Exécuter des points de terminaison de traitement par lots à partir d’Azure Data Factory
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Les Big Data nécessitent un service pouvant orchestrer et opérationnaliser les processus qui permettent d’affiner les données brutes de ces gigantesques magasins pour les transformer en insights métier exploitables. Le service cloud managé Azure Data Factory gère ces projets hybrides complexes d’extraction, transformation et chargement (ETL), d’extraction, chargement et transformation (ELT), et d’intégration des données.
Azure Data Factory vous permet de créer des pipelines qui peuvent orchestrer plusieurs transformations de données et de les gérer en tant qu’unité unique. Les points de terminaison par lots sont un excellent candidat pour devenir une étape dans un tel flux de travail de traitement.
Dans cet article, découvrez comment utiliser des points de terminaison par lots dans des activités Azure Data Factory en vous appuyant sur l’activité Appel Web et l’API REST.
Conseil
Lorsque vous utilisez des pipelines de données dans Fabric, vous pouvez appeler un point de terminaison par lots directement à l’aide de l’activité Azure Machine Learning. Nous vous recommandons d’utiliser Fabric pour l’orchestration des données chaque fois que possible pour tirer parti des fonctionnalités les plus récentes. L’activité Azure Machine Learning dans Azure Data Factory ne peut fonctionner qu’avec des ressources d’Azure Machine Learning V1. Pour plus d’informations, consultez Exécuter des modèles Azure Machine Learning à partir de Fabric en utilisant des points de terminaison par lots (préversion).
Prérequis
Modèle déployé en tant que point de terminaison par lots. Utilisez le classifieur de la condition cardiaque créé dans Utilisation de modèles MLflow dans les déploiements par lots.
Une ressource Azure Data Factory. Pour créer une fabrique de données, suivez les étapes de Démarrage rapide : créer une fabrique de données à l’aide du Portail Azure.
Après avoir créé votre fabrique de données, accédez-y dans le Portail Azure et sélectionnez Lancement du studio :


Authentification sur les points de terminaison du traitement par lots
Azure Data Factory peut appeler les API REST des points de terminaison par lots à l’aide de l’activité Appel web. Les points de terminaison par lots prennent en charge Microsoft Entra ID pour l’autorisation et la requête adressée aux API nécessite une gestion d’authentification appropriée. Pour plus d’informations, consultez Activité web dans Azure Data Factory et Azure Synapse Analytics.
Vous pouvez utiliser un principal de service ou une identité managée pour l’authentification auprès de points de terminaison par lots. Nous vous recommandons d’utiliser une identité managée car elle simplifie l’utilisation des secrets.
Vous pouvez utiliser une identité managée Azure Data Factory pour communiquer avec les points de terminaison par lots. Dans ce cas, vous devez uniquement vous assurer que votre ressource Azure Data Factory a été déployée avec une identité managée.
Si vous n’avez pas de ressource Azure Data Factory ou qu’elle a déjà été déployée sans identité managée, suivez cette procédure pour la créer : Identité managée affectée par le système.
Attention
Il n’est pas possible de modifier l’identité de la ressource dans Azure Data Factory après le déploiement. Si vous devez modifier l’identité d’une ressource après sa création, vous devez recréer la ressource.
Une fois le déploiement effectué, accordez à votre espace de travail Azure Machine Learning l’accès à l’identité managée de la ressource que vous avez créée. Consultez Octroyer l’accès. Dans cet exemple, le principal de service nécessite :
- Autorisation dans l’espace de travail pour lire les déploiements par lots et effectuer des actions dessus.
- Autorisations de lecture/écriture dans les magasins de données.
- Autorisations de lecture dans un emplacement cloud (compte de stockage) indiqué en tant qu’entrée de données.
À propos du pipeline
Dans cet exemple, vous créez un pipeline dans Azure Data Factory qui peut appeler un point de terminaison par lots donné sur certaines données. Le pipeline communique avec les points de terminaison par lots Azure Machine Learning à l’aide de REST. Pour plus d’informations sur l’utilisation de l’API REST des points de terminaison par lots, consultez Créer des travaux et des données d’entrée pour les points de terminaison par lots.
Le pipeline se présente comme suit :

Le pipeline contient les activités suivantes :
Exécuter Batch-Endpoint : une activité web qui utilise l’URI de point de terminaison par lots pour l’appeler. Elle transmet l’URI de données d’entrée où se trouvent les données et le fichier de sortie attendu.
