Préparer les données pour les tâches de vision par ordinateur avec le Machine Learning automatisé
S’APPLIQUE À : Extension Azure ML CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (préversion)
Extension Azure ML CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (préversion)
Important
La prise en charge de l’apprentissage des modèles de vision par ordinateur avec ML automatisé dans Azure Machine Learning est une fonctionnalité en préversion publique expérimentale. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Dans cet article, vous allez apprendre à préparer les données d’image pour l’apprentissage des modèles de vision par ordinateur avec des Machine Learning automatisé dans Azure Machine Learning. Pour générer des modèles destinés à des tâches de vision par ordinateur avec Machine Learning automatisé, vous devez apporter les données d’image étiquetées comme entrées pour l’apprentissage de modèles sous la forme d’un MLTable Azure Machine Learning.
Vous pouvez créer un MLTable à partir de données d’entraînement étiquetées au format JSONL. Si vos données de formation étiquetées sont dans un format différent, comme Pascal Visual Object Classes (VOC) ou COCO, vous pouvez utiliser un script de conversion pour les convertir en JSONL, puis créer un fichierMLTable. Alternativement, vous pouvez utiliser l’outil d’étiquetage des données d’Azure Machine Learning pour étiqueter manuellement les images. Exportez ensuite les données étiquetées à utiliser pour former votre modèle AutoML.
Prérequis
- Familiarisez-vous avec les schémas acceptés pour les fichiers JSONL pour les expériences de vision d’ordinateur AutoML.
Obtenir des données étiquetées
Pour former des modèles de vision par ordinateur en utilisant AutoML, vous devez d’abord obtenir des données de formation étiquetées. Les images doivent être chargées dans le cloud. Les annotations d’étiquette doivent être au format JSONL. Vous pouvez utiliser l’outil d’étiquetage des données Azure Machine Learning pour étiqueter vos données ou bien vous pouvez commencer avec des données d’image préétiquetées.
Utilisez l’outil d’étiquetage des données Azure Machine Learning pour étiqueter vos données de formation
Si vous n’avez pas de données préétiquetées, vous pouvez utiliser l’outil d’étiquetage des données d’Azure Machine Learning pour étiqueter manuellement les images. Cet outil génère automatiquement les données requises pour l’apprentissage au format accepté. Pour plus d’informations, voir Configurer un projet d’étiquetage d’images.
L’outil permet de créer, gérer et surveiller les tâches d’étiquetage des données pour :
- Classification d’images (multi-classe et multi-étiquette)
- Détection d’objets (cadre englobant)
- Segmentation d'instance (polygone)
Si vous avez déjà des données étiquetées à utiliser, vous pouvez exporter ces données étiquetées en tant que jeu de données Azure Machine Learning, puis accéder au jeu de données sous l’onglet « Jeux de données » dans Azure Machine Learning studio. Vous pouvez transmettre ce jeu de données exporté en tant qu’entrée à l’aide de format azureml:<tabulardataset_name>:<version>. Pour plus d’informations, consultez Exporter les étiquettes.
Voici un exemple montrant comment passer un jeu de données existant comme entrée pour des modèles d’apprentissage Vision par ordinateur.
S’APPLIQUE À : Extension ml Azure CLI v2 (actuelle)
training_data:
path: azureml:odFridgeObjectsTrainingDataset:1
type: mltable
mode: direct
Utilisez des données de formation préétiquetées provenant d’une machine locale
Si vous avez des données étiquetées que vous voulez utiliser pour former de votre modèle, chargez les images dans Azure. Vous pouvez charger vos images dans le Stockage Blob Azure par défaut de votre espace de travail Azure Machine Learning. Enregistrez-les en tant que ressource de données. Pour plus d’informations, consultez Créer et gérer des ressources de données.
Le script suivant charge les données d’image sur votre ordinateur local dans le chemin d’accès ./data/odFridgeObjects du magasin de données dans Stockage Blob Azure. Il crée ensuite une ressource de données nommée fridge-items-images-object-detection dans votre espace de travail Azure Machine Learning.
S’il existe déjà une ressource de données nommée fridge-items-images-object-detection dans votre espace de travail Azure Machine Learning, le script met à jour le numéro de version de cette ressource et la fait pointer vers le nouvel emplacement où les données d’image ont été chargées.
