Dans cet article, vous apprenez à utiliser ONNX (Open Neural Network Exchange) pour effectuer des prédictions sur des modèles de vision par ordinateur générés par le ML automatisé (AutoML) dans Azure Machine Learning.
Pour utiliser ONNX pour les prédictions, vous devez :
Télécharger les fichiers de modèle ONNX à partir d’une exécution d’entraînement AutoML.
Comprendre les entrées et les sorties d’un modèle ONNX.
Prétraiter vos données afin qu’elles soient au format requis pour les images d’entrée.
Procéder à l’inférence avec le runtime ONNX pour Python.
Visualiser les prédictions de la détection d’objets et les tâches de segmentation d’instances.
ONNX est une norme ouverte pour les modèles de machine learning et de deep learning. Elle permet l’importation et l’exportation (interopérabilité) des modèles sur les infrastructures d’IA populaires. Pour plus de détails, explorez le projet ONNX GitHub.
Le Runtime ONNX est un projet open source qui prend en charge l’inférence multiplateforme. Le runtime ONNX fournit des API sur des langages de programmation (notamment Python, C++, C#, C, Java et JavaScript). Vous pouvez utiliser ces API pour effectuer une inférence sur les images d’entrée. Une fois que le modèle a été exporté au format ONNX, vous pouvez utiliser ces API sur n’importe quel langage de programmation dont votre projet a besoin.
Dans ce guide, vous apprenez à utiliser les API Python pour le runtime ONNX afin d’effectuer des prédictions sur des images pour des tâches de vision populaires. Vous pouvez utiliser ces modèles exportés par ONNX dans différents langages.
Installez le package onnxruntime. Les méthodes décrites dans cet article ont été testées avec les versions 1.3.0 à 1.8.0.
Télécharger les fichiers de modèle ONNX
Vous pouvez télécharger les fichiers de modèle ONNX à partir d’une exécution AutoML à l’aide de l’interface utilisateur Azure Machine Learning studio ou du kit de développement logiciel (SDK) Python Azure Machine Learning. Nous vous recommandons de les télécharger via le kit de développement logiciel (SDK) avec le nom de l’expérience et l’ID d’exécution parent.
Azure Machine Learning Studio
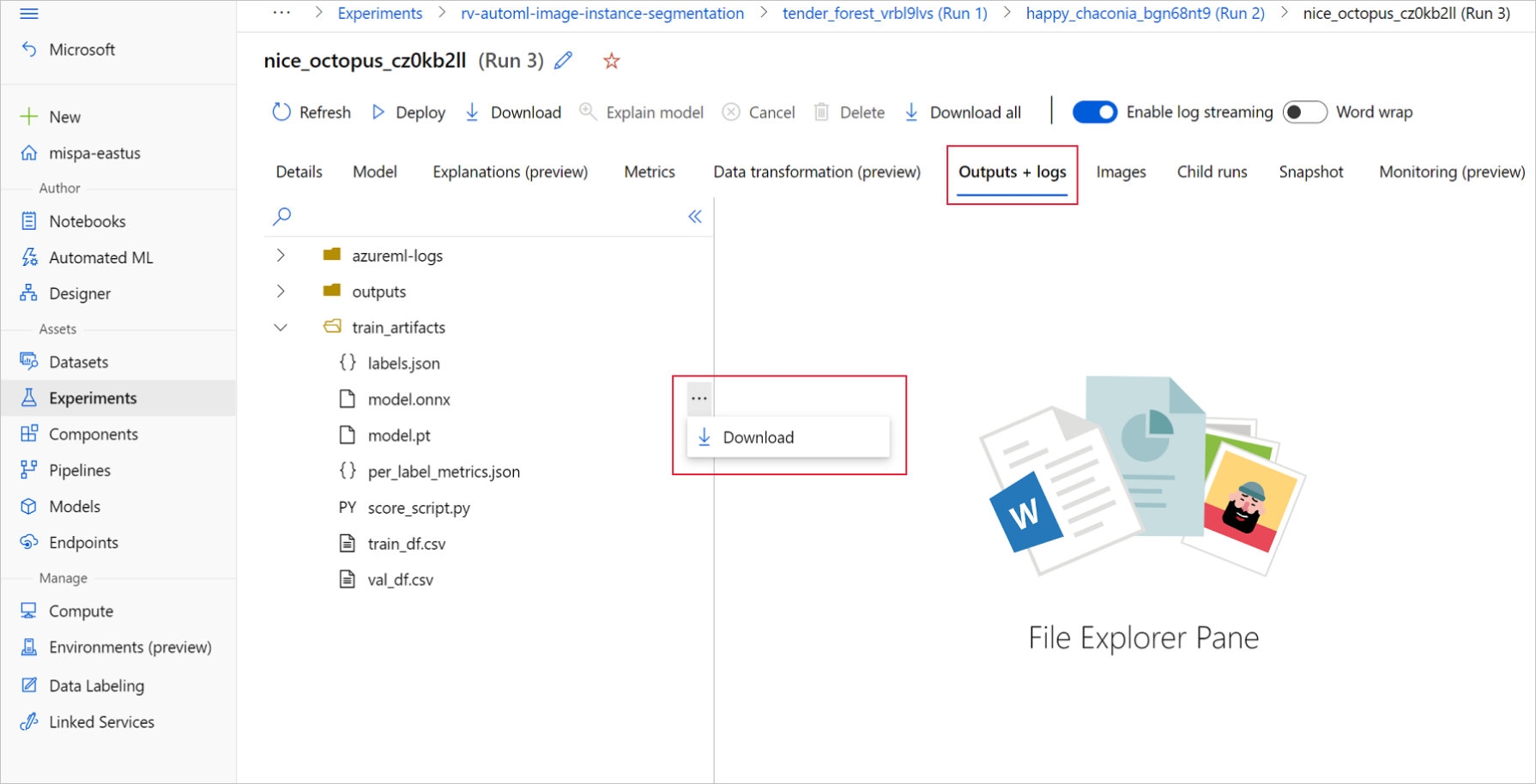
Dans Azure Machine Learning studio, accédez à votre expérience en utilisant le lien hypertexte vers l’expérience générée dans le notebook de formation, ou en sélectionnant le nom de l’expérience dans l’onglet Expériences sous Ressources. Sélectionnez ensuite la meilleure exécution enfant.
Dans la meilleure exécution enfant, accédez à Sorties + journaux>train_artifacts. Utilisez le bouton Télécharger pour télécharger manuellement les fichiers suivants :
labels.json : fichier qui contient toutes les classes ou étiquettes du jeu de données d’apprentissage.
model.onnx : modèle au format ONNX.
Enregistrez les fichiers de modèle téléchargés dans un répertoire. L’exemple de cet article utilise le répertoire ./automl_models.
SDK Python Azure Machine Learning
Avec le kit de développement logiciel (SDK), vous pouvez sélectionner la meilleure expérience enfant (par métrique principale) avec le nom de l’expérience et l’ID d’exécution parent. Ensuite, vous pouvez télécharger les fichiers labels.json et model.onnx.
