Configurer AutoML pour effectuer l'apprentissage des modèles de vision par ordinateur
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Dans cet article, vous allez apprendre à former des modèles de vision par ordinateur sur des données d’image avec le ML automatisé. Vous pouvez former des modèles à l’aide de l’extension CLI Azure Machine Learning v2 ou du kit de développement logiciel (SDK) Python Azure Machine Learning v2.
Le ML automatisé prend en charge l’entraînement de modèles pour les tâches de vision par ordinateur telles que la classification d’images, la détection d’objets et la segmentation d’instances. La création de modèles AutoML pour les tâches de vision par ordinateur est actuellement prise en charge via le kit SDK Python Azure Machine Learning. Les essais, modèles et sorties des expérimentations sont accessibles dans l’interface utilisateur du studio Azure Machine Learning. En savoir plus sur le ML automatisé pour les tâches de vision par ordinateur sur les données d’image.
Prérequis
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
- Un espace de travail Azure Machine Learning. Pour créer l’espace de travail, consultez Créer des ressources d’espace de travail.
- Installez et configurez la CLI (v2), et assurez-vous que vous installez l’extension
ml.
Sélectionner votre type de tâche
Le ML automatisé pour les images prend en charge les types de tâches suivants :
| Type de tâche | Syntaxe du travail AutoML |
|---|---|
| classification d’image | CLI v2 : image_classification Kit de développement logiciel (SDK) v2 : image_classification() |
| classification d’images multi-étiquette | CLI v2 : image_classification_multilabel Kit de développement logiciel (SDK) v2 : image_classification_multilabel() |
| détection d’objets image | CLI v2 : image_object_detection Kit de développement logiciel (SDK) v2 : image_object_detection() |
| segmentation d’instances d’image | CLI v2 : image_instance_segmentation Kit de développement logiciel (SDK) v2 : image_instance_segmentation() |
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
Ce type de tâche est un paramètre obligatoire et peut être défini à l’aide de la clé task.
Par exemple :
task: image_object_detection
Données de formation et de validation
Pour générer des modèles de vision par ordinateur, vous devez apporter les données d’image étiquetées comme entrées pour la formation de modèles sous la forme d’un MLTable. Vous pouvez créer un MLTable à partir de données de formation au format JSONL.
Si vos données d’entraînement sont dans un autre format (par exemple, pascal VOC ou COCO), vous pouvez appliquer les scripts d’assistance inclus avec les exemples de notebook pour convertir les données en JSONL. En savoir plus sur la préparation des données pour les tâches de vision par ordinateur avec le ML automatisé.
Notes
Le jeu de données de formation doit comporter au moins 10 images afin de pouvoir envoyer un travail AutoML.
Avertissement
La création de MLTable n’est prise en charge qu’avec le Kit de développement logiciel (SDK) et la CLI pour créer à partir de données au format JSONL pour cette fonctionnalité. La création de MLTable via l’interface utilisateur n’est pas prise en charge pour l’instant.
Exemples de schémas JSONL
La structure du TabularDataset dépend de la tâche en cours. Pour les types de tâche de vision par ordinateur, elle comprend les champs suivants :
| Champ | Description |
|---|---|
image_url |
Contient le chemin du fichier comme objet StreamInfo |
image_details |
Les informations de métadonnées d’image se composent de la hauteur, de la largeur et du format. Ce champ est facultatif et peut donc exister ou pas. |
label |
Représentation JSON de l’étiquette de l’image, en fonction du type de tâche. |
Le code suivant est un exemple de fichier JSONL pour la classification d’images :
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Le code suivant est un exemple de fichier JSONL pour la détection d’objets :
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Consommer les données
Une fois vos données au format JSONL, vous pouvez créer une formation et une validation MLTable comme indiqué ci-dessous.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Le ML automatisé n’impose aucune contrainte sur la taille des données de formation ou de validation pour les tâches de vision par ordinateur. La taille maximale d’un jeu de données n’est limitée que par la couche de stockage derrière le jeu de données (par exemple, un magasin d’objets blob). Il n’y a aucun nombre minimal d’images ou d’étiquettes. Toutefois, nous vous recommandons de commencer avec un minimum de 10-15 échantillons par étiquette pour vous assurer que le modèle de sortie est suffisamment formé. Plus le nombre total d’étiquettes/classes est élevé, plus vous avez besoin d’échantillons par étiquette.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
Les données d’apprentissage sont obligatoires et passées à l’aide de la clé training_data. Vous pouvez éventuellement spécifier un autre MLtable en tant que données de validation avec la clé validation_data. Si aucune donnée de validation n’est spécifiée, 20 % de vos données de formation sont utilisés pour la validation par défaut, sauf si vous transmettez l’argument validation_data_size avec une valeur différente.
Le nom de colonne cible est un paramètre obligatoire et utilisé comme cible pour la tâche de ML supervisée. Il est passé à l’aide de la clé target_column_name. Par exemple,
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Capacité de calcul pour exécuter l’expérience
Fournissez une cible de calcul pour le ML automatisé afin de procéder à l’entraînement des modèles. Les modèles du ML automatisé pour les tâches de vision par ordinateur requièrent des références SKU GPU et prennent en charge les familles NC et ND. Nous recommandons d’utiliser la série NCsv3 (avec v100 GPU) pour accélérer l’entraînement. Une cible de calcul avec une référence SKU de machine virtuelle multi-GPU utilise plusieurs GPU pour accélérer l’entraînement également. De plus, lorsque vous configurez une cible de calcul avec plusieurs nœuds, vous pouvez procéder à un entraînement plus rapide des modèles via le parallélisme lors du réglage des hyperparamètres de votre modèle.
Notes
Si vous utilisez une instance de calcul comme cible de calcul, vérifiez que plusieurs travaux AutoML ne sont pas exécutés en même temps. En outre, assurez-vous que max_concurrent_trials est défini sur 1 dans vos limites de travail.
