Tutoriel : indexer des objets blob JSON imbriqués à partir du Stockage Azure en utilisant REST
Remarque
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
La recherche Azure AI peut indexer des tableaux et documents Markdown dans le Stockage Blob Azure à l’aide d’un indexeur qui sait comment lire des données Markdown.
Ce tutoriel vous montre comment indexer les fichiers Markdown indexés à l’aide du mode d’analyse Markdown oneToMany. Il utilise un client REST et les API REST de Recherche pour effectuer les tâches suivantes :
- Configurer des exemples de données et configurer une source de données
azureblob - Créer un index de recherche Azure AI où stocker le contenu de recherche
- Créer et exécuter un indexeur pour lire le conteneur et extraire le contenu de recherche
- Effectuer une recherche dans l’index que vous venez de créer
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
Visual Studio Code avec un client REST.
Recherche Azure AI. Créez ou recherchez une ressource Recherche Azure AI existante sous votre abonnement actuel.
Remarque
Vous pouvez utiliser le service gratuit pour ce tutoriel. Avec un service de recherche gratuit, vous êtes limité à trois index, trois indexeurs et trois sources de données. Ce didacticiel crée une occurrence de chaque élément. Avant de commencer, veillez à disposer de l’espace suffisant sur votre service pour accepter les nouvelles ressources.
Création d’un document Markdown
Copiez et collez la configuration YAML suivante dans un fichier nommé sample_markdown.md. L’exemple de données est un fichier Markdown unique contenant différents éléments Markdown. Nous avons choisi un fichier Markdown afin de rester sous les limites de stockage du niveau gratuit.
# Project Documentation
## Introduction
This document provides a complete overview of the **Markdown Features** used within this project. The following sections demonstrate the richness of Markdown formatting, with examples of lists, tables, links, images, blockquotes, inline styles, and more.
---
## Table of Contents
1. [Headers](#headers)
2. [Introduction](#introduction)
3. [Basic Text Formatting](#basic-text-formatting)
4. [Lists](#lists)
5. [Blockquotes](#blockquotes)
6. [Images](#images)
7. [Links](#links)
8. [Tables](#tables)
9. [Code Blocks and Inline Code](#code-blocks-and-inline-code)
10. [Horizontal Rules](#horizontal-rules)
11. [Inline Elements](#inline-elements)
12. [Escaping Characters](#escaping-characters)
13. [HTML Elements](#html-elements)
14. [Emojis](#emojis)
15. [Footnotes](#footnotes)
16. [Task Lists](#task-lists)
17. [Conclusion](#conclusion)
---
## Headers
Markdown supports six levels of headers. Use `#` to create headers:
"# Project Documentation" at the top of the document is an example of an h1 header.
"## Headers" above is an example of an h2 header.
### h3 example
#### h4 example
##### h5 example
###### h6 example
This is an example of content underneath a header.
## Basic Text Formatting
You can apply various styles to your text:
- **Bold**: Use double asterisks or underscores: `**bold**` or `__bold__`.
- *Italic*: Use single asterisks or underscores: `*italic*` or `_italic_`.
- ~~Strikethrough~~: Use double tildes: `~~strikethrough~~`.
## Lists
### Ordered List
1. First item
2. Second item
3. Third item
### Unordered List
- Item A
- Item B
- Item C
### Nested List
1. Parent item
- Child item
- Child item
## Blockquotes
> This is a blockquote.
> Blockquotes are great for emphasizing important information.
>> Nested blockquotes are also possible!
## Images

## Links
[Visit Markdown Guide](https://www.markdownguide.org)
## Tables
| Syntax | Description | Example |
|-------------|-------------|---------------|
| Header | Title | Header Cell |
| Paragraph | Text block | Row Content |
## Code Blocks and Inline Code
### Inline Code
Use backticks to create `inline code`.
### Code Block
```javascript
// JavaScript example
function greet(name) {
console.log(`Hello, ${name}!`);
}
greet('World');
```
## Horizontal Rules
Use three or more dashes or underscores to create a horizontal rule.
---
___
## Inline Elements
Sometimes, it’s useful to include `inline code` to highlight code-like content.
You can also emphasize text like *this* or make it **bold**.
## Escaping Characters
To render special Markdown characters, use backslashes:
- \*Asterisks\*
- \#Hashes\#
- \[Brackets\]
## HTML Elements
You can mix HTML tags with Markdown:
<table>
<tr>
<th>HTML Table</th>
<th>With Markdown</th>
</tr>
<tr>
<td>Row 1</td>
<td>Data 1</td>
</tr>
</table>
## Emojis
Markdown supports some basic emojis:
- :smile: 😄
- :rocket: 🚀
- :checkered_flag: 🏁
## Footnotes
This is an example of a footnote[^1]. Footnotes allow you to add notes without cluttering the main text.