S’APPLIQUE À : Extension ml Azure CLI v2 (actuelle)
Créez un fichier .yml avec la configuration suivante.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: ./data/odFridgeObjects
type: uri_folder
Pour charger des images en tant que ressource de données, exécutez la commande CLI v2 suivante avec le chemin de votre fichier .yml, le nom de l’espace de travail, le groupe de ressources et l’ID d’abonnement.
az ml data create -f [PATH_TO_YML_FILE] --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
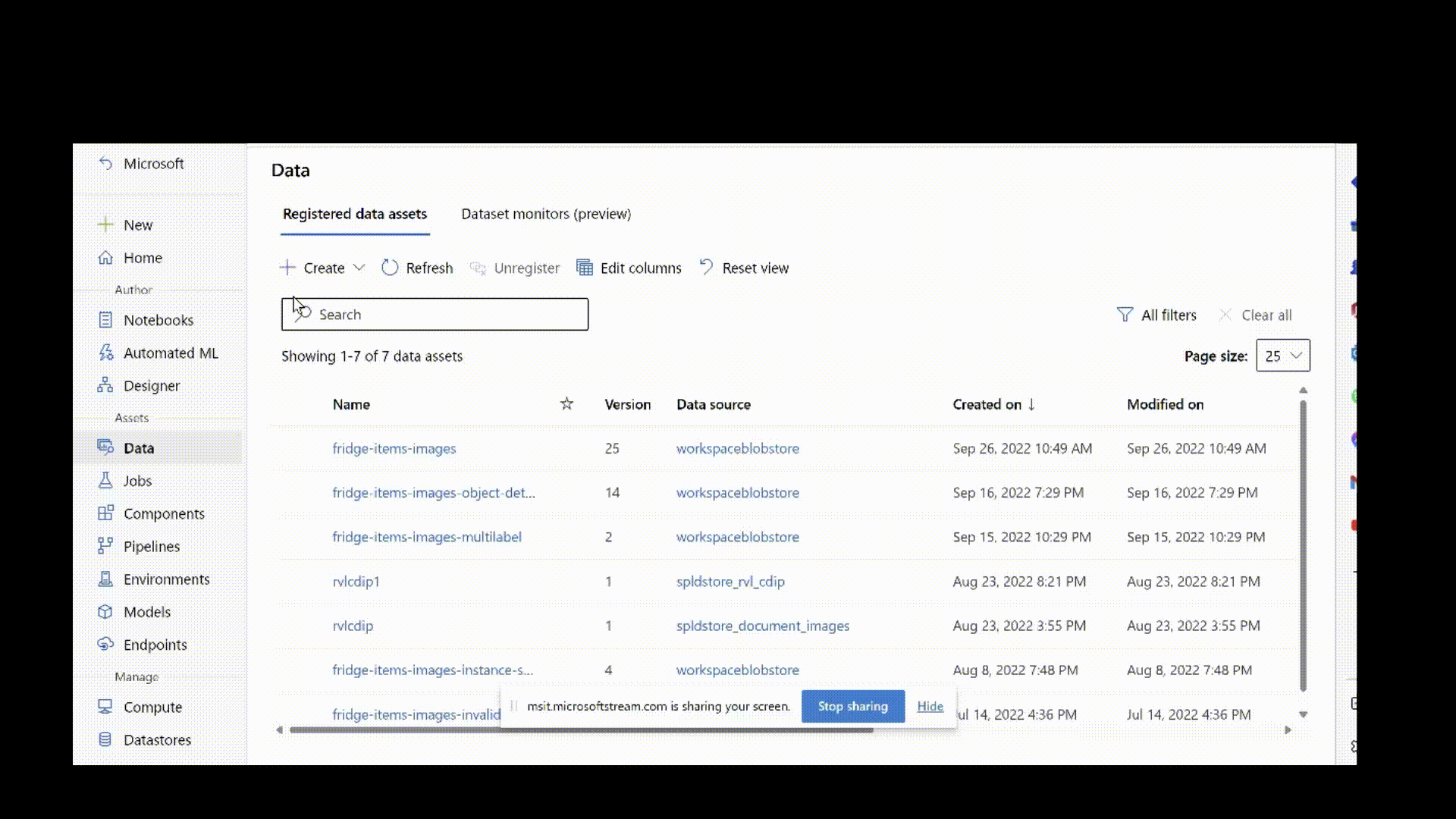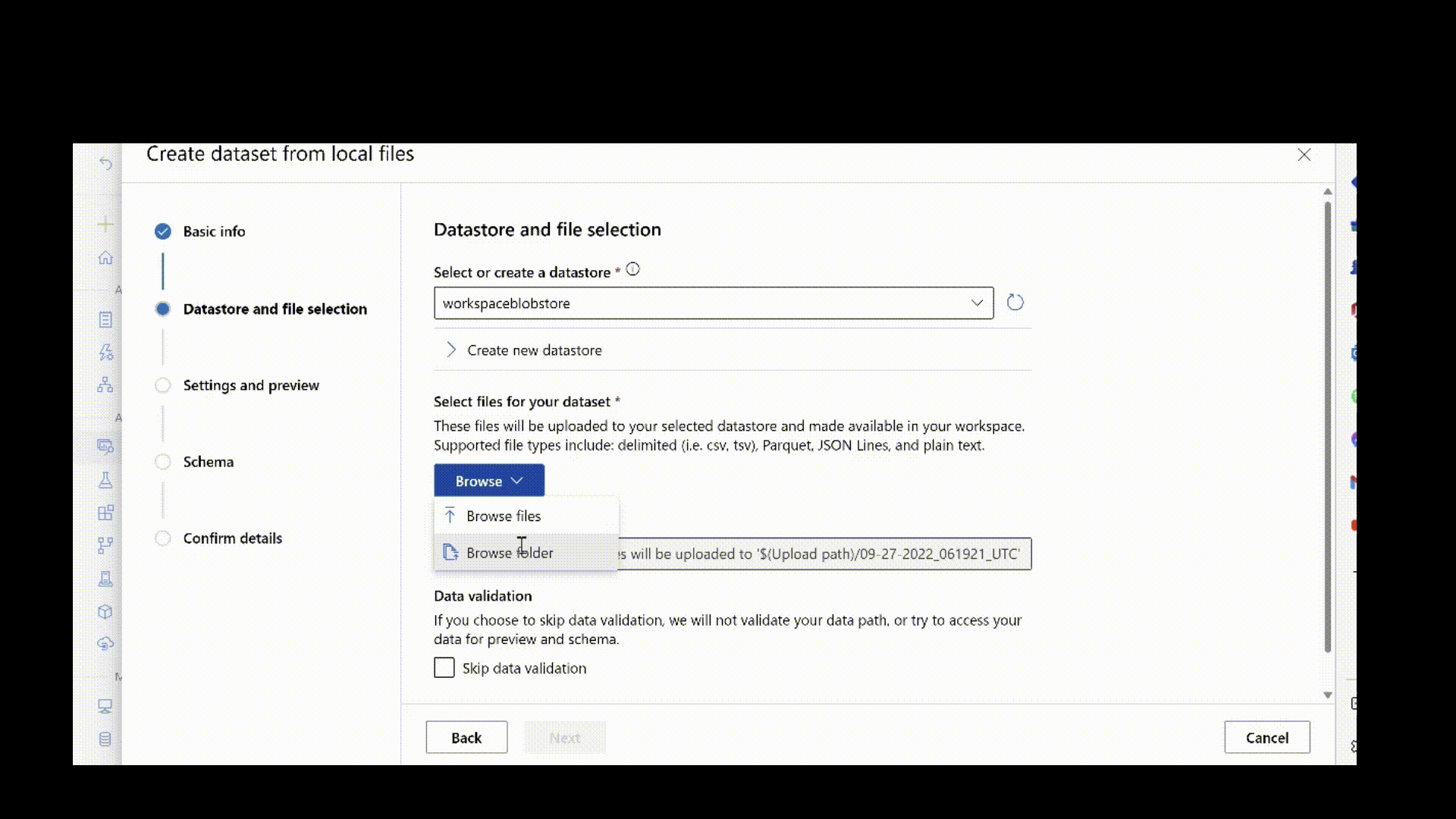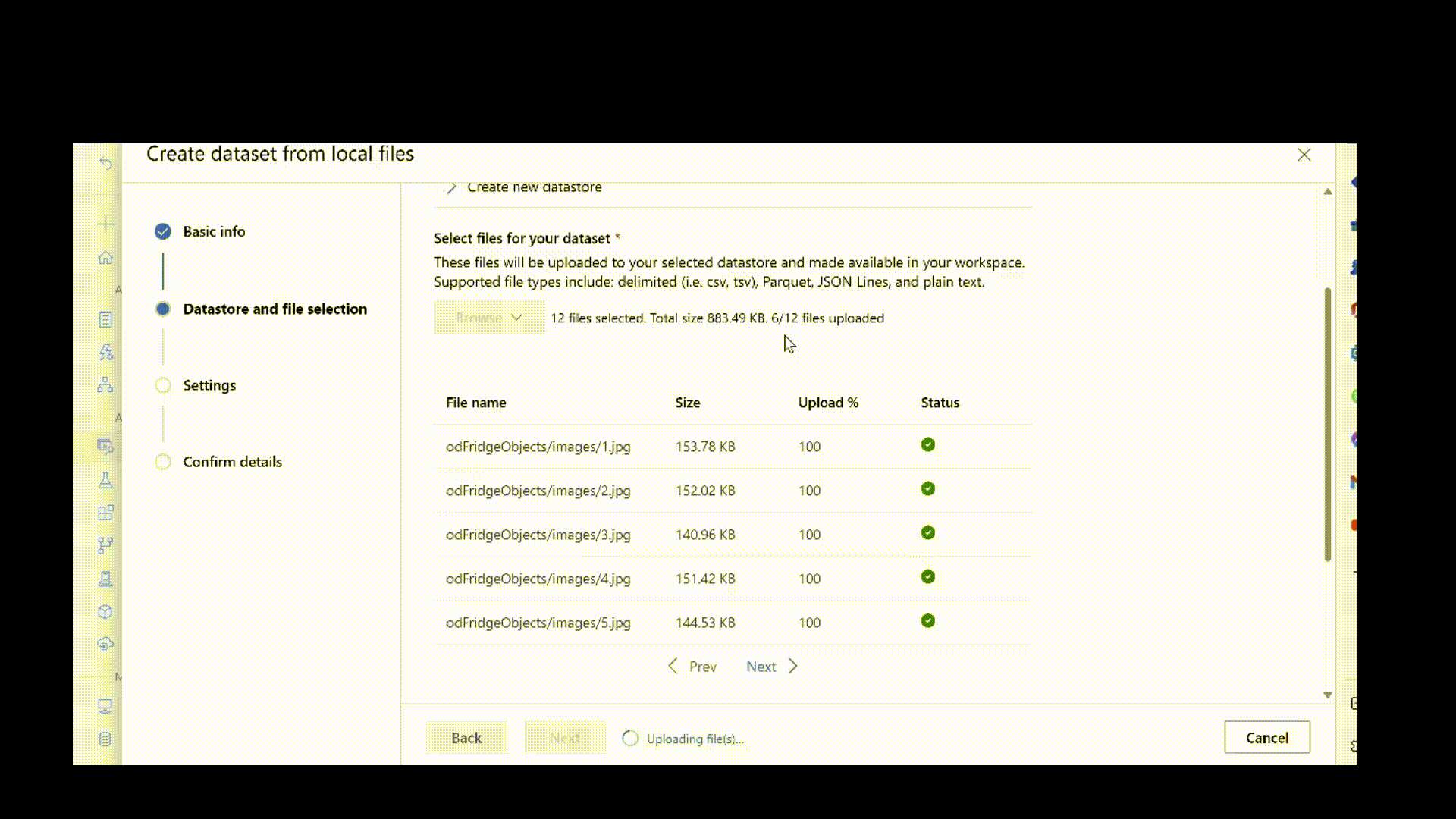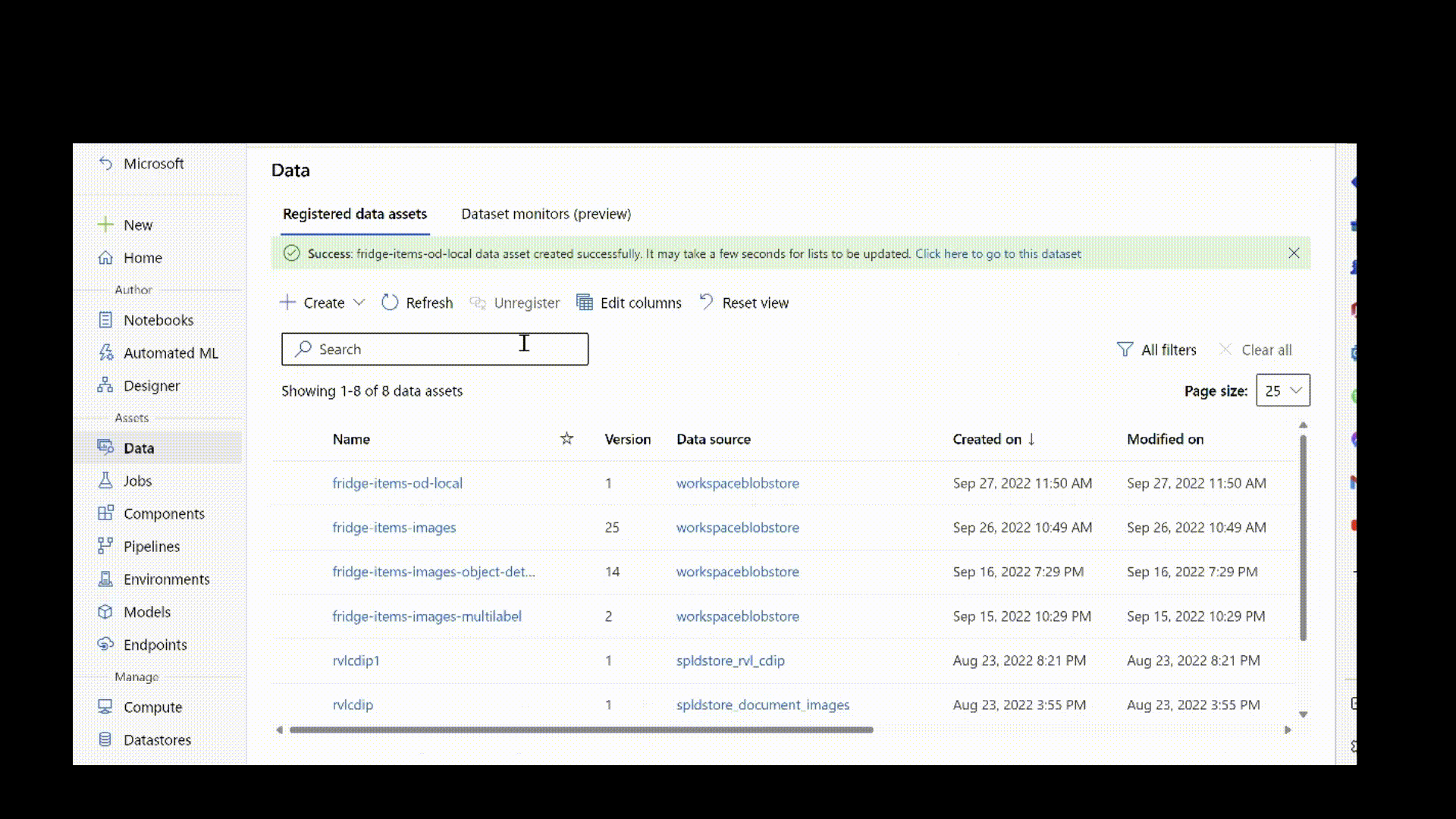
Si vous disposez déjà de vos données dans un magasin de données existant, vous pouvez créer une ressource de données à partir de celle-ci. Indiquez le chemin d’accès aux données