Démarrage rapide : Bien démarrer avec Azure Machine Learning
S’APPLIQUE À :  Kit de développement logiciel (SDK) Python azure-ai-ml v2 (actuelle)
Kit de développement logiciel (SDK) Python azure-ai-ml v2 (actuelle)
Ce tutoriel est une introduction à plusieurs fonctionnalités les plus courantes du service Azure Machine Learning. Il va vous permettre de créer, d’inscrire et de déployer un modèle. Ce tutoriel va vous aider à vous familiariser avec les concepts fondamentaux d’Azure Machine Learning et leur utilisation la plus courante.
Vous allez apprendre à exécuter un travail d’entraînement sur une ressource de calcul évolutive, à le déployer, puis à tester le déploiement.
Vous allez créer un script d’entraînement pour gérer la préparation des données, l’entraînement et l’inscription d’un modèle. Dès que vous aurez entraîné le modèle, vous le déploierez en tant que point de terminaison, puis vous appellerez le point de terminaison pour inférence.
Voici les étapes à suivre :
- Configurer un descripteur vers votre espace de travail Azure Machine Learning
- Créer votre script d’entraînement
- Créer une ressource de calcul évolutive, un cluster de calcul
- Créer et exécuter un travail de commande pour exécuter le script de formation sur la ressource de calcul, configuré avec l’environnement de travail approprié
- Afficher la sortie de votre script d’entraînement
- Déployer le modèle nouvellement entraîné en tant que point de terminaison.
- Appeler le point de terminaison Azure Machine Learning pour l’inférence
Regardez cette vidéo pour avoir une vue d’ensemble des étapes de ce guide de démarrage rapide.
Prérequis
-
Vous avez besoin d’un espace de travail pour utiliser Azure Machine Learning. Si vous n’en avez pas, suivez la procédure Créer les ressources nécessaires pour commencer pour créer un espace de travail et en savoir plus sur son utilisation.
Important
Si votre espace de travail Azure Machine Learning est configuré avec un réseau virtuel managé, vous devrez peut-être ajouter des règles de trafic sortant pour autoriser l’accès aux référentiels publics de packages Python. Pour plus d’informations, consulter Scénario : accéder aux packages Machine Learning publics.
-
Connectez-vous au studio et sélectionnez votre espace de travail s’il n’est pas déjà ouvert.
-
Ouvrez ou créez un notebook dans votre espace de travail :
- Si vous souhaitez copier et coller du code dans les cellules, créez un notebook.
- Ou ouvrez tutorials/get-started-notebooks/pipeline.ipynb à partir de la section Exemples de Studio. Sélectionnez ensuite Cloner pour ajouter le notebook à vos fichiers. Pour trouver des exemples de notebooks, consultez Apprendre à partir d’exemples de notebooks.
Définir votre noyau et ouvrir dans Visual Studio Code (VS Code)
Dans la barre supérieure au-dessus de votre notebook ouvert, créez une instance de calcul si vous n’en avez pas déjà une.

Si l’instance de calcul est arrêtée, sélectionnez Démarrer le calcul et attendez qu’elle s’exécute.

Attendez que l’instance de calcul soit en cours d’exécution. Vérifiez ensuite que le noyau, situé en haut à droite, est
Python 3.10 - SDK v2. Si ce n’est pas le cas, utilisez la liste déroulante pour sélectionner ce noyau.
Si vous ne voyez pas ce noyau, vérifiez que votre instance de calcul est en cours d’exécution. S’il est présent, sélectionnez le bouton Actualiser en haut à droite du notebook.
Si une bannière vous indique que vous devez être authentifié, sélectionnez Authentifier.
