Conseils pour améliorer les performances dans Azure AI Search
Cet article est un ensemble de conseils et de bonnes pratiques pour améliorer les performances des requêtes et de l’indexation dans la recherche de mots clés. Connaître les facteurs les plus susceptibles d’avoir un impact sur les performances de recherche peut vous aider à éviter les inefficacités et à tirer le meilleur parti de votre service de recherche. Voici quelques facteurs clés :
- Composition de l’index (schéma et taille)
- Conception de requête
- Capacité du service (niveau et nombre de réplicas et de partitions)
Remarque
Vous recherchez des stratégies sur l’indexation à volume élevé ? Consultez Indexer des jeux de données volumineux dans Azure AI Search.
Taille et schéma de l’index
Les requêtes s’exécutent plus rapidement sur des index plus petits. Cela est dû en partie au fait qu’il y a moins de champs à analyser, mais aussi à la façon dont le système met en cache le contenu pour les futures requêtes. Après la première requête, une partie du contenu reste en mémoire, où il est recherché plus efficacement. La taille de l’index ayant tendance à croître au fil du temps, une meilleure pratique consiste à réexaminer régulièrement la composition de l’index, tant au niveau du schéma que des documents, afin de rechercher des possibilités de réduction du contenu. Toutefois, si l’index est bien dimensionné, la seule autre calibration que vous pouvez effectuer est d’augmenter la capacité : soit en ajoutant des réplicas, soit en mettant à niveau le niveau de service. La section « Conseil : effectuez une mise à niveau vers un niveau standard S2 » aborde le choix entre un scale-up et un scale-out.
La complexité du schéma peut également nuire aux performances de l’indexation et des requêtes. L’attribution excessive de champs entraîne des limitations et des besoins de traitement. L’indexation et l’interrogation des types complexes prennent plus de temps. Les sections suivantes explorent chaque condition.
Conseil : Soyez sélectif dans l’attribution de champ
Une erreur fréquente commise par les administrateurs et les développeurs lors de la création d’un index de recherche consiste à sélectionner toutes les propriétés disponibles pour les champs, au lieu de ne sélectionner que les propriétés nécessaires. Par exemple, si un champ ne doit pas faire l’objet d’une recherche en texte intégral, ignorez ce champ lorsque vous définissez l’attribut de recherche.
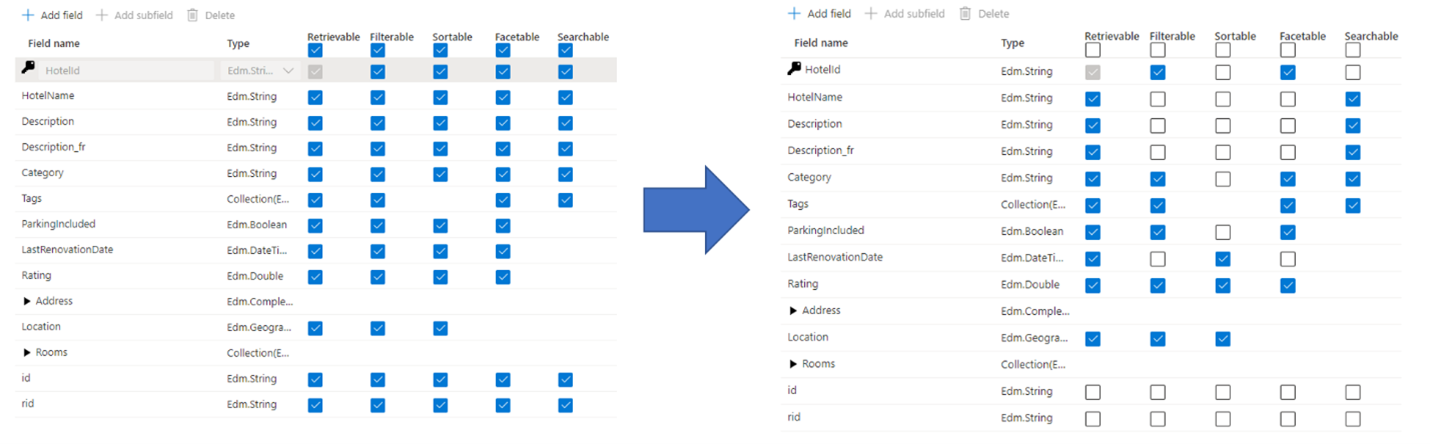
La prise en charge des filtres, des facettes et du tri peut quadrupler les besoins de stockage. Si vous ajoutez des suggesteurs, les besoins en stockage augmentent encore davantage. Pour obtenir une illustration de l’impact des attributs sur le stockage, consultez Attributs et taille de l’index.
