Flux d’évaluation et métriques
Les flux d’évaluation sont un type spécial de flux d’invite qui calcule les métriques pour évaluer la façon dont les sorties d’une exécution répondent à des critères et objectifs spécifiques. Vous pouvez créer ou personnaliser des flux d’évaluation et des métriques adaptés à vos tâches et objectifs, et les utiliser pour évaluer d’autres flux d’invite. Cet article explique les flux d’évaluation, comment les développer et les personnaliser, et comment les utiliser dans les exécutions par lot de flux d’invite pour évaluer les performances du flux.
Comprendre les flux d’évaluation
Un flux d’invite est une séquence de nœuds qui traitent l’entrée et génèrent la sortie. Les flux d’évaluation consomment également les entrées requises et produisent des sorties correspondantes qui sont généralement des scores ou des métriques. Les flux d’évaluation diffèrent des flux standard dans leur expérience de création et leur utilisation.
Les flux d’évaluation s’exécutent généralement après l’exécution qu’ils testent en recevant ses sorties et en utilisant les sorties pour calculer les scores et les métriques. Les métriques de journalisation des flux d’évaluation utilisent la fonction log_metric() du kit de développement logiciel (SDK) de flux d’invite.
Les sorties du flux d’évaluation sont les résultats qui mesurent les performances du flux testé. Les flux d’évaluation peuvent avoir un nœud d’agrégation qui calcule les performances globales du flux testé sur le jeu de données de test.
Les sections suivantes décrivent comment définir des entrées et des sorties dans des flux d’évaluation.
Entrées
Les flux d’évaluation calculent les métriques ou les scores des exécutions par lot en prenant les sorties de l’exécution qu’ils testent. Par exemple, si le flux testé est un flux QnA qui génère une réponse basée sur une question, vous pouvez nommer une entrée d’évaluation answer. Si le flux testé est un flux de classification qui classifie un texte dans une catégorie, vous pouvez nommer une entrée d’évaluation category.
Vous aurez peut-être besoin d’autres entrées comme fondement de vérité. Par exemple, si vous souhaitez calculer l’exactitude d’un flux de classification, vous devez fournir la colonne category dans le jeu de données comme fondement de vérité. Si vous souhaitez calculer l’exactitude d’un flux QnA, vous devez fournir la colonne answer du jeu de données comme fondement de vérité. Vous aurez peut-être besoin d’autres entrées pour calculer des métriques, telles que question et context dans les scénarios de QnA ou de récupération de génération augmentée (RAG).
Vous définissez les entrées du flux d’évaluation de la même façon que des entrées d’un flux standard. Par défaut, l’évaluation utilise le même jeu de données que l’exécution testée. Toutefois, si les étiquettes correspondantes ou les valeurs de fondement de vérité cibles se trouvent dans un jeu de données différent, vous pouvez facilement basculer vers ce jeu de données.
Descriptions d’entrée
Pour décrire les entrées nécessaires au calcul des métriques, vous pouvez ajouter des descriptions. Les descriptions s’affichent lorsque vous mappez les sources d’entrée dans les soumissions d’exécution par lot.
Pour ajouter des descriptions pour chaque entrée, sélectionnez Afficher la description dans la section Entrée lors du développement de votre méthode d’évaluation, puis entrez les descriptions.

Pour masquer les descriptions du formulaire d’entrée, sélectionnez Masquer la description.

