Résoudre les problèmes et identifier les requêtes s’exécutant lentement dans Azure Database pour PostgreSQL - Serveur flexible
S’APPLIQUE À :  Azure Database pour PostgreSQL : serveur flexible
Azure Database pour PostgreSQL : serveur flexible
Cet article explique comment identifier et diagnostiquer la cause racine des requêtes s’exécutant lentement.
Cet article porte sur les points suivants :
- Comment identifier les requêtes s’exécutant lentement.
- Comment identifier une procédure s’exécutant lentement en parallèle. Identifier une requête s’exécutant lentement parmi une liste de requêtes qui appartiennent à la même procédure stockée d’exécution lente.
Prérequis
Activez les guides de résolution des problèmes en suivant les étapes décrites dans les guides de résolution des problèmes.
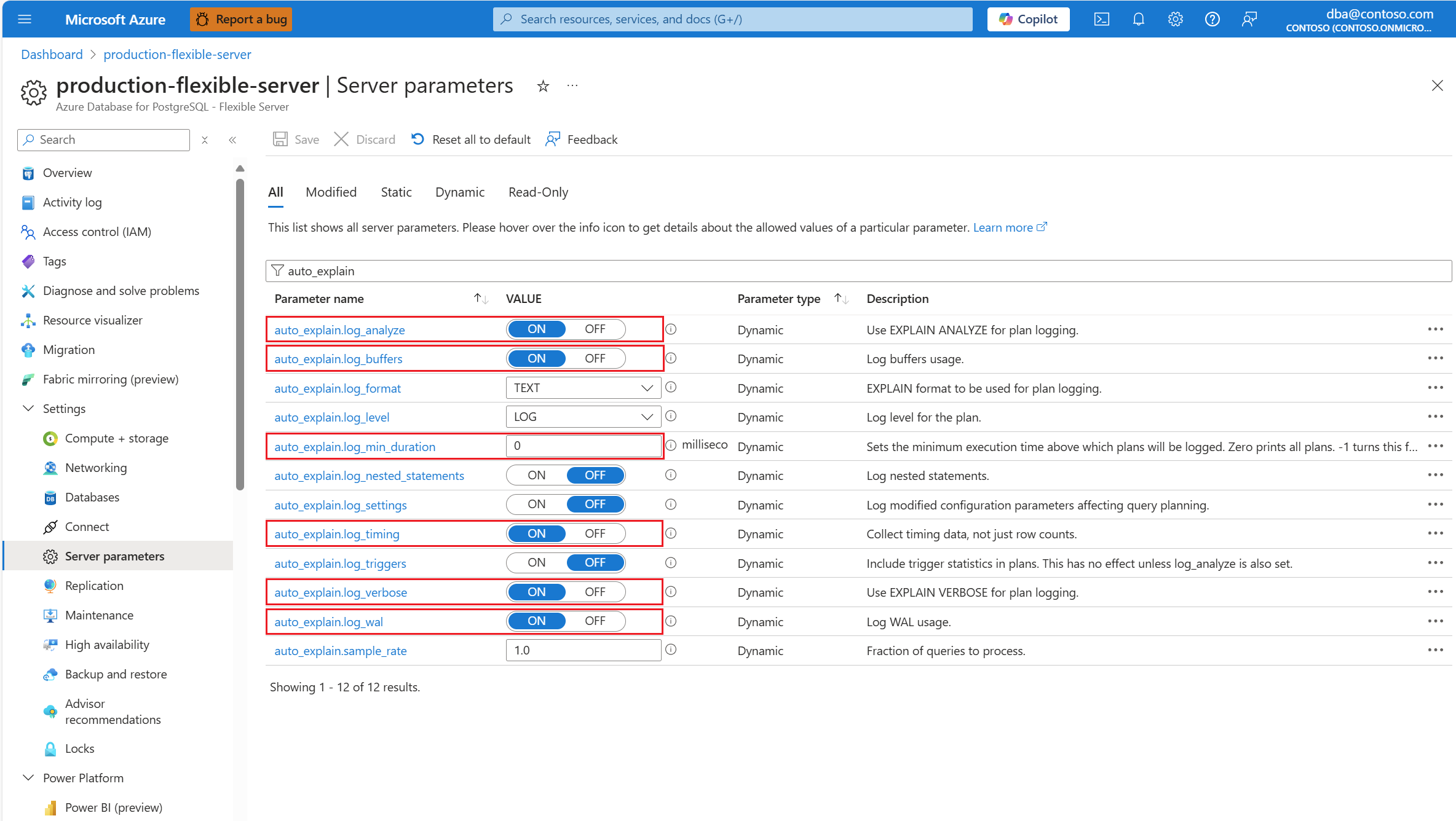
Configurez l’extension
auto_explainen mettant sur liste d’autorisation et en chargeant l’extension.Une fois l’extension
auto_explainconfigurée, modifiez les paramètres de serveur suivants, qui contrôlent le comportement de l’extension :auto_explain.log_analyzeenON.auto_explain.log_buffersenON.auto_explain.log_min_durationselon ce qui est raisonnable dans votre scénario.auto_explain.log_timingenON.auto_explain.log_verboseenON.