En résumé, les conséquences d’une attribution excessive sont les suivantes :
Dégradation des performances d’indexation en raison du travail supplémentaire requis pour traiter le contenu du champ, puis le stocker dans l’index inversé de recherche (définissez l’attribut « Possibilité de recherche » uniquement sur les champs qui contiennent du contenu pouvant faire l’objet d’une recherche).
Crée une plus grande surface que chaque requête doit couvrir. Tous les champs marqués comme pouvant faire l’objet d’une recherche sont analysés dans le cadre d’une recherche en texte intégral.
Augmente les coûts opérationnels en raison du stockage supplémentaire. Le filtrage et le tri nécessitent de l’espace supplémentaire pour le stockage des chaînes d’origine (non analysées). Évitez de définir le filtrage ou le tri sur des champs qui n’en ont pas besoin.
Dans de nombreux cas, une attribution excessive limite les capacités du champ. Par exemple, si un champ est à facettes, filtrable et pouvant faire l’objet d’une recherche, vous pouvez stocker uniquement 16 ko de texte dans un champ, alors qu’un champ pouvant seulement faire l’objet d’une recherche peut contenir jusqu’à 16 Mo de texte.
Remarque
Seule l’attribution inutile est à éviter. Les filtres et les facettes sont souvent essentiels à l’expérience de recherche. Dans les cas où des filtres sont utilisés, vous devez souvent effectuer un tri afin de pouvoir ordonner les résultats (les filtres seuls sont retournés dans un ensemble non ordonné).
Conseil : Envisagez des alternatives aux types complexes
Les types de données complexes sont utiles lorsque les données ont une structure imbriquée complexe, telle que les éléments parent-enfant trouvés dans les documents JSON. L’inconvénient des types complexes est qu’ils nécessitent un stockage et des ressources supplémentaires pour indexer le contenu, par rapport aux types de données non complexes.
Dans certains cas, vous pouvez éviter ces inconvénients en faisant correspondre une structure de données complexe à un type de champ plus simple, tel qu’une collection. Vous pouvez également choisir d’aplatir une hiérarchie de champs en champs individuels de niveau racine.

Conception de requête
La composition et la complexité des requêtes sont l’un des facteurs les plus importants pour les performances, et l’optimisation des requêtes peut améliorer considérablement les performances. Lorsque vous concevez des requêtes, réfléchissez aux points suivants :
Nombre de champs pouvant faire l’objet d’une recherche. Chaque champ supplémentaire pouvant faire l’objet d’une recherche entraîne davantage de travail pour le service de recherche. Vous pouvez limiter les champs pouvant faire l’objet d’une recherche au moment de la requête en utilisant le paramètre « searchFields ». Il est préférable de spécifier uniquement les champs qui vous intéressent pour améliorer les performances.
Quantité de données renvoyées. L’extraction d’une grande quantité de contenu peut ralentir les requêtes. Lorsque vous structurez une requête, renvoyez uniquement les champs dont vous avez besoin pour afficher la page de résultats, puis récupérez les champs restants à l’aide de l’API de recherche une fois que l’utilisateur a sélectionné une correspondance.
Utilisation de recherches de terme partiel. Les recherches de terme partiel, telles que la recherche de préfixe, la recherche approximative et la recherche d’expression régulière, sont plus gourmandes en calcul que les recherches de mot clé classiques, car elles nécessitent des analyses complètes de l’index pour produire des résultats.