Sorties et métriques
Les sorties d’une évaluation sont les résultats qui témoignent des performances du flux testé. La sortie contient généralement des métriques telles que des scores et peut également inclure du texte pour la réflexion et les suggestions.
Scores de sortie
Un flux d’invite traite une ligne de données à la fois et génère un enregistrement de sortie. Les flux d’évaluation peuvent également calculer des scores pour chaque ligne de données. Vous pouvez donc vérifier comment un flux s’exécute sur chaque point de données individuel.
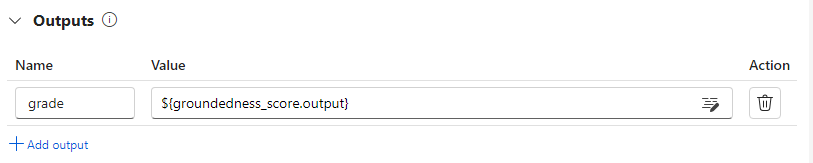
Vous pouvez enregistrer les scores de chaque instance de données en tant que sorties de flux d’évaluation en les spécifiant dans la section sortie du flux d’évaluation. L’expérience de création est identique à la définition d’une sortie de flux standard.
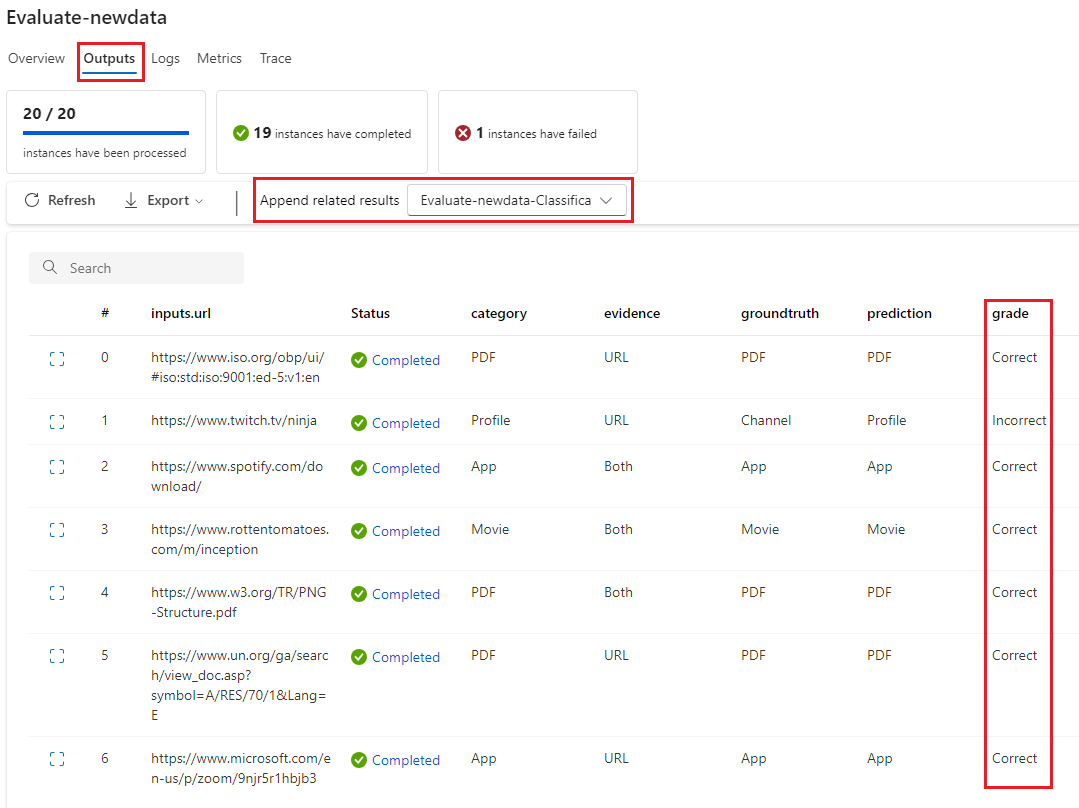
Vous pouvez afficher les scores individuels sous l’onglet Sorties lorsque vous sélectionnez Afficher les sorties, de la même manière que vous vérifiez ceux d’une exécution par lot de flux standard. Vous pouvez ajouter ces scores au niveau de l’instance à la sortie du flux que vous avez testé.
Journalisation des agrégations et des métriques
Le flux d’évaluation fournit également une évaluation globale de l’exécution. Pour distinguer les résultats globaux des scores de sortie individuels, ces valeurs globales de performances d’exécution sont appelées des métriques.
Pour calculer une valeur d’évaluation globale basée sur des scores individuels, cochez la case Agrégation sur un nœud Python dans un flux d’évaluation pour le transformer en un nœud reduce. Le nœud prend ensuite les entrées sous la forme d’une liste et les traite en tant que lot.

