Vue d’ensemble de la continuité d’activité dans Azure Database pour PostgreSQL – Serveur flexible
S’APPLIQUE À :  Azure Database pour PostgreSQL - Serveur flexible
Azure Database pour PostgreSQL - Serveur flexible
La continuité d’activité dans Azure Database pour PostgreSQL – Serveur flexible fait référence aux mécanismes, stratégies et procédures qui permettent à votre entreprise de continuer à fonctionner en cas d’interruption affectant notamment son infrastructure informatique. Dans la plupart des cas, Azure Database pour PostgreSQL – Serveur flexible gère les événements perturbateurs qui peuvent se produire dans l’environnement cloud et maintient l’exécution de vos applications et processus métier. Toutefois, certains événements ne peuvent pas être gérés automatiquement, par exemple :
- Un utilisateur supprime ou met à jour accidentellement une ligne dans une table.
- Le tremblement de terre provoque une panne de courant et désactive temporairement une zone de disponibilité ou une région.
- Mise à jour corrective de base de données requise pour corriger un bogue ou un problème de sécurité.
Le serveur flexible Azure Database pour PostgreSQL fournit des fonctionnalités qui protègent les données et atténuent les temps d’arrêt de vos bases de données stratégiques pendant les événements de temps d’arrêt planifiés et non planifiés. Reposant sur l’infrastructure Azure qui offre une résilience et une disponibilité robustes, le Azure Database pour PostgreSQL – Serveur flexible offre des fonctionnalités de continuité d’activité qui fournissent une autre protection contre les pannes, répondent aux exigences de temps de récupération et réduisent l’exposition aux pertes de données. À mesure que vous architecturez vos applications, vous devez prendre en compte la tolérance aux temps d’arrêt, l’objectif de temps de récupération (RTO), et l’exposition à la perte de données, l’objectif de point de récupération (RPO). Par exemple, votre base de données vitale pour l’entreprise impose une durée de bon fonctionnement plus stricte qu’une base de données de test.
Le tableau ci-dessous illustre les fonctionnalités offertes par le service Azure Database pour PostgreSQL – Serveur flexible.
| Fonctionnalité | Description | Considérations |
|---|---|---|
| Sauvegardes automatiques | Azure Database pour PostgreSQL – Serveur flexible effectue automatiquement des sauvegardes quotidiennes de vos fichiers de base de données et sauvegarde en permanence les journaux des transactions. Les sauvegardes peuvent être conservées de 7 à 35 jours. Vous pouvez restaurer votre serveur de base de données à n’importe quel point dans le temps au cours de la période de conservation de votre sauvegarde. Le RTO dépend de la taille des données à restaurer et la durée d’exécution de la récupération du journal. Il peut aller de quelques minutes à 12 heures. Pour plus d’informations, consultez Concepts – Sauvegarde et restauration. | Les données de sauvegarde restent dans la région. |
| Haute disponibilité redondante interzone | Vous pouvez déployer Azure Database pour PostgreSQL – Serveur flexible avec une configuration de haute disponibilité (HA) redondante interzone où les serveurs primaire et de secours sont déployés dans deux zones de disponibilité différentes au sein d’une même région. Cette configuration de haute disponibilité protège vos bases de données contre les défaillances au niveau de la zone, et permet de réduire les temps d’arrêt d’applications pendant les temps d’arrêt planifiés et non planifiés. Les données du serveur primaire sont répliquées vers le serveur réplica de secours en mode synchrone. En cas d’interruption du serveur primaire, le serveur est automatiquement basculé vers le réplica de secours. Dans la plupart des cas, le RPO devrait être de moins de 120 secondes. Le RPO est supposé être égal à zéro (aucune perte de données). Pour plus d'informations, voir [Concepts – Haute disponibilité]/azure/reliability/reliability-postgresql-flexible-server. | Pris en charge dans les niveaux de calcul à usage général et à mémoire optimisée. Disponible uniquement dans les régions où plusieurs zones sont disponibles. |