Nombre de facettes. L’ajout de facettes aux requêtes nécessite des agrégations pour chaque requête. Demander un « nombre » plus élevé pour une facette exige également du service un travail supplémentaire. En général, contentez-vous d’ajouter les facettes que vous envisagez d’afficher dans votre application et évitez de demander un nombre élevé de facettes, sauf si cela est nécessaire.
Valeurs d’omission élevées. L’affectation d’une valeur élevée (par exemple, dans les milliers) au paramètre
$skipaugmente la latence de la recherche, car le moteur récupère et classe un plus grand volume de documents pour chaque requête. Pour des raisons de performances, il est préférable d’éviter les valeurs$skipélevées et d’utiliser d’autres techniques à la place, comme le filtrage, pour récupérer un grand nombre de documents.Limiter les champs à cardinalité élevée. Un champ à cardinalité élevée est un champ à facettes ou filtrable qui possède un grand nombre de valeurs uniques. Ce champ consomme donc une quantité considérable de ressources lors du calcul des résultats. Par exemple, si vous définissez un champ ID produit ou Description en tant que champ à facettes ou filtrable, il s’agit d’un champ à cardinalité élevée, car la plupart des valeurs sont uniques d’un document à l’autre.
Conseil : Utilisez des fonctions de recherche au lieu de surcharger les critères de filtrage
Lorsqu’une requête utilise des critères de filtrage de plus en plus complexes, les performances de la requête de recherche se dégradent. Prenons l’exemple suivant, qui illustre l’utilisation de filtres pour affiner les résultats en fonction de l’identité d’un utilisateur :
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
Dans ce cas, les expressions de filtre sont utilisées pour vérifier si un seul champ de chaque document est égal à l’une des nombreuses valeurs possibles d’une identité d’utilisateur. Vous trouverez probablement ce modèle dans les applications qui implémentent le filtrage de sécurité (vérification d’un champ contenant un ou plusieurs ID de principal par rapport à une liste d’ID de principal représentant l’utilisateur qui émet la requête).
Une façon plus efficace d’exécuter les filtres qui contiennent un grand nombre de valeurs est d’utiliser la fonction search.in, comme illustré dans cet exemple :
search.in(userid, '123,234,345,456,567', ',')
Conseil : Ajoutez des partitions pour les requêtes individuelles lentes
Lorsque les performances des requêtes ralentissent, l’ajout de réplicas permet souvent de résoudre le problème. Mais qu’en est-il si le problème est une seule requête qui prend trop de temps à se terminer ? Dans ce scénario, l’ajout de réplicas n’est pas utile, mais l’inclusion de plus de partitions pourrait l’être. Une partition divise les données entre des ressources de calcul supplémentaires. Deux partitions divisent les données en deux, trois partitions les divisent en trois, et ainsi de suite.
L’un des avantages découlant de l’ajout de partitions réside dans l’accélération potentielle de l’exécution des requêtes les plus lentes grâce au calcul parallèle. Nous avons constaté une parallélisation sur les requêtes qui affichent une faible sélectivité, telles que les requêtes portant sur de nombreux documents ou les facettes comptabilisant un grand nombre de documents. Dans la mesure où des calculs significatifs sont nécessaires pour évaluer la pertinence des documents ou pour comptabiliser les documents, l’ajout de partitions supplémentaires contribue à accélérer l’exécution des requêtes.
Pour ajouter des partitions, utilisez Portail Azure, PowerShell, Azure CLI ou un Kit de développement logiciel (SDK) de gestion.
Capacité de service
Un service est surchargé quand les requêtes prennent trop de temps ou que le service commence à abandonner des requêtes. Dans ce cas, vous pouvez résoudre le problème en mettant à niveau le service ou en ajoutant de la capacité.
Le niveau de votre service de recherche et le nombre de réplicas/partitions ont également un impact important sur les performances. Chaque niveau supérieur se caractérise progressivement par des processeurs plus rapides et une plus grande mémoire, ce qui a un impact positif sur les performances.