La cible de calcul est transmise à l’aide du paramètre compute. Par exemple :
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
compute: azureml:gpu-cluster
Configurer des expériences
Pour les tâches de vision par ordinateur, vous pouvez lancer des essais individuels, des balayages manuels ou des balayages automatiques. Nous vous recommandons de commencer par un balayage automatique pour obtenir un premier modèle de base. Ensuite, vous pouvez essayer des évaluations individuelles avec certains modèles et configurations d’hyperparamètres. Enfin, avec les balayages manuels, vous pouvez explorer plusieurs valeurs d’hyperparamètre près des modèles et des configurations d’hyperparamètres les plus prometteurs. Ce flux de travail en trois étapes (balayage automatique, essais individuels, balayages manuels) évite de rechercher l’intégralité de l’espace des hyperparamètres, qui augmente de façon exponentielle dans le nombre d’hyperparamètres.
Les balayages automatiques peuvent produire des résultats compétitifs pour de nombreux jeux de données. En outre, ils ne nécessitent pas de connaissances avancées sur les architectures de modèles, prennent en compte les corrélations d’hyperparamètres et fonctionnent en toute transparence sur différentes configurations matérielles. Toutes ces raisons en font une option forte pour le début de votre processus d’expérimentation.
Métrique principale
Un travail d’entraînement AutoML utilise une métrique principale pour l’optimisation du modèle et le réglage des hyperparamètres. La métrique principale dépend du type de tâche, comme indiqué ci-dessous ; les autres valeurs de métrique primaire ne sont actuellement pas prises en charge.
- Précision pour la classification d’images
- Intersection sur union pour la classification d’images avec plusieurs étiquettes
- Précision moyenne moyenne pour la détection d’objets image
- Précision moyenne moyenne pour la segmentation d’instances d’image
Limites du travail
Vous pouvez contrôler les ressources dépensées sur votre travail d’apprentissage d’image AutoML en spécifiant timeout_minutes, max_trials et max_concurrent_trials pour le travail dans les paramètres de limite comme décrit dans l’exemple ci-dessous.
| Paramètre | Détail |
|---|---|
max_trials |
Paramètre pour le nombre maximal d’évaluations à balayer. Doit être un entier compris entre 1 et 1000. Lorsque vous explorez juste les hyperparamètres par défaut d’une architecture de modèle donnée, affectez la valeur 1 à ce paramètre. La valeur par défaut est 1. |
max_concurrent_trials |
Nombre maximal d’évaluations pouvant se dérouler simultanément. En cas de spécification, doit être un entier compris entre 1 et 100. La valeur par défaut est 1. REMARQUE : max_concurrent_trials est limité à max_trialsen interne. Par exemple, si l’utilisateur définit max_concurrent_trials=4, max_trials=2, les valeurs sont mises à jour en interne en tant que max_concurrent_trials=2, max_trials=2. |
timeout_minutes |
Le temps en minutes avant la fin de l’expérience. Si aucune durée n’est spécifiée, le délai timeout_minutes par défaut de l’expérience est de sept jours (maximum 60 jours). |
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Balayage automatique des hyperparamètres de modèle (AutoMode)
Important
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Il est difficile de prévoir la meilleure architecture de modèle et les meilleurs hyperparamètres d’un jeu de données. En outre, dans certains cas, le temps humain alloué au réglage des hyperparamètres peut être limité. Pour les tâches de vision par ordinateur, vous pouvez spécifier le nombre d’essais souhaités et le système détermine automatiquement la région de l’espace hyperparamètre à balayer. Vous n’avez pas besoin de définir d’espace de recherche hyperparamètre, de méthode d’échantillonnage ou de stratégie d’arrêt anticipé.
Déclenchement de l’automode
Vous pouvez exécuter des balayages automatiques en définissant max_trials sur une valeur supérieure à 1 pouce dans limits et en ne spécifiant pas l’espace de recherche, la méthode d’échantillonnage et la stratégie d’arrêt. Nous appelons cette fonctionnalité AutoMode ; veuillez consulter l’exemple qui suit.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
limits:
max_trials: 10
max_concurrent_trials: 2
Un nombre d’essais compris entre 10 et 20 fonctionne généralement bien sur de nombreux jeux de données. Le budget de temps pour le travail AutoML peut toujours être défini, mais nous vous recommandons de le faire uniquement si chaque version d’évaluation peut prendre beaucoup de temps.
Avertissement
Le lancement de balayages automatiques via l’interface utilisateur n’est pas pris en charge pour le moment.
Essais individuels
Dans les évaluations individuelles, vous contrôlez directement l’architecture de modèle et les hyperparamètres. L’architecture du modèle est transmise par le paramètre model_name.
Architectures de modèle prises en charge
Le tableau suivant récapitule les modèles hérités pris en charge pour chaque tâche de vision par ordinateur. Utiliser uniquement ces modèles hérités déclenche des exécutions avec le runtime hérité (où chaque exécution ou essai individuel est soumis en tant que tâche de commande). Veuillez consulter la prise en charge HuggingFace et MMDetection ci-dessous.
| Tâche | Architectures de modèle | Syntaxe des littéraux de chaînedefault_model* indiqué par * |
|---|---|---|
| Classification d’images (multi-classe et multi-étiquette) |
MobileNet : modèles légers pour applications mobiles ResNet : réseaux résiduels ResNeSt : réseaux d’attention partagée SE-ResNeXt50 : réseaux de compression et excitation (Squeeze-and-Excitation) ViT : réseaux de transformateurs de vision |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (petit) vitb16r224* (base) vitl16r224 (grand) |
| Détection d’objets |
YOLOv5 : modèle de détection d’objets monophase Faster RCNN ResNet FPN : modèles de détection d’objets double-phase RetinaNet ResNet FPN : résolution du déséquilibre de classes avec la perte focale Remarque : Reportez-vous à l’hyperparamètre model_size pour les tailles de modèle YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentation d’instances | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Architectures de modèles prises en charge – HuggingFace et MMDetection
Avec le nouveau back-end qui s’exécute sur les pipelines Azure Machine Learning, vous pouvez également utiliser un modèle de classification d’images à partir du HuggingFace Hub qui fait partie de la bibliothèque de transformateurs (comme microsoft/beit-base-patch16-224), ainsi qu’un modèle de détection d’objet ou de segmentation d’instance de MMDetection Version 3.1.0 Model Zoo (par exemple, atss_r50_fpn_1x_coco).