| Haute disponibilité dans la même zone | Vous pouvez déployer Azure Database pour PostgreSQL – Serveur flexible avec la même configuration de haute disponibilité (HA) de zone où les serveurs primaires et de secours sont déployés dans la même zone de disponibilité dans une région. Cette configuration de haute disponibilité protège vos bases de données contre les défaillances au niveau du nœud, et permet de réduire les temps d’arrêt d’applications pendant les temps d’arrêt planifiés et non planifiés. Les données du serveur primaire sont répliquées vers le serveur réplica de secours en mode synchrone. En cas d’interruption du serveur primaire, le serveur est automatiquement basculé vers le réplica de secours. Dans la plupart des cas, le RPO devrait être de moins de 120 secondes. Le RPO est supposé être égal à zéro (aucune perte de données). Pour plus d'informations, voir [Concepts – Haute disponibilité]/azure/reliability/reliability-postgresql-flexible-server. | Pris en charge dans les niveaux de calcul à usage général et à mémoire optimisée. |
| Disques managés Premium | Les fichiers de base de données sont stockés dans un stockage managé Premium durable et fiable. Cela assure une redondance des données avec trois copies du réplica stockées dans une zone de disponibilité avec des fonctionnalités de récupération de données automatiques. Pour plus d’informations, consultez la Documentation sur la fonctionnalité Disques managés. | Données stockées dans une zone de disponibilité. |
| Sauvegarde redondante interzone | Les sauvegardes Azure Database pour PostgreSQL – Serveur flexible sont automatiquement stockées en toute sécurité dans un stockage redondant interzone au sein d’une région, si la région prend en charge les zones de disponibilité. Au cours d’une défaillance au niveau de la zone où votre serveur est provisionné, si votre serveur n’est pas configuré avec une redondance de zone, vous pouvez toujours restaurer votre base de données à l’aide du dernier point de restauration dans une autre zone. Pour plus d’informations, consultez Concepts – Sauvegarde et restauration. | Applicable uniquement dans les régions où plusieurs zones sont disponibles. |
| Sauvegarde géoredondante | Les sauvegardes Azure Database pour PostgreSQL – Serveur flexible sont copiées dans une région distante. Cela est utile pour la récupération d’urgence en cas de panne de la région du serveur primaire. | Cette fonctionnalité est actuellement activée dans les régions sélectionnées. Elle accepte RTO plus long et un RPO plus élevé en fonction de la taille des données à restaurer et de l’ampleur de la récupération à effectuer. |
| Réplica en lecture | Des réplicas de lecture interrégion peuvent être déployés pour protéger vos bases de données contre les défaillances au niveau de la région. Les réplicas en lecture sont mis à jour de manière asynchrone à l’aide de la technologie de réplication physique de PostgreSQL et peuvent présenter un décalage avec le serveur principal. Pour en savoir plus, consultez Concepts - Réplicas en lecture. | Pris en charge dans les niveaux de calcul à usage général et à mémoire optimisée. |
Le tableau suivant compare le RTO et le RPO dans un scénario de charge de travail classique :
| Fonctionnalité | Expansible | Usage général | Mémoire optimisée |
|---|---|---|---|
| Limite de restauration dans le temps à partir de la sauvegarde | N’importe quel point de restauration dans la période de rétention RTO – Variable RPO < 5 min |
N’importe quel point de restauration dans la période de rétention RTO – Variable RPO < 5 min |
N’importe quel point de restauration dans la période de rétention RTO – Variable RPO < 5 min |
| Géo-restauration à partir de sauvegardes répliquées géographiquement | RTO – Variable RPO < 1 h |
RTO – Variable RPO < 1 h |
RTO – Variable RPO < 1 h |
| Réplicas en lecture | RTO – Quelques minutes* RPO < 5 min* |
RTO – Quelques minutes* RPO < 5 min* |
RTO – Quelques minutes* RPO < 5 min* |
* Le RTO et le RPO peuvent être beaucoup plus élevés dans certains cas en fonction de différents facteurs, notamment la latence entre les sites, la quantité de données à transmettre et, surtout, la charge de travail d’écriture de la base de données primaire.
