriels (utilisés pour les champs vectoriels pouvant faire l’objet d’une recherche). Cet article explique quelles sont les limites des index vectoriels internes sur lesquels reposent chacun de vos champs vectoriels.
Conseil
Les techniques d’optimisation des vecteurs sont désormais généralement disponibles. Utilisez des fonctionnalités telles que les types de données étroits et binaires, la quantification scalaire et l’élimination du stockage redondant pour rester sous quota vectoriel et quota de stockage.
Points clés concernant le quota et la taille de l’index vectoriel
La taille de l’index vectoriel est mesurée en octets.
Les quotas vectoriels sont basés sur des contraintes de mémoire. Pour les index vectoriels créés à l’aide de l’algorithme HNSW (Hierarchical Navigable Small World), les index vectoriels pouvant faire l’objet d’une recherche résident dans la mémoire. En même temps, il doit également y avoir suffisamment de mémoire pour d’autres opérations d’exécution. Les quotas vectoriels existent afin de garantir que le système global demeure stable et équilibré pour toutes les charges de travail. Si vous utilisez un algorithme KNN exhaustif, les index sont chargés en mémoire uniquement au moment de la requête.
Les index vectoriels sont également soumis à un quota de disque, au sens où tous les index sont soumis au quota de disque. Il n’existe aucun quota de disque distinct pour les index vectoriels.
Les quotas vectoriels sont appliqués au service de recherche dans son ensemble, par partition, ce qui signifie que si vous ajoutez des partitions, le quota vectoriel augmente. Les quotas de vecteurs par partition sont plus élevés sur les services plus récents. Pour plus d’informations, consultez Limite de la taille de l’index vectoriel.
Comment vérifier la taille et la quantité de partitions ?
Si vous ne savez pas quelles sont les limites de votre service de recherche, voici deux façons d’obtenir ces informations :
Dans le portail Azure, dans la page Vue d’ensemble du service de recherche, les onglets Propriétés et Utilisation affichent la taille de partition et le stockage, ainsi que le quota vectoriel et la taille de l’index vectoriel.
Dans le portail Azure, dans la page Mise à l’échelle, vous pouvez passer en revue le nombre et la taille des partitions.
Comment vérifier la date de création du service ?
Les services récents créés après le 3 avril 2024 offrent cinq à dix fois plus de stockage vectoriel que les services plus anciens au même niveau de facturation. Si votre service est plus ancien, envisagez de créer un service et de migrer votre contenu.
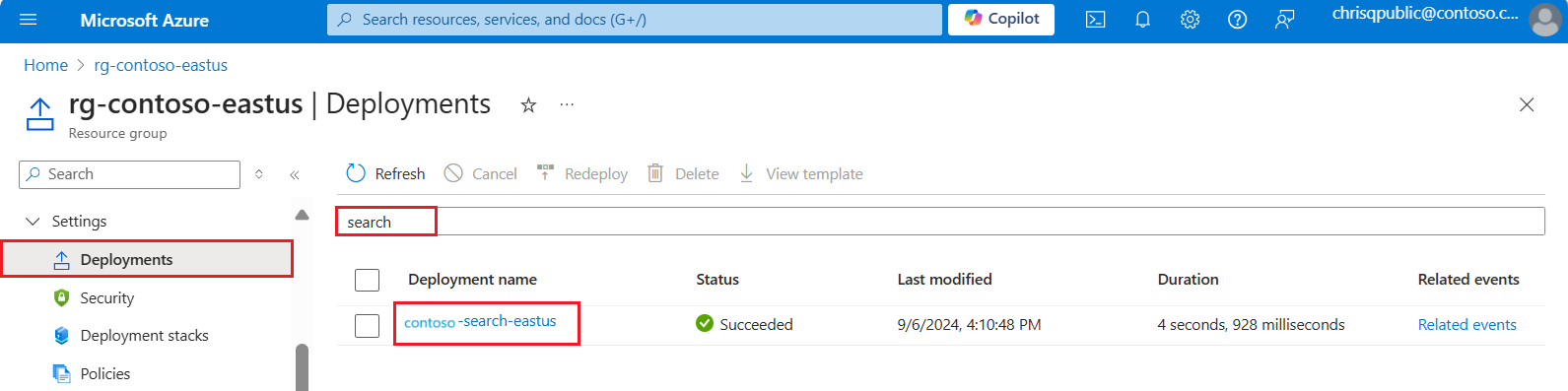
Dans le portail Azure, ouvrez le groupe de ressources qui contient votre service de recherche.