Conseil : Créez un nouveau service de recherche à haute capacité
Les services de base et standard créés dans les régions prises en charge après le 3 avril 2024 disposent de plus d’espace de stockage par partition que les services plus anciens. Avant de passer à un niveau supérieur et à un taux de facturation plus élevé, réexaminez les limites du service de niveau pour voir si le même niveau sur un service plus récent vous offre l’espace de stockage nécessaire.
Conseil : Mettez à jour vers le niveau Standard S2
Les clients commencent souvent par le niveau de recherche Standard S1. Un modèle commun pour les services S1 est que les index croissent avec le temps, ce qui nécessite davantage de partitions. L’augmentation du nombre de partitions entraîne un ralentissement des temps de réponse, ce qui requiert l’ajout de réplicas pour gérer la charge des requêtes. Comme vous pouvez l’imaginer, le coût d’exécution d’un service S1 a maintenant atteint des niveaux dépassant la configuration initiale.
À ce stade, il est important de se demander s’il serait avantageux de passer à un niveau supérieur, plutôt que d’augmenter progressivement le nombre de partitions ou de réplicas du service actuel.
Prenons la topologie suivante comme exemple d’un service qui a pris le parti d’augmenter ces niveaux de capacité :
- Niveau Standard S1
- Taille de l’index : 190 Go
- Nombre de partitions : 8 (sur S1, la taille de chaque partition est de 25 Go)
- Nombre de réplicas : 2
- Nombre total d’unités de recherche : 16 (8 partitions x 2 réplicas)
- Prix de vente hypothétique : environ 4 000 $/mois (en supposant 250 USD x 16 unités de recherche)
Supposons que l’administrateur de services fédérés constate toujours des taux de latence plus élevés et qu’il envisage d’ajouter une autre réplica. Cela ferait passer le nombre de réplicas de 2 à 3 et, par conséquent, le nombre d’unités de recherche à 24, pour un prix de 6 000 USD/mois.
Toutefois, si l’administrateur choisit de passer au niveau Standard S2, la topologie sera la suivante :
- Niveau Standard S2
- Taille de l’index : 190 Go
- Nombre de partitions : 2 (sur S2, la taille de chaque partition est de 100 Go)
- Nombre de réplicas : 2
- Nombre total d’unités de recherche : 4 (2 partitions x 2 réplicas)
- Prix de vente hypothétique : environ 4 000 $/mois (1,000 USD x 4 unités de recherche)
Comme l’illustre ce scénario hypothétique, des configurations de niveaux inférieurs peuvent entraîner les mêmes coûts que si vous aviez opté pour un niveau supérieur dès le départ. Toutefois, les niveaux supérieurs sont dotés d’un stockage premium, ce qui accélère l’indexation. Les niveaux supérieurs offrent également une plus grande puissance de calcul, ainsi qu’une quantité de mémoire supplémentaire. Pour le même coût, vous pourriez avoir une infrastructure plus puissante pour sauvegarder le même index.
Un avantage important de la mémoire supplémentaire est qu’une plus grande partie de l’index peut être mise en cache, ce qui permet de réduire la latence de recherche et d’augmenter le nombre de requêtes par seconde. Grâce à cette puissance supplémentaire, l’administrateur n’aura peut-être même pas besoin d’augmenter le nombre de réplicas et pourra potentiellement payer moins qu’en restant sur le service S1.
Conseil : Envisagez des alternatives aux requêtes d’expression régulière
Les requêtes d’expression régulière ou les expressions régulières peuvent être particulièrement coûteuses. Bien qu’ils puissent être très utiles pour les recherches avancées, l’exécution peut nécessiter beaucoup de puissance de traitement, en particulier si l’expression régulière est compliquée ou si vous effectuez une recherche dans une grande quantité de données. Tous ces facteurs contribuent à une latence élevée de recherche. Pour atténuer ceci, essayez de simplifier l’expression régulière ou de décomposer la requête complexe en requêtes plus petites et plus gérables.
Étapes suivantes
Examinez ces autres articles relatifs aux performances du service :