Événements de temps d’arrêt planifiés
Voici quelques scénarios de maintenance planifiée. Ces événements occasionnent généralement quelques minutes de temps d’arrêt, sans perte de données.
| Scénario | Processus |
|---|---|
| Mise à l’échelle du calcul (initiée par l’utilisateur) | Pendant l’opération de mise à l’échelle du calcul, les points de contrôle actifs sont autorisés à cesser d’opérer, les connexions clientes sont purgées, toutes les transactions non validées sont annulées, le stockage est détaché puis le serveur est arrêté. Une nouvelle instance Azure Database pour PostgreSQL – Serveur flexible portant le même nom de serveur de base de données est approvisionnée avec la configuration de calcul mise à l’échelle. Le stockage est ensuite attaché au nouveau serveur et la base de données est démarrée, ce qui effectue la récupération, si nécessaire, avant d’accepter les connexions clientes. |
| Mise à l’échelle du stockage (initiée par l’utilisateur) | Quand une mise à l’échelle de opération de stockage est lancée, les points de contrôle actifs sont autorisés à cesser d’opérer, les connexions clientes sont purgées et toutes les transactions non validées sont annulées. Ensuite, le serveur est arrêté. Le stockage est mis à l’échelle à la taille souhaitée, puis attaché au nouveau serveur. Une récupération est effectuée si nécessaire avant d’accepter les connexions client. Notez qu’un scale-down de la taille de stockage n’est pas pris en charge. |
| Déploiement de nouveaux logiciels (initiés par Azure) | Le déploiement de nouvelles fonctionnalités ou les corrections de bogues se produisent automatiquement dans le cadre de la maintenance planifiée du service, et vous pouvez planifier le moment auquel ces activités se produisent. Pour plus d’informations, consultez votre portail. |
| Mises à niveau de version mineure (initiées par Azure) | Le service Azure Database pour PostgreSQL opère automatiquement la mise à niveau des serveurs de base de données vers la version mineure déterminée par Azure. Cela se produit dans le cadre de la maintenance planifiée du service. Le serveur de base de données est redémarré automatiquement avec la nouvelle version mineure. Pour plus d’informations, consultez la documentation. Vous pouvez également consulter votre portail. |
Lorsqu’une instance Azure Database pour PostgreSQL – Serveur flexible est configurée avec une haute disponibilité, le service commence par effectuer en premier les opérations de mise à l’échelle et de maintenance sur le serveur de secours. Pour plus d'informations, voir [Concepts – Haute disponibilité]/azure/reliability/reliability-postgresql-flexible-server.
Réduction des temps d’arrêt non planifiés
Des temps d’arrêt non planifiés peuvent se produire suite à des interruptions imprévues, telles qu’une panne matérielle sous-jacente, des problèmes de mise en réseau et des bogues logiciels. Si le serveur de base de données configuré avec une haute disponibilité tombe en panne de façon inattendue, le serveur réplica de secours est activé et les clients peuvent reprendre leurs opérations. S’il n’est pas configuré avec une haute disponibilité (HA), si la tentative de redémarrage échoue, un nouveau serveur de base de données est automatiquement approvisionné. Bien qu’il ne soit pas possible d’éviter les temps d’arrêt non planifiés, Azure Database pour PostgreSQL – Serveur flexible permet d’atténuer les temps d’arrêt en effectuant automatiquement des opérations de récupération sans nécessiter d’intervention humaine.
Bien que nous fassions continuellement tout notre possible pour fournir une haute disponibilité, il arrive que le service Azure Database pour PostgreSQL – Serveur flexible entraîne une panne qui provoque l’indisponibilité des bases de données et affecte donc votre application. Lorsque notre analyse du service détecte des problèmes qui provoquent des erreurs de connectivité généralisées, des défaillances ou des problèmes de performances, le service déclare automatiquement une panne pour vous tenir informé.
Interruption de service
En cas de panne du service Azure Database pour PostgreSQL – Serveur flexible, vous pouvez consulter d’autres informations sur la panne dans les emplacements suivants :
- Bannière du portail Azure: si votre abonnement est identifié pour être affecté, une alerte de panne d’un problème de service s’affiche dans votre portail Azure Notifications.