Remarque
Si vous définissez auto_explain.log_min_duration sur 0, l’extension démarre la journalisation de toutes les requêtes exécutées sur le serveur. Cela peut avoir un impact sur le niveau de performance de la base de données. Une diligence raisonnable appropriée doit être exercée pour arriver à une valeur considérée comme lente sur le serveur. Par exemple, si toutes les requêtes se terminent en moins de 30 000 secondes, et que cela est acceptable pour votre application, il est conseillé de mettre à jour le paramètre à 30 000 millisecondes. Cela journaliserait ensuite toute requête qui prend plus de 30 secondes.
Identifier la requête lente
À l’aide des guides de résolution des problèmes et de l’extension auto_explain existante, nous décrivons le scénario avec l’aide d’un exemple.
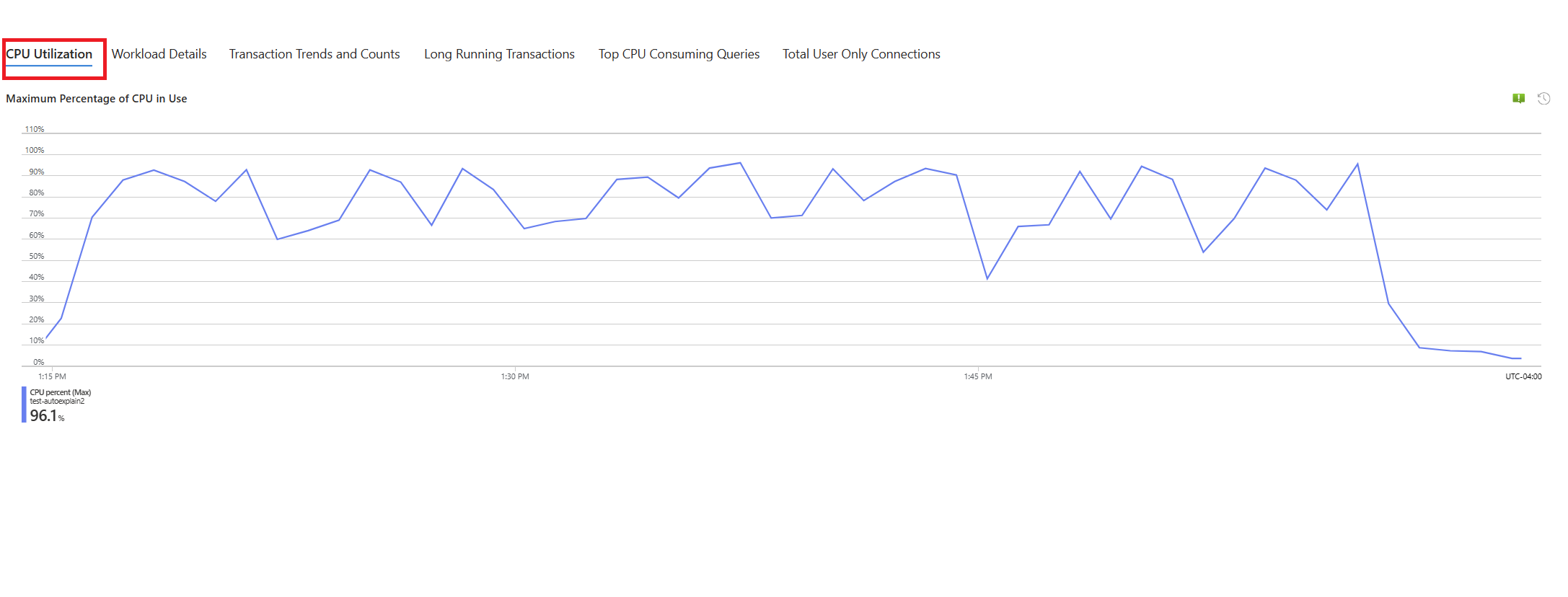
Nous avons un scénario où l’utilisation du processeur atteint 90 % et nous voulons déterminer la cause de ce pic. Pour déboguer le scénario, procédez comme suit :
Dès que vous recevez une alerte concernant un scénario de processeur, dans le menu de ressources de l’instance affectée de serveur flexible Azure Database pour PostgreSQL, sous la section Surveillance, sélectionnez Guides de résolution des problèmes.
