Déboguer un ensemble de compétences Recherche Azure AI dans le Portail Microsoft Azure
Démarrez une session de débogage basée sur le portail pour identifier et résoudre les erreurs, valider les modifications et les envoyer (push) à un ensemble de compétences existant dans votre service Recherche Azure AI.
Une session de débogage est une exécution de l’indexeur et de l’ensemble de compétences mise en cache, délimitée à un seul document, que vous pouvez utiliser pour modifier et tester les changements d’ensemble de compétences de manière interactive. Une fois le débogage terminé, vous pouvez enregistrer vos modifications apportées à l'ensemble de compétences.
Pour obtenir des informations générales sur le fonctionnement d’une session de débogage, consultez Sessions de débogage dans Azure AI Search. Pour vous entraîner à utiliser un flux de travail de débogage avec un exemple de document, consultez Tutoriel : Sessions de débogage.
Prérequis
Un service de Recherche Azure AI. Nous vous recommandons d’utiliser une identité managée affectée par le système et des attributions de rôles qui permettent à Azure AI Search d’écrire dans le stockage Azure et d’appeler les ressources Azure AI utilisées dans l’ensemble de compétences.
Un compte Stockage Azure, utilisé pour sauvegarder l’état de la session.
Un pipeline d’enrichissement existant, y compris une source de données, des compétences, un indexeur et un index.
Pour les attributions de rôles, l’identité du service de recherche doit avoir :
Des autorisations d’utilisateur Cognitive Services sur le compte multiservice Azure AI utilisé par l’ensemble de compétences.
Des autorisations de contributeur de données de blob de stockage sur le stockage Azure. Sinon, prévoyez d'utiliser une chaîne de connexion à accès complet pour la connexion de la session de débogage au stockage Azure.
Si le compte Stockage Microsoft Azure se trouve derrière un pare-feu, configurez-le pour autoriser l'accès au service de recherche.
Limites
Les sessions de débogage fonctionnent avec toutes les sources de données d'indexeur en disponibilité générale et la plupart des sources de données en préversion, avec les exceptions suivantes :
Indexeur SharePoint Online.
Indexeur Azure Cosmos DB for MongoDB.
Pour Azure Cosmos DB for NoSQL, si une ligne échoue pendant l’index et qu’il n’y a pas de métadonnées correspondantes, la session de débogage risque de ne pas choisir la ligne correcte.
Pour l’API SQL d’Azure Cosmos DB, si une collection partitionnée n’était pas partitionnée auparavant, la session de débogage ne trouvera pas le document.
Pour les compétences personnalisées, une identité managée attribuée par l’utilisateur n’est pas prise en charge pour une connexion de session de débogage au stockage Azure. Comme indiqué dans les conditions préalables, vous pouvez utiliser une identité gérée par le système ou spécifier une chaîne de connexion à accès complet qui inclut une clé. Pour plus d’informations, consultez Connecter un service de recherche à d’autres ressources Azure à l’aide d’une identité managée.
Actuellement, la possibilité de sélectionner le document à déboguer n’est pas disponible. Cette limitation n’est pas permanente et sera bientôt levée. À ce stade, les sessions de débogage sélectionnent le premier document dans le conteneur ou le dossier de données source.
Créer une session de débogage
Connectez-vous au Portail Azure, puis trouvez votre service de recherche.
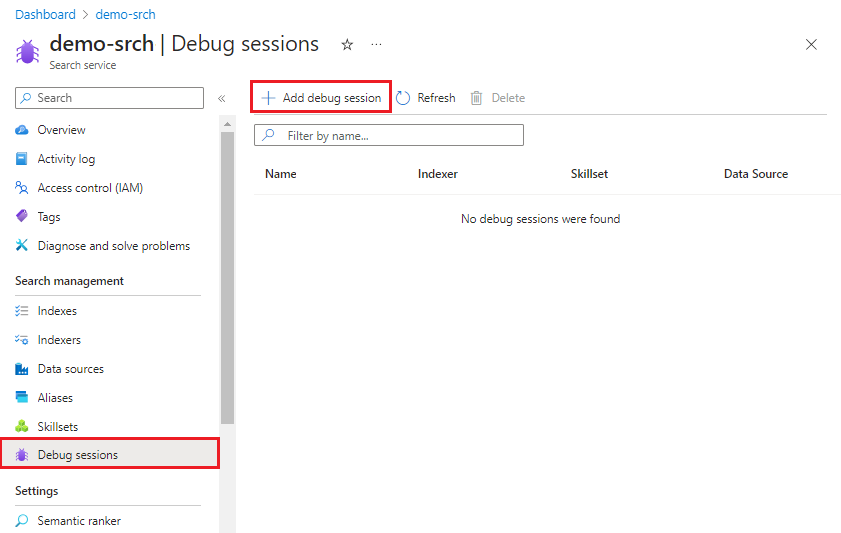
Dans le menu de gauche, sélectionnez Gestion de la recherche>Sessions de débogage.