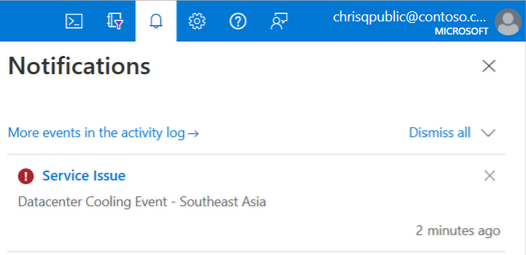
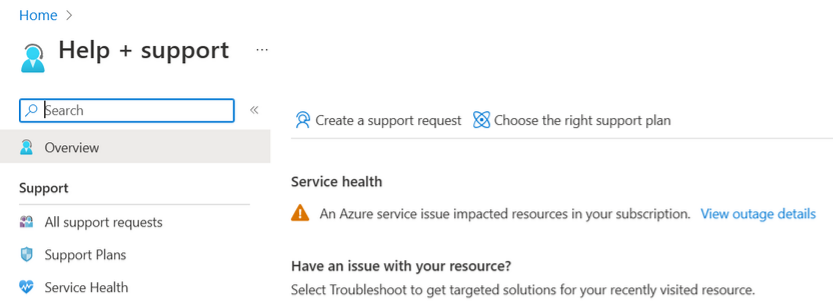
- Aide + support ou Support + résolution des problèmes: lorsque vous créez un ticket de support à partir de Aide + support ou Support + résolution des problèmes, des informations sur les problèmes qui affectent vos ressources sont disponibles. Sélectionnez Afficher les détails sur la panne pour plus d’informations et un résumé de l’impact. Il y aura également une alerte dans la page Nouvelle demande de support.
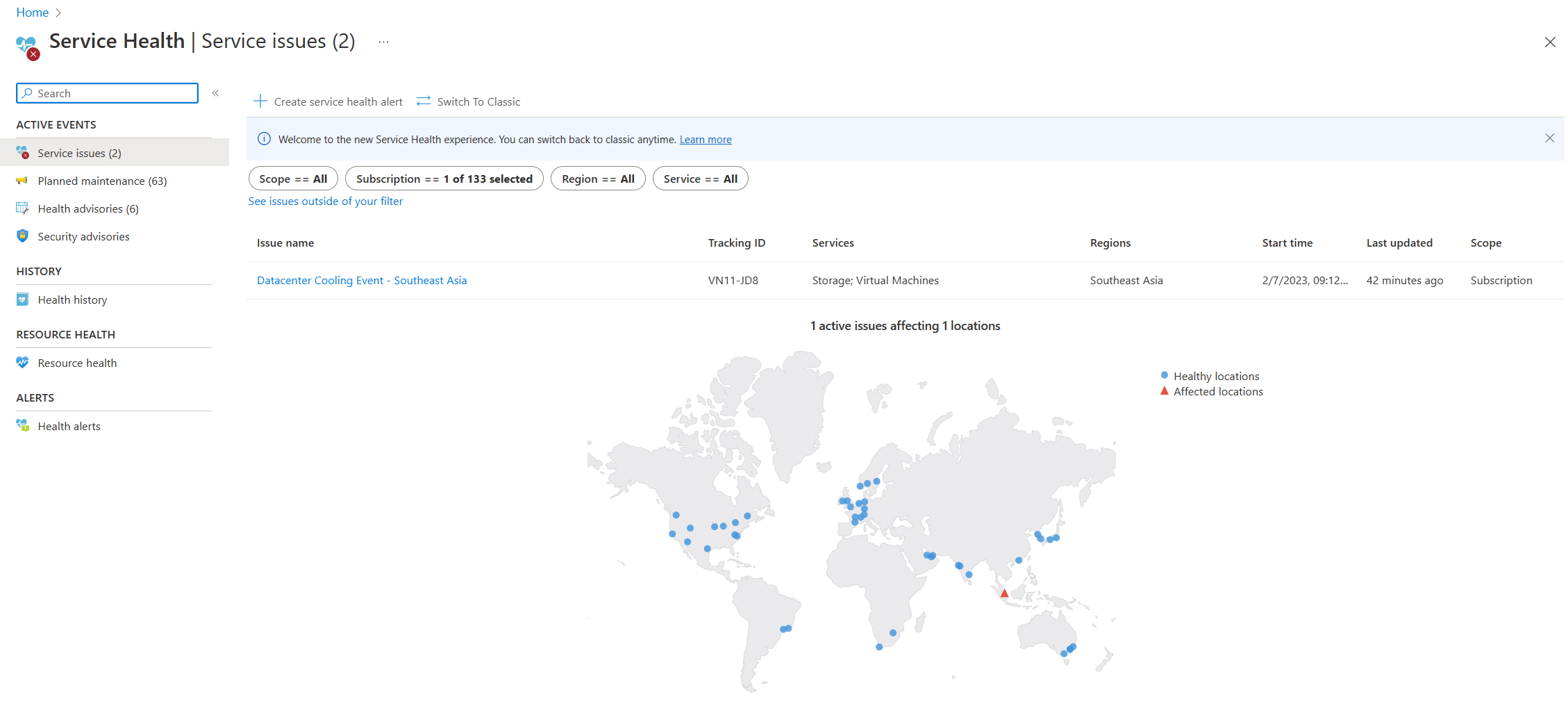
- Aide du service: la page Service Health du portail Azure contient des informations sur l’état du centre de données Azure dans le monde entier. Recherchez « Intégrité du service » dans la barre de recherche du Portail Azure, puis affichez Problèmes de service dans la catégorie Événements actifs. Vous pouvez également afficher l’intégrité des ressources individuelles dans la page Intégrité des ressources de n’importe quelle ressource sous le menu Aide. Voici un exemple de capture d’écran de la page Service Health , avec des informations sur un problème de service actif en Asie Sud-Est.
- Notification par e-mail: si vous avez configuré des alertes, une notification par e-mail arrive lorsqu’une panne de service impacte votre abonnement et votre ressource. Les e-mails arrivent de «azure-noreply@microsoft.com ». Le corps de l’e-mail commence par « L’alerte du journal d’activité ... a été déclenchée par un problème de service pour l’abonnement Azure... ». Pour plus d’informations sur les alertes d’intégrité du service, consultez Recevoir des alertes de journal d’activité sur les notifications de service Azure à l’aide du Portail Azure.
Important
Comme son nom l’indique, les espaces de table temporaires dans PostgreSQL sont utilisés pour les objets temporaires, tout comme pour d’autres opérations de base de données internes, telles que le tri. Par conséquent, nous vous déconseillons de créer des objets de schéma utilisateur dans un espace de table temporaire, car nous ne garantissons pas la durabilité de ces objets après des redémarrages du serveur, les basculements à haute disponibilité, etc.
Temps d’arrêt non planifié : scénarios d’échec et récupération du service
Voici quelques scénarios d’échec non planifiés et le processus de récupération.
| Scénario | Processus de récupération [Serveurs configurés sans haute disponibilité redondante dans une zone] |
Processus de récupération [Serveurs configurés avec une haute disponibilité redondante dans une zone] |
|---|---|---|
