Responsabilité partagée pour la résilience
Sur la plateforme du cloud public Azure, la résilience est une responsabilité partagée entre Microsoft et vous. Étant donné qu’il existe différents niveaux de résilience dans chaque charge de travail que vous concevez et déployez, il est important de comprendre qui a la responsabilité principale de chacun de ces niveaux du point de vue de la résilience.
Pour vous aider à mieux comprendre le fonctionnement de la responsabilité partagée, en particulier lorsque vous faites face à une panne ou à une catastrophe, cet article explique le modèle de responsabilité partagée pour la résilience. Pour découvrir plus d’informations sur la façon d’utiliser effectivement ce modèle pour planifier la récupération d’urgence, consultez Suggestions pour la conception d’une stratégie de récupération d’urgence.
Modèle de responsabilité partagée pour la résilience
Ce modèle de responsabilité partagée pour la résilience se compose de trois niveaux :
- Fiabilité de la plateforme principale. La plateforme Azure offre un niveau de base de fiabilité pour tous les clients et tous les services via l’infrastructure sous-jacente, les services et les processus.
- Fonctionnalités d’amélioration de la résilience Azure propose une suite de services et de fonctionnalités intégrés qui améliorent la résilience, comme l’utilisation des zones de disponibilité, le déploiement sur plusieurs régions et l’amélioration des stratégies de sauvegarde. Bien qu’Azure fournisse ces fonctionnalités, il vous incombe de les évaluer et de les configurer pour les aligner sur vos exigences spécifiques. Les exigences peuvent inclure la fiabilité, les coûts, les performances et la conformité aux normes réglementaires.
- Applications. Pour utiliser efficacement les autres niveaux, votre application et votre charge de travail doivent être conçues pour la résilience.
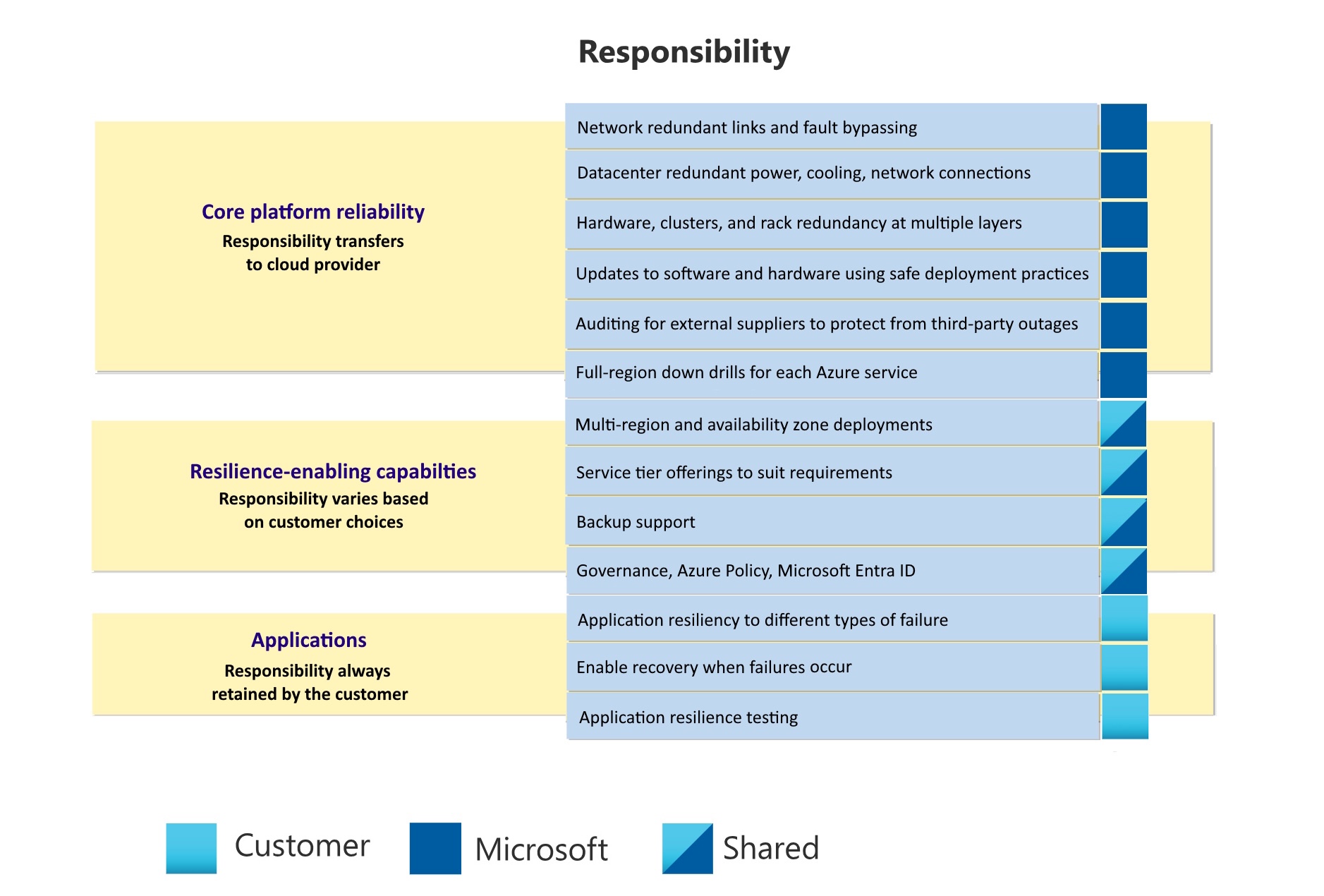
Microsoft est uniquement responsable de la fiabilité de la plateforme principale. Microsoft se charge également de fournir les fonctionnalités d’amélioration de la résilience que vous pouvez utiliser. Vous êtes responsable de la sélection et de l’utilisation des composants appropriés.
