Effectuer un lancement sécurisé de nouveaux déploiements pour l’inférence en temps réel
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Dans cet article, vous allez apprendre à déployer une nouvelle version d’un modèle Machine Learning en production sans provoquer d’interruption. Vous allez utiliser une stratégie de déploiement bleu-vert (également appelée stratégie de lancement sécurisé) pour introduire une nouvelle version d’un service web en production. Cette stratégie vous permettra de déployer votre nouvelle version du service web sur un petit sous-ensemble d’utilisateurs ou de demandes avant de le déployer complètement.
Cet article suppose que vous utilisez des points de terminaison en ligne, c’est-à-dire des points de terminaison utilisés pour l’inférence en ligne (en temps réel). Il existe deux types de points de terminaison en ligne : les points de terminaison en ligne managés et les points de terminaison en ligne Kubernetes. Pour plus d’informations sur les points de terminaison et les différences entre les points de terminaison en ligne managés et les points de terminaison en ligne Kubernetes, consultez Qu’est-ce que les points de terminaison Azure Machine Learning ?.
L’exemple principal de cet article utilise des points de terminaison en ligne managés pour le déploiement. Pour utiliser des points de terminaison Kubernetes à la place, consultez les notes dans ce document qui sont incluses avec la discussion sur les points de terminaison en ligne managés.
Dans cet article, vous allez apprendre à effectuer les opérations suivantes :
- Définir un point de terminaison en ligne avec un déploiement appelé « bleu » pour servir la version 1 d’un modèle
- Mettre à l’échelle le déploiement bleu afin qu’il puisse gérer plus de demandes
- Déployer la version 2 du modèle (appelé déploiement « vert ») sur le point de terminaison, mais n’envoyer au déploiement aucun trafic dynamique
- Tester le déploiement green de façon isolée
- Mettre en miroir un pourcentage du trafic dynamique vers le déploiement vert pour le valider
- Envoyer un faible pourcentage du trafic dynamique au déploiement vert
- Envoyer tout le trafic dynamique au déploiement vert
- Supprimer le déploiement blue de la version 1 maintenant inutilisée
Prérequis
Avant de suivre les étapes décrites dans cet article, vérifiez que vous disposez des composants requis suivants :
L’interface CLI Azure et l’extension
mlpour l’interface CLI Azure. Pour plus d’informations, consultez Installer, configurer et utiliser l’interface CLI (v2).Important
Les exemples CLI de cet article supposent que vous utilisez l’interpréteur de commandes Bash (ou compatible). Par exemple, à partir d’un système Linux ou d’un sous-système Windows pour Linux.
Un espace de travail Azure Machine Learning. Si vous n’en avez pas, suivez les étapes décrites dans la section Installation, configuration et utilisation de l’interface CLI (v2) pour en créer une.
Les contrôles d’accès en fonction du rôle Azure (Azure RBAC) sont utilisés pour accorder l’accès aux opérations dans Azure Machine Learning. Pour effectuer les étapes décrites dans cet article, votre compte d’utilisateur doit avoir le rôle Propriétaire ou Contributeur sur l’espace de travail Azure Machine Learning, ou un rôle personnalisé autorisant
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Pour plus d’informations, consultez Gérer l’accès à un espace de travail Azure Machine Learning.(Facultatif) Pour déployer localement, vous devez installer Moteur Docker sur votre ordinateur local. Nous recommandons fortement cette option pour déboguer les problèmes plus facilement.
Préparer votre système
Définir des variables d’environnement
Si vous n’avez pas encore défini les paramètres par défaut pour l’interface CLI Azure, enregistrez vos paramètres par défaut. Pour éviter de transmettre plusieurs fois les valeurs de votre abonnement, de votre espace de travail et de votre groupe de ressources, exécutez le code suivant :
az account set --subscription <subscription id>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Cloner le référentiel d’exemples
Pour suivre cet article, commencez par cloner le dépôt d’exemples (azureml-examples). Accédez ensuite au répertoire cli/ du dépôt :
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
cd cli
Conseil
Utilisez --depth 1 pour cloner uniquement le dernier commit dans le dépôt. Cela réduit le temps nécessaire à l’exécution de l’opération.