| Panne du serveur de base de données | Si le serveur de base de données est à l’arrêt, Azure tente de le redémarrer. En cas d’échec, le serveur de base de données est redémarré sur un autre nœud physique. Le temps de récupération dépend de différents facteurs, notamment l’activité au moment de l’erreur, comme la transaction volumineuse et le volume de récupération à effectuer pendant le processus de démarrage du serveur de base de données. Des applications utilisant les bases de données PostgreSQL doivent être créées de manière à détecter et à retenter les connexions abandonnées et les transactions ayant échoué. |
Si la défaillance du serveur de base de données est détectée, le serveur est basculé sur le serveur de secours, ce qui réduit le temps d’arrêt. Pour plus d'informations, voir [HA concepts page]/azure/reliability/reliability-postgresql-flexible-server. Le RTO devrait être compris entre 60 et 120 secondes, sans perte de données. |
| Échec de stockage | Les applications ne détectent aucun impact des problèmes liés au stockage, tels qu’une défaillance de disque ou une corruption de bloc physique. Les données étant stockées dans trois copies, leur copie est servie par le stockage survivant. Le bloc de données endommagé est réparé automatiquement, et une nouvelle copie des données est automatiquement créée. | Pour toute erreur rare et non récupérable, telle que l’inaccessibilité du stockage entier, Azure Database pour PostgreSQL – Serveur flexible est basculé vers le réplica de secours pour réduire le temps d’arrêt. Pour plus d'informations, voir [HA concepts page]/azure/reliability/reliability-postgresql-flexible-server. |
| Erreurs logiques/de l’utilisateur | Pour récupérer d’erreurs d’utilisateur, telles que des tables supprimées accidentellement ou des données incorrectement mises à jour, vous devez effectuer une Récupération jusqu’à une date et heure (PITR). Lors de l’exécution de l’opération de restauration, vous spécifiez le point de restauration personnalisé, qui est l’heure juste avant la survenance de l’erreur. Si vous ne souhaitez restaurer qu’un sous-ensemble de bases de données ou de tables spécifiques plutôt que toutes les bases de données du serveur de base de données, vous pouvez restaurer celui-ci dans une nouvelle instance, exporter les tables via l’utilitaire pg_dump, puis vous servir de l’utilitaire pg_restore pour restaurer ces tables dans votre base de données. |
Ces erreurs utilisateur ne sont pas protégées avec une haute disponibilité, car toutes les modifications sont répliquées de façon synchrone sur le serveur réplica de secours. Pour récupérer de telles erreurs, vous devez effectuer une récupération jusqu`à une date et heure. |