Le code suivant retourne la meilleure expérience enfant en fonction de la métrique principale pertinente.
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
mlflow_client = MlflowClient()
credential = DefaultAzureCredential()
ml_client = None
try:
ml_client = MLClient.from_config(credential)
except Exception as ex:
print(ex)
# Enter details of your Azure Machine Learning workspace
subscription_id = ''
resource_group = ''
workspace_name = ''
ml_client = MLClient(credential, subscription_id, resource_group, workspace_name)
import mlflow
from mlflow.tracking.client import MlflowClient
# Obtain the tracking URL from MLClient
MLFLOW_TRACKING_URI = ml_client.workspaces.get(
name=ml_client.workspace_name
).mlflow_tracking_uri
mlflow.set_tracking_uri(MLFLOW_TRACKING_URI)
# Specify the job name
job_name = ''
# Get the parent run
mlflow_parent_run = mlflow_client.get_run(job_name)
best_child_run_id = mlflow_parent_run.data.tags['automl_best_child_run_id']
# get the best child run
best_run = mlflow_client.get_run(best_child_run_id)
Téléchargez le fichier labels.json qui contient toutes les classes et étiquettes du jeu de données d’apprentissage.
local_dir = './automl_models'
if not os.path.exists(local_dir):
os.mkdir(local_dir)
labels_file = mlflow_client.download_artifacts(
best_run.info.run_id, 'train_artifacts/labels.json', local_dir
)
En cas d’inférence par lots pour la détection d’objets et la segmentation d’instance à l’aide de modèles ONNX, reportez-vous à la section relative à la génération de modèles pour le scoring par lots.
Génération de modèle pour la notation par lots
Par défaut, AutoML pour les images prend en charge le scoring par lots pour la classification. Mais les modèles ONNX de détection d’objets et de segmentation d’instances ne prennent pas en charge l’inférence par lots. En cas d’inférence par lots pour la détection d’objets et la segmentation d’instances, utilisez la procédure suivante pour générer un modèle ONNX pour la taille de lot requise. Les modèles générés pour une taille de lot spécifique ne fonctionnent pas pour d’autres tailles de lot.
Téléchargez le fichier d’environnement conda et créez un objet d’environnement à utiliser avec le travail de commande.
# Download conda file and define the environment
conda_file = mlflow_client.download_artifacts(
best_run.info.run_id, "outputs/conda_env_v_1_0_0.yml", local_dir
)
from azure.ai.ml.entities import Environment
env = Environment(
name="automl-images-env-onnx",
description="environment for automl images ONNX batch model generation",
image="mcr.microsoft.com/azureml/openmpi4.1.0-cuda11.1-cudnn8-ubuntu18.04",
conda_file=conda_file,
)
Pour récupérer les valeurs d’argument nécessaires à la création du modèle de notation par lots, consultez les scripts de notation générés dans le dossier des sorties des exécutions de formation AutoML. Utilisez les valeurs d’hyperparamètres disponibles dans la variable de paramètres de modèle dans le fichier de notation pour la meilleure exécution enfant.