Les commandes de ce tutoriel se trouvent dans le fichier deploy-safe-rollout-online-endpoints.sh du répertoire cli, tandis que les fichiers de configuration YAML se trouvent dans le sous-répertoire endpoints/online/managed/sample/.
Notes
Les fichiers de configuration YAML pour les points de terminaison en ligne Kubernetes se trouvent dans le sous-répertoire endpoints/online/kubernetes/.
Définition du point de terminaison et du déploiement
Les points de terminaison en ligne sont utilisés pour l’inférence en ligne (en temps réel). Les points de terminaison en ligne contiennent des déploiements prêts à recevoir des données des clients et renvoyer des réponses en temps réel.
Définir un point de terminaison
Le tableau suivant répertorie les attributs clés à spécifier quand vous définissez un point de terminaison.
| Attribut | Description |
|---|---|
| Nom | Obligatoire. Nom du point de terminaison, Il doit être unique au sein de la région Azure. Pour obtenir plus d’informations sur les règles d’affectation de noms, consultez les limites de point de terminaison. |
| Mode d'authentification | Méthode d’authentification du point de terminaison. Choisissez entre l’authentification key basée sur une clé et l’authentification aml_token basée sur un jeton Azure Machine Learning. Une clé n’expire pas, mais un jeton expire bien. Pour plus d’informations sur l’authentification, consultez S’authentifier auprès d’un point de terminaison en ligne. |
| Description | Description du point de terminaison. |
| Étiquettes | Dictionnaire d’étiquettes du point de terminaison. |
| Trafic | Règles sur comment acheminer le trafic entre déploiements. Représentez le trafic en tant que dictionnaire de paires clé-valeur, où la clé représente le nom du déploiement et la valeur représente le pourcentage de trafic vers ce déploiement. Vous pouvez définir le trafic uniquement une fois les déploiements créés sous un point de terminaison. Vous pouvez également mettre à jour le trafic d’un point de terminaison en ligne après avoir créé les déploiements. Pour plus d’informations sur l’utilisation du trafic mis en miroir, consultez Allouer un faible pourcentage du trafic en direct au nouveau déploiement. |
| Mettre en miroir le trafic | Pourcentage de trafic en direct vers un déploiement. Pour plus d’informations sur l’utilisation du trafic mis en miroir, consultez Tester le déploiement avec le trafic mis en miroir. |
Pour afficher la liste complète des attributs que vous pouvez spécifier quand vous créez un point de terminaison, consultez le Schéma YAML de point de terminaison en ligne de l’Infrastructure de langage commun (CLI, Common Language Infrastructure) (v2) ou la Classe ManagedOnlineEndpoint du Kit de développement logiciel (SDK, Software Development Kit) (v2).
Définir un déploiement
Un déploiement est un ensemble de ressources nécessaires pour héberger le modèle qui effectue l’inférence réelle. Le tableau suivant décrit les attributs clés à spécifier quand vous définissez un déploiement.