En plus de prendre en charge tous les modèles HuggingFace Transfomers et MMDetection 3.1.0, nous proposons également une liste de modèles organisés à partir de ces bibliothèques dans le registre azureml. Ces modèles organisés ont été testés minutieusement et utilisent des hyperparamètres par défaut sélectionnés à partir d’une évaluation approfondie, pour garantir une formation efficace. Le tableau ci-dessous récapitule ces modèles organisés.
| Tâche | Architectures de modèle | Syntaxe des littéraux de chaîne |
|---|---|---|
| Classification d’images (multi-classe et multi-étiquette) |
BEiT ViT DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Détection d’objet |
Sparse R-CNN Deformable DETR VFNet YOLOF |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Segmentation d’instance | Mask R-CNN | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
Nous mettons constamment à jour la liste des modèles organisés. Vous pouvez obtenir la liste la plus récente des modèles organisés pour une tâche donnée à l’aide du kit de développement logiciel (SDK) Python :
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Sortie :
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
Utiliser un modèle HuggingFace ou MMDetection déclenche des exécutions à l’aide de composants de pipeline. Si les modèles hérités et HuggingFace/MMdetection sont utilisés, toutes les exécutions et tous les essais sont déclenchés à l’aide de composants.
En plus du contrôle de l’architecture du modèle, vous pouvez également régler les hyperparamètres utilisés pour l’entraînement du modèle. Même si un grand nombre des hyperparamètres exposés sont indépendants du modèle, il existe des cas où les hyperparamètres sont spécifiques à une tâche ou à un modèle. En savoir plus sur les hyperparamètres disponibles pour ces instances.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
Si vous souhaitez utiliser les valeurs d’hyperparamètres par défaut pour une architecture donnée (par exemple, yolov5), vous pouvez le spécifier à l’aide de la clé model_name de la section training_parameters. Par exemple,
training_parameters:
model_name: yolov5
Balayage manuel des hyperparamètres de modèle
Lors de l’entraînement des modèles de vision par ordinateur, les performances des modèles dépendent beaucoup des valeurs d’hyperparamètre sélectionnées. Souvent, vous voudrez probablement régler les hyperparamètres pour obtenir des performances optimales. Pour les tâches de vision par ordinateur, vous pouvez balayer les hyperparamètres pour trouver les paramètres optimaux pour votre modèle. Cette fonctionnalité applique les fonctions de réglage des hyperparamètres dans Azure Machine Learning. Apprenez à régler les hyperparamètres.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
Définir l’espace de recherche de paramètres
Vous pouvez définir les architectures et les hyperparamètres des modèles pour balayer l’espace de paramètres. Vous pouvez spécifier une seule architecture de modèle ou plusieurs.
- Voir Évaluations individuelles pour la liste des architectures de modèle pris en charge pour chaque type de tâche.
- Consultez Hyperparamètres pour les tâches de vision par ordinateur hyperparamètres pour chaque type de tâche de vision par ordinateur.
- Consultez les Détails sur les distributions prises en charge pour les hyperparamètres discrets et continus.
Méthodes d’échantillonnage pour le balayage
Lors du balayage des hyperparamètres, vous devez spécifier la méthode d’échantillonnage à utiliser pour balayer l’espace de paramètres défini. Actuellement, les méthodes d’échantillonnage suivantes sont prises en charge avec le paramètre sampling_algorithm :
| Type d’échantillonnage | Syntaxe du travail AutoML |
|---|---|
| Échantillonnage aléatoire | random |
| Échantillonnage par grille | grid |
| Échantillonnage bayésien | bayesian |
Notes
Seul les échantillonnages aléatoire et par grille prennent actuellement en charge les espaces conditionnels d’hyperparamètres.
Stratégies d’arrêt anticipé
Vous pouvez arrêter automatiquement les évaluations peu performantes avec une stratégie d’arrêt anticipé. Un arrêt anticipé améliore l’efficacité du calcul, en sauvant des ressources de calcul qui auraient autrement été consacrées à des essais moins prometteurs. Le ML automatisé pour les images prend en charge les stratégies d’arrêt anticipé suivantes avec le paramètre early_termination. Si aucune stratégie d’arrêt n’est spécifiée, toutes les évaluations sont exécutées jusqu’à la fin.
| Stratégie d’arrêt anticipé | Syntaxe du travail AutoML |
|---|---|
| Stratégie Bandit | CLI v2 : bandit Kit de développement logiciel (SDK) v2 : BanditPolicy() |
| Stratégie d’arrêt médiane | CLI v2 : median_stopping Kit de développement logiciel (SDK) v2 : MedianStoppingPolicy() |
| Stratégie de sélection de troncation | CLI v2 : truncation_selection Kit de développement logiciel (SDK) v2 : TruncationSelectionPolicy() |
Découvrez plus en détail comment configurer la stratégie d’arrêt anticipé pour votre balayage d’hyperparamètres.
Notes
Pour obtenir un exemple complet de configuration de balayage, reportez-vous à ce tutoriel.