Dans le volet le plus à gauche, sous Paramètres, sélectionnez Déploiements.
Recherchez le déploiement de votre service de recherche. S’il existe de nombreux déploiements, utilisez le filtre pour rechercher « recherche ».
Sélectionnez le déploiement. Si vous en avez plusieurs, cliquez dessus pour voir s’il est résolu dans votre service de recherche.
Développez les détails du déploiement. Vous devez voir Créé et la date de création.
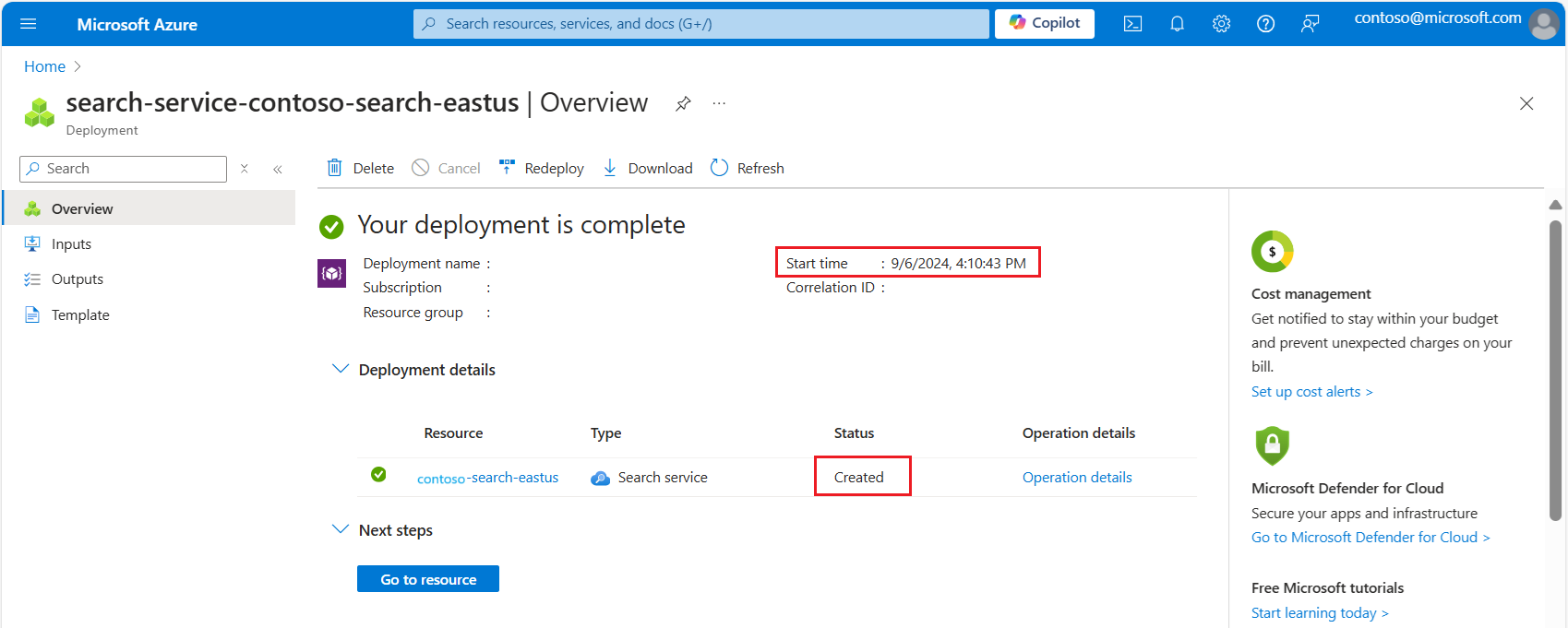
Maintenant que vous connaissez l’âge de votre service de recherche, passez en revue les limites de quota de vecteurs en fonction de la création du service : Limite de la taille de l’index vectoriel.


Comment obtenir la taille de l’index vectoriel
Une demande de métriques vectorielles est une opération de plan de données. Vous pouvez utiliser le Portail Azure, les API REST ou les kits de développement logiciel Azure pour obtenir l’utilisation de vecteurs au niveau du service via des statistiques de service et pour des index individuels.
Taille de vecteur par index
Pour obtenir la taille de l’index vectoriel par index, sélectionnez Gestion de recherche>Index pour afficher une liste des index et le nombre de documents, la taille des index vectoriels en mémoire et la taille totale des index stockés sur le disque.