dans le magasin de données au lieu du chemin d’accès de votre ordinateur local. Mettez à jour le code précédent avec l’extrait suivant.
S’APPLIQUE À : Extension ml Azure CLI v2 (actuelle)
Créez un fichier .yml avec la configuration suivante.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/<path_to_image_data_folder>
type: uri_folder
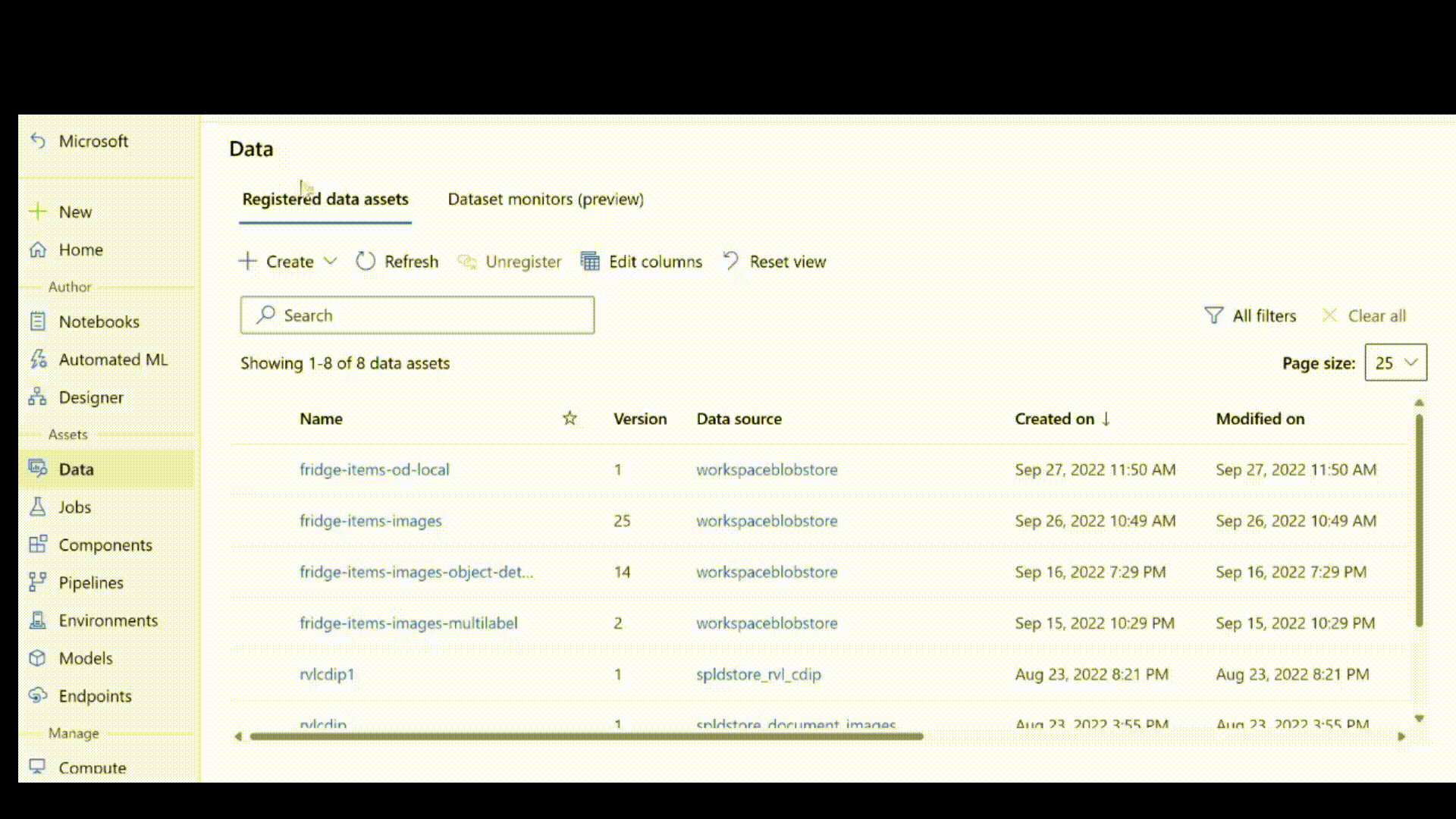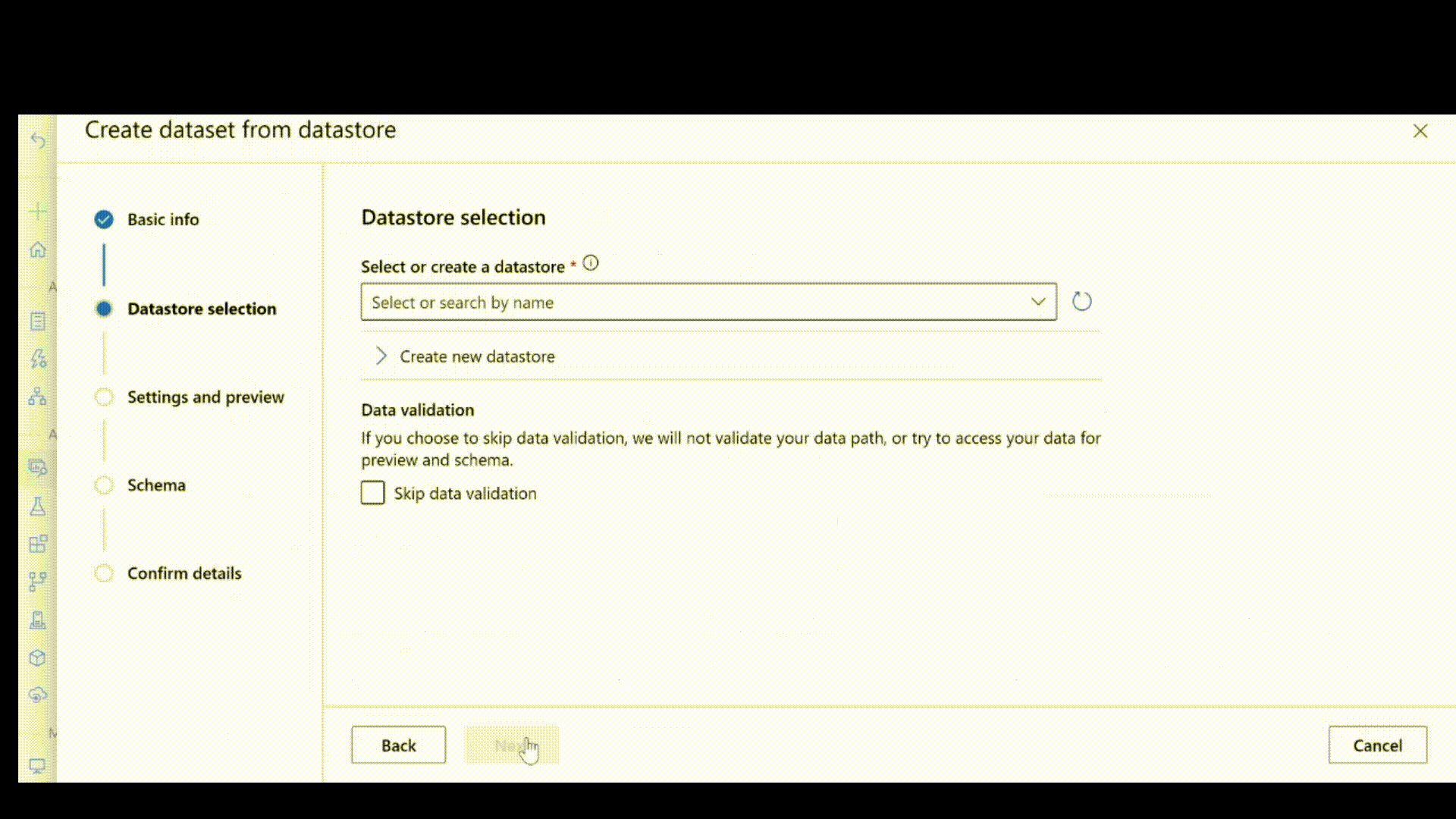