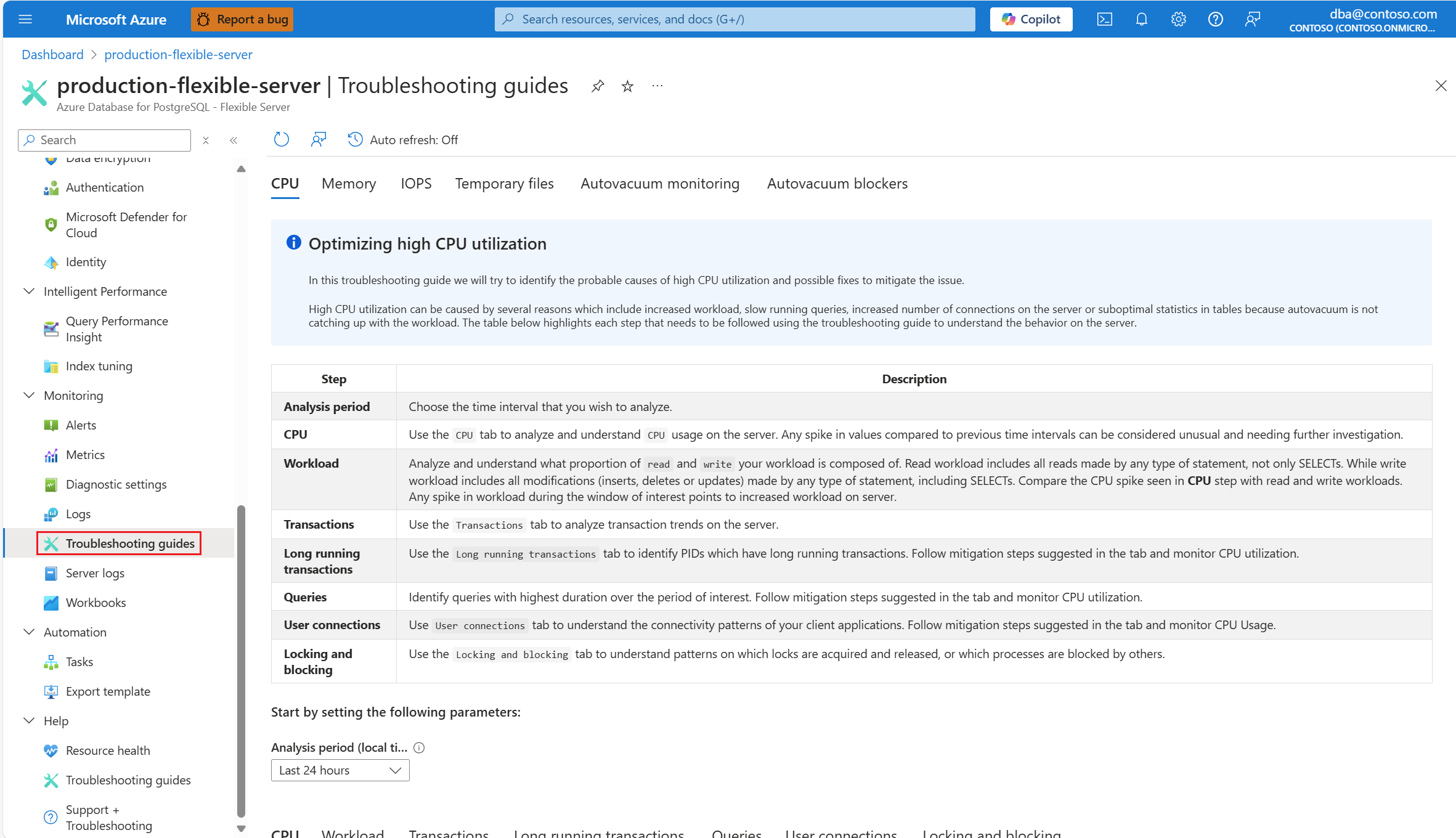
Sélectionnez l’onglet Processeur. Le guide de résolution des problèmes Optimisation de l’utilisation élevée du processeur s’ouvre.

