Gérer les entrées et les sorties des composants et des pipelines
Les pipelines Azure Machine Learning prennent en charge les entrées et les sorties au niveau du composant et du pipeline. Cet article décrit les entrées et sorties des pipelines et des composants et explique comment les gérer.
Au niveau du composant, les entrées et les sorties définissent l’interface du composant. Vous pouvez utiliser la sortie d’un composant comme entrée pour un autre composant dans le même pipeline parent, ce qui permet de transférer des données ou des modèles entre les composants. Cette interconnexion représente le flux de données au sein du pipeline.
Au niveau du pipeline, vous pouvez utiliser des entrées et des sorties pour envoyer des travaux de pipeline avec des entrées de données ou des paramètres variables, tels que learning_rate. Les entrées et sorties sont particulièrement utiles lorsque vous appelez un pipeline via un point de terminaison REST. Vous pouvez affecter différentes valeurs à l’entrée du pipeline ou accéder à la sortie de différents travaux de pipeline. Pour plus d’information, consultez Créer des travaux et des données d’entrée pour les points de terminaison de lot.
Types d’entrée et de sortie
Les types suivants sont pris en charge en tant qu’entrées et sorties de composants ou de pipelines :
les types de données ; Pour plus d’informations, consultez Types de données.
uri_fileuri_foldermltable
Types de modèles.
mlflow_modelcustom_model
Les types primitifs suivants sont également pris en charge pour les entrées uniquement :
- Types primitifs
stringnumberintegerboolean
La sortie de type primitif n’est pas prise en charge.
Exemples d’entrées et de sorties
Ces exemples proviennent du pipeline Régression des données NYC Taxi dans le dépôt GitHub Exemples Azure Machine Learning.
- Le composant d’apprentissage a une entrée
numbernomméetest_split_ratio. - Le composant de préparation a une sortie de type
uri_folder. Le code source du composant lit les fichiers csv du dossier d’entrée, traite les fichiers et écrit les fichiers CSV traités dans le dossier de sortie. - Le composant d’apprentissage a une sortie de type
mlflow_model. Le code source du composant enregistre le modèle entraîné à l’aide de la méthodemlflow.sklearn.save_model.
Sérialisation des sorties
L’utilisation de sorties de données ou de modèles sérialise les sorties et les enregistre sous forme de fichiers dans un emplacement de stockage. Les étapes ultérieures peuvent accéder aux fichiers pendant l’exécution du travail en montant cet emplacement de stockage ou en téléchargeant ou en chargeant les fichiers dans le système de fichiers de calcul.
Le code source du composant doit sérialiser l’objet de sortie, généralement stocké en mémoire, dans des fichiers. Par exemple, vous pouvez sérialiser un dataframe pandas en tant que fichier CSV. Azure Machine Learning ne définit pas de méthodes standardisées pour la sérialisation d’objets. Vous avez la possibilité de choisir vos méthodes préférées pour sérialiser des objets dans des fichiers. Dans le composant en aval, vous pouvez choisir comment désérialiser et lire ces fichiers.
Chemins d’entrée et de sortie de type de données
Pour les entrées et les sorties des ressources de données, vous devez spécifier un paramètre de chemin qui pointe vers l’emplacement des données. Le tableau suivant présente les emplacements de données pris en charge pour les entrées et sorties du pipeline Azure Machine Learning, avec des exemples de paramètre path.
| Emplacement | Entrée | Sortie | Exemple |
|---|---|---|---|
| Chemin sur votre ordinateur local | ✓ | ./home/<username>/data/my_data |
|
| Un chemin sur un serveur http/s public | ✓ | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
|
| Chemin dans Stockage Azure | * | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>or abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
|
| Un chemin sur un magasin de données Azure Machine Learning | ✓ | ✓ | azureml://datastores/<data_store_name>/paths/<path> |
| Un chemin vers une ressource de données | ✓ | ✓ | azureml:my_data:<version> |
* L’utilisation directe du stockage Azure n’est pas recommandée pour l’entrée, car une configuration d’identité supplémentaire peut être requise pour lire les données. Il est préférable d’utiliser des chemins de magasin de données Azure Machine Learning, pris en charge dans différents types de travaux de pipeline.