[^1]: This is the content of the footnote.
## Task Lists
- [x] Complete the introduction
- [ ] Add more examples
- [ ] Review the document
## Conclusion
Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.
Thank you for reviewing this example!
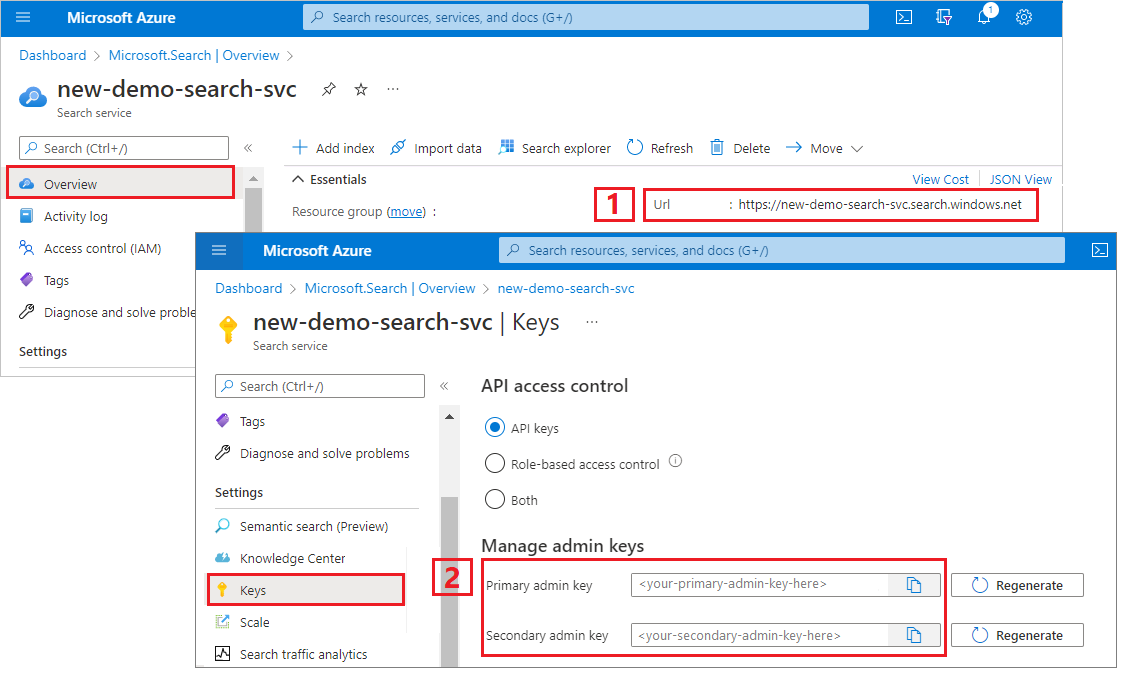
Copier l’URL et la clé API d’un service de recherche
Pour ce tutoriel, les connexions à Recherche Azure AI nécessitent un point de terminaison et une clé API. Vous pouvez obtenir ces valeurs à partir du Portail Azure. Pour obtenir d’autres méthodes de connexion, consultez Identités managées.
Connectez-vous au Portail Azure, accédez à la page Vue d’ensemble du service de recherche et copiez l’URL. Voici un exemple de point de terminaison :
https://mydemo.search.windows.net.Sous Paramètres>Clés, copiez une clé d’administration. Les clés d’administration sont utilisées pour ajouter, modifier et supprimer des objets. Il existe deux clés d’administration interchangeables. Copiez l’une ou l’autre.
Configurer votre fichier REST
Démarrez Visual Studio Code et créez un fichier.
Fournissez des valeurs pour les variables utilisées dans la requête :
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnectionString = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HEREEnregistrez le fichier en utilisant une extension de fichier
.restou.http.
Consultez Démarrage rapide : Recherche de texte à l’aide de REST si vous avez besoin d’aide avec le client REST.
Création d'une source de données
Créer une source de données (REST) permet de créer une connexion à la source de données qui spécifie les données à indexer.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Envoyez la demande. La réponse doit ressembler à ce qui suit :
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DCF52E926A3C76"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('sample-markdown-ds')?api-version=2024-11-01-preview
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 0714c187-217e-4d35-928a-5069251e5cba
elapsed-time: 204
Date: Fri, 25 Oct 2024 19:52:35 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DCF52E926A3C76\"",
"name": "sample-markdown-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "markdown-container",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null,
"identity": null
}
Création d'un index
Créer un index (REST) permet de créer un index de recherche sur votre service de recherche. Un index spécifie tous les champs et leurs attributs.
Dans l’analyse un-à-plusieurs, le document de recherche définit le côté « plusieurs » de la relation. Les champs que vous spécifiez dans l’index déterminent la structure du document de recherche.