| Attribut | Description |
|---|---|
| Nom | Obligatoire. Nom du déploiement. |
| Nom du point de terminaison | Obligatoire. Nom du point de terminaison sous lequel créer le déploiement. |
| Modèle | Modèle à utiliser pour le déploiement. Cette valeur peut être une référence à un modèle versionné existant dans l’espace de travail ou une spécification de modèle inline. Dans l’exemple, nous avons un modèle scikit-learn qui effectue une régression. |
| Chemin du code | Le chemin d’accès du répertoire dans l’environnement de développement local qui contient tout le code source Python pour le scoring du modèle. Vous pouvez utiliser des répertoires et des packages imbriqués. |
| Script de scoring | Le code Python qui exécute le modèle pour une requête d’entrée donnée. Cette valeur peut être le chemin d'accès relatif du fichier de scoring dans le répertoire de code source. Le script de scoring reçoit les données envoyées à un service web déployé et les passe au modèle. Le script exécute ensuite le modèle et retourne sa réponse au client. Le script de scoring est spécifique à votre modèle. Il doit comprendre les données que le modèle attend en tant qu’entrée et retourne en tant que sortie. Dans cet exemple, nous disposons d’un fichier score.py. Ce code Python doit avoir une fonction init() et une fonction run(). La fonction init() sera appelée une fois le modèle créé ou mis à jour (vous pouvez l’utiliser pour mettre en cache le modèle dans la mémoire, par exemple). La fonction run() est appelée à chaque appel du point de terminaison pour effectuer la notation et la prédiction réelles. |
| Environnement | Obligatoire. L’environnement pour héberger le modèle et le code. Cette valeur peut être une référence à un environnement versionné existant dans l’espace de travail ou une spécification d’environnement inline. L’environnement peut être une image Docker avec des dépendances Conda, un Dockerfile, ou un environnement enregistré. |
| Type d’instance | Obligatoire. Taille de machine virtuelle à utiliser pour le déploiement. Pour obtenir la liste des tailles prises en charge, consultez la liste des références SKU des points de terminaison en ligne managés. |
| Nombre d’instances | Obligatoire. Nombre d’instances à utiliser pour le déploiement. Basez la valeur sur la charge de travail que vous attendez. Pour une haute disponibilité, nous vous recommandons de définir la valeur sur au moins 3. Nous réservons 20 % en plus pour effectuer des mises à niveau. Pour obtenir plus d’informations, consultez les limites pour les points de terminaison en ligne. |
Pour voir la liste complète des attributs que vous pouvez spécifier quand vous créez un déploiement, consultez le Schéma YAML de déploiement en ligne managé de la CLI (v2) ou la Classe ManagedOnlineDeployment du SDK (v2).
Créez le point de terminaison en ligne
Définissez d’abord le nom du point de terminaison, puis configurez-le. Dans cet article, vous utilisez le fichier endpoints/online/managed/sample/endpoint.yml pour configurer le point de terminaison. L’extrait suivant affiche le contenu du fichier :
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
La référence pour le format YAML du point de terminaison est décrite dans le tableau suivant. Pour savoir comment spécifier ces attributs, consultez la référence YAML du point de terminaison en ligne. Pour obtenir plus d’informations sur les limites liées aux points de terminaison en ligne managés, voir limites pour les points de terminaison.
| Clé | Description |
|---|---|
$schema |
(Facultatif) Schéma YAML. Pour voir toutes les options disponibles dans le fichier YAML, vous pouvez consulter le schéma dans l’extrait de code précédent avec un navigateur. |
name |
Nom du point de terminaison. |
auth_mode |
Utilisez key pour l’authentification basée sur les clés. Utilisez aml_token pour l’authentification Azure Machine Learning basée sur les jetons. Utilisez la commande az ml online-endpoint get-credentials pour récupérer le jeton le plus récent. |
Pour créer un point de terminaison en ligne :
Définissez le nom de votre point de terminaison :
Pour Unix, exécutez cette commande (remplacez
YOUR_ENDPOINT_NAMEpar un nom unique) :export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Important
Les noms de points de terminaison doivent être uniques au sein d’une région Azure. Par exemple, dans la région Azure
westus2, il ne peut y avoir qu’un seul point de terminaison avec le nommy-endpoint.Créez le point de terminaison dans le cloud :
Exécutez le code suivant pour utiliser le fichier
endpoint.ymlpour configurer le point de terminaison :az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Créer le déploiement « bleu »
Dans cet article, vous utilisez le fichier endpoints/online/managed/sample/blue-deployment.yml pour configurer les aspects clés du déploiement. L’extrait suivant affiche le contenu du fichier :
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu22.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Pour créer un déploiement nommé blue sur votre point de terminaison, exécutez la commande suivante pour utiliser le fichier blue-deployment.yml pour la configuration
az ml online-deployment create --name blue --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml --all-traffic
Important
L’indicateur --all-traffic dans az ml online-deployment create alloue 100 % du trafic du point de terminaison au déploiement bleu nouvellement créé.