Pour la classification d’images multiclasse, le modèle ONNX généré pour la meilleure exécution enfant prend en charge la notation par lots par défaut. Par conséquent, aucun argument spécifique au modèle n’est nécessaire pour ce type de tâche et vous pouvez passer à la section Charger les étiquettes et les fichiers de modèle ONNX.
Pour la classification d’images multiclasse, le modèle ONNX généré pour la meilleure exécution enfant prend en charge la notation par lots par défaut. Par conséquent, aucun argument spécifique au modèle n’est nécessaire pour ce type de tâche et vous pouvez passer à la section Charger les étiquettes et les fichiers de modèle ONNX.
inputs = {'model_name': 'fasterrcnn_resnet34_fpn', # enter the faster rcnn or retinanet model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
inputs = {'model_name': 'yolov5', # enter the yolo model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 640, # enter the height of input to ONNX model
'width_onnx': 640, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-object-detection',
'img_size': 640, # image size for inference
'model_size': 'small', # size of the yolo model
'box_score_thresh': 0.1, # threshold to return proposals with a classification score > box_score_thresh
'box_iou_thresh': 0.5
}
inputs = {'model_name': 'maskrcnn_resnet50_fpn', # enter the maskrcnn model name
'batch_size': 8, # enter the batch size of your choice
'height_onnx': 600, # enter the height of input to ONNX model
'width_onnx': 800, # enter the width of input to ONNX model
'job_name': job_name,
'task_type': 'image-instance-segmentation',
'min_size': 600, # minimum size of the image to be rescaled before feeding it to the backbone
'max_size': 1333, # maximum size of the image to be rescaled before feeding it to the backbone
'box_score_thresh': 0.3, # threshold to return proposals with a classification score > box_score_thresh
'box_nms_thresh': 0.5, # NMS threshold for the prediction head
'box_detections_per_img': 100 # maximum number of detections per image, for all classes
}
Téléchargez et conservez le fichier ONNX_batch_model_generator_automl_for_images.py dans le répertoire actif pour envoyer le script. Utilisez le travail de commande suivant pour envoyer le script ONNX_batch_model_generator_automl_for_images.py disponible dans le référentiel GitHub azureml-examples, afin de générer un modèle ONNX d’une taille de lot spécifique. Dans le code suivant, l’environnement de modèle entraîné est utilisé pour envoyer ce script afin de générer et d’enregistrer le modèle ONNX dans le répertoire des sorties.
Pour la classification d’images multiclasse, le modèle ONNX généré pour la meilleure exécution enfant prend en charge la notation par lots par défaut. Par conséquent, aucun argument spécifique au modèle n’est nécessaire pour ce type de tâche et vous pouvez passer à la section Charger les étiquettes et les fichiers de modèle ONNX.
Pour la classification d’images multiclasse, le modèle ONNX généré pour la meilleure exécution enfant prend en charge la notation par lots par défaut. Par conséquent, aucun argument spécifique au modèle n’est nécessaire pour ce type de tâche et vous pouvez passer à la section Charger les étiquettes et les fichiers de modèle ONNX.
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-rcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --img_size ${{inputs.img_size}} --model_size ${{inputs.model_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_iou_thresh ${{inputs.box_iou_thresh}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
from azure.ai.ml import command
job = command(
code="./onnx_generator_files", # local path where the code is stored
command="python ONNX_batch_model_generator_automl_for_images.py --model_name ${{inputs.model_name}} --batch_size ${{inputs.batch_size}} --height_onnx ${{inputs.height_onnx}} --width_onnx ${{inputs.width_onnx}} --job_name ${{inputs.job_name}} --task_type ${{inputs.task_type}} --min_size ${{inputs.min_size}} --max_size ${{inputs.max_size}} --box_score_thresh ${{inputs.box_score_thresh}} --box_nms_thresh ${{inputs.box_nms_thresh}} --box_detections_per_img ${{inputs.box_detections_per_img}}",
inputs=inputs,
environment=env,
compute=compute_name,
display_name="ONNX-batch-model-generation-maskrcnn",
description="Use the PyTorch to generate ONNX batch scoring model.",
)
returned_job = ml_client.create_or_update(job)
ml_client.jobs.stream(returned_job.name)
Une fois le modèle de lot généré, téléchargez-le manuellement via l’interface utilisateur à partir de Sorties+journaux>sorties, ou utilisez la méthode suivante :
batch_size = 8 # use the batch size used to generate the model
returned_job_run = mlflow_client.get_run(returned_job.name)
# Download run's artifacts/outputs
onnx_model_path = mlflow_client.download_artifacts(
returned_job_run.info.run_id, 'outputs/model_'+str(batch_size)+'.onnx', local_dir
)
Après l’étape de téléchargement du modèle, utilisez le package Python du runtime ONNX pour effectuer une inférence à l’aide du fichier model.onnx. À des fins de démonstration, cet article utilise les jeux de données de la rubrique Comment préparer les jeux de données d’images pour chaque tâche de vision.