Vous avez uniquement besoin de champs pour les éléments Markdown pris en charge par l’analyseur. Ces champs sont les suivants :
content: chaîne qui contient le Markdown brut trouvé dans un emplacement spécifique, en fonction des métadonnées d’en-tête à ce stade du document.sections: objet qui contient des sous-champs pour les métadonnées d’en-tête jusqu’au niveau d’en-tête souhaité. Par exemple, lorsquemarkdownHeaderDepthest défini surh3, contient des champs de chaîneh1,h2eth3. Ces champs sont indexés en mettant en miroir cette structure dans l’index, ou via des mappages de champs au format/sections/h1,sections/h2, etc. Consultez les configurations d’index et d’indexeur dans les exemples suivants pour obtenir des exemples dans le contexte. Les sous-champs contenus sont les suivants :-
h1: chaîne contenant la valeur d’en-tête h1. Chaîne vide si elle n’est pas définie à ce stade dans le document. - (Facultatif)
h2: chaîne contenant la valeur d’en-tête h2. Chaîne vide si elle n’est pas définie à ce stade dans le document. - (Facultatif)
h3: chaîne contenant la valeur d’en-tête h3. Chaîne vide si elle n’est pas définie à ce stade dans le document. - (Facultatif)
h4: chaîne contenant la valeur d’en-tête h4. Chaîne vide si elle n’est pas définie à ce stade dans le document. - (Facultatif)
h5: chaîne contenant la valeur d’en-tête h5. Chaîne vide si elle n’est pas définie à ce stade dans le document. - (Facultatif)
h6: chaîne contenant la valeur d’en-tête h6. Chaîne vide si elle n’est pas définie à ce stade dans le document.
-
ordinal_position: valeur entière indiquant la position de la section dans la hiérarchie de documents. Ce champ est utilisé pour classer les sections dans leur séquence d’origine à mesure qu’ils apparaissent dans le document, en commençant par une position ordinale de 1 et en incrémentant séquentiellement pour chaque bloc de contenu.
Cette implémentation tire parti des mappages de champs dans l’indexeur pour mapper du contenu enrichi à l’index. Pour plus d’informations sur la structure de document un-à-plusieurs analysée, consultez les objets blob Markdown d’index.
Cet exemple fournit des cas d’indexation des données avec et sans mappages de champs. Dans ce cas, nous savons que h1 contient le titre du document, pour que nous puissions le mapper à un champ nommé title. Nous allons également mapper les champs h2 et h3 vers les champs h2_subheader et h3_subheader respectivement. Les champs content et ordinal_position ne nécessitent aucun mappage, car ils sont extraits directement de Markdown dans des champs utilisant ces noms. Pour obtenir un exemple de schéma d’index complet qui ne nécessite pas de mappages de champs, consultez la fin de cette section.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "title", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3_subheader", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Schéma d’index dans une configuration sans mappages de champs
Les mappages de champs vous permettent de manipuler et de filtrer du contenu enrichi pour s’adapter à votre forme d’index souhaitée, mais vous cherchez peut-être simplement à prendre directement le contenu enrichi. Dans ce cas, le schéma se présente comme suit :
{
"name": "sample-markdown-index",
"fields": [
{"name": "id", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "content", "type": "Edm.String", "key": false, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "sections",
"type": "Edm.ComplexType",
"fields": [
{"name": "h1", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h2", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "h3", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
},
{"name": "ordinal_position", "type": "Edm.Int32", "searchable": false, "retrievable": true, "filterable": true, "facetable": true, "sortable": true}
]
}
Comme il a déjà été dit, nous avons des sous-champs jusqu’à h3 dans l’objet sections, car markdownHeaderDepth est défini sur h3.
Si vous choisissez d’utiliser ce schéma, veillez à ajuster les requêtes ultérieures en conséquence. Cela nécessite la suppression des mappages de champs de la configuration de l’indexeur et la mise à jour des requêtes de recherche pour utiliser les noms de champs correspondants.
Créer et exécuter un indexeur
Créer un indexeur permet de créer un indexeur sur votre service de recherche. Un indexeur se connecte à la source de données, charge et indexe des données et peut fournir une planification pour automatiser l’actualisation des données.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "sample-markdown-indexer",
"dataSourceName": "sample-markdown-ds",
"targetIndexName": "sample-markdown-index",
"parameters" : {
"configuration": {
"parsingMode": "markdown",
"markdownParsingSubmode": "oneToMany",
"markdownHeaderDepth": "h3"
}
},
"fieldMappings" : [
{
"sourceFieldName": "/sections/h1",
"targetFieldName": "title",
"mappingFunction": null
}
]
}
Points essentiels :
L’indexeur analyse uniquement les en-têtes jusqu’à
h3. Tous les en-têtes de niveau inférieur (h4,h5,h6) sont traités comme du texte brut et s’affichent dans le champcontent. C’est pourquoi les mappages d’index et de champs existent uniquement jusqu’à une profondeur deh3.Les champs
contentetordinal_positionne nécessitent aucun mappage de champ puisqu’ils existent avec ces noms dans le contenu enrichi.