Modes d’entrée et de sortie de type de données
Pour les entrées et sorties de type de données, vous pouvez choisir parmi plusieurs modes de téléchargement, de chargement et de montage pour définir la façon dont la cible de calcul accède aux données. Le tableau suivant présente les modes pris en charge pour différents types d’entrées et de sorties.
| Type | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|
Entrée uri_folder |
✓ | ✓ | ✓ | ||||
Entrée uri_file |
✓ | ✓ | ✓ | ||||
Entrée mltable |
✓ | ✓ | ✓ | ✓ | ✓ | ||
Sortie uri_folder |
✓ | ✓ | |||||
Sortie uri_file |
✓ | ✓ | |||||
Sortie mltable |
✓ | ✓ | ✓ |
Les modes ro_mount ou rw_mount sont recommandés pour la plupart des cas. Pour plus d’informations, consultez Modes.
Entrées et sorties dans les graphiques de pipeline
Sur la page du travail de pipeline dans Azure Machine Learning studio, les entrées et sorties des composants apparaissent sous forme de petits cercles appelés ports d’entrée/sortie. Ces ports représentent le flux de données dans le pipeline. La sortie au niveau du pipeline s’affiche sous la forme de zones violettes pour faciliter l’identification.
La capture d’écran suivante du graphique du pipeline Régression de données NYC Taxi montre de nombreuses entrées et sorties de composant et de pipeline.

Lorsque vous pointez sur un port d’entrée/sortie, le type s’affiche.
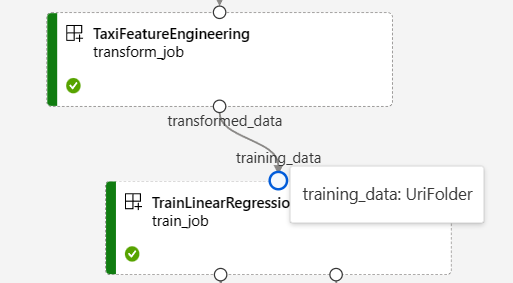
Le graphique de pipeline n’affiche pas d’entrées de type primitif. Ces entrées s’affichent sur l’onglet Paramètres du panneau Vue d’ensemble du travail du pipeline pour les entrées au niveau du pipeline, ou dans le panneau du composant pour les entrées au niveau du composant. Pour ouvrir le panneau du composant, double-cliquez sur le composant dans le graphique.

Lorsque vous modifiez un pipeline dans le Concepteur studio, les entrées et sorties de pipeline se trouvent dans le panneau Interface de pipeline, et les entrées et sorties de composant se trouvent dans le panneau du composant.
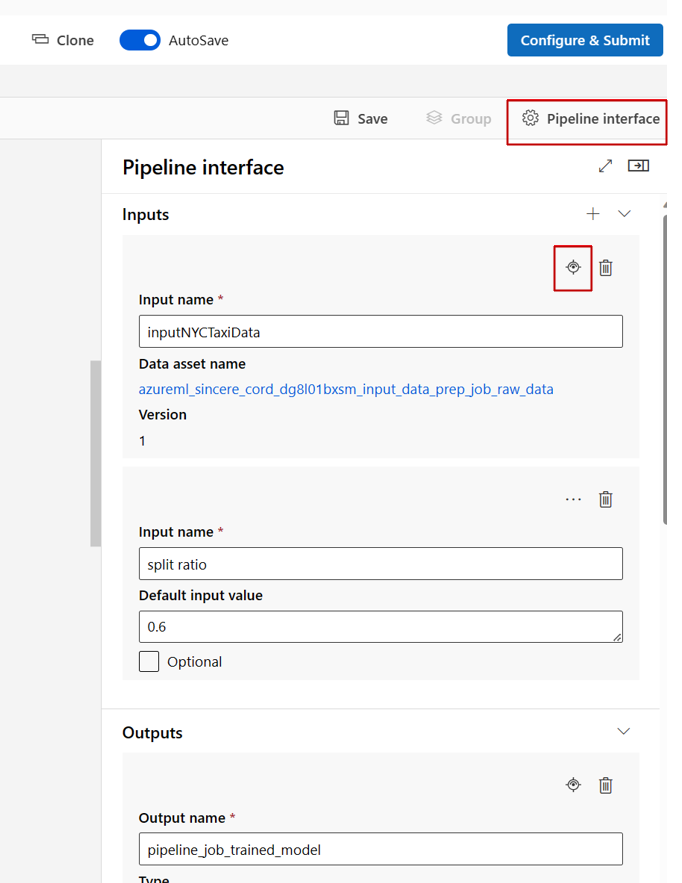
Promouvoir les entrées et les sorties de composant au niveau du pipeline
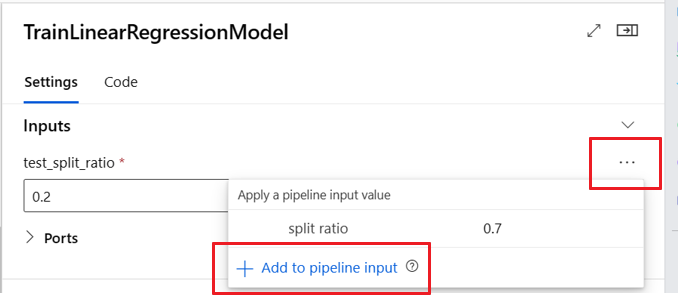
La promotion de l’entrée/sortie d’un composant au niveau du pipeline vous permet de remplacer l’entrée/sortie du composant lors de l’envoi d’un travail de pipeline. Cette capacité est particulièrement utile pour déclencher des pipelines à l’aide de points de terminaison REST.