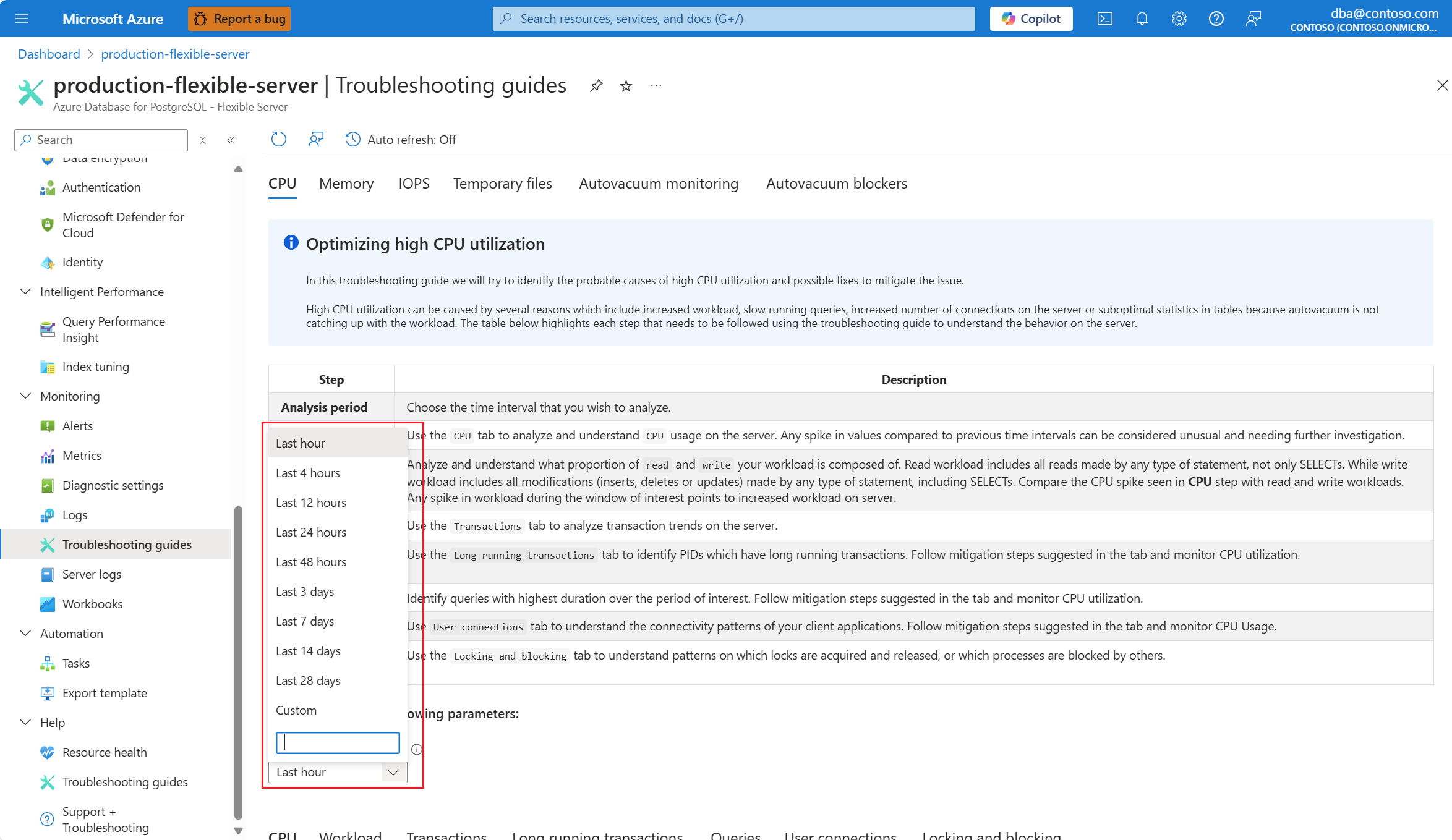
Dans la liste déroulante Période d’analyse (heure locale), sélectionnez l’intervalle de temps sur lequel vous souhaitez concentrer l’analyse.