Nous avons entraîné les modèles pour toutes les tâches de vision avec leurs jeux de données respectifs afin d’illustrer l’inférence de modèle ONNX.
Charger les étiquettes et les fichiers de modèle ONNX
L’extrait de code suivant charge labels.json, dans lequel les noms de classe sont triés. Autrement dit, si le modèle ONNX prédit un ID d’étiquette de 2, il correspond au nom d’étiquette donné au troisième index du fichier labels.json.
import json
import onnxruntime
labels_file = "automl_models/labels.json"
with open(labels_file) as f:
classes = json.load(f)
print(classes)
try:
session = onnxruntime.InferenceSession(onnx_model_path)
print("ONNX model loaded...")
except Exception as e:
print("Error loading ONNX file: ", str(e))
Obtenir les détails d’entrée et de sortie attendus d’un modèle ONNX
Une fois que vous disposez du modèle, il est important de connaître certains détails spécifiques aux modèles et aux tâches. Ces détails incluent le nombre d’entrées et le nombre de sorties, la forme d’entrée ou le format attendu pour le prétraitement de l’image, ainsi que la forme de sortie, afin de connaître les sorties spécifiques à un modèle ou à une tâche.
sess_input = session.get_inputs()
sess_output = session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
for idx, input_ in enumerate(range(len(sess_input))):
input_name = sess_input[input_].name
input_shape = sess_input[input_].shape
input_type = sess_input[input_].type
print(f"{idx} Input name : { input_name }, Input shape : {input_shape}, \
Input type : {input_type}")
for idx, output in enumerate(range(len(sess_output))):
output_name = sess_output[output].name
output_shape = sess_output[output].shape
output_type = sess_output[output].type
print(f" {idx} Output name : {output_name}, Output shape : {output_shape}, \
Output type : {output_type}")
Formats d’entrée et de sortie attendus pour le modèle ONNX
Chaque modèle ONNX a un ensemble prédéfini de formats d’entrée et de sortie.
Cet exemple applique le modèle formé sur le jeu de données fridgeObjects de 134 images et 4 classes/étiquettes pour expliquer l’inférence de modèle ONNX. Pour plus d’informations sur l’apprentissage d’une tâche de classification d’images, consultez le notebook d’images multiclasses.
Format d’entrée
L’entrée est une image prétraitée.
Nom d’entrée
Forme d’entrée
Type d’entrée
Description
input1
(batch_size, num_channels, height, width)
ndarray(float)
L’entrée est une image prétraitée, avec la forme (1, 3, 224, 224) pour une taille de lot de 1, et une hauteur et une largeur de 224. Ces chiffres correspondent aux valeurs utilisées pour crop_size dans l’exemple d’apprentissage.
Format de sortie
La sortie est un tableau de logits pour toutes les classes/étiquettes.
Nom de sortie
Forme de sortie
Type de sortie
Description
output1
(batch_size, num_classes)
ndarray(float)
Le modèle retourne logits (sans softmax). Par exemple, pour les classes de taille de lot 1 et 4, il retourne (1, 4).
L’entrée est une image prétraitée, avec la forme (1, 3, 224, 224) pour une taille de lot de 1, et une hauteur et une largeur de 224. Ces chiffres correspondent aux valeurs utilisées pour crop_size dans l’exemple d’apprentissage.
Format de sortie
La sortie est un tableau de logits pour toutes les classes/étiquettes.
Nom de sortie
Forme de sortie
Type de sortie
Description
output1
(batch_size, num_classes)
ndarray(float)
Le modèle retourne logits (sans sigmoid). Par exemple, pour les classes de taille de lot 1 et 4, il retourne (1, 4).
Cet exemple de détection d’objets utilise le modèle formé sur le jeu de données de détection fridgeObjects de 128 images et 4 classes/étiquettes pour expliquer l’inférence de modèle ONNX. Cet exemple entraîne des modèles Faster R-CNN plus rapides pour illustrer les étapes d’inférence. Pour plus d’informations sur l’apprentissage des modèles de détection d’objets, consultez le notebook de détection d'objet.
Format d’entrée
L’entrée est une image prétraitée.
Nom d’entrée
Forme d’entrée
Type d’entrée
Description
Entrée
(batch_size, num_channels, height, width)
ndarray(float)
L’entrée est une image prétraitée, avec la forme (1, 3, 600, 800) pour une taille de lot de 1, une hauteur de 600 et une largeur de 800.
