Prévisions à grande échelle : de nombreux modèles et formations distribués
Cet article concerne la formation des modèles de prévision sur de grandes quantités de données historiques. Vous trouverez des instructions et des exemples pour l’apprentissage des modèles de prévision dans AutoML dans notre article Configurer AutoML pour effectuer l’apprentissage d’un modèle de prévision de série chronologique.
Les données de série chronologique peuvent être volumineuses en raison du nombre de séries dans les données, du nombre d’observations historiques ou des deux. De nombreux modèles et séries chronologiques hiérarchiques, ou HTS, sont des solutions de mise à l’échelle pour le scénario précédent, où les données se composent d’un grand nombre de séries chronologiques. Dans ce cas, il peut être utile pour la précision et la scalabilité du modèle de partitionner les données en groupes et d’entraîner un grand nombre de modèles indépendants en parallèle sur les groupes. À l’inverse, il existe des scénarios où un ou plusieurs modèles à haute capacité sont meilleurs. L’entraînement DNN distribué cible ce cas. Nous passons en revue les concepts autour de ces scénarios dans le reste de l’article.
Nombreux modèles
Les nombreux composants de modèles d’AutoML vous permettent d’entraîner et de gérer des millions de modèles en parallèle. Par exemple, supposons que vous disposez de données historiques de ventes pour un grand nombre de magasins. Vous pouvez utiliser de nombreux modèles pour lancer des travaux de formation AutoML parallèles pour chaque magasin, comme dans le diagramme suivant :

Le composant de formation de nombreux modèles applique le balayage et la sélection du modèle AutoML indépendamment à chaque magasin dans cet exemple. Cette indépendance de modèle favorise la scalabilité et peut bénéficier de la précision du modèle, en particulier lorsque les magasins ont une dynamique de vente divergente. Toutefois, une approche de modèle unique peut produire des prévisions plus précises lorsqu’il existe une dynamique de vente commune. Pour plus d’informations sur ce cas, consultez la section formation DNN distribuée.
Vous pouvez configurer le partitionnement des données, les paramètres AutoML pour les modèles et le degré de parallélisme pour de nombreux travaux de formation de modèles. Pour obtenir des exemples, consultez notre section de guide sur de nombreux composants de modèles.
Prévision de série chronologique hiérarchique
Il est courant que les séries chronologiques dans les applications métier aient des attributs imbriqués qui forment une hiérarchie. Les attributs de la géographie et du catalogue de produits sont souvent imbriqués, pour instance. Prenons un exemple où la hiérarchie a deux attributs géographiques, l’ID d’état et de magasin, et deux attributs de produit, la catégorie et la référence SKU :

Cette hiérarchie est illustrée par le diagramme suivant :

Il est important de noter que les quantités de ventes au niveau feuille (SKU) s’ajoutent aux quantités de ventes agrégées aux niveaux de l’état et du total des ventes. Les méthodes de prévision hiérarchique conservent ces propriétés d’agrégation lors de la prévision de la quantité vendue à n’importe quel niveau de la hiérarchie. Les prévisions avec cette propriété sont cohérentes par rapport à la hiérarchie.
AutoML prend en charge les fonctionnalités suivantes pour les séries chronologiques hiérarchiques (HTS) :
- Formation à n’importe quel niveau de la hiérarchie. Dans certains cas, les données de niveau feuille peuvent être bruyantes, mais les agrégats peuvent être plus accessibles à la prévision.
- Récupération des prévisions de points à n’importe quel niveau de la hiérarchie. Si le niveau de prévision est « inférieur » au niveau de formation, les prévisions du niveau de formation sont désagrégées en fonction des proportions historiques moyennes ou des proportions des moyennes historiques. Les prévisions de niveau de formation sont additionnées en fonction de la structure d’agrégation lorsque le niveau de prévision est « supérieur » au niveau d’entraînement.
- Récupération des prévisions quantiles/probabilistes pour les niveaux au niveau de formation ou « inférieurs ». Les fonctionnalités de modélisation actuelles prennent en charge la désagrégation des prévisions probabilistes.
Les composants HTS dans AutoML sont basés sur de nombreux modèles. HtS partage donc les propriétés évolutives de nombreux modèles. Pour obtenir des exemples, consultez notre section de guide sur de nombreux composants HTS.
Formation sur DNN distribué (préversion)
Important
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge.
Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Les scénarios de données comportant de grandes quantités d’observations historiques et/ou un grand nombre de séries chronologiques associées peuvent tirer parti d’une approche de modèle unique et évolutive. Par conséquent, AutoML prend en charge la formation distribuée et la recherche de modèles sur les modèles de réseau convolutionnel temporel (TCN), qui sont un type de réseau neuronal profond (DNN) pour les données de série chronologique. Pour plus d’informations sur la classe de modèle TCN d’AutoML, consultez notre article DNN.
La formation DNN distribuée permet d’atteindre la scalabilité à l’aide d’un algorithme de partitionnement des données qui respecte les limites des séries chronologiques. Le diagramme suivant illustre un exemple simple avec deux partitions :
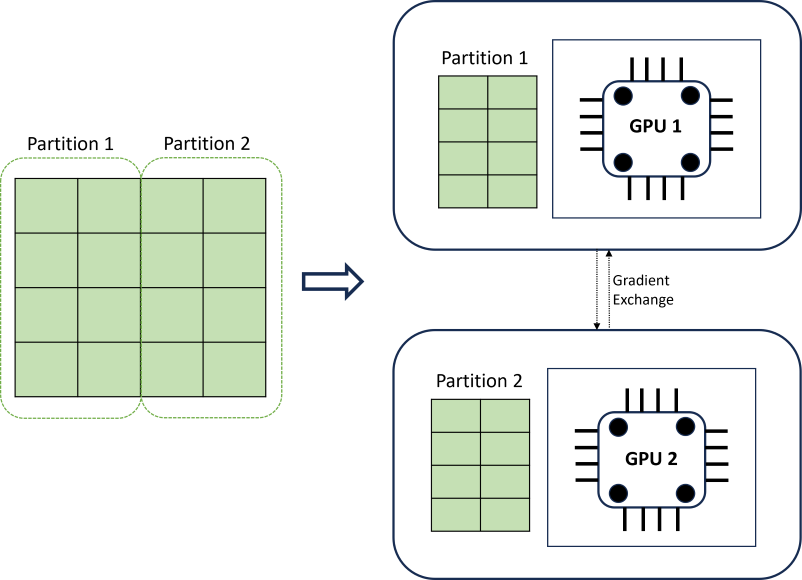
Pendant la formation, les chargeurs de données DNN sur chaque calcul chargent exactement ce dont ils ont besoin pour effectuer une itération de la propagation en arrière-plan; le jeu de données entier n’est jamais lu en mémoire. Les partitions sont distribuées sur plusieurs cœurs de calcul (généralement des GPU) sur plusieurs nœuds pour accélérer la formation. La coordination entre les calculs est fournie par l’infrastructure Horovod.
Étapes suivantes
- En savoir plus sur la procédure pour configurer AutoML pour effectuer l’apprentissage d’un modèle de prévision de série chronologique.
- Découvrez comment AutoML utilise le Machine Learning pour créer des modèles de prévision.
- En savoir plus sur les modèles de deep learning pour les prévisions dans AutoML