Vous pouvez configurer tous les paramètres associés au balayage, comme illustré dans l’exemple qui suit.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Correction des paramètres
Vous pouvez transmettre des paramètres fixes, qui ne changent pas pendant le balayage de l’espace de paramètres, comme illustré dans l’exemple qui suit.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Augmentation des données
En général, les performances des modèles Deep Learning peuvent souvent s’améliorer avec davantage de données. L’augmentation des données est une technique pratique pour amplifier la taille des données et la variabilité d’un jeu de données, ce qui permet d’empêcher le surajustement et d’améliorer la capacité de généralisation du modèle sur les données non vues. Le ML automatisé applique différentes techniques d’augmentation des données en fonction de la tâche de vision par ordinateur, avant d’alimenter les images d’entrée dans le modèle. Actuellement, il n’y a pas d’hyperparamètre exposé pour contrôler les augmentations de données.
| Tâche | Jeu de données impacté | Technique(s) d’augmentation des données appliquée(s) |
|---|---|---|
| Classification d’images (multi-classe et multi-étiquette) | Formation Validation et test |
Redimensionnement et rognage aléatoires, retournement horizontal, variation des couleurs (luminosité, contraste, saturation et teinte), normalisation avec la moyenne et l’écart type d’ImageNet au niveau canal Redimensionnement, rognage central, normalisation |
| Détection d’objets, segmentation d’instances | Formation Validation et test |
Rognage aléatoire autour des cadres englobants, développement, retournement horizontal, normalisation, redimensionnement Normalisation, redimensionnement |
| Détection d’objets avec yolov5 | Formation Validation et test |
Mise en mosaïque, affinité aléatoire (rotation, translation, mise à l’échelle, inclinaison), retournement horizontal Redimensionnement des cadres |
Actuellement, les augmentations définies ci-dessus sont appliquées par défaut pour un travail de ML automatisé pour image. Pour contrôler les augmentations, le ML automatisé pour les images expose les deux indicateurs ci-dessous pour désactiver certaines augmentations. Actuellement, ces indicateurs sont uniquement pris en charge pour les tâches de détection d’objets et de segmentation d’instance.
- apply_mosaic_for_yolo : Cet indicateur est uniquement spécifique au modèle Yolo. Le fait de le définir sur False désactive l’augmentation des données de mosaïque qui est appliquée au moment de la formation.
-
apply_automl_train_augmentations : La définition de cet indicateur sur false désactive l’augmentation appliquée pendant le temps d’apprentissage pour les modèles de détection d’objets et de segmentation d’instance. Pour les augmentations, consultez les détails dans le tableau ci-dessus.
- Pour le modèle de détection d’objets non-yolo et les modèles de segmentation d’instance, cet indicateur désactive uniquement les trois premières augmentations. Par exemple : Rognage aléatoire autour des cadres englobants, développement, retournement horizontal. Les augmentations de normalisation et de redimensionnement sont toujours appliquées, quel que soit cet indicateur.
- Pour le modèle Yolo, cet indicateur désactive les augmentations random affine et horizontal.
Ces deux indicateurs sont pris en charge via advanced_settings sous training_parameters et peuvent être contrôlés de la manière suivante.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Notez que ces deux indicateurs sont indépendants l’un de l’autre et peuvent également être utilisés en combinaison à l’aide des paramètres qui suivent.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
Lors de nos expériences, nous avons constaté que ces augmentations aident le modèle à mieux généraliser. Par conséquent, lorsque ces augmentations sont désactivées, nous recommandons aux utilisateurs de les combiner avec d’autres augmentations hors connexion pour obtenir de meilleurs résultats.
Entraînement incrémentiel (facultatif)
Une fois le travail de formation terminé, vous avez la possibilité de former davantage le modèle en chargeant le point de contrôle du modèle formé. Vous pouvez utiliser le même jeu de données ou un jeu différent pour un entraînement incrémentiel. Si vous êtes satisfait du modèle, vous pouvez choisir d’arrêter la formation et utiliser le modèle actuel.
Passer le point de contrôle via l’ID de travail
Vous pouvez transmettre l’ID de travail à partir duquel vous voulez charger le point de contrôle.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
Envoyer le travail AutoML
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
Pour soumettre votre travail AutoML, vous exécutez la commande CLI v2 suivante avec le chemin d’accès à votre fichier .yml, le nom de l’espace de travail, le groupe de ressources et l’ID d’abonnement.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Sorties et métriques d’évaluation
Les travaux de formation de ML automatisé génèrent des fichiers de modèle de sortie, des métriques d’évaluation, des journaux et des artefacts de déploiement, comme le fichier de scoring et le fichier d’environnement. Ces fichiers et métriques peuvent être affichés depuis l’onglet sorties, journaux et métriques des tâches enfant.
Conseil
Regardez comment accéder aux résultats des tâches à partir de la section Consulter les résultats des travaux.
Pour obtenir des définitions et des exemples des graphiques et métriques de performances fournis pour chaque travail, consultez Évaluer les résultats de l’expérience de Machine Learning automatisé.
Inscrire et déployer un modèle
Une fois le travail terminé, vous pouvez inscrire le modèle qui a été créé à partir du meilleur essai (configuration qui a généré la meilleure métrique principale). Vous pouvez inscrire le modèle après le téléchargement ou en spécifiant le chemin d’accès azureml avec l’id de travail correspondant. Remarque : quand vous voulez modifier les paramètres d’inférence décrits ci-dessous, vous devez télécharger le modèle, modifier settings.json et vous inscrire à l’aide du dossier de modèle mis à jour.
Obtenir le meilleur essai
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
CLI example not available, please use Python SDK.