Les exemples suivants montrent comment promouvoir les entrées/sorties au niveau des composants en entrées/sorties au niveau du pipeline.
Le pipeline suivant promeut trois entrées et trois sorties au niveau du pipeline. Par exemple, pipeline_job_training_max_epocs est une entrée au niveau du pipeline, car il est déclaré sous la section inputs au niveau de la racine.
Sous train_job, dans la section jobs, l’entrée nommée max_epocs est référencée comme ${{parent.inputs.pipeline_job_training_max_epocs}}, ce qui indique que l’entrée de train_job, max_epocs fait référence à l’entrée pipeline_job_training_max_epocs au niveau du pipeline. La sortie du pipeline est promue à l’aide du même schéma.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
Vous trouverez l’exemple complet sous pipeline train-score-eval avec des composants inscrits dans le référentiel Exemples Azure Machine Learning.
Définir des entrées facultatives
Par défaut, toutes les entrées sont requises et doivent avoir une valeur par défaut ou recevoir une valeur chaque fois que vous envoyez un travail de pipeline. Toutefois, vous pouvez définir une entrée facultative.
Remarque
Les sorties facultatives ne sont pas prises en charge.
Définir des entrées facultatives peut être utile dans deux scénarios :
Si vous définissez une entrée de type de données/modèle facultative et que vous ne lui attribuez pas de valeur lors de l’envoi du travail de pipeline, le composant de pipeline n’a pas cette dépendance de données. Si le port d’entrée du composant n’est lié à aucun composant ou nœud de données/modèle, le pipeline appelle le composant directement au lieu d’attendre une dépendance précédente.
Si vous définissez
continue_on_step_failure = Truepour le pipeline, mais quenode2utilise l’entrée requise à partir denode1,node2ne s’exécute pas sinode1échoue. Si l’entréenode1est facultative,node2s’exécute même sinode1échoue. Le graphique suivant illustre ce scénario.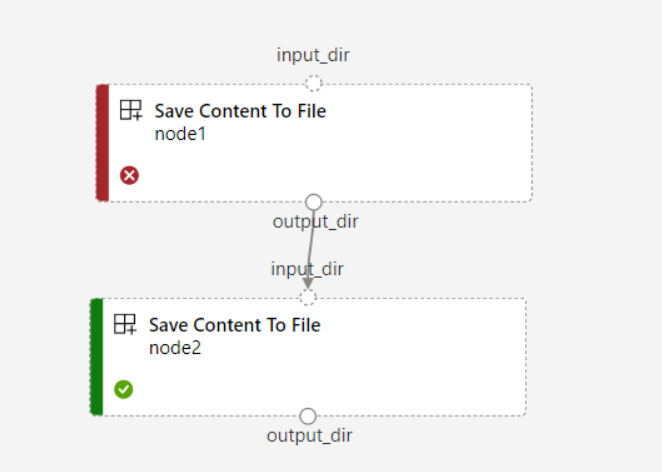
L’exemple de code suivant montre comment supprimer une entrée facultative. Lorsque l’entrée est définie comme optional = true, vous devez utiliser $[[]] pour adopter les entrées de ligne de commande, comme dans les lignes mises en surbrillance de l’exemple.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}

Personnaliser les chemins de sortie
Par défaut, la sortie du composant est stockée dans le {default_datastore} que vous définissez pour le pipeline, azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}}. S’il n’est pas spécifié, l’emplacement par défaut est le stockage blob de l’espace de travail.