Attendre la fin du travail : il s’agit d’une activité de boucle qui vérifie l’état du travail créé et attend son achèvement, avec l’état Terminé ou Ayant échoué. Cette activité, à son tour, utilise les activités suivantes :
- Vérifier l’état : une activité web qui interroge l’état de la ressource de travail retournée en tant que réponse à l’activité Exécuter Batch-Endpoint.
- Attendre : une activité d’attente qui contrôle la fréquence d’interrogation de l’état du travail. Nous définissons une valeur par défaut de 120 (2 minutes).
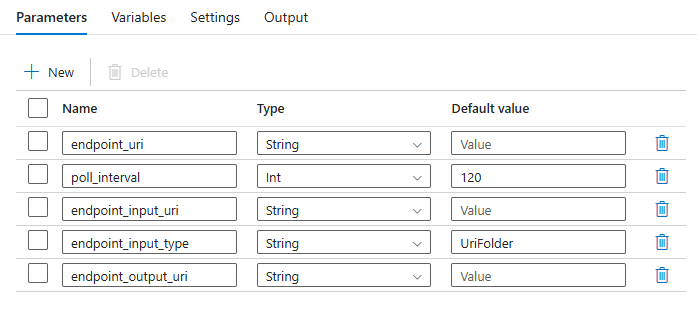
Le pipeline vous oblige à configurer les paramètres suivants :
| Paramètre | Description | Exemple de valeur |
|---|---|---|
endpoint_uri |
URI de scoring du point de terminaison | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
Nombre de secondes d’attente avant de vérifier l’état d’achèvement du travail. La valeur par défaut est 120. |
120 |
endpoint_input_uri |
Données d’entrée du point de terminaison. Plusieurs types d’entrée de données sont pris en charge. Vérifiez que l’identité managée que vous utilisez pour exécuter le travail a accès à l’emplacement sous-jacent. Ou, si vous utilisez des magasins de données, vérifiez que les informations d’identification y sont indiquées. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
Type des données d’entrée que vous fournissez. Actuellement, les points de terminaison de lot prennent en charge les dossiers (UriFolder) et fichiers (UriFile). La valeur par défaut est UriFolder. |
UriFolder |
endpoint_output_uri |
Fichier de données de sortie du point de terminaison. Il doit s’agir d’un chemin d’accès à un fichier de sortie dans un magasin de données attaché à l’espace de travail Machine Learning. Aucun autre type d’URI n’est pris en charge. Vous pouvez utiliser le magasin de données Azure Machine Learning par défaut, nommé workspaceblobstore. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |

Avertissement
N’oubliez pas que endpoint_output_uri doit être le chemin d’accès à un fichier qui n’existe pas encore. Sinon, le travail échoue avec l’erreur le chemin d’accès existe déjà.
Créer le pipeline
Pour créer ce pipeline dans votre instance Azure Data Factory existante et appeler des points de terminaison, procédez comme suit :
Vérifiez que le calcul sur lequel le point de terminaison par lots s’exécute dispose des autorisations nécessaires pour monter les données qu’Azure Data Factory fournit en tant qu’entrée. L’entité qui appelle le point de terminaison accorde toujours l’accès.
Dans ce cas, il s’agit d’Azure Data Factory. Toutefois, le calcul sur lequel le point de terminaison par lots s’exécute doit avoir l’autorisation de monter le compte de stockage fourni par votre instance Azure Data Factory. Pour plus d’informations, consultez Accès aux services de stockage.
Ouvrez Azure Data Factory Studio. Sélectionnez l’icône crayon pour ouvrir le volet Auteur et, sous Ressources de fabrique, sélectionnez le signe plus.
Sélectionnez Pipeline>Importer à partir du modèle de pipeline.
Sélectionnez un fichier .zip.
- Pour utiliser des identités managées, sélectionnez ce fichier.
- Pour utiliser un principe de service, sélectionnez ce fichier.
Un aperçu du pipeline s’affiche dans le portail. Cliquez sur Utiliser ce modèle.
Le pipeline est créé pour vous avec le nom Run-BatchEndpoint.
Configurez les paramètres du déploiement par lots :
Avertissement
Vérifiez que votre point de terminaison par lots a un déploiement par défaut configuré avant de soumettre un travail à celui-ci. Le pipeline créé appelle le point de terminaison. Un déploiement par défaut doit être créé et configuré.