Dans la barre d'action du haut, sélectionnez Ajouter une session de débogage.
Dans Nom de la session de débogage, fournissez un nom qui vous rappellera les compétences, l’indexeur et la source de données auxquels se rapporte la session de débogage.
Dans Modèle d’indexeur, sélectionnez l’indexeur qui pilote l’ensemble de compétences que vous souhaitez déboguer. Des copies de l’indexeur et de l’ensemble de compétences sont utilisées pour initialiser la session.
Dans Compte de stockage, recherchez un compte de stockage à usage général pour la mise en cache de la session de débogage.
Sélectionnez Authentifier à l’aide de l’identité managée si vous avez précédemment affecté les autorisations Contributeur aux données Blob de stockage à l’identité managée du service de recherche.
Cliquez sur Enregistrer.
- La recherche Azure AI crée un conteneur blob sur le stockage Azure nommé ms-az-cognitive-search-debugsession.
- Dans ce conteneur, il crée un dossier à l’aide du nom que vous avez fourni pour le nom de session.
- Cela démarre votre session de débogage.
Une session de débogage s’ouvre sur la page des paramètres. Vous pouvez apporter des modifications à la configuration initiale et remplacer les valeurs par défaut.
Dans la chaîne de connexion de stockage, vous pouvez spécifier la chaîne de connexion ou modifier le compte de stockage.
Si vous le souhaitez, dans Paramètres de l’indexeur, spécifiez les paramètres d’exécution de l’indexeur à utiliser pour créer la session. Les paramètres doivent correspondre aux paramètres utilisés par l’indexeur réel. Les options d’indexeur que vous spécifiez dans une session de débogage n’ont aucun effet sur l’indexeur lui-même.
Si vous avez effectué des modifications, sélectionnez Enregistrer la session, puis Exécuter.

La session de débogage commence par exécuter l’indexeur et l’ensemble de compétences sur le document sélectionné. Le contenu et les métadonnées du document sont visibles et disponibles dans la session.
Une session de débogage peut être annulée durant son exécution avec le bouton Annuler. Si vous appuyez sur le bouton Annuler , vous devriez être en mesure d’analyser les résultats partiels.
On s'attend à ce qu'une session de débogage prenne plus de temps à s'exécuter que l'indexeur, car elle passe par un traitement supplémentaire.
Démarrer avec les erreurs et avertissements
L’historique d’exécution de l’indexeur dans le portail vous donne une liste complète des erreurs et avertissements pour tous les documents. Dans une session de débogage, les erreurs et avertissements sont limités à un seul document. Vous pouvez parcourir cette liste, y apporter vos modifications, puis revenir à la liste pour vérifier si les problèmes sont résolus.
N’oubliez pas qu’une session de débogage est basée sur un document de l’index tout entier. Si une entrée ou une sortie semble incorrecte, le problème peut être spécifique à ce document. Vous pouvez choisir un autre document pour vérifier si les erreurs et les avertissements sont omniprésents ou spécifiques à un seul document.
Sélectionnez Erreurs ou Avertissements pour obtenir la liste des problèmes.

Il est recommandé de résoudre les problèmes liés aux entrées avant de passer aux sorties.
Pour vérifier qu’une modification résout une erreur, procédez comme suit :
Sélectionnez Enregistrer dans le volet d’informations de la compétence pour conserver vos modifications.
Sélectionnez Exécuter dans la fenêtre de session pour appeler l’exécution des compétences à l’aide de la définition modifiée.
Revenez aux Erreurs ou aux Avertissements pour voir si leur nombre est réduit.
Afficher le contenu enrichi ou généré
Les pipelines d’enrichissement par IA extraient ou déduisent les informations et la structure des documents sources, créant ainsi un document enrichi au passage. Un document enrichi est d’abord créé lors du craquage de document et est rempli avec un nœud racine (/document), ainsi que des nœuds pour tout contenu directement porté à partir de la source de données, par exemple, des métadonnées et la clé de document. Des nœuds additionnels sont créés par des compétences lors de l’exécution des compétences, où chaque sortie de compétence ajoute un nouveau nœud à l’arborescence d’enrichissement.