| Défaillance de zone de disponibilité | Pour récupérer d’une défaillance au niveau d’une zone, vous pouvez effectuer une restauration à un instant dans le passé à l’aide de la sauvegarde, en choisissant un point de restauration personnalisé avec la dernière heure pour restaurer les données les plus récentes. Une nouvelle instance Azure Database pour PostgreSQL – Serveur flexible est déployée dans une autre zone non affectée. Le temps que prend la restauration dépend de la sauvegarde précédente et du volume des journaux des transactions à récupérer. | Azure Database pour PostgreSQL – Serveur flexible est automatiquement basculé vers le serveur de secours dans un délai de 60 à 120 secondes sans aucune perte de données. Pour plus d'informations, voir [HA concepts page]/azure/reliability/reliability-postgresql-flexible-server. |
| Panne de région | Si votre serveur est configuré avec une sauvegarde géo-redondante, vous pouvez effectuer la géo-restauration dans la région appairée. Un nouveau serveur est approvisionné et récupéré jusqu’aux dernières données disponibles copiées dans cette région. Vous pouvez également utiliser des réplicas en lecture entre régions. En cas de défaillance de la région, vous pouvez effectuer une opération de récupération d’urgence en faisant de votre réplica en lecture un serveur en lecture-écriture autonome. Le RPO devrait être jusqu’à 5 minutes (perte de données possible), sauf en cas de défaillance régionale grave lorsque le RPO peut être proche du retard de réplication au moment de la défaillance. |
Même processus. |
Configurer votre base de données après une récupération suite à une défaillance régionale
- Si vous utilisez la géo-restauration ou la géo-réplica pour récupérer après une panne, vous devez vous assurer que la connectivité à la nouvelle base de données est correctement configurée pour permettre à l’application de reprendre un fonctionnement normal. Vous pouvez suivre les tâches post-restauration.
- Si vous avez déjà configuré un paramètre de diagnostic sur le serveur d’origine, veillez à faire de même sur le serveur cible si nécessaire, comme expliqué dans Configurer et accéder aux journaux d’activité dans Azure Database pour PostgreSQL - Serveur flexible.
- Pour configurer des alertes de télémétrie, vous devez vous assurer que vos paramètres de règles d’alerte existants sont mis à jour de manière à mapper vers le nouveau serveur. Pour plus d’informations sur les règles d’alerte, consultez Utiliser le Portail Azure pour configurer des alertes sur des indicateurs de performance pour Azure Database pour PostgreSQL - Serveur flexible.
Important
Il est possible de restaurer des serveurs supprimés. Si vous supprimez le serveur, vous pouvez suivre nos conseils dans Restaurer une base de données Azure supprimée – Azure Database pour PostgreSQL – Serveur flexible afin de le récupérer. Utilisez le verrouillage des ressources Azure pour éviter la suppression accidentelle de votre serveur.