Inscrire le modèle
Inscrivez le modèle à l’aide du chemin azureml ou de votre chemin téléchargé localement.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Après avoir inscrit le modèle que vous souhaitez utiliser, vous pouvez le déployer à l’aide du point de terminaison en ligne managé deploy-managed-online-endpoint
Configurer le point de terminaison en ligne
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
Créer le point de terminaison
En utilisant le MLClient créé précédemment, nous allons créer le point de terminaison dans l’espace de travail. Cette commande lance la création du point de terminaison et retourne une réponse de confirmation, pendant que la création du point de terminaison se poursuit.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Configurer le déploiement en ligne
Un déploiement est un ensemble de ressources nécessaires pour héberger le modèle qui effectue l’inférence réelle. Nous allons créer un déploiement pour notre point de terminaison à l’aide de la classe ManagedOnlineDeployment. Vous pouvez utiliser l’une des références SKU de machine virtuelle GPU ou CPU pour votre cluster de déploiement.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
Créer le déploiement
À l’aide de MLClient créé précédemment, nous allons maintenant créer le déploiement dans l’espace de travail. Cette commande initie la création du déploiement et renvoie un réponse de confirmation tandis que la création du déploiement se poursuit.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
mettre à jour le trafic :
Par défaut, le déploiement actuel est défini pour recevoir 0 % de trafic. vous pouvez définir le pourcentage de trafic que le déploiement actuel doit recevoir. Somme des pourcentages de trafic de tous les déploiements avec un point de terminaison qui ne doit pas dépasser 100 %.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Vous pouvez aussi déployer le modèle à partir de l’interface utilisateur Azure Machine Learning studio. Accédez au modèle que vous souhaitez déployer sous l’onglet Modèles du travail ML automatisé, puis sélectionnez Déployer et sélectionnez Déployer sur le point de terminaison en temps réel.
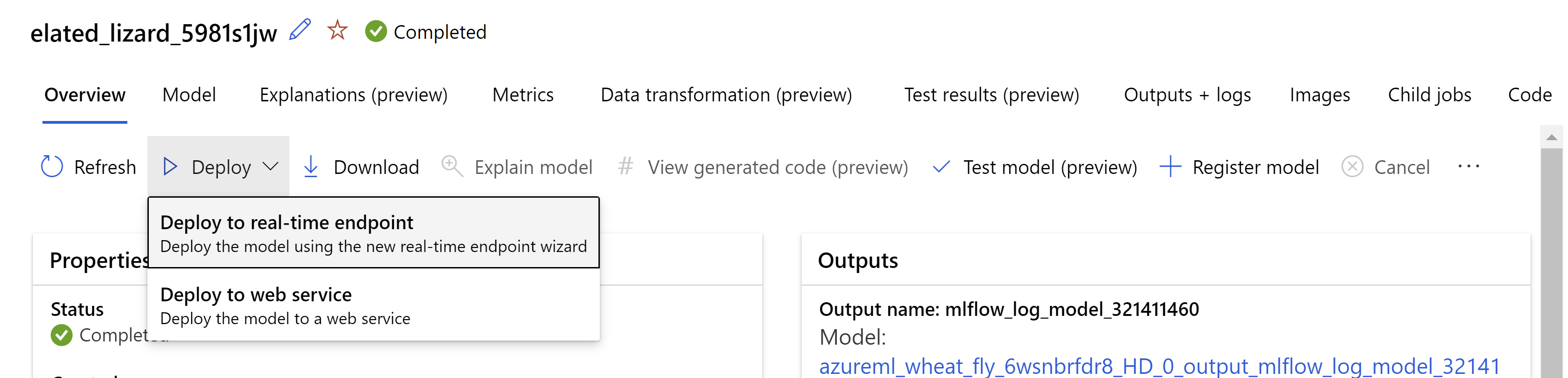 .
.
c’est à cela que votre page de révision ressemble. nous pouvons sélectionner le type d’instance, le nombre d’instances et définir le pourcentage de trafic pour le déploiement actuel.
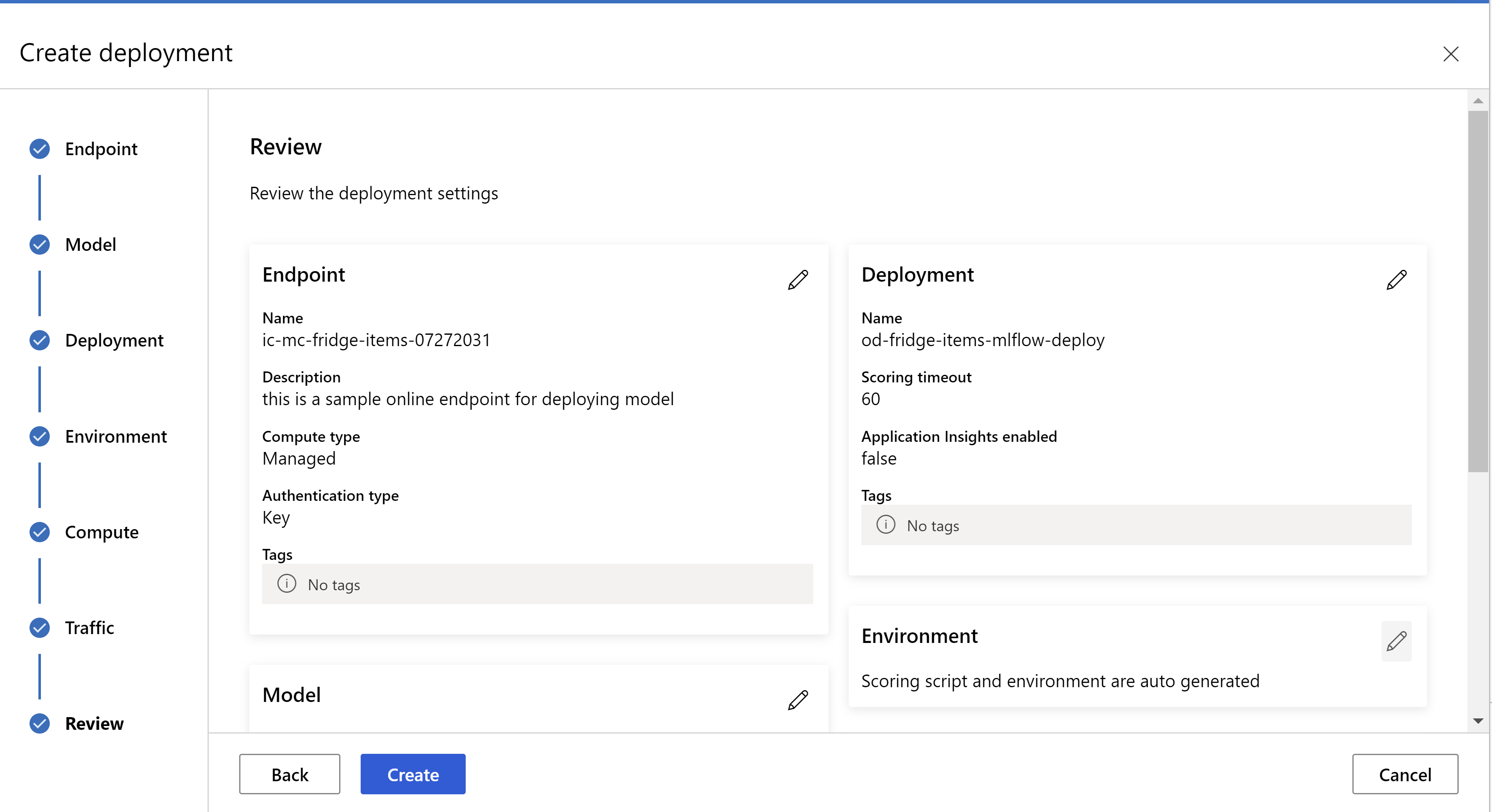 .