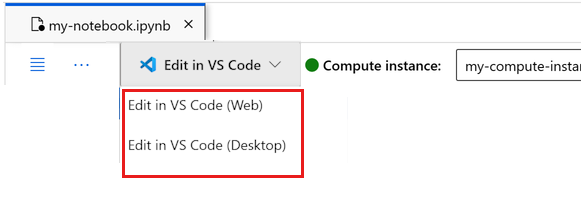
Vous pouvez exécuter le notebook ici, ou l’ouvrir dans VS Code pour un environnement de développement intégré (IDE) complet avec la puissance des ressources Azure Machine Learning. Sélectionnez Ouvrir dans VS Code, puis l’option web ou de bureau. Lors d’un tel lancement, VS Code est attaché à votre instance de calcul, au noyau et au système de fichiers de l’espace de travail.




Important
Le reste de ce tutoriel contient des cellules du notebook du tutoriel. Copiez-le, et collez-le dans votre nouveau notebook, ou accédez maintenant au notebook si vous l’avez cloné.
Créer un descripteur vers l’espace de travail
Avant de se lancer dans la rédaction du code, il faut trouver un moyen de référencer l’espace de travail. L’espace de travail est la ressource de niveau supérieur pour Azure Machine Learning. Il fournit un emplacement centralisé dans lequel exploiter tous les artefacts que vous créez lorsque vous utilisez Azure Machine Learning.
Vous allez créer ml_client pour un descripteur pour l’espace de travail. Vous utilisez ensuite ml_client pour gérer les ressources et les travaux.
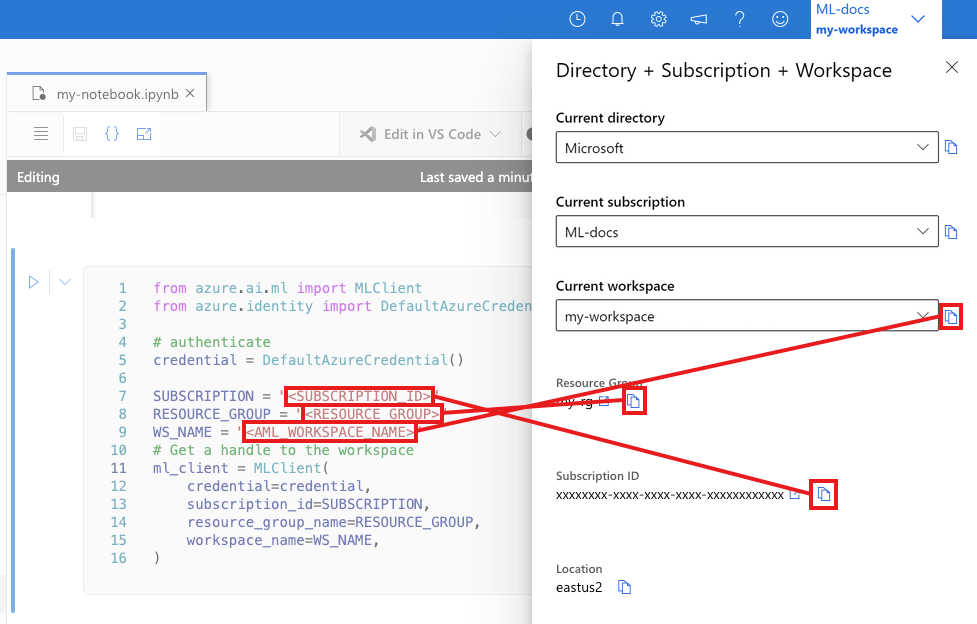
Dans la cellule suivante, entrez votre ID d’abonnement, le nom du groupe de ressources et le nom de l’espace de travail. Pour rechercher ces valeurs :
- Dans la barre d’outils supérieure droite d’Azure Machine Learning Studio, sélectionnez le nom de votre espace de travail.
- Copiez la valeur de l’espace de travail, du groupe de ressources et de l’ID d’abonnement dans le code.
- Vous devez copier une valeur, fermer la zone et coller, puis revenir pour la suivante.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Notes
La création de MLClient n’établit pas de connexion à l’espace de travail. L’initialisation du client est lente, elle attendra la première fois qu’elle aura besoin de passer un appel (ce qui se produira dans la prochaine cellule de code).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Créer un script d’entraînement
Commençons par créer le script d’entraînement : le fichier Python main.py.