Tout le contenu créé ou utilisé par un ensemble de compétences apparaît dans l’évaluateur d’expression. Vous pouvez pointer sur les liens pour afficher chaque valeur d’entrée ou de sortie dans l’arborescence de documents enrichie. Pour afficher l’entrée ou la sortie de chaque compétence, procédez comme suit :
Dans une session de débogage, développez la flèche bleue pour afficher les détails contextuels. Par défaut, les détails portent sur la structure de données de document enrichie. Toutefois, si vous sélectionnez une compétence ou un mappage, les détails concernent cet objet.
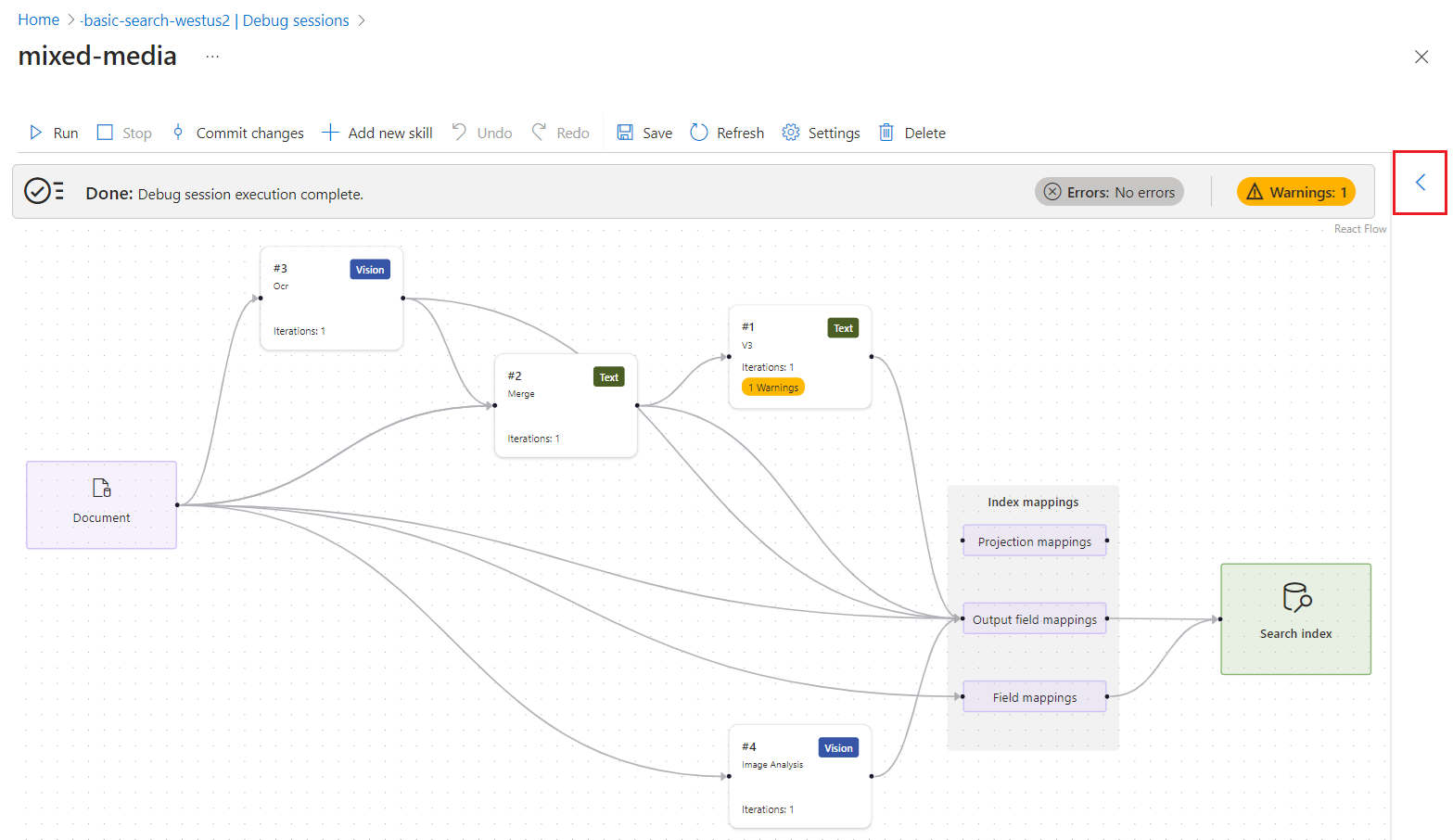
Sélectionnez une compétence.