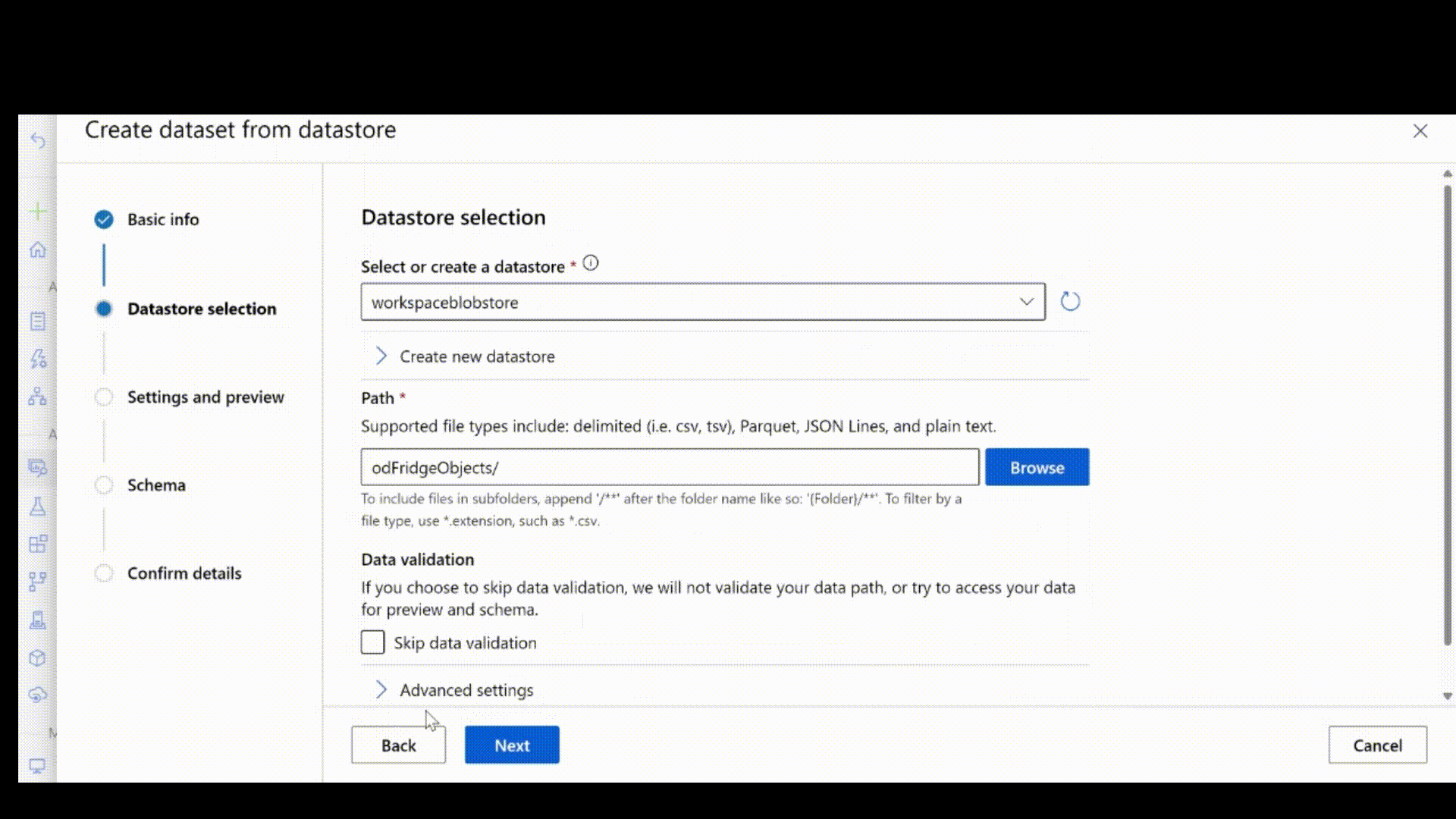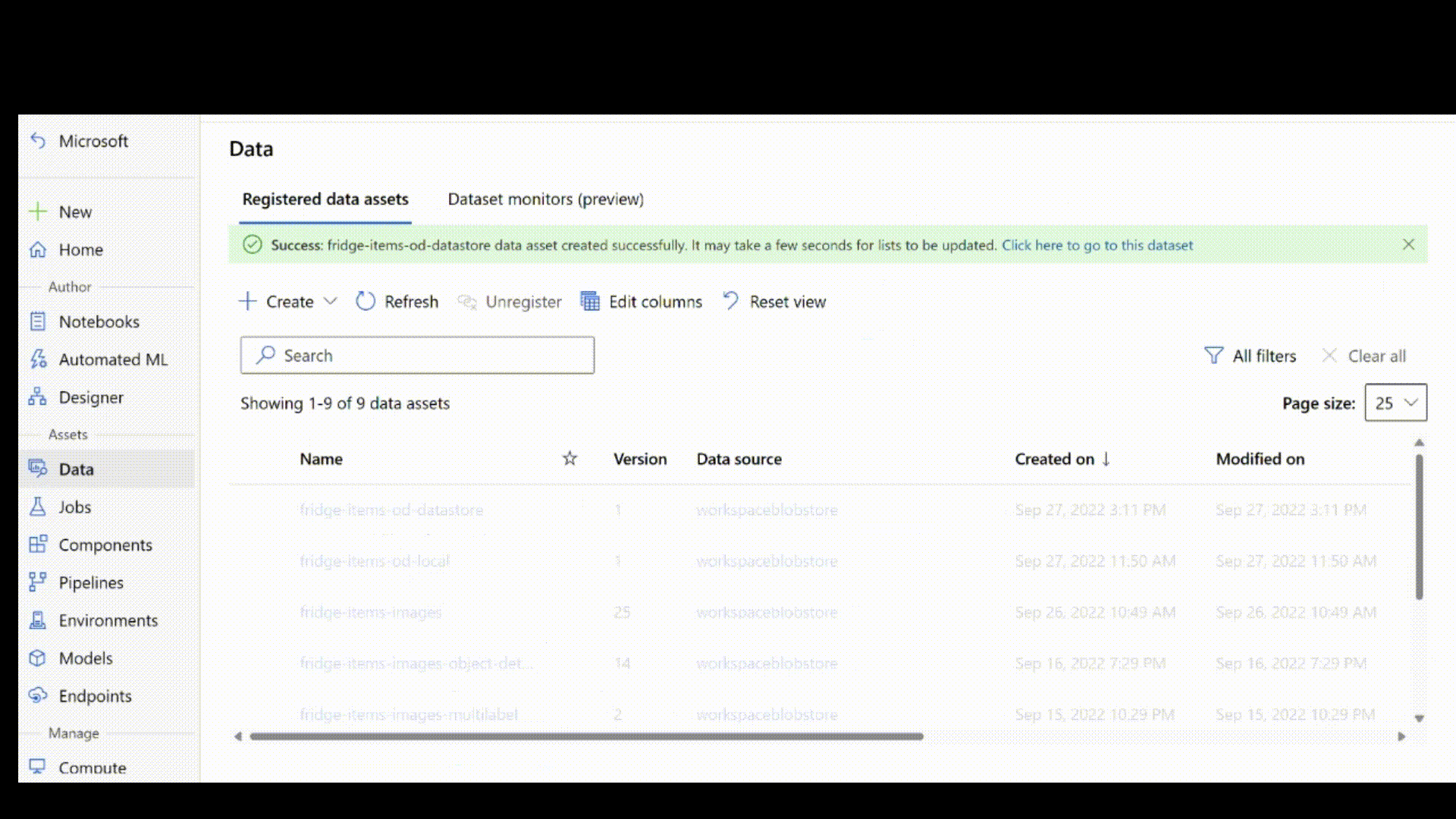
Ensuite, obtenez les annotations d’étiquette au format JSONL. Le schéma des données étiquetées dépend de la tâche de vision par ordinateur en question. Pour en savoir plus sur le schéma JSONL requis pour chaque type de tâche, consultez schémas de données pour former des modèles de vision par ordinateur avec le machine learning automatisé.
Si vos données de formation sont dans un format différent, comme pascal VOC ou COCO, des scripts d’aide peuvent convertir les données en JSONL. Les scripts sont disponibles dans les exemples de notebook.
Après avoir créé le fichier .jsonl, vous pouvez l’inscrire en tant que ressource de données à l’aide de l’interface utilisateur. Veillez à sélectionner le type stream dans la section schéma, comme indiqué dans cette animation.
Utilisez des données de formation préétiquetées provenant de Stockage Blob Azure
Si vos données de formation étiquetées sont présentes dans un conteneur dans stockage Blob Azure, vous pouvez y accéder directement. Créez un magasin de données dans ce conteneur. Pour plus d’informations, consultez Créer et gérer des ressources de données.
Créer un MLTable
Après que vos données sont étiquetées au format JSONL, vous pouvez les utiliser pour créer une MLTable comme indiqué dans cet extrait de code yaml. MLtable compresse vos données dans un objet consommable pour l’entraînement.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Vous pouvez ensuite passer MLTable comme une entrée de données de votre travail d’entraînement AutoML. Pour plus d’informations, consultez Configurer AutoML pour entraîner des modèles vision par ordinateur.