Conseil
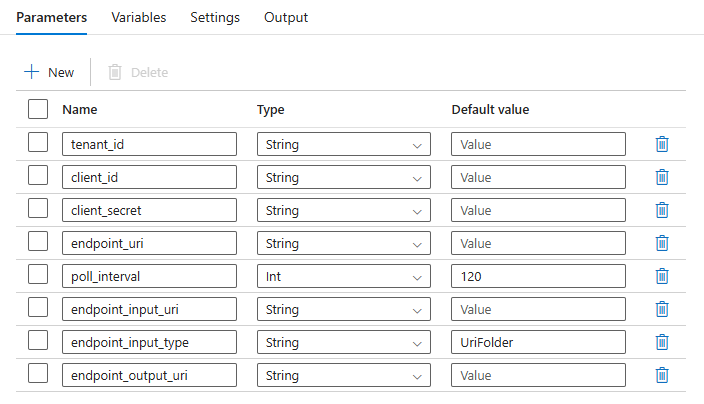
Pour une meilleure réutilisation, utilisez le pipeline créé en tant que modèle et appelez-le à partir d’autres pipelines Azure Data Factory à l’aide de l’activité Execute Pipeline. Dans ce cas, ne configurez pas les paramètres dans le pipeline interne, mais passez-les en tant que paramètres à partir du pipeline externe, comme illustré dans l’image suivante :
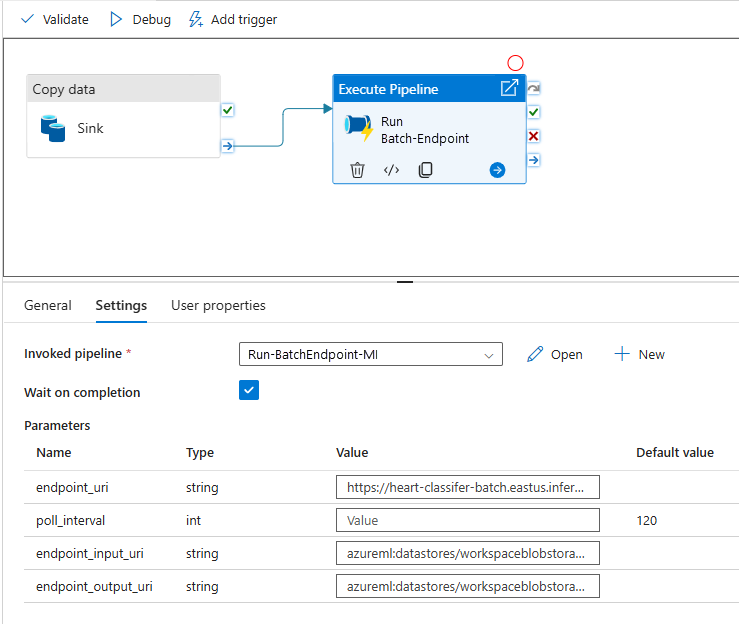
Votre pipeline est prêt à être utilisé.
Limites
Lorsque vous utilisez des déploiements par lots Azure Machine Learning, tenez compte des limitations suivantes :
Entrées de données
- Seuls les magasins de données Azure Machine Learning ou les comptes de stockage Azure (Stockage Blob Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2) sont pris en charge en tant qu’entrées. Si vos données d’entrée se trouvent dans une autre source, utilisez l’activité de copie Azure Data Factory avant l’exécution du travail par lots pour réceptionner les données dans un magasin compatible.
- Les travaux de point de terminaison par lots n’explorent pas les dossiers imbriqués. Ils ne peuvent pas fonctionner avec des structures de dossiers imbriquées. Si vos données sont distribuées dans plusieurs dossiers, vous devez aplatir la structure.
- Assurez-vous que votre script de scoring fourni dans le déploiement peut gérer les données car il alimentera le travail. Si le modèle est MLflow, pour les limitations relatives aux types de fichiers pris en charge, consultez Déployer des modèles MLflow dans des déploiements par lots.
Sorties de données
- Seuls les magasins de données Azure Machine Learning inscrits sont pris en charge. Nous vous recommandons d’inscrire le compte de stockage que votre instance Azure Data Factory utilise comme magasin de données dans Azure Machine Learning. De cette façon, vous pouvez réécrire dans le même compte de stockage que celui où vous lisez.
- Seuls les comptes Stockage Blob Azure sont pris en charge pour les sorties. Par exemple, Azure Data Lake Storage Gen2 n’est pas pris en charge comme sortie dans les travaux de déploiement par lots. Si vous devez générer les données au niveau d’un autre emplacement ou récepteur, utilisez l’activité Copy d’Azure Data Factory après avoir exécuter le travail par lots.