Le {name} de travail est résolu au moment de l’exécution du travail et {output_name} est le nom que vous avez défini dans le composant YAML. Vous pouvez personnaliser l’emplacement de stockage de la sortie en définissant un chemin de sortie.
Le fichier pipeline.yml dans l’exemple de pipeline train-score-eval avec composants inscrits définit un pipeline qui a trois sorties au niveau du pipeline. Vous pouvez utiliser la commande suivante pour définir les chemins de sortie personnalisé pour la sortie pipeline_job_trained_model.
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path

Télécharger des sorties
Vous pouvez télécharger des sorties au niveau du pipeline ou du composant.
Télécharger les sorties au niveau du pipeline
Vous pouvez télécharger toutes les sorties d’un travail ou télécharger une sortie spécifique.
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download a specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>

Télécharger les sorties de composant
Pour télécharger les sorties d’un composant enfant, commencez par répertorier tous les travaux enfants d’un travail de pipeline, puis utilisez du code similaire pour télécharger les sorties.
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select the desired child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
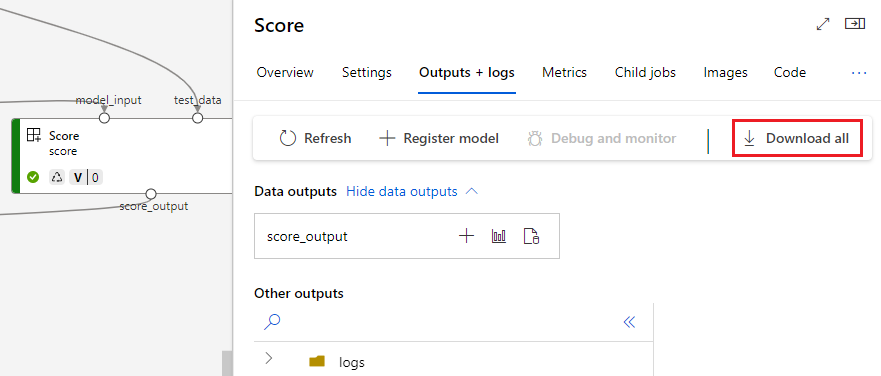
Inscrire la sortie en tant que ressource nommée
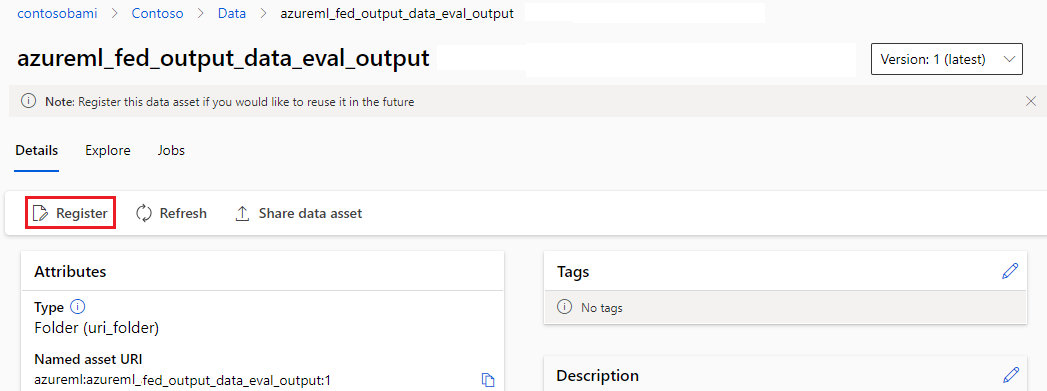
Vous pouvez inscrire la sortie d’un composant ou d’un pipeline en tant que ressource nommée en affectant un name et une version à la sortie. La ressource inscrite peut être listée dans votre espace de travail par le biais de l’interface utilisateur studio, de l’interface CLI ou du SDK et également être référencée dans vos travaux d’espace de travail futurs.
Inscrire la sortie au niveau du pipeline
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster
Inscrire la sortie du composant
display_name: register_node_output
type: pipeline
jobs:
node:
type: command
component: ../components/helloworld_component.yml
inputs:
component_in_path:
type: uri_file
path: 'https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
outputs:
component_out_path:
type: uri_folder
name: 'node_output' # Define name and version to register a child job's output
version: '1'
settings:
default_compute: azureml:cpu-cluster