Format de sortie
La sortie est un tuple de output_names et des prédictions. Ici, output_names et predictions sont des listes dont la longueur est égale à 3*batch_size chacune. Pour Faster R-CNN, l’ordre des sorties est zones, étiquettes et scores, tandis que l’ordre des sorties RetinaNet est zones, scores et étiquettes.
Nom de sortie
Forme de sortie
Type de sortie
Description
output_names
(3*batch_size)
Liste de clés
Pour une taille de lot de 2, output_names est ['boxes_0', 'labels_0', 'scores_0', 'boxes_1', 'labels_1', 'scores_1']
predictions
(3*batch_size)
Liste des ndarray(float)
Pour une taille de lot de 2, predictions prend la forme [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n2_boxes, 4), (n2_boxes), (n2_boxes)]. Ici, les valeurs de chaque index correspondent au même index dans output_names.
Le tableau suivant décrit les zones, les étiquettes et les scores renvoyés pour chaque échantillon dans le lot d’images.
Nom
Forme
Type
Description
Zones
(n_boxes, 4), où chaque zone a x_min, y_min, x_max, y_max
ndarray(float)
Le modèle renvoie n zones avec leurs coordonnées en haut à gauche et en bas à droite.
Étiquettes
(n_boxes)
ndarray(float)
ID d’étiquette ou de classe d’un objet dans chaque zone.
Scores
(n_boxes)
ndarray(float)
Score de confiance d’un objet dans chaque zone.
Cet exemple de détection d’objets utilise le modèle formé sur le jeu de données de détection fridgeObjects de 128 images et 4 classes/étiquettes pour expliquer l’inférence de modèle ONNX. Cet exemple entraîne des modèles R-CNN plus rapides pour illustrer les étapes d’inférence. Pour plus d’informations sur l’apprentissage des modèles de détection d’objets, consultez le notebook de détection d'objet.
Format d’entrée
L’entrée est une image prétraitée, avec la forme (1, 3, 640, 640) pour une taille de lot de 1, et une hauteur et une largeur de 640. Ces chiffres correspondent aux valeurs utilisées dans l’exemple d’apprentissage.
Nom d’entrée
Forme d’entrée
Type d’entrée
Description
Entrée
(batch_size, num_channels, height, width)
ndarray(float)
L’entrée est une image prétraitée, avec la forme (1, 3, 640, 640) pour une taille de lot de 1, une hauteur de 640 et une largeur de 640.
Format de sortie
Les prédictions de modèle ONNX contiennent plusieurs sorties. La première sortie est nécessaire afin d’effectuer une suppression non maximale pour les détections. Pour faciliter l’utilisation, le ML automatisé affiche le format de sortie après l’étape de post-traitement NMS. La sortie après NMS est une liste de zones, d’étiquettes et de scores pour chaque échantillon dans le lot.
Nom de sortie
Forme de sortie
Type de sortie
Description
Sortie
(batch_size)
Liste des ndarray(float)
Le modèle retourne des détections de zones pour chaque échantillon dans le lot
Chaque cellule de la liste indique des détections de zone d’un échantillon avec la forme (n_boxes, 6), où chaque zone a x_min, y_min, x_max, y_max, confidence_score, class_id.
Pour cet exemple de segmentation d’instance, utilisez le modèle Mask R-CNN qui a été formé sur le jeu de données fridgeObjects avec 128 images et 4 classes/étiquettes pour expliquer l’inférence de modèle ONNX. Pour plus d’informations sur l’apprentissage du modèle de segmentation d’instance, consultez le notebook sur la segmentation d’instance.
Important
Seul le modèle Mask R-CNN est pris en charge pour les tâches de segmentation d’instance. Les formats d’entrée et de sortie sont basés uniquement sur le modèle Mask R-CNN.
Format d’entrée
L’entrée est une image prétraitée. Le modèle ONNX pour Mask R-CNN a été exporté pour fonctionner avec des images de différentes formes. Pour de meilleures performances, nous vous recommandons de les redimensionner sur une taille fixe cohérente avec des tailles d’images de formation.
Nom d’entrée
Forme d’entrée
Type d’entrée
Description
Entrée
(batch_size, num_channels, height, width)
ndarray(float)
L’entrée est une image prétraitée, avec la forme (1, 3, input_image_height, input_image_width) pour une taille de lot de 1, et une hauteur et une largeur similaires à celles d’une image d’entrée.
Format de sortie
La sortie est un tuple de output_names et des prédictions. Ici, output_names et predictions sont des listes dont la longueur est égale à 4*batch_size chacune.