Rappelez-vous que le quota de vecteurs est basé sur des contraintes de mémoire. Pour les index vectoriels créés à l’aide de l’algorithme HNSW, tous les index vectoriels pouvant faire l’objet d’une recherche sont chargés définitivement en mémoire. Pour les index créés à l’aide de l’algorithme KNN exhaustif, les index vectoriels sont chargés en blocs, séquentiellement, au moment de la requête. Il n’existe aucune exigence de résidence de mémoire pour les index KNN exhaustifs. La durée de vie des pages chargées en mémoire est similaire à la recherche de texte et aucune autre métrique n’est applicable aux index KNN exhaustifs autre que le stockage total.
La capture d’écran suivante montre deux versions du même index vectoriel. Une version est créée à l’aide de l’algorithme HNSW, où le graphe vectoriel réside en mémoire. Une autre version est créée à l’aide d’un algorithme KNN exhaustif. Avec KNN exhaustif, il n’existe aucun index vectoriel en mémoire spécialisé. Le portail affiche donc 0 Mo pour la taille de l’index vectoriel. Ces vecteurs existent toujours et sont comptabilisés dans la taille de stockage globale, mais ils n’occupent pas la ressource en mémoire suivie par la métrique de taille de l’index vectoriel.

Taille de vecteur par service
Pour obtenir la taille de l’index vectoriel pour le service de recherche dans son ensemble, accédez à la page Vue d’ensemble et sélectionnez l’onglet Utilisation. Les pages du portail s’actualisent toutes les quelques minutes. Par conséquent, si vous avez récemment mis à jour un index, attendez quelques instants avant de vérifier les résultats.
La capture d’écran suivante concerne un ancien service de recherche Standard 1 (S1), configuré pour une partition et un réplica.
Le quota de stockage est une contrainte de disque, et il est inclusif de tous les index (vectoriels et non-vectoriels) sur un service de recherche.
Le quota de taille d’index vectoriel est une contrainte de mémoire. Il s’agit de la quantité de mémoire nécessaire pour charger tous les index vectoriels internes créés pour chaque champ vectoriel sur un service de recherche.
La capture d’écran indique que les index (vectoriels et non-vectoriels) consomment près de 460 mégaoctets de stockage disque disponible. Les index vectoriels consomment près de 93 mégaoctets de mémoire au niveau du service.

Les quotas pour la taille du stockage et de l’index vectoriel augmentent ou diminuent lorsque vous ajoutez ou supprimez des partitions. Si vous modifiez le nombre de partitions, la vignette affiche une modification correspondante du stockage et du quota vectoriel.
Remarque
Sur le disque, les index vectoriels ne sont pas de 93 mégaoctets. Les index vectoriels sur le disque prennent environ trois fois plus d’espace que les index vectoriels en mémoire. Consultez Comment les champs vectoriels affectent le stockage sur disque pour plus d’informations.
Facteurs affectant la taille de l’index vectoriel
Trois composants majeurs affectent la taille de votre index vectoriel interne :
- Taille brute des données
- Charge supplémentaire due à l’algorithme sélectionné
- Charge supplémentaire due à la suppression ou à la mise à jour de documents dans l’index
Taille brute des données
Chaque vecteur est généralement un tableau de nombres à virgule flottante en simple précision, dans un champ de type Collection(Edm.Single).
Les structures de données vectorielles nécessitent du stockage, représenté dans le calcul suivant par la « taille brute » de vos données. Utilisez cette taille brute pour estimer les besoins en taille d’index vectoriel de vos champs vectoriels.
La taille de stockage d’un vecteur est déterminée par sa dimensionnalité. Multipliez la taille d’un vecteur par le nombre de documents contenant ce champ vectoriel pour obtenir la taille brute :
raw size = (number of documents) * (dimensions of vector field) * (size of data type)
| Type de données EDM | Taille du type de données |
|---|---|
Collection(Edm.Single) |
4 octets |
Collection(Edm.Half) |
2 octets |
Collection(Edm.Int16) |
2 octets |
Collection(Edm.SByte) |
1 octet |
Charge supplémentaire de la mémoire due à l’algorithme sélectionné
Chaque algorithme de recherche du plus proche voisin (Approximate Nearest Neighbor, ANN) génère des structures de données supplémentaires en mémoire pour permettre une recherche efficace. Ces structures occupent un espace supplémentaire dans la mémoire.
Pour l’algorithme HNSW, la charge supplémentaire en mémoire est comprise entre 1 et 20 %.
La charge supplémentaire en mémoire est inférieure pour les dimensions plus élevées, car la taille brute des vecteurs augmente, tandis que les structures de données supplémentaires restent à une taille fixe, étant donné qu’elles stockent des informations sur la connectivité dans le graphe. Par conséquent, la contribution des structures de données supplémentaires représente une part plus faible de la taille totale.