Dans le fichier blue-deployment.yaml, nous spécifions le path (l’emplacement à partir duquel charger les fichiers) inclus. L’interface CLI charge automatiquement les fichiers et inscrit le modèle et l’environnement. En guise de bonne pratique pour la production, vous devez inscrire le modèle et l’environnement et spécifier séparément le nom et la version inscrits dans le code YAML. Utilisez le formulaire model: azureml:my-model:1 ou environment: azureml:my-env:1.
Pour effectuer l’inscription, vous pouvez extraire les définitions YAML de model et environment dans des fichiers YAML distincts et utiliser les commandes az ml model create et az ml environment create. Pour en savoir plus sur ces commandes, exécutez az ml model create -h et az ml environment create -h.
Pour plus d’informations sur l’enregistrement de votre modèle en tant que ressource, consultez Enregistrer votre modèle en tant que ressource dans Machine Learning à l’aide de la CLI. Pour plus d’informations sur la création d’un environnement, consultez Gérer les environnements Azure Machine Learning avec l’interface CLI et le kit SDK (v2).





Vérifier votre déploiement existant
Appeler votre point de terminaison afin qu’il puisse noter votre modèle d’une requête d’entrée donnée est un moyen de confirmer votre déploiement existant. Lorsque vous appelez votre point de terminaison via l’interface CLI ou le kit de développement logiciel (SDK) Python, vous pouvez choisir de spécifier le nom du déploiement qui reçoit le trafic entrant.
Remarque
Contrairement à l’interface CLI ou au kit de développement logiciel (SDK) Python, Azure Machine Learning studio vous oblige à spécifier un déploiement lorsque vous appelez un point de terminaison.
Appeler un point de terminaison avec un nom du déploiement
Si vous appelez le point de terminaison avec le nom du déploiement qui recevra le trafic, Azure Machine Learning acheminera le trafic du point de terminaison directement vers le déploiement spécifié et retournera sa sortie. Vous pouvez utiliser l’option --deployment-namepour CLI v2 ou l’option deployment_namepour SDK v2 afin de spécifier le déploiement.
Appeler un point de terminaison sans spécifier le déploiement
Si vous appelez le point de terminaison sans spécifier le déploiement qui recevra le trafic, Azure Machine Learning acheminera le trafic entrant du point de terminaison vers le ou les déploiements du point de terminaison en fonction des paramètres de contrôle du trafic.
Les paramètres de contrôle du trafic allouent des pourcentages spécifiés de trafic entrant à chaque déploiement du point de terminaison. Par exemple, si vos règles de trafic spécifient qu’un déploiement particulier de votre point de terminaison recevra le trafic entrant 40 % du temps, Azure Machine Learning acheminera 40 % du trafic du point de terminaison vers ce déploiement.
Vous pouvez afficher l’état de vos point de terminaison et déploiement existants en exécutant :
az ml online-endpoint show --name $ENDPOINT_NAME
az ml online-deployment show --name blue --endpoint $ENDPOINT_NAME
Vous devez normalement voir le point de terminaison identifié par $ENDPOINT_NAME et un déploiement appelé blue.
Tester le point de terminaison avec des exemples de données
Le point de terminaison peut être appelé avec la commande invoke. Nous allons envoyer un exemple de requête à l’aide d’un fichier json.