Votre choix des catégories de service SaaS, PaaS ou IaaS détermine le type de décisions que vous prenez. Par exemple, si vous utilisez un service SaaS, vous n’avez généralement pas besoin de choisir d’utiliser les zones de disponibilité. Si vous utilisez les services PaaS pour votre niveau de données, il est possible que vous ayez des fonctionnalités automatisées pour la sauvegarde à votre disposition. Si vous utilisez les services IaaS, vous devez généralement planifier et implémenter vous-même plusieurs fonctionnalités de résilience.
Remarque
Les catégories de service (SaaS, PaaS et IaaS) sont utiles en tant que vaste regroupement de services, mais il est important de comprendre vos responsabilités pour chaque service individuel utilisé.
Les guides de fiabilité fournissent une vue d’ensemble du fonctionnement de chaque service du point de vue de la résilience et vous permettent de prendre des décisions éclairées sur la façon de configurer vos services pour répondre à vos besoins.
Vous vous chargez également de la conception de votre application et de votre charge de travail, ainsi que de la définition de vos exigences de fiabilité, ce qui vous permet de décider de la conception et de la configuration de votre solution.
Fiabilité de la plateforme principale
La plateforme cloud Microsoft compte un grand nombre d’infrastructures, de matériels, de logiciels et de processus permettant de prendre en charge la gestion et le déploiement de services. Chaque composant est conçu pour être hautement résilient, avec plusieurs redondances pour les matériels et avec des processus logiciels basés sur la recherche. Ces composants constituent ensemble le niveau de fiabilité de la plateforme principale. Quelques exemples sur la façon dont Microsoft fournit une plateforme fiable sont les suivants :
- Les réseaux ont des liens redondants et peuvent contourner dynamiquement les segments défaillants.
- Au sein de chaque région, les centres de données sont connectés via un réseau à faible latence, ce qui permet une variété d’approches de réplication de données.
- Les installations du centre de données ont des connexions réseau, un refroidissement et une alimentation. Elles sont exploitées par des équipes sur site qui les sécurisent, les monitorent et les gèrent.
- Les matériels, notamment les clusters et les racks, ont une redondance à plusieurs couches.