Nom de sortie
Forme de sortie
Type de sortie
Description
output_names
(4*batch_size)
Liste de clés
Pour une taille de lot de 2, output_names est ['boxes_0', 'labels_0', 'scores_0', 'masks_0', 'boxes_1', 'labels_1', 'scores_1', 'masks_1']
predictions
(4*batch_size)
Liste des ndarray(float)
Pour une taille de lot de 2, predictions prend la forme [(n1_boxes, 4), (n1_boxes), (n1_boxes), (n1_boxes, 1, height_onnx, width_onnx), (n2_boxes, 4), (n2_boxes), (n2_boxes), (n2_boxes, 1, height_onnx, width_onnx)]. Ici, les valeurs de chaque index correspondent au même index dans output_names.
Nom
Forme
Type
Description
Zones
(n_boxes, 4), où chaque zone a x_min, y_min, x_max, y_max
ndarray(float)
Le modèle renvoie n zones avec leurs coordonnées en haut à gauche et en bas à droite.
Étiquettes
(n_boxes)
ndarray(float)
ID d’étiquette ou de classe d’un objet dans chaque zone.
Scores
(n_boxes)
ndarray(float)
Score de confiance d’un objet dans chaque zone.
Masques
(n_boxes, 1, height_onnx, width_onnx)
ndarray(float)
Masques (polygones) des objets détectés avec la hauteur et la largeur de la forme d’une image d’entrée.
Effectuez les étapes de prétraitement suivantes pour l’inférence de modèle ONNX :
Convertissez l’image en RVB.
Redimensionnez l’image avec les valeurs valid_resize_size et valid_resize_size qui correspondent aux valeurs utilisées dans la transformation du jeu de données de validation au cours de l’apprentissage. La valeur par défaut pour valid_resize_size est 256.
Rognez et centrez l’image sur height_onnx_crop_size et width_onnx_crop_size. Cela correspond à valid_crop_size avec la valeur par défaut de 224.
Remplacez HxWxC par CxHxW.
Convertissez au type float.
Normalisez avec mean = [0.485, 0.456, 0.406] et std = [0.229, 0.224, 0.225] d’ImageNet.
Si vous avez choisi des valeurs différentes pour les hyperparamètresvalid_resize_size et valid_crop_size pendant l’apprentissage, ces valeurs doivent être utilisées.
Obtenez la forme d’entrée nécessaire pour le modèle ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Avec PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_cls/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Effectuez les étapes de prétraitement suivantes pour l’inférence de modèle ONNX. Ces étapes sont les mêmes pour la classification d’images multi-classe.
Convertissez l’image en RVB.
Redimensionnez l’image avec les valeurs valid_resize_size et valid_resize_size qui correspondent aux valeurs utilisées dans la transformation du jeu de données de validation au cours de l’apprentissage. La valeur par défaut pour valid_resize_size est 256.
Rognez et centrez l’image sur height_onnx_crop_size et width_onnx_crop_size. Cela correspond à valid_crop_size avec une valeur par défaut de 224.
Remplacez HxWxC par CxHxW.
Convertissez au type float.
Normalisez avec mean = [0.485, 0.456, 0.406] et std = [0.229, 0.224, 0.225] d’ImageNet.
Si vous avez choisi des valeurs différentes pour les hyperparamètresvalid_resize_size et valid_crop_size pendant l’apprentissage, ces valeurs doivent être utilisées.
Obtenez la forme d’entrée nécessaire pour le modèle ONNX.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
# resize
image = image.resize((resize_size, resize_size))
# center crop
left = (resize_size - crop_size_onnx)/2
top = (resize_size - crop_size_onnx)/2
right = (resize_size + crop_size_onnx)/2
bottom = (resize_size + crop_size_onnx)/2
image = image.crop((left, top, right, bottom))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Avec PyTorch
import glob
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
def _make_3d_tensor(x) -> torch.Tensor:
"""This function is for images that have less channels.
:param x: input tensor
:type x: torch.Tensor
:return: return a tensor with the correct number of channels
:rtype: torch.Tensor
"""
return x if x.shape[0] == 3 else x.expand((3, x.shape[1], x.shape[2]))
def preprocess(image, resize_size, crop_size_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_size: value to resize the image
:type image: Int
:param crop_size_onnx: expected height of an input image in onnx model
:type crop_size_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
transform = transforms.Compose([
transforms.Resize(resize_size),
transforms.CenterCrop(crop_size_onnx),
transforms.ToTensor(),
transforms.Lambda(_make_3d_tensor),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
img_data = transform(image)
img_data = img_data.numpy()
img_data = np.expand_dims(img_data, axis=0)
return img_data
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_multi_label/test_images_dir/*" # replace with path to images
# Select batch size needed
batch_size = 8
# you can modify resize_size based on your trained model
resize_size = 256
# height and width will be the same for classification
crop_size_onnx = height_onnx_crop_size
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, resize_size, crop_size_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Pour la détection d’objets avec l’architecture Faster R-CNN, suivez les mêmes étapes de prétraitement que pour la classification d’images, à l’exception du rognage d’image. Vous pouvez redimensionner l’image en définissant la hauteur 600 et la largeur 800. Vous pouvez obtenir la hauteur et la largeur attendues avec le code suivant.