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json


Mettre à l’échelle votre déploiement existant pour gérer davantage de trafic
Dans le déploiement décrit dans Déployer et scorer un modèle Machine Learning avec un point de terminaison en ligne, vous définissez instance_count sur la valeur 1 dans le fichier YAML de déploiement. Vous pouvez effectuer un scale-out à l’aide de la commande update :
az ml online-deployment update --name blue --endpoint-name $ENDPOINT_NAME --set instance_count=2
Notes
Notez que, dans la commande ci-dessus, nous utilisons --set pour remplacer la configuration de déploiement. Vous pouvez également mettre à jour le fichier YAML et le transmettre en tant qu’entrée à la commande update en tapant --file.

Déployer un nouveau modèle, mais sans lui envoyer encore aucun trafic
Créez un déploiement nommé green :
az ml online-deployment create --name green --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/green-deployment.yml
Étant donné que nous n’avons pas explicitement alloué de trafic à green, aucun trafic ne lui est alloué. Vous pouvez vérifier cela à l’aide de la commande :
az ml online-endpoint show -n $ENDPOINT_NAME --query traffic
Tester le nouveau déploiement
Bien que 0 % du trafic soit alloué à green, vous pouvez l’appeler directement en spécifiant le nom --deployment :
az ml online-endpoint invoke --name $ENDPOINT_NAME --deployment-name green --request-file endpoints/online/model-2/sample-request.json
Si vous voulez utiliser un client REST pour appeler le déploiement directement sans passer par les règles de trafic, définissez l’en-tête HTTP suivant : azureml-model-deployment: <deployment-name>. L’extrait de code ci-dessous utilise curl pour appeler le déploiement directement. L’extrait de code doit fonctionner dans des environnements Unix/WSL :
# get the scoring uri
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
# use curl to invoke the endpoint
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --header "azureml-model-deployment: green" --data @endpoints/online/model-2/sample-request.json


Tester le déploiement avec du trafic en miroir
Une fois que vous avez testé votre déploiement green, vous pouvez mettre en miroir (ou copier) en sa direction un pourcentage du trafic en direct. La mise en miroir du trafic (également appelée mise en miroir fantôme) ne modifie pas les résultats retournés aux clients. Les requêtes continuent d’être transmises à 100 % vers le déploiement blue. Le pourcentage en miroir du trafic est copié et envoyé au déploiement green pour que vous puissiez collecter des métriques et une journalisation sans impacter vos clients. La mise en miroir est utile pour valider un nouveau déploiement sans impacter les clients. Par exemple, vous pouvez utiliser la mise en miroir pour vérifier si la latence est dans des limites acceptables ou qu’il n’y a pas d’erreur HTTP. Le test du nouveau déploiement avec la mise en miroir/l’ombre du trafic est également appelé test instantané. Le déploiement qui reçoit le trafic mis en miroir (dans ce cas, le déploiement green) peut également être appelé déploiement fantôme.
La mise en miroir a les limites suivantes :
- La mise en miroir est prise en charge pour la CLI (v2) (version 2.4.0 ou ultérieure) et le SDK Python (v2) (version 1.0.0 ou ultérieure). Si vous utilisez une version antérieure de CLI/SDK pour mettre à jour un point de terminaison, vous perdrez le paramètre de mise en miroir du trafic.
- La mise en miroir n’est pas actuellement prise en charge pour les points de terminaison en ligne Kubernetes.
- La mise en miroir de trafic ne peut être effectuée que vers un seul déploiement dans un point de terminaison.
- Le pourcentage maximal de trafic que vous pouvez mettre en miroir est de 50 %. Cette limite sert à réduire l’effet sur votre quota de bande passante de point de terminaison (5 Mo/s par défaut). La bande passante de votre point de terminaison est limitée si vous dépassez le quota alloué. Pour plus d’informations sur le monitoring de la limitation de bande passante, consultez Monitorer les points de terminaison en ligne managés.
Notez également les comportements suivants :
- Un déploiement peut être configuré pour recevoir uniquement le trafic en direct ou le trafic mis en miroir, mais pas les deux à la fois.