Suivez les liens pour explorer davantage le traitement des compétences. Par exemple, la capture d’écran suivante montre la sortie de la première itération de la compétence Fractionnement de texte.




Vérifiez les mappages d’index
Si les compétences génèrent une sortie, mais que l’index de recherche est vide, vérifiez les mappages de champs. Les mappages de champs spécifient comment le contenu sort du pipeline et entre dans un index de recherche.
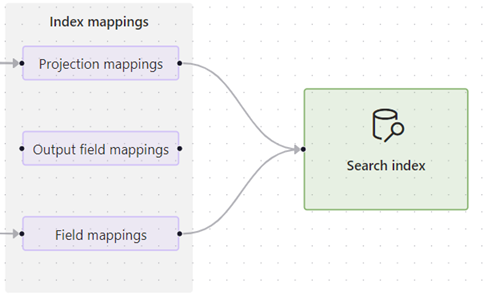
Sélectionnez l’une des options de mappage et développez la vue des détails pour examiner les définitions source et cible.
Les mappages de projections sont trouvés dans des ensembles de compétences qui fournissent une vectorisation intégrée, telles que les compétences créées par l’Assistant Importation et vectorisation des données. Ces mappages déterminent les mappages de champs parent-enfant (segment) et si un index secondaire est créé uniquement pour le contenu segmenté
Les mappages de champs de sortie sont trouvés dans les indexeurs et sont utilisés lorsque des ensembles de compétences appellent des compétences intégrées ou personnalisées. Ces mappages sont utilisés pour définir le chemin des données à partir d’un nœud de l’arborescence d’enrichissement sur un champ de l’index de recherche. Pour plus d’informations sur les chemins d’accès, consultez Syntaxe de chemin de nœud d’enrichissement.
Les mappages de champs sont trouvés dans les définitions d’indexeur et établissent le chemin des données à partir du contenu brut dans la source de données et un champ dans l’index. Vous pouvez également utiliser des mappages de champs pour ajouter des étapes d’encodage et de décodage.
Cet exemple montre les détails d’un mappage de projection. Vous pouvez modifier le fichier JSON pour résoudre les problèmes de mappage.

Modifier les définitions de compétences
Si les mappages de champs sont corrects, vérifiez les compétences individuelles relatives à la configuration et au contenu. Si une compétence ne génère pas de sortie, il se peut qu’il manque une propriété ou un paramètre, ce qui peut être déterminé par le biais des messages d’erreur et de validation.
D’autres problèmes, comme un contexte ou une expression d’entrée non valide, peuvent être plus difficiles à résoudre, car l’erreur indiquera ce qui ne va pas, mais pas comment corriger le problème. Pour obtenir de l’aide sur le contexte et la syntaxe d’entrée, consultez Enrichissements de référence dans un ensemble de compétences Azure AI Search. Pour obtenir de l’aide sur des messages individuels, consultez Dépannage des erreurs et avertissements courants de l’indexeur.
Les étapes suivantes vous montrent comment obtenir des informations sur une compétence.
Sélectionnez une compétence sur l’aire de travail. Le volet Détails de la compétence s’ouvre à droite.
Modifiez une définition de compétence à l’aide des Paramètres de la compétence. Vous pouvez modifier directement le fichier JSON.
Vérifiez la syntaxe du chemin d’accès pour les nœuds de référence dans une arborescence d’enrichissement. Voici quelques-uns des chemins d’accès d’entrée les plus courants :
/document/contentpour les blocs de texte. Ce nœud est rempli à partir de la propriété content de l’objet blob./document/merged_contentpour les segments de texte dans des ensembles de compétences qui incluent une compétence de fusion de texte./document/normalized_images/*pour le texte qui est reconnu ou inféré à partir d’images.
Déboguer une compétence personnalisée localement
Les compétences personnalisées peuvent être plus difficiles à déboguer, car le code s’exécute en externe, de sorte que la session de débogage ne peut pas être utilisée pour les déboguer. Cette section décrit comment déboguer localement votre compétence API Web personnalisée, votre session de débogage, Visual Studio Code et ngrok ou Tunnelmole. Cette technique fonctionne avec les compétences personnalisées qui s’exécutent dans Azure Functions ou tout autre framework web qui s’exécute localement (par exemple, , FastAPI).
Obtenir une URL publique
Cette section décrit deux approches pour obtenir une URL publique vers une compétence personnalisée.
Utiliser Tunnelmole
Tunnelmole est un outil de tunneling open source qui peut créer une URL publique qui transmet les requêtes à votre machine locale via un tunnel.