Tout d’abord, créez un dossier source pour le script :
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Ce script gère le prétraitement des données, le fractionnant en données de test et d’apprentissage. Il consomme ensuite ces données pour entraîner un modèle basé sur une arborescence et retourner le modèle de sortie.
MLFlow est utilisé pour consigner les paramètres et les métriques pendant l’exécution de notre pipeline.
La cellule ci-dessous utilise IPython magic pour écrire le script d’entraînement dans le répertoire que vous venez de créer.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
# pin numpy
conda_env = {
'name': 'mlflow-env',
'channels': ['conda-forge'],
'dependencies': [
'python=3.10.15',
'pip<=21.3.1',
{
'pip': [
'mlflow==2.17.0',
'cloudpickle==2.2.1',
'pandas==1.5.3',
'psutil==5.8.0',
'scikit-learn==1.5.2',
'numpy==1.26.4',
]
}
],
}
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
conda_env=conda_env,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Comme vous pouvez le voir dans ce script, une fois le modèle entraîné, le fichier de modèle est enregistré et inscrit auprès de l’espace de travail. Vous pouvez maintenant utiliser le modèle inscrit dans les points de terminaison d’inférence.
Vous devrez peut-être sélectionner Actualiser pour afficher le nouveau dossier et le nouveau script dans vos fichiers.
Configurer la commande
Maintenant que vous disposez d’un script qui peut effectuer les tâches souhaitées et d’un cluster de calcul qui permet d’exécuter le script, vous allez utiliser une commande à usage général qui peut exécuter des actions de ligne de commande. Cette action de ligne de commande peut appeler directement des commandes système ou exécuter un script.
Ici, vous allez créer des variables d’entrée pour spécifier les données d’entrée, le ratio de fractionnement, le taux d’apprentissage et le nom du modèle inscrit. Le script de commande effectue les actions suivantes :
- Utiliser un environnement qui définit les bibliothèques de logiciels et de runtime nécessaires pour le script de formation. Azure Machine Learning fournit de nombreux environnements organisés ou prêts à l’utilisation, qui sont utiles pour les scénarios courants d’apprentissage et d’inférence. Vous allez utiliser l’un de ces environnements ici. Dans Tutoriel : Entraîner un modèle dans Azure Machine Learning, vous apprenez à créer un environnement personnalisé.
- Configurez l’action de ligne de commande elle-même.
python main.py, dans ce cas. Les entrées/sorties sont accessibles sur la commande au moyen de la notation${{ ... }}. - Dans cet exemple, nous accédons aux données à partir d’un fichier sur Internet.
- Étant donné qu’aucune ressource de calcul n’a été spécifiée, le script est exécuté sur un cluster de calcul serverless qui est automatiquement créé.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="azureml://registries/azureml/environments/sklearn-1.5/labels/latest",
display_name="credit_default_prediction",
)
Envoi du travail
Il est maintenant temps de soumettre le travail à exécuter dans Azure Machine Learning. Cette fois, vous utilisez create_or_update sur ml_client.
ml_client.create_or_update(job)
Afficher la sortie du travail et attendre l’achèvement du travail
Affichez le travail dans Azure Machine Learning Studio en sélectionnant le lien dans la sortie de la cellule précédente.
La sortie de ce travail ressemble à ceci dans Azure Machine Learning studio. Explorez les onglets pour voir différents détails tels que les métriques, les sorties, etc. Une fois terminé, le travail inscrit un modèle dans votre espace de travail suite à l’entraînement.
Important
Attendez que l’état du travail soit terminé avant de revenir à ce notebook pour continuer. Le travail prend 2 à 3 minutes. Cela peut prendre plus de temps (jusqu’à 10 minutes) si le cluster de calcul a été mis à l’échelle jusqu’à zéro nœuds et que l’environnement personnalisé est toujours généré.
Déployer le modèle en tant que point de terminaison en ligne
Déployez maintenant votre modèle Machine Learning en tant que service web dans le cloud Azure, un online endpoint.