.
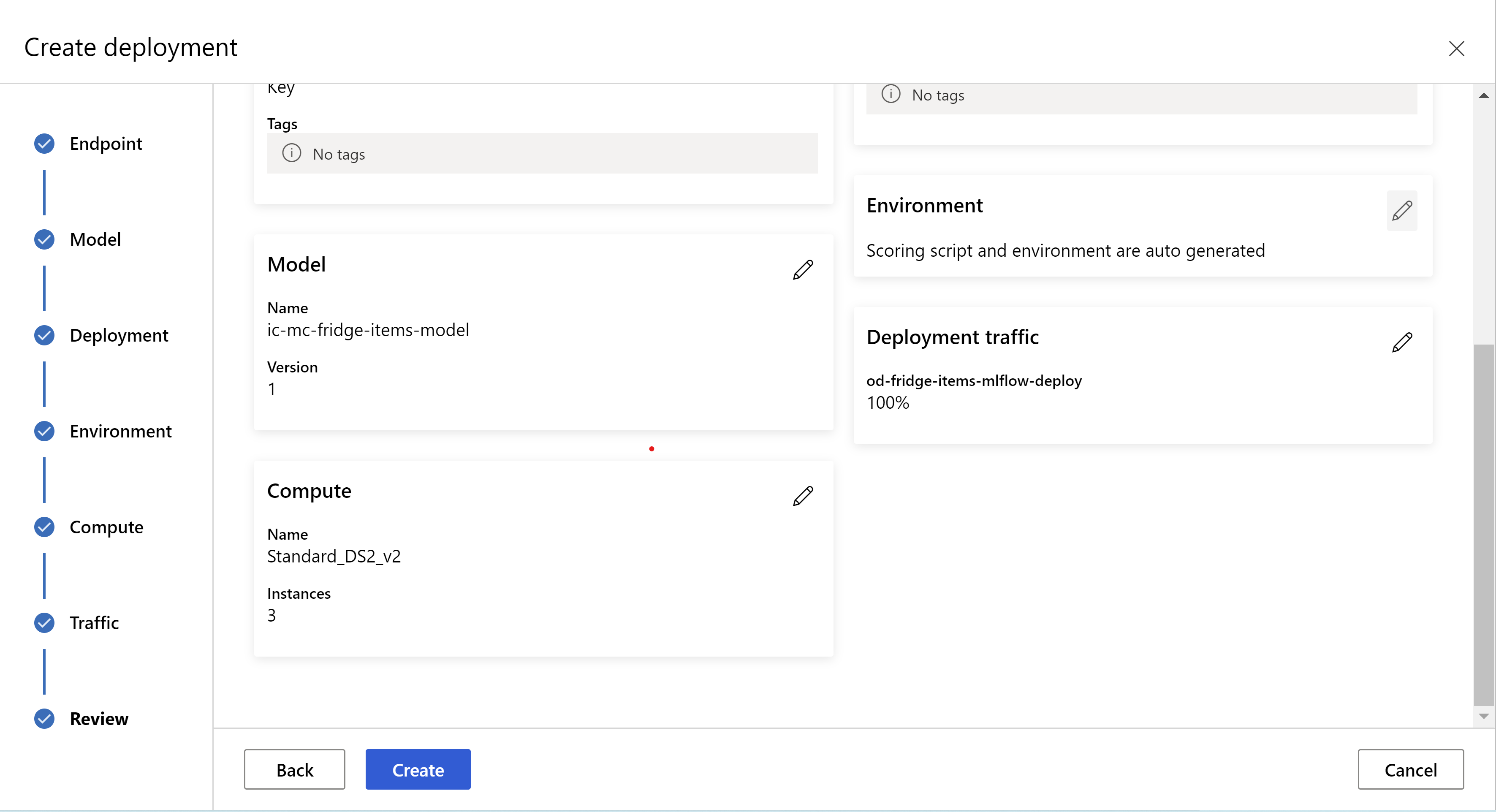 .
.
Mettre à jour les paramètres d’inférence
À l’étape précédente, nous avons téléchargé un fichier mlflow-model/artifacts/settings.json à partir du meilleur modèle. qui peut être utilisé pour mettre à jour les paramètres d’inférence avant d’inscrire le modèle. Bien qu’il soit recommandé d’utiliser les mêmes paramètres que l’entraînement pour des performances optimales.
Chacune des tâches (et certains modèles) possède un ensemble de paramètres. Par défaut, nous utilisons les mêmes valeurs pour les paramètres qui ont été utilisés pendant l’entraînement et la validation. En fonction du comportement dont nous avons besoin lors de l’utilisation du modèle pour l’inférence, nous pouvons changer ces paramètres. Vous trouverez ci-dessous une liste de paramètres pour chaque type de tâche et modèle.
| Tâche | Nom du paramètre | Default |
|---|---|---|
| Classification d’images (multi-classe et multi-étiquette) | valid_resize_sizevalid_crop_size |
256 224 |
| Détection d’objets | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0.5 100 |
Détection d’objets avec yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 moyenne 0.1 0.5 |
| Segmentation d’instances | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0.5 100 0.5 100 False JPG |
Pour obtenir une description détaillée des hyperparamètres spécifiques aux tâches, consultez Hyperparamètres pour les tâches de vision par ordinateur dans le Machine Learning automatisé.