Grâce à cette agrégation, vous pouvez calculer et traiter tous les scores de chaque sortie de flux et calculer un résultat global à l’aide de chaque score. Par exemple, pour calculer l’exactitude d’un flux de classification, vous pouvez calculer l’exactitude de chaque sortie de score, puis calculer l’exactitude moyenne de toutes les sorties de score. Ensuite, vous pouvez consigner la précision moyenne en tant que métrique à l’aide de promptflow_sdk.log_metric(). Les métriques doivent être numériques, telles que float ou int. La journalisation des métriques de type chaîne n’est pas prise en charge.
L’extrait de code suivant est un exemple de calcul d’exactitude globale élaboré avec la moyenne du score d’exactitude (grades) de tous les points de données. La précision globale est enregistrée sous la forme d’une métrique à l’aide de promptflow_sdk.log_metric().
from typing import List
from promptflow import tool, log_metric
@tool
def calculate_accuracy(grades: List[str]): # Receive a list of grades from a previous node
# calculate accuracy
accuracy = round((grades.count("Correct") / len(grades)), 2)
log_metric("accuracy", accuracy)
return accuracy
Puisque vous appelez cette fonction dans le nœud Python, vous n’avez pas besoin de l’affecter ailleurs, et vous pouvez afficher les métriques ultérieurement. Après avoir utilisé cette méthode d’évaluation dans une exécution par lot, vous pouvez afficher la métrique présentant les performances globales en sélectionnant l’onglet Métriques lorsque vous observez les sorties.

Développer un flux d’évaluation
Pour développer votre propre flux d’évaluation, sélectionnez Créer sur la page Flux d’invite Azure Machine Learning studio. Dans la page Créer un flux, vous pouvez :
Sélectionner Créer dans la carte Flux d’évaluation sous Créer par type. Cette sélection fournit un modèle pour développer une nouvelle méthode d’évaluation.
Sélectionner Flux d’évaluation dans Explorer la galerie, puis sélectionnez l’un des flux intégrés disponibles. Sélectionner Afficher les détails pour obtenir un résumé de chaque flux, puis sélectionnez Cloner pour ouvrir et personnaliser le flux. L’Assistant Création de flux vous aide à modifier le flux pour votre propre scénario.

Calculer les scores pour chaque point de données
Les flux d’évaluation calculent les scores et les métriques des flux qui s’exécutent sur des jeux de données. La première étape des flux d’évaluation consiste à calculer les scores pour chaque sortie de données individuelle.
Par exemple, dans le flux intégré d’évaluation de la précision de classification, le grade qui mesure la précision de chaque sortie générée par flux pour son fondement de vérité correspondant est calculée dans le nœud grade Python.
Si vous utilisez le modèle de flux d’évaluation, vous calculez ce score dans le nœud line_process Python. Vous pouvez également remplacer le nœud Python line_process par un nœud de grand modèle de langage (LLM) pour utiliser un LLM pour calculer le score, ou utiliser plusieurs nœuds pour effectuer le calcul.