Pour déployer un service Machine Learning, vous utilisez le modèle que vous avez inscrit.
Créer un point de terminaison en ligne
Maintenant que vous avez un modèle inscrit, le moment est venu de créer votre point de terminaison en ligne. Le nom du point de terminaison doit être unique dans toute la région Azure. Pour les besoins de ce tutoriel, vous créez un nom unique à l’aide de UUID.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Créez le point de terminaison :
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Notes
Attendez-vous à ce que la création du point de terminaison prenne quelques minutes.
Une fois le point de terminaison créé, vous pouvez le récupérer comme suit :
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Déployer le modèle sur le point de terminaison
Une fois le point de terminaison créé, déployez le modèle avec le script d’entrée. Chaque point de terminaison peut avoir plusieurs déploiements. Le trafic direct vers ces déploiements peut être spécifié à l’aide des règles. Ici, vous créez un déploiement unique qui gère 100 % du trafic entrant. Nous avons choisi un nom de couleur pour le déploiement, par exemple bleu, vert, rouge, qui est arbitraire.
Vous pouvez consulter la page Modèles dans Azure Machine Learning Studio pour identifier la dernière version de votre modèle inscrit. En guise d’alternative, le code ci-dessous récupère le numéro de la version la plus récente à utiliser.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
Déployez la dernière version du modèle.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Notes
Attendez-vous à ce que ce déploiement prenne environ six à huit minutes.
Une fois le déploiement terminé, vous êtes prêt à le tester.
Tester avec un exemple de requête
Une fois le modèle déployé sur le point de terminaison, vous pouvez exécuter l’inférence avec celui-ci.
Créez un exemple de fichier de requête suivant la conception attendue dans la méthode d’exécution dans le script de score.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
Nettoyer les ressources
Si vous ne souhaitez pas utiliser le point de terminaison, supprimez-le pour cesser d’utiliser la ressource. Vérifiez qu’aucun autre déploiement n’utilise un point de terminaison avant de le supprimer.
Notes
Attendez-vous à ce que la suppression complète prenne environ 20 minutes.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Arrêter l’instance de calcul
Si vous ne comptez pas l’utiliser maintenant, arrêtez l’instance de calcul :
- Dans la zone de navigation gauche de Studio, sélectionnez Calculer.
- Sous les onglets supérieurs, sélectionnez Instances de calcul
- Sélectionnez l’instance de calcul dans la liste.
- Dans la barre d’outils supérieure, sélectionnez Arrêter.
Supprimer toutes les ressources
Important
Les ressources que vous avez créées peuvent être utilisées comme prérequis pour d’autres tutoriels d’Azure Machine Learning et des articles de procédure.
Si vous n’avez pas l’intention d’utiliser les ressources que vous avez créées, supprimez-les pour éviter des frais :
Dans la zone de recherche du Portail Azure, saisissez Groupes de ressources, puis sélectionnez-le dans les résultats.
Dans la liste, sélectionnez le groupe de ressources créé.
Dans la page Vue d’ensemble, sélectionnez Supprimer le groupe de ressources.
Entrez le nom du groupe de ressources. Puis sélectionnez Supprimer.
Étapes suivantes
Maintenant que vous avez une idée des éléments impliqués dans l’apprentissage et le déploiement d’un modèle, apprenez-en davantage sur le processus dans les tutoriels ci-dessous :
| Didacticiel | Description |
|---|---|
| Charger, accéder et explorer vos données dans Azure Machine Learning | Stocker des données volumineuses dans le cloud et les récupérer à partir de notebooks et de scripts |
| Développement de modèles sur une station de travail cloud | Démarrer le prototypage et le développement de modèles Machine Learning |
| Effectuer l’apprentissage d’un modèle dans Azure Machine Learning | Plongez dans les détails de la formation d’un modèle |
| Déployer un modèle en tant que point de terminaison en ligne | Plongez dans les détails du déploiement d’un modèle |
| Créer des pipelines Machine Learning de production | Fractionnez une tâche Machine Learning complète en un flux de travail en plusieurs étapes. |