import glob
import numpy as np
from PIL import Image
def preprocess(image, height_onnx, width_onnx):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param height_onnx: expected height of an input image in onnx model
:type height_onnx: Int
:param width_onnx: expected width of an input image in onnx model
:type width_onnx: Int
:return: pre-processed image in numpy format
:rtype: ndarray 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((width_onnx, height_onnx))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:] / 255 - mean_vec[i]) / std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
test_images_path = "automl_models_od/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Pour la détection d’objets avec l’architecture YOLO, suivez les mêmes étapes de prétraitement que pour la classification d’images, à l’exception du rognage d’image. Vous pouvez redimensionner l’image avec la hauteur 600 et la largeur 800 et récupérer la hauteur et la largeur d’entrée attendues avec le code suivant.
import glob
import numpy as np
from yolo_onnx_preprocessing_utils import preprocess
# use height and width based on the generated model
test_images_path = "automl_models_od_yolo/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
pad_list = []
for i in range(batch_size):
img_processed, pad = preprocess(image_files[i])
img_processed_list.append(img_processed)
pad_list.append(pad)
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Important
Seul le modèle Mask R-CNN est pris en charge pour les tâches de segmentation d’instance. Les étapes de prétraitement sont basées uniquement sur le modèle Mask R-CNN.
Effectuez les étapes de prétraitement suivantes pour l’inférence de modèle ONNX :
Convertissez l’image en RVB.
Redimensionnez l’image.
Remplacez HxWxC par CxHxW.
Convertissez au type float.
Normalisez avec mean = [0.485, 0.456, 0.406] et std = [0.229, 0.224, 0.225] d’ImageNet.
Pour resize_height et resize_width, vous pouvez également utiliser les valeurs que vous avez utilisées lors de l’apprentissage, limitées par les hyperparamètresmin_size et max_size pour Mask R-CNN.
import glob
import numpy as np
from PIL import Image
def preprocess(image, resize_height, resize_width):
"""Perform pre-processing on raw input image
:param image: raw input image
:type image: PIL image
:param resize_height: resize height of an input image
:type resize_height: Int
:param resize_width: resize width of an input image
:type resize_width: Int
:return: pre-processed image in numpy format
:rtype: ndarray of shape 1xCxHxW
"""
image = image.convert('RGB')
image = image.resize((resize_width, resize_height))
np_image = np.array(image)
# HWC -> CHW
np_image = np_image.transpose(2, 0, 1) # CxHxW
# normalize the image
mean_vec = np.array([0.485, 0.456, 0.406])
std_vec = np.array([0.229, 0.224, 0.225])
norm_img_data = np.zeros(np_image.shape).astype('float32')
for i in range(np_image.shape[0]):
norm_img_data[i,:,:] = (np_image[i,:,:]/255 - mean_vec[i])/std_vec[i]
np_image = np.expand_dims(norm_img_data, axis=0) # 1xCxHxW
return np_image
# following code loads only batch_size number of images for demonstrating ONNX inference
# make sure that the data directory has at least batch_size number of images
# use height and width based on the trained model
# use height and width based on the generated model
test_images_path = "automl_models_is/test_images_dir/*" # replace with path to images
image_files = glob.glob(test_images_path)
img_processed_list = []
for i in range(batch_size):
img = Image.open(image_files[i])
img_processed_list.append(preprocess(img, height_onnx, width_onnx))
if len(img_processed_list) > 1:
img_data = np.concatenate(img_processed_list)
elif len(img_processed_list) == 1:
img_data = img_processed_list[0]
else:
img_data = None
assert batch_size == img_data.shape[0]
Inférence avec le runtime ONNX
L’inférence avec le runtime ONNX diffère pour chaque tâche de vision par ordinateur.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: scores with shapes
(1, No. of classes in training dataset)
:rtype: numpy array
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
print(f"No. of inputs : {len(sess_input)}, No. of outputs : {len(sess_output)}")
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
scores = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return scores[0]
scores = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session, img_data):
"""perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
(No. of boxes, 4) (No. of boxes,) (No. of boxes,)
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
def get_predictions_from_ONNX(onnx_session,img_data):
"""perform predictions with ONNX Runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores
:rtype: list
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
pred = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return pred[0]
result = get_predictions_from_ONNX(session, img_data)
Le modèle de segmentation d’instance prédit les zones, les étiquettes, les scores et les masques. ONNX génère un masque prédit par instance, ainsi que des zones englobantes et un score de confiance de classe correspondants. Vous devrez peut-être convertir le masque binaire en polygone si nécessaire.