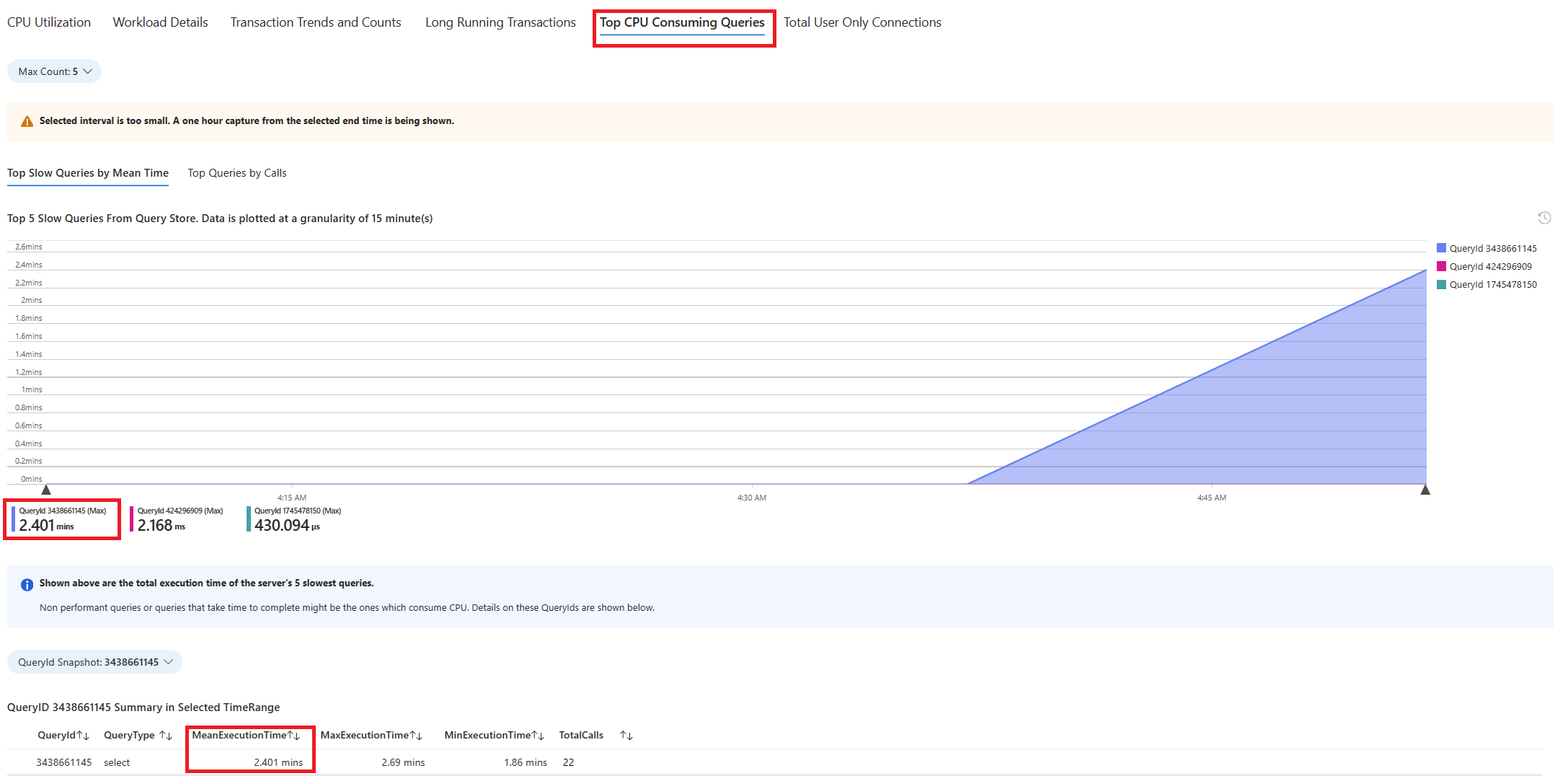
Sélectionnez l’onglet Requêtes. Il contient les détails de toutes les requêtes exécutées dans l’intervalle où une utilisation du processeur de 90 % a été observée. À partir de l’instantané, il semble que la requête avec le temps d’exécution moyen le plus long au cours de l’intervalle de temps était d’environ 2,6 minutes, et que la requête a exécutée 22 fois pendant l’intervalle. Cette requête est probablement la cause des pics d’utilisation du processeur.