- Les mises à jour apportées aux hôtes, racks et clusters de calcul suivent un processus contrôlé. Nous utilisons des techniques telles que la mise à jour corrective à chaud pour réduire ou éliminer l’impact sur les hôtes.
- Les modifications de la configuration et les mises à jour apportées à la plateforme logicielle sont appliquées en suivant nos pratiques de déploiement sécurisées.
- Microsoft audite les fournisseurs externes critiques pour veiller à ce qu’une panne tierce ne perturbe pas les services Azure.
- Chaque service Azure doit avoir un plan de récupération d’urgence détaillée. Nous réalisons des simulations dans une région complète des régions correspondant aux environnements de production.
Tous les services Azure profitent de ces fonctionnalités de fiabilité de la plateforme principale et des améliorations continues apportées par Microsoft.
Fonctionnalités d’amélioration de la résilience
Azure fournit plusieurs fonctionnalités différentes d’amélioration de la résilience. Bien que Microsoft se charge de la fourniture de ces fonctionnalités, vous êtes entièrement responsable de la sélection et de l’utilisation de celles appropriées à vos besoins. En voici quelques exemples :
Régions. Azure a plus de 60 régions. Vous pouvez utiliser de nombreuses régions dans une seule solution pour parvenir à la géo-redondance, répondre à vos besoins de résidence des données et activer la communication à faible latence pour les utilisateurs dans le monde entier. Pour en savoir plus sur les régions, consultez Qu’est-ce que les régions Azure ?.
Zones de disponibilité. Plusieurs régions Azure prennent en charge les zones de disponibilité qui vous permettent de distribuer vos charges de travail sur plusieurs ensembles de centres de données indépendants. Les services Azure prennent en charge les zones de disponibilité de façon à ce qu’elles répondent à leurs fins prévues, généralement en prenant en charge les déploiements zonaux (épinglés à une seule zone) et/ou les déploiements redondants interzone (répartis entre de nombreuses zones). Pour découvrir plus d’informations sur les zones de disponibilité, consultez Que sont les zones de disponibilité ?.
Niveaux de service. Les services fournissent une gamme d’offres et de niveaux convenant à différentes exigences. Par exemple, lorsque vous créez une machine virtuelle, vous pouvez choisir entre un disque standard, qui offre une option économique, ou un disque Premium pour obtenir un niveau plus élevé de disponibilité.
Sauvegardes. De nombreux services Azure stockant des données prennent en charge les sauvegardes qui peuvent être automatiques, manuelles ou les deux. Grâce aux sauvegardes, vous pouvez protéger votre charge de travail contre les pannes, ainsi que l’altération des données et d’autres événements de perte de données.
Gouvernance. Les fonctionnalités de la plateforme, telles qu’Azure Policy, le contrôle d’accès en fonction du rôle et les fonctionnalités de protection des identités Microsoft Entra ID, peuvent être configurées pour appliquer constamment les exigences de votre organisation. Ces approches vous permettent de protéger vos charges de travail contre les incidents de sécurité et les modifications accidentelles pouvant provoquer un temps d’arrêt ou d’autres problèmes avec votre charge de travail.
Important
Il est important de comprendre les contrats de niveau du service (SLA) pour chaque service Azure. Les SLA fournissent d’importantes informations sur la durée de bon fonctionnement attendue du service et toutes les conditions que vous devez respecter pour être éligible au contrat SLA. Pour connaître les contrats SLA de chaque service, consultez Contrats de niveau de service pour les services en ligne.
Applications
Il est de votre responsabilité de vérifier que vos applications sont conçues pour être résilientes. Utilisez les piliers Azure Well-Architected Framework* pour stimuler l’excellence architecturale au niveau fondamental d’une charge de travail. Le pilier de fiabilité se concentre sur la façon dont vous rendez votre charge de travail et vos applications résilientes aux différents types d’échec et activez la récupération lorsque des échecs se produisent.
Étapes suivantes
Le modèle de responsabilité partagée s’applique aux autres parties de votre solution au-delà de la résilience. Pour découvrir plus d’informations sur le modèle de responsabilité partagée pour la sécurité, consultez Centre de gestion de la confidentialité Microsoft.