Si vous souhaitez utiliser la mise en mosaïque et contrôler son comportement, les paramètres suivants sont disponibles : tile_grid_size, tile_overlap_ratio et tile_predictions_nms_thresh. Pour plus d’informations sur ces paramètres, consultez Entraîner un modèle de détection de petits objets avec le Machine Learning automatisé.
test du déploiement
Consultez cette section Tester le déploiement pour tester le déploiement et visualiser les détections à partir du modèle.
Générer des explications pour les prédictions
Important
Ces paramètres sont actuellement en préversion publique. Ils sont fournis sans contrat de niveau de service. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Avertissement
L’explicabilité de modèle est prise en charge uniquement pour la classification multi-classe et la classification multi-étiquette.
Voici quelques-uns des avantages de l’utilisation de l’IA explicable (XAI) avec AutoML pour les images :
- Améliore la transparence dans les prédictions de modèle de vision complexe
- Aide les utilisateurs à comprendre les caractéristiques/pixels importants dans l’image d’entrée qui contribuent aux prédictions du modèle
- Aide à résoudre les problèmes liés aux modèles
- Aide à découvrir le biais
Explications
Les explications sont des attributions de caractéristiques ou des pondérations données à chaque pixel dans l’image d’entrée en fonction de sa contribution à la prédiction du modèle. Chaque pondération peut être négative (corrélée négativement avec la prédiction) ou positive (corrélée positivement avec la prédiction). Ces attributions sont calculées par rapport à la classe prédite. Pour la classification multiclasse, une seule matrice d’attribution de taille [3, valid_crop_size, valid_crop_size] est générée par échantillon, tandis que pour la classification multi-étiquette, une matrice d’attribution de taille [3, valid_crop_size, valid_crop_size] est générée pour chaque étiquette/classe prédite pour chaque échantillon.
À l’aide de l’IA explicable dans AutoML pour images sur le point de terminaison déployé, les utilisateurs peuvent obtenir des visualisations d’explications (attributions superposées sur une image d’entrée) et/ou d’attributions (tableau multidimensionnel de taille [3, valid_crop_size, valid_crop_size]) pour chaque image. Outre les visualisations, les utilisateurs peuvent également obtenir des matrices d’attribution pour mieux contrôler les explications (comme la génération de visualisations personnalisées à l’aide d’attributions ou l’examen de segments d’attributions). Tous les algorithmes d’explication utilisent des images carrées rognées de taille valid_crop_size pour générer des attributions.
Les explications peuvent être générées à partir d’un point de terminaison en ligne ou d’un point de terminaison de lot. Une fois le déploiement terminé, ce point de terminaison peut être utilisé pour générer les explications des prédictions. Pour les déploiements en ligne, veillez à passer le paramètre request_settings = OnlineRequestSettings(request_timeout_ms=90000) à ManagedOnlineDeploymentet à définir request_timeout_ms à sa valeur maximale pour éviter les problèmes de délai d’expiration lors de la génération d’explications (consulter la section Inscrire et déployer un modèle). Certaines méthodes d’explicabilité (XAI) comme xrai consomment plus de temps (en particulier pour la classification multi-étiquette, car nous devons générer des attributions et/ou des visualisations par rapport à chaque étiquette prédite). Par conséquent, nous recommandons n’importe quelle instance GPU pour des explications plus rapides. Pour plus d’informations sur le schéma d’entrée et de sortie pour générer des explications, consultez la documentation sur le schéma.
Nous prenons en charge les algorithmes d’explicabilité de pointe suivants dans AutoML pour les images :
- XRAI (xrai)
- Dégradés intégrés (integrated_gradients)
- GradCAM guidé (guided_gradcam)
- Rétropropagation guidée (guided_backprop)
Le tableau suivant décrit les paramètres de réglage spécifiques de l’algorithme d’explicabilité pour XRAI et les dégradés intégrés. La rétropropagation guidée et la gradcam guidée ne nécessitent aucun paramètre de réglage.
| Algorithme JWT | Paramètres spécifiques à l’algorithme | Valeurs par défaut |
|---|---|---|
xrai |
1. n_steps: nombre d’étapes utilisées par la méthode d’approximation. Un plus grand nombre d’étapes conduit à de meilleures approximations des attributions (explications). La plage de n_steps est [2, inf), mais les performances des attributions commencent à converger après 50 étapes. Optional, Int 2. xrai_fast: Indique s’il faut utiliser une version plus rapide de XRAI. si True, le temps de calcul pour les explications est plus rapide, mais conduit à des explications moins précises (attributions) Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: nombre d’étapes utilisées par la méthode d’approximation. Un plus grand nombre d’étapes conduit à de meilleures attributions (explications). La plage de n_steps est [2, inf), mais les performances des attributions commencent à converger après 50 étapes.Optional, Int 2. approximation_method: Méthode d’approximation de l’intégrale. Les méthodes d’approximation disponibles sont riemann_middle et gausslegendre.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
En interne, l’algorithme XRAI utilise des dégradés intégrés. Par conséquent, le paramètren_steps est requis par les dégradés intégrés et les algorithmes XRAI. Un plus grand nombre d’étapes consomme plus de temps pour rapprocher les explications et peut entraîner des problèmes de délai d’expiration sur le point de terminaison en ligne.
Nous vous recommandons d’utiliser des algorithmes XRAI >GradCAM guidé> Gradients intégrés > Rétropropagation guidée pour de meilleures explications, tandis que les XRAI Rétropropagation guidée > GradCAM guidé>Gradients intégrés> sont recommandés pour des explications plus rapides dans l’ordre spécifié.