Pour récupérer le texte de requête réel, connectez-vous à la base de données
azure_syset exécutez la requête suivante.




psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- Dans l’exemple considéré, la requête trouvée lente était :
SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id, c_id
ORDER BY c_w_id;
Pour comprendre quel plan d’explication exact a été généré, utilisez les journaux du serveur flexible Azure Database pour PostgreSQL. Chaque fois que la requête a terminé l’exécution pendant cette fenêtre de temps, l’extension
auto_explaindoit écrire une entrée dans les journaux. Dans le menu de la ressource, sous la section Surveillance, sélectionnez Journaux.
Sélectionnez l’intervalle de temps où une utilisation du processeur de 90 % a été constatée.
Exécutez la requête suivante pour récupérer la sortie d’EXPLAIN ANALYZE pour la requête identifiée.

AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
La colonne de message stocke le plan d’exécution comme indiqué dans cette sortie :
2024-11-10 19:56:46 UTC-6525a8e7.2e3d-LOG: duration: 150692.864 ms plan:
Query Text: SELECT c_id, SUM(c_balance) AS total_balance
FROM customer
GROUP BY c_w_id,c_id
order by c_w_id;
GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=70930.833..129231.950 rows=10000000 loops=1)
Output: c_id, sum(c_balance), c_w_id
Group Key: customer.c_w_id, customer.c_id
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=70930.821..81898.430 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
Sort Key: customer.c_w_id, customer.c_id
Sort Method: external merge Disk: 225104kB
Buffers: shared hit=44639 read=355362, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.021..22997.697 rows=10000000 loops=1)
Output: c_id, c_w_id, c_balance
La requête s’est exécutée pendant environ 2,5 minutes, comme indiqué dans le guide de résolution des problèmes. La valeur duration de 150 692,864 ms de la sortie du plan d’exécution extraite le confirme. Utilisez la sortie d’EXPLAIN ANALYZE pour résoudre les problèmes et régler la requête.
Remarque
Observez que la requête a été exécutée 22 fois pendant l’intervalle, et que les journaux affichés contiennent l’une de ces entrées capturées pendant l’intervalle.
Identifier les requêtes s’exécutant lentement dans une procédure stockée
À l’aide des guides de résolution des problèmes et de l’extension auto_explain existante, nous expliquons le scénario avec l’aide d’un exemple.
Nous avons un scénario où l’utilisation du processeur atteint 90 % et nous voulons déterminer la cause de ce pic. Pour déboguer le scénario, procédez comme suit :
Dès que vous recevez une alerte concernant un scénario de processeur, dans le menu de ressources de l’instance affectée de serveur flexible Azure Database pour PostgreSQL, sous la section Surveillance, sélectionnez Guides de résolution des problèmes.
Sélectionnez l’onglet Processeur. Le guide de résolution des problèmes Optimisation de l’utilisation élevée du processeur s’ouvre.
Dans la liste déroulante Période d’analyse (heure locale), sélectionnez l’intervalle de temps sur lequel vous souhaitez concentrer l’analyse.