def get_predictions_from_ONNX(onnx_session, img_data):
"""Perform predictions with ONNX runtime
:param onnx_session: onnx model session
:type onnx_session: class InferenceSession
:param img_data: pre-processed numpy image
:type img_data: ndarray with shape 1xCxHxW
:return: boxes, labels , scores , masks with shapes
(No. of instances, 4) (No. of instances,) (No. of instances,)
(No. of instances, 1, HEIGHT, WIDTH))
:rtype: tuple
"""
sess_input = onnx_session.get_inputs()
sess_output = onnx_session.get_outputs()
# predict with ONNX Runtime
output_names = [ output.name for output in sess_output]
predictions = onnx_session.run(output_names=output_names,\
input_feed={sess_input[0].name: img_data})
return output_names, predictions
output_names, predictions = get_predictions_from_ONNX(session, img_data)
Appliquez softmax() à des valeurs prédites pour obtenir des scores de confiance de classification (probabilités) pour chaque classe. La prédiction sera la classe ayant la probabilité la plus élevée.
conf_scores = torch.nn.functional.softmax(torch.from_numpy(scores), dim=1)
class_preds = torch.argmax(conf_scores, dim=1)
print("predicted classes:", ([(class_idx.item(), classes[class_idx]) for class_idx in class_preds]))
Cette étape diffère de la classification multiclasse. Vous devez appliquer sigmoid à logits (sortie ONNX) pour obtenir des scores de confiance pour la classification d’images à plusieurs étiquettes.
Sans PyTorch
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = sigmoid(scores)
image_wise_preds = np.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Avec PyTorch
# we apply a threshold of 0.5 on confidence scores
score_threshold = 0.5
conf_scores = torch.sigmoid(torch.from_numpy(scores))
image_wise_preds = torch.where(conf_scores > score_threshold)
for image_idx, class_idx in zip(image_wise_preds[0], image_wise_preds[1]):
print('image: {}, class_index: {}, class_name: {}'.format(image_files[image_idx], class_idx, classes[class_idx]))
Pour une classification multiclasse et à plusieurs étiquettes, vous pouvez suivre les mêmes étapes que celles mentionnées plus haut pour toutes les architectures prises en charge par AutoML.
Pour la détection d’objets, les prédictions sont automatiquement sur l’échelle de height_onnx, width_onnx. Pour transformer les coordonnées de zone prédites en dimensions d’origine, vous pouvez implémenter les calculs suivants.
Xmin * original_width/width_onnx
Ymin * original_height/height_onnx
Xmax * original_width/width_onnx
Ymax * original_height/height_onnx
Une autre option consiste à utiliser le code suivant pour mettre à l’échelle les dimensions de la zone afin qu’elles soient comprises dans la plage [0, 1]. Cela permet de multiplier les coordonnées de la zone avec la hauteur et la largeur des images d’origine par les coordonnées respectives (comme décrit dans la section de visualisation des prédictions) pour obtenir des zones dans les dimensions d’image d’origine.
def _get_box_dims(image_shape, box):
box_keys = ['topX', 'topY', 'bottomX', 'bottomY']
height, width = image_shape[0], image_shape[1]
box_dims = dict(zip(box_keys, [coordinate.item() for coordinate in box]))
box_dims['topX'] = box_dims['topX'] * 1.0 / width
box_dims['bottomX'] = box_dims['bottomX'] * 1.0 / width
box_dims['topY'] = box_dims['topY'] * 1.0 / height
box_dims['bottomY'] = box_dims['bottomY'] * 1.0 / height
return box_dims
def _get_prediction(boxes, labels, scores, image_shape, classes):
bounding_boxes = []
for box, label_index, score in zip(boxes, labels, scores):
box_dims = _get_box_dims(image_shape, box)
box_record = {'box': box_dims,
'label': classes[label_index],
'score': score.item()}
bounding_boxes.append(box_record)
return bounding_boxes
# Filter the results with threshold.
# Please replace the threshold for your test scenario.
score_threshold = 0.8
filtered_boxes_batch = []
for batch_sample in range(0, batch_size*3, 3):
# in case of retinanet change the order of boxes, labels, scores to boxes, scores, labels
# confirm the same from order of boxes, labels, scores output_names
boxes, labels, scores = predictions[batch_sample], predictions[batch_sample + 1], predictions[batch_sample + 2]
bounding_boxes = _get_prediction(boxes, labels, scores, (height_onnx, width_onnx), classes)
filtered_bounding_boxes = [box for box in bounding_boxes if box['score'] >= score_threshold]
filtered_boxes_batch.append(filtered_bounding_boxes)
Le code suivant crée des zones, des étiquettes et des scores. Utilisez les détails de la zone limitée pour effectuer les mêmes étapes de post-traitement que pour le modèle Faster R-CNN.
Vous pouvez utiliser les étapes indiquées pour Faster R-CNN (dans le cas de Mask R-CNN, chaque exemple comporte quatre éléments : zones, étiquettes, scores et masques) ou consultez la section de visualisation des prédictions pour la segmentation d’instances.
 Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)
Kit de développement logiciel (SDK) Python azure-ai-mlv2 (préversion)