Un exemple de demande au point de terminaison en ligne ressemble à ce qui suit. Cette requête génère des explications lorsque model_explainability est défini sur True. La requête suivante génère des visualisations et des attributions à l’aide d’une version plus rapide de l’algorithme XRAI avec 50 étapes.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
Pour plus d’informations sur la génération d’explications, consultez Référentiel de notebooks GitHub pour les exemples de Machine Learning automatisé.
Interprétation des visualisations
Le point de terminaison déployé retourne une chaîne d’image encodée en base64 si model_explainabilityetvisualizations ont la valeur True. Décodez la chaîne base64 comme décrit dans les notebooks ou utilisez le code suivant pour décoder et visualiser les chaînes d’image base64 dans la prédiction.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
L’image suivante décrit la visualisation des explications d’un exemple d’image d’entrée.

La figure en base64 décodée aura quatre sections d’image dans une grille de 2 x 2.
- L’image en haut à gauche (0, 0) est l’image d’entrée rognée
- L’image en haut à droite (0, 1) est la carte thermique des attributions sur une échelle de couleurs bgyw (bleu vert jaune blanc) où la contribution des pixels blancs sur la classe prédite est la plus élevée et les pixels bleus est la plus faible.
- L’image située dans le coin inférieur gauche (1, 0) est une carte thermique mixte des attributions sur l’image d’entrée rognée
- L’image située en bas à droite (1, 1) est l’image d’entrée rognée avec les 30 % supérieurs des pixels en fonction des scores d’attribution.
Interprétation des attributions
Le point de terminaison déployé retourne des attributions si model_explainabilityet attributions ont la valeur True. Pour plus d’informations, reportez-vous aux notebooks de classification multiclasse et de classification à plusieurs étiquettes.
Ces attributions donnent plus de contrôle aux utilisateurs pour générer des visualisations personnalisées ou examiner les scores d’attribution au niveau des pixels. L’extrait de code suivant décrit un moyen de générer des visualisations personnalisées à l’aide de la matrice d’attribution. Pour plus d’informations sur le schéma des attributions pour la classification multiclasse et la classification multiétiquette, consultez la documentation sur les schémas.
Utilisez les valeurs exactes valid_resize_size et valid_crop_size du modèle sélectionné pour générer les explications (les valeurs par défaut sont respectivement 256 et 224). Le code suivant utilise la fonctionnalité de visualisation Captum pour générer des visualisations personnalisées. Les utilisateurs peuvent utiliser n’importe quelle autre bibliothèque pour générer des visualisations. Pour plus d’informations, reportez-vous aux utilitaires de visualisation captum.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Jeux de données volumineux
Si vous utilisez AutoML pour effectuer l’apprentissage sur des jeux de données volumineux, certains paramètres expérimentaux peuvent être utiles.
Important
Ces paramètres sont actuellement en préversion publique. Ils sont fournis sans contrat de niveau de service. Certaines fonctionnalités peuvent être limitées ou non prises en charge. Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Apprentissage multi-GPU et multi-nœuds
Par défaut, l’apprentissage de chaque modèle s’effectue sur une seule machine virtuelle. Si l’apprentissage d’un modèle prend trop de temps, l’utilisation de machines virtuelles contenant plusieurs GPU peut vous aider. Le temps d’apprentissage d’un modèle sur des jeux de données volumineux devrait diminuer en proportion approximativement linéaire du nombre de GPU utilisés (par exemple, un modèle devrait effectuer son apprentissage environ deux fois plus rapidement sur une machine virtuelle avec deux GPU que sur une machine virtuelle avec un seule GPU). Si le temps d’apprentissage d’un modèle est toujours élevé sur une machine virtuelle avec plusieurs GPU, vous pouvez augmenter le nombre de machines virtuelles utilisées pour effectuer l’apprentissage de chaque modèle. Comme pour l’apprentissage multi-GPU, le temps d’apprentissage d’un modèle sur des jeux de données volumineux devrait également diminuer en proportion approximativement linéaire du nombre de machines virtuelles utilisées. Lors de l’apprentissage d’un modèle sur plusieurs machines virtuelles, veillez à utiliser une référence SKU de calcul prenant en charge InfiniBand pour obtenir des résultats optimaux. Vous pouvez configurer le nombre de machines virtuelles utilisées pour effectuer l’apprentissage d’un modèle unique en définissant la propriété node_count_per_trial du travail AutoML.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
properties:
node_count_per_trial: "2"
Diffusion en continu de fichiers image à partir du stockage
Par défaut, tous les fichiers image sont téléchargés sur disque avant l’apprentissage du modèle. Si la taille des fichiers image est supérieure à l’espace disque disponible, la tâche échoue. Au lieu de télécharger toutes les images sur disque, vous pouvez choisir de diffuser en continu des fichiers image à partir du stockage Azure, car ils sont nécessaires lors de l’apprentissage. Les fichiers image sont diffusés directement à partir du stockage Azure vers la mémoire système, en contournant le disque. En même temps, le plus grand nombre possible de fichiers du stockage sont mis en cache sur disque pour réduire le nombre de requêtes adressées au stockage.
Notes
Si la diffusion en continu est activée, vérifiez que le compte de stockage Azure se trouve dans la même région que le calcul afin de réduire les coûts et la latence.
S’APPLIQUE À :Extension ml Azure CLI v2 (actuelle)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Exemples de notebooks
Passez en revue les exemples de code détaillé et les cas d’usage disponibles dans le dépôt GitHub d’exemples de blocs-notes pour le Machine Learning automatisé. Vérifiez les dossiers avec le préfixe « automl-image- » pour obtenir des exemples propres à la création de modèles de vision par ordinateur.
Exemples de code
Passez en revue les exemples de code détaillé et les cas d’usage disponibles dans le référentiel azureml-examples d’exemples de Machine Learning automatisé.