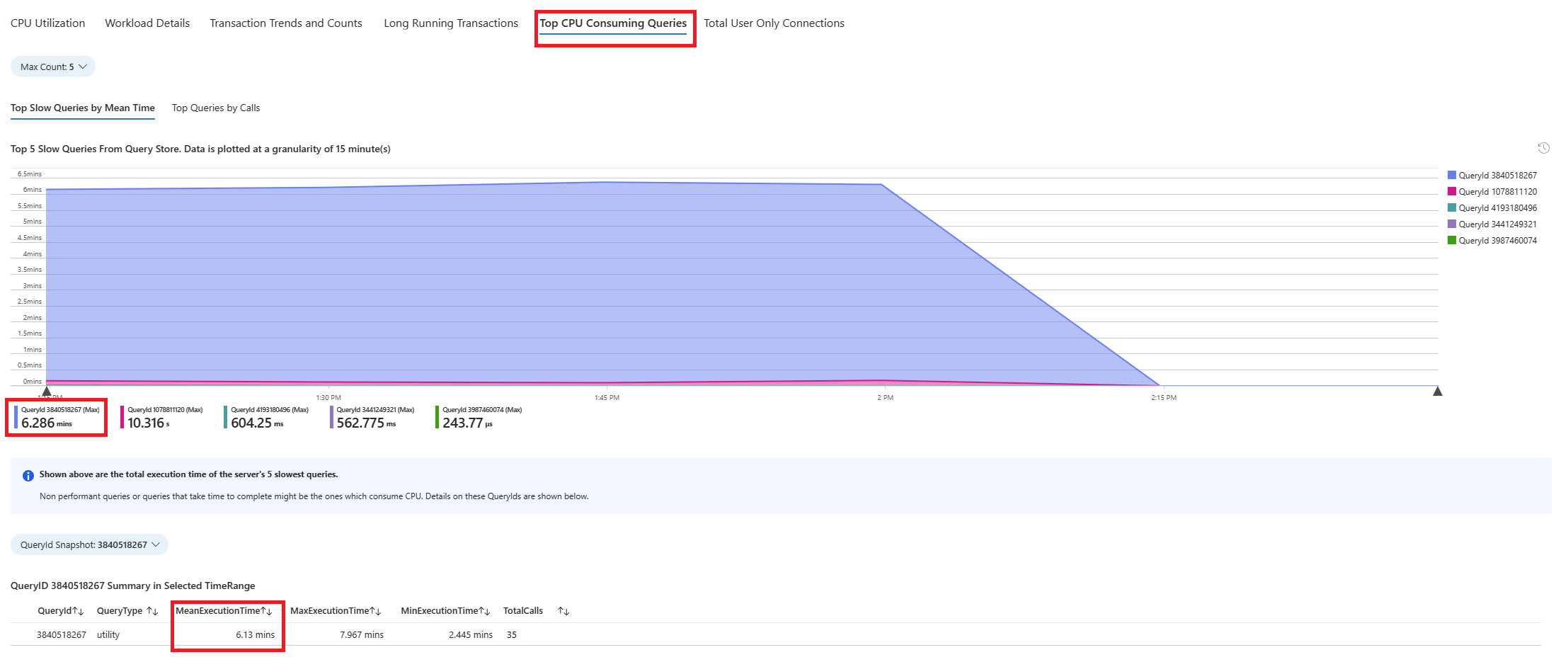
Sélectionnez l’onglet Requêtes. Il contient les détails de toutes les requêtes exécutées dans l’intervalle où une utilisation du processeur de 90 % a été observée. À partir de l’instantané, il semble que la requête avec le temps d’exécution moyen le plus long au cours de l’intervalle de temps était d’environ 2,6 minutes, et que la requête a exécutée 22 fois pendant l’intervalle. Cette requête est probablement la cause des pics d’utilisation du processeur.
Connectez-vous à la base de données azure_sys et exécutez la requête pour récupérer le texte de requête réel à l’aide du script suivant.


psql -h <server>.postgres.database.azure.com -U <user> -d azure_sys
SELECT query_sql_text
FROM query_store.query_texts_view
WHERE query_text_id = <query_id>;
- Dans l’exemple considéré, la requête trouvée lente était une procédure stockée :
call autoexplain_test ();
- Pour comprendre quel plan d’explication exact a été généré, utilisez les journaux du serveur flexible Azure Database pour PostgreSQL. Chaque fois que la requête a terminé l’exécution pendant cette fenêtre de temps, l’extension
auto_explaindoit écrire une entrée dans les journaux. Dans le menu de la ressource, sous la section Surveillance, sélectionnez Journaux. Ensuite, dans Intervalle de temps :, sélectionnez la fenêtre de temps dans laquelle vous souhaitez concentrer l’analyse.

- Exécutez la requête suivante pour récupérer l’explication de la sortie d’analyse de la requête identifiée.
AzureDiagnostics
| where Category contains 'PostgreSQLLogs'
| where Message contains "<snippet of SQL text identified or name of any of the tables referenced in the query>"
| project TimeGenerated, Message
La procédure comporte plusieurs requêtes, qui sont mises en évidence ci-dessous. L’explication de la sortie d’analyse de chaque requête utilisée dans la procédure stockée est consignée pour analyser plus loin et résoudre les problèmes. Le temps d’exécution des requêtes journalisées peut être utilisé pour identifier les requêtes les plus lentes qui font partie de la procédure stockée.