Vous spécifiez les sorties de ce nœud comme sorties du flux d’évaluation, ce qui indique que les sorties sont les scores calculés pour chaque échantillon de données. Vous pouvez également générer un raisonnement en tant qu’informations supplémentaires, de manière similaire à l’expérience de définition des sorties dans un flux standard.
Calculer et consigner les métriques
L’étape suivante de l’évaluation consiste à calculer les métriques globales pour évaluer l’exécution. Vous calculez les métriques dans un nœud Python avec l’option Agrégation sélectionnée. Ce nœud prend les scores du nœud de calcul précédent et les organise en liste, puis calcule les valeurs globales.
Si vous utilisez le modèle d’évaluation, ce score est calculé dans le nœud aggregate. L’extrait de code suivant montre le modèle pour le nœud d’agrégation.
from typing import List
from promptflow import tool
@tool
def aggregate(processed_results: List[str]):
"""
This tool aggregates the processed result of all lines and log metric.
:param processed_results: List of the output of line_process node.
"""
# Add your aggregation logic here
aggregated_results = {}
# Log metric
# from promptflow import log_metric
# log_metric(key="<my-metric-name>", value=aggregated_results["<my-metric-name>"])
return aggregated_results
Vous pouvez utiliser votre propre logique d’agrégation, telle que le calcul de la moyenne du score, de la médiane ou de l’écart type.
Consignez les métriques à l’aide de la fonction promptflow.log_metric(). Vous pouvez consigner plusieurs métriques dans un seul flux d’évaluation. Les métriques doivent être numériques (float/int).
Utiliser des flux d’évaluation
Après avoir créé votre propre flux d’évaluation et vos métriques, vous pouvez utiliser le flux pour évaluer les performances d’un flux standard. Par exemple, vous pouvez évaluer un flux QnA pour tester son fonctionnement sur un jeu de données volumineux.
Dans Azure Machine Learning studio, ouvrez le flux que vous souhaitez évaluer, puis sélectionnez Évaluer dans la barre de menus supérieure.

Dans l’Assistant Exécuter par lot et évaluer, renseignez les paramètres de base et les paramètres d’exécution par lot pour charger le jeu de données à des fins de test et configurer le mappage d’entrée. Pour plus d’informations, consultez Envoyer une exécution par lot et évaluer un flux.
Dans l’étape Sélectionner l’évaluation, vous pouvez sélectionner une ou plusieurs de vos évaluations personnalisées ou évaluations intégrées à exécuter. Évaluation personnalisée répertorie tous les flux d’évaluation que vous avez créés, clonés ou personnalisés. Les flux d’évaluation créés par d’autres personnes travaillant sur le même projet n’apparaissent pas dans cette section.

Sur l’écran Configurer l’évaluation, spécifiez les sources des données d’entrée nécessaires à la méthode d’évaluation. Par exemple, la colonne de fondement de vérité est susceptible de provenir d’un jeu de données. Si votre méthode d’évaluation ne nécessite pas de données à partir d’un jeu de données, vous n’avez pas besoin de sélectionner un jeu de données ou de référencer des colonnes de jeu de données dans la section de mappage d’entrée.
Dans la section Mappage d’entrée de l’évaluation, vous pouvez indiquer les sources d’entrées requises pour l’évaluation. Si les données source proviennent de votre sortie d’exécution, définissez la source sur
${run.outputs.[OutputName]}. Si les données proviennent de votre jeu de données de test, définissez la source sur${data.[ColumnName]}. Toutes les descriptions que vous définissez pour les entrées de données s’affichent également ici. Pour plus d’informations, consultez Envoyer une exécution par lot et évaluer un flux.
Important
Si votre flux d’évaluation a un nœud LLM ou nécessite une connexion pour consommer des informations d’identification ou d’autres clés, vous devez entrer les données de connexion dans la section Connexion de cet écran pour pouvoir utiliser le flux d’évaluation.
Sélectionnez Vérifier + envoyer, puis Envoyer pour exécuter le flux d’évaluation.
Une fois le flux d’évaluation terminé, vous pouvez voir les scores au niveau de l’instance en sélectionnant Afficher les exécutions par lot>Afficher les dernières sorties d’exécution par lot en haut du flux que vous avez évalué. Sélectionnez votre exécution d’évaluation dans la liste déroulante Ajouter des résultats liés pour afficher la note de chaque ligne de données.