Installer Tunnelmole :
- npm :
npm install -g tunnelmole - Linux :
curl -s https://tunnelmole.com/sh/install-linux.sh | sudo bash - Mac :
curl -s https://tunnelmole.com/sh/install-mac.sh --output install-mac.sh && sudo bash install-mac.sh - Windows : installez à l'aide de npm. Ou si NodeJS n'est pas installé, téléchargez le fichier .exe précompilé pour Windows et placez-le quelque part dans votre PATH.
- npm :
Exécutez cette commande pour créer un nouveau tunnel :
tmole 7071Vous devriez voir une réponse qui ressemble à ceci :
http://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071 https://m5hdpb-ip-49-183-170-144.tunnelmole.net is forwarding to localhost:7071Dans l’exemple précédent, transfère
https://m5hdpb-ip-49-183-170-144.tunnelmole.netvers le port7071de votre ordinateur local, qui est le port par défaut sur lequel les fonctions Azure sont exposées.
Utiliser ngrok
ngrok est une application multi-plateforme populaire, à code source fermé, qui peut créer une URL de tunneling ou de transfert, afin que les requêtes Internet atteignent votre ordinateur local. Utilisez ngrok pour transférer des requêtes à partir d’un pipeline d’enrichissement de votre service de recherche vers votre machine pour permettre un débogage local.
Installez ngrok.
Ouvrez un terminal et accédez au dossier contenant l’exécutable ngrok.
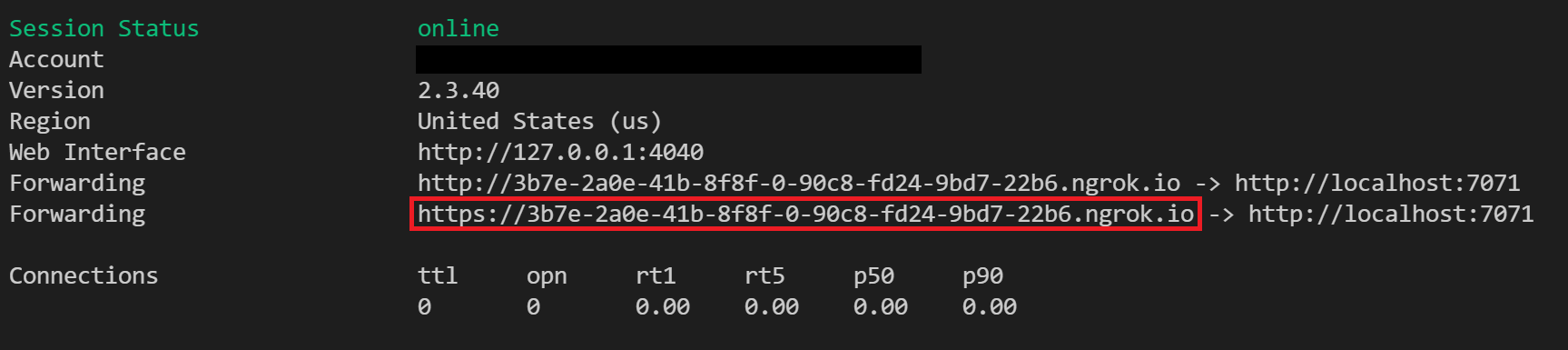
Exécutez ngrok avec la commande suivante pour créer un tunnel :
ngrok http 7071Remarque
Par défaut, les fonctions Azure sont exposées sur 7071. D’autres outils et configurations peuvent nécessiter que vous fournissiez un autre port.
Lorsque ngrok démarre, copiez et enregistrez l’URL de transfert public pour la prochaine étape. L’URL de transfert est générée de façon aléatoire.
Configurer dans le portail Azure
Une fois que vous avez une URL publique pour votre compétence personnalisée, modifiez l’URI de votre compétence API Web personnalisée dans une session de débogage pour appeler l’URL de transfert Tunnelmole ou ngrok. Prenez soin d’ajouter « /api/FunctionName » lors de l’utilisation de fonction Azure pour exécuter le code de l’ensemble de compétences.
Vous pouvez modifier la définition de compétence dans la section Paramètres de la compétence du volet Détails de la compétence.
Test de votre code
À ce stade, les nouvelles demandes de votre session de débogage doivent maintenant être envoyées à votre fonction Azure locale. Vous pouvez utiliser des points d'arrêt dans votre Visual Studio Code pour déboguer votre code ou l'exécuter étape par étape.
Étapes suivantes
Maintenant que vous comprenez la disposition et les fonctionnalités de l’éditeur visuel de sessions de débogage, essayez le tutoriel pour obtenir une expérience pratique.