2024-11-10 17:52:45 UTC-6526d7f0.7f67-LOG: duration: 38459.176 ms plan:
Query Text: insert into customer_balance SELECT c_id, SUM(c_balance) AS total_balance FROM customer GROUP BY c_w_id,c_id order by c_w_id
Insert on public.customer_balance (cost=1906820.83..2231820.83 rows=0 width=0) (actual time=38459.173..38459.174 rows=0 loops=1)Buffers: shared hit=10108203 read=454055 dirtied=54058, temp read=77521 written=77701 WAL: records=10000000 fpi=1 bytes=640002197
-> Subquery Scan on "*SELECT*" (cost=1906820.83..2231820.83 rows=10000000 width=36) (actual time=20415.738..29514.742 rows=10000000 loops=1)
Output: "*SELECT*".c_id, "*SELECT*".total_balance Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> GroupAggregate (cost=1906820.83..2131820.83 rows=10000000 width=40) (actual time=20415.737..28574.266 rows=10000000 loops=1)
Output: customer.c_id, sum(customer.c_balance), customer.c_w_id Group Key: customer.c_w_id, customer.c_id Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Sort (cost=1906820.83..1931820.83 rows=10000000 width=13) (actual time=20415.723..22023.515 rows=10000000 loops=1)
Output: customer.c_id, customer.c_w_id, customer.c_balance Sort Key: customer.c_w_id, customer.c_id Sort Method: external merge Disk: 225104kB Buffers: shared hit=1 read=400000, temp read=77521 written=77701
-> Seq Scan on public.customer (cost=0.00..500001.00 rows=10000000 width=13) (actual time=0.310..15061.471 rows=10000000 loops=1) Output: customer.c_id, customer.c_w_id, customer.c_balance Buffers: shared hit=1 read=400000
2024-11-10 17:52:07 UTC-6526d7f0.7f67-LOG: duration: 61939.529 ms plan:
Query Text: delete from customer_balance
Delete on public.customer_balance (cost=0.00..799173.51 rows=0 width=0) (actual time=61939.525..61939.526 rows=0 loops=1) Buffers: shared hit=50027707 read=620942 dirtied=295462 written=71785 WAL: records=50026565 fpi=34 bytes=2711252160
-> Seq Scan on public.customer_balance (cost=0.00..799173.51 rows=15052451 width=6) (actual time=3185.519..35234.061 rows=50000000 loops=1)
Output: ctid Buffers: shared hit=27707 read=620942 dirtied=26565 written=71785 WAL: records=26565 fpi=34 bytes=11252160
2024-11-10 17:51:05 UTC-6526d7f0.7f67-LOG: duration: 10387.322 ms plan:
Query Text: select max(c_id) from customer
Finalize Aggregate (cost=180185.84..180185.85 rows=1 width=4) (actual time=10387.220..10387.319 rows=1 loops=1) Output: max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Gather (cost=180185.63..180185.84 rows=2 width=4) (actual time=10387.214..10387.314 rows=1 loops=1)
Output: (PARTIAL max(c_id)) Workers Planned: 2 Workers Launched: 0 Buffers: shared hit=37148 read=1204 written=69
-> Partial Aggregate (cost=179185.63..179185.64 rows=1 width=4) (actual time=10387.012..10387.013 rows=1 loops=1) Output: PARTIAL max(c_id) Buffers: shared hit=37148 read=1204 written=69
-> Parallel Index Only Scan using customer_i1 on public.customer (cost=0.43..168768.96 rows=4166667 width=4) (actual time=0.446..7676.356 rows=10000000 loops=1)
Output: c_w_id, c_d_id, c_id Heap Fetches: 24 Buffers: shared hit=37148 read=1204 written=69
Remarque
À des fins de démonstration, la sortie EXPLAIN ANALYZE ne contient que quelques requêtes utilisées dans la procédure. L’idée est de rassembler la sortie EXPLAIN ANALYZE de toutes les requêtes à partir des journaux, d’identifier les plus lentes d’entre elles et d’essayer de les régler.
Contenu connexe
- Résoudre les problèmes d’utilisation élevée du processeur dans Azure Database pour PostgreSQL - Serveur flexible.
- Résoudre les problèmes liés à l’utilisation élevée d’IOPS pour Azure Database pour PostgreSQL – Serveur flexible
- Résoudre les problèmes liés à l’utilisation élevée de la mémoire dans Azure Database pour PostgreSQL – Serveur flexible.
- Paramètres serveur dans Azure Database pour PostgreSQL – Serveur flexible.
- Réglage du vide automatique dans la base de données Azure pour PostgreSQL - Serveur flexible.