Exécuter des requêtes
Vous pouvez démarrer la recherche dès que le premier document est chargé.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Envoyez la demande. Il s’agit d’une requête de recherche en texte intégral non spécifiée qui retourne tous les champs marqués comme récupérables dans l’index, ainsi qu’un nombre de documents. La réponse doit ressembler à ce qui suit :
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 6b94e605-55e8-47a5-ae15-834f926ddd14
elapsed-time: 77
Date: Fri, 25 Oct 2024 20:22:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 22,
"value": [
<22 search documents here>
]
}
Ajoutez un paramètre search pour effectuer une recherche sur une chaîne.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "h4",
"count": true,
}
Envoyez la demande. La réponse doit ressembler à ce qui suit :
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: ec5d03f1-e3e7-472f-9396-7ff8e3782105
elapsed-time: 52
Date: Fri, 25 Oct 2024 20:26:29 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 0.8744742,
"section_id": "aHR0cHM6Ly9hcmphZ2Fubmpma2ZpbGVzLmJsb2IuY29yZS53aW5kb3dzLm5ldC9tYXJrZG93bi10dXRvcmlhbC9zYW1wbGVfbWFya2Rvd24ubWQ7NA2",
"content": "#### h4 example\r\n##### h5 example\r\n###### h6 example\r\nThis is an example of content underneath a header.\r\n",
"title": "Project Documentation",
"h2_subheader": "Headers",
"h3_subheader": "h3 example",
"ordinal_position": 4
}
]
}
Points essentiels :
Étant donné que le
markdownHeaderDepthest défini surh3, les en-têtesh4,h5eth6les en-têtes sont traités en texte brut, de sorte qu’ils apparaissent dans le champcontent.La position ordinale ici est
4. Ce contenu apparaît en quatrième position sur les 22 sections de contenu totales.
Ajoutez un paramètre select pour limiter les résultats à moins de champs. Ajoutez un filter pour affiner davantage la recherche.
### Query the index
POST {{baseUrl}}/indexes/sample-markdown-index/docs/search?api-version=2024-11-01-preview HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "Markdown",
"count": true,
"select": "title, content, h2_subheader",
"filter": "h2_subheader eq 'Conclusion'"
}
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a6f9bd46-a064-4e28-818f-ea077618014b
elapsed-time: 35
Date: Fri, 25 Oct 2024 20:36:10 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('sample-markdown-index')/$metadata#docs(*)",
"@odata.count": 1,
"value": [
{
"@search.score": 1.1029507,
"content": "Markdown is a lightweight yet powerful tool for writing documentation. It supports a variety of formatting options while maintaining simplicity and readability.\r\n\r\nThank you for reviewing this example!",
"title": "Project Documentation",
"h2_subheader": "Conclusion"
}
]
}
Pour les filtres, vous pouvez également utiliser des opérateurs logiques (and, or, not) et des opérateurs de comparaison (eq, ne, gt, lt, ge, le). Les comparaisons de chaînes sont sensibles à la casse. Pour plus d’informations et d’exemples, consultez Créer une requête.
Remarque
Le paramètre $filter fonctionne uniquement sur les champs qui ont été marquées comme « filtrables » lors de la création de l’index.
Réinitialiser et réexécuter
Les indexeurs peuvent être réinitialisés, ce qui efface l’historique de l’exécution et permet une réexécution complète. Les requêtes GET suivantes concernent la réinitialisation, suivie de la réexécution.
### Reset the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/reset?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/sample-markdown-indexer/run?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/sample-markdown-indexer/status?api-version=2024-11-01-preview HTTP/1.1
api-key: {{apiKey}}
Nettoyer les ressources
Lorsque vous travaillez dans votre propre abonnement, il est judicieux à la fin d’un projet de supprimer les ressources dont vous n’avez plus besoin. Les ressources laissées en cours d’exécution peuvent vous coûter de l’argent. Vous pouvez supprimer les ressources individuellement, ou supprimer le groupe de ressources pour supprimer l’ensemble des ressources.
Vous pouvez utiliser le portail Azure pour supprimer les index, les indexeurs et les sources de données.
Étapes suivantes
Maintenant que vous êtes familiarisé avec les principes fondamentaux de l’indexation de Stockage Blob Azure, examinons de plus près la configuration de l’indexeur pour les objets blob JSON dans Stockage Azure.