La charge supplémentaire en mémoire est plus importante pour les valeurs plus élevées du paramètre m de HNSW, qui détermine le nombre de liens bidirectionnels créés pour chaque nouveau vecteur lors de la construction de l’index. En effet, m représente environ huit à dix octets par document, multiplié par m.
Le tableau suivant résume les pourcentages de charge supplémentaire observés lors de tests internes :
| Axes analytiques | Paramètre de HNSW (m) | Pourcentage de charge supplémentaire |
|---|---|---|
| 96 | 4 | 20% |
| 200 | 4 | 8 % |
| 768 | 4 | %2 |
| 1536 | 4 | %1 |
| 3 072 | 4 | 0,5 % |
Ces résultats montrent la relation entre les dimensions, le paramètre de HNSW m et la charge supplémentaire en mémoire pour l’algorithme HNSW.
Charge supplémentaire due à la suppression ou à la mise à jour de documents dans l’index
Quand un document comportant un champ vectoriel est supprimé ou mis à jour (les mises à jour sont représentées en interne sous la forme d’une opération de suppression et d’insertion), le document sous-jacent est marqué comme supprimé et ignoré lors des requêtes ultérieures. Au fur et à mesure que de nouveaux documents sont indexés et que l’index vectoriel interne augmente, le système nettoie ces documents supprimés et récupère les ressources. Cela signifie que vous observerez probablement un décalage entre la suppression des documents et la libération des ressources sous-jacentes.
C’est ce que nous appelons le ratio de documents supprimés. Comme le ratio de documents supprimés dépend des caractéristiques d’indexation de votre service, il n’existe pas d’heuristique universelle pour estimer ce paramètre, et il n’y a pas d’API ou de script qui retourne le ratio effectif pour votre service. Nous constatons que la moitié de nos clients ont un ratio de documents supprimés inférieur à 10 %. Si vous avez tendance à effectuer des suppressions ou des mises à jour fréquentes, vous pouvez observer un ratio de documents supprimés plus élevé.
C’est un autre facteur impactant la taille de votre index vectoriel. Malheureusement, nous ne disposons pas d’un mécanisme permettant de faire apparaître votre ratio de documents supprimés en cours.
Estimation de la taille totale de vos données en mémoire
En tenant compte des facteurs décrits précédemment, pour estimer la taille totale de votre index vectoriel, utilisez le calcul suivant :
(raw_size) * (1 + algorithm_overhead (in percent)) * (1 + deleted_docs_ratio (in percent))
Par exemple, pour calculer la taille brute (raw_size), supposons que vous utilisez le modèle Azure OpenAI répandu text-embedding-ada-002 avec 1 536 dimensions. Cela signifie qu’un document consommerait 1 536 Edm.Single (valeurs en virgule flottante) ou 6 144 octets, car chaque Edm.Single est de 4 octets. 1 000 documents avec un seul champ vectoriel de 1 536 dimensions consommeraient au total 1 000 documents x 1 536 valeurs en virgule flottante/doc = 1 536 000 valeurs en virgule flottante, soit 6 144 000 octets.
Si vous avez plusieurs champs vectoriels, vous devez effectuer ce calcul pour chaque champ vectoriel de votre index et les additionner. Par exemple, 1 000 documents avec deux champs vectoriels de 1 536 dimensions consomment 1000 documents x 2 champs x 1 536 valeurs en virgule flottante/doc x 4 octets/valeur en virgule flottante = 12 288 000 octets.
Pour obtenir la taille de l’index vectoriel, multipliez cette taille brute (raw_size) par la charge supplémentaire de l’algorithme et le ratio de documents supprimés. Si la charge supplémentaire de votre algorithme pour les paramètres HNSW que vous avez choisis est de 10 % et que votre ratio de documents supprimés est de 10 %, nous obtenons : 6.144 MB * (1 + 0.10) * (1 + 0.10) = 7.434 MB.
Comment les champs vectoriels affectent le stockage sur disque
La plupart de cet article fournit des informations sur la taille des vecteurs en mémoire. Si vous souhaitez connaître la taille du vecteur sur le disque, la consommation de disque pour les données vectorielles est d’environ trois fois la taille de l’index vectoriel en mémoire. Par exemple, si votre utilisation de vectorIndexSize est à 100 mégaoctets (10 millions d’octets), vous avez utilisé au moins 300 mégaoctets de quota storageSize pour prendre en charge vos index vectoriels.