- Lorsque vous appelez un point de terminaison, vous pouvez spécifier le nom de l’un de ses déploiements, même un déploiement fantôme, pour retourner la prédiction.
- Lorsque vous appelez un point de terminaison avec le nom du déploiement qui recevra le trafic entrant, Azure Machine Learning ne met pas en miroir le trafic sur le déploiement fantôme. Azure Machine Learning met en miroir le trafic vers le déploiement fantôme à partir du trafic envoyé au point de terminaison quand vous ne spécifiez pas de déploiement.
Nous allons maintenant définir le déploiement vert pour recevoir 10 % du trafic mis en miroir. Les clients continueront de recevoir des prédictions uniquement du déploiement bleu.
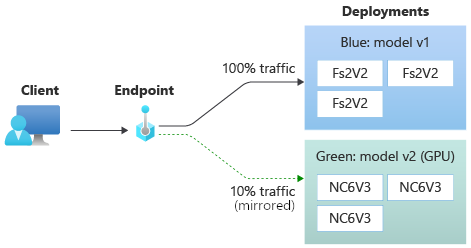
La commande suivante met en miroir 10 % du trafic sur le déploiement green :
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=10"
Vous pouvez tester le trafic miroir en appelant le point de terminaison plusieurs fois sans spécifier le déploiement qui recevra le trafic entrant :
for i in {1..20} ; do
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
done
Vous pouvez vérifier qu’un certain pourcentage du trafic a été envoyé au déploiement green en consultant les journaux du déploiement :
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Après le test, vous pouvez définir le trafic miroir sur zéro pour désactiver la mise en miroir :
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=0"



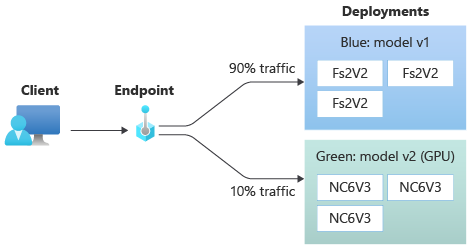
Allouer un faible pourcentage du trafic en direct vers le nouveau déploiement
Après avoir testé votre déploiement green, allouez-lui un petit pourcentage de trafic :
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=90 green=10"
Conseil
Le pourcentage total de trafic doit être égal à 0 % (pour désactiver le trafic) ou 100 % (pour activer le trafic).
Votre déploiement green reçoit désormais 10 % de tout le trafic en direct. Les clients reçoivent des prédictions à la fois des déploiements blue et green.
Envoyer tout le trafic vers votre nouveau déploiement
Une fois que votre déploiement green vous donne entière satisfaction, basculez tout le trafic vers celui-ci.
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=0 green=100"
Supprimer l’ancien déploiement
Effectuez les étapes suivantes pour supprimer un déploiement individuel d’un point de terminaison en ligne managé. La suppression d’un déploiement individuel n’affecte pas les autres déploiements dans le point de terminaison en ligne managé :
az ml online-deployment delete --name blue --endpoint $ENDPOINT_NAME --yes --no-wait
Supprimer le point de terminaison et le déploiement
Si vous ne comptez pas utiliser le point de terminaison et le déploiement, vous devriez les supprimer. En supprimant le point de terminaison, vous supprimez également tous ses déploiements sous-jacents.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Contenu connexe
- Explorer les exemples de points de terminaison en ligne
- Déployer des modèles avec REST
- Utiliser l’isolement réseau avec les points de terminaison en ligne managés
- Accéder aux ressources Azure avec un point de terminaison en ligne et une identité managée
- Monitorer les points de terminaison en ligne managés
- Gérer et augmenter les quotas pour les ressources avec Azure Machine Learning
- Voir les coûts d’un point de terminaison en ligne managé Azure Machine Learning
- Liste des références SKU de points de terminaison en ligne managés
- Résolution des problèmes de déploiement et de scoring de points de terminaison en ligne
- Informations de référence du schéma YAML de point de terminaison en ligne