Gérer les délais d’expiration des procédures stockées dans le connecteur SQL pour Azure Logic Apps
S’applique à : Azure Logic Apps (Consommation)
Lorsque votre application logique fonctionne avec des jeux de résultats si volumineux que le connecteur SQL ne retourne pas tous les résultats en même temps, ou si vous souhaitez plus de contrôle sur la taille et la structure de vos jeux de résultats, vous pouvez créer une procédure stockée qui organise les résultats comme vous le souhaitez. Le connecteur SQL fournit de nombreuses fonctionnalités back-end auxquelles vous pouvez accéder à l’aide d’Azure Logic Apps afin d’automatiser plus facilement les tâches métier qui utilisent des tables de base de données SQL.
Par exemple, lorsque vous procédez à l’extraction ou à l’insertion de plusieurs lignes, votre application logique peut effectuer une itération dans ces lignes en utilisant une boucle Until dans ces limites. Toutefois, lorsque votre application logique doit manipuler des milliers ou millions de lignes, vous pouvez réduire les coûts liés aux appels à la base de données. Pour plus d’informations, consultez Gérer des données en bloc à l’aide du connecteur SQL.
Limite de délai d’expiration pour l’exécution d’une procédure stockée
Le connecteur SQL a une limite de délai d’expiration de procédure stockée qui est inférieure à 2 minutes. Certaines procédures stockées peuvent prendre plus de temps que cette limite, provoquant une erreur 504 Timeout. Parfois, ces processus de longue durée sont codées en tant que procédures stockées explicitement à cette fin. En raison de cette limite de délai d’expiration, l’appel de ces procédures à partir d’Azure Logic Apps peut occasionner des problèmes. Bien que le connecteur SQL ne prenne en charge nativement aucun mode asynchrone, vous pouvez contourner ce problème et simuler un tel mode à l’aide d’un déclencheur d’achèvement SQL, d’une requête pass-through SQL native, d’une table des états et de travaux côté serveur. Pour cette tâche, vous pouvez utiliser l’Agent de travail élastique Azure pour Azure SQL Database. Pour SQL Server en local et Azure SQL Managed Instance, vous pouvez utiliser le service SQL Server Agent.
Supposons, par exemple, que vous avez la procédure stockée de longue durée suivante, qui prend plus de temps que la limite de délai d’expiration. Si vous exécutez cette procédure stockée à partir d’une application logique à l’aide du connecteur SQL, vous obtenez une erreur HTTP 504 Gateway Timeout.
CREATE PROCEDURE [dbo].[WaitForIt]
@delay char(8) = '00:03:00'
AS
BEGIN
SET NOCOUNT ON;
WAITFOR DELAY @delay
END
Au lieu d’appeler directement la procédure stockée, vous pouvez l’exécuter de manière asynchrone en arrière-plan à l’aide d’un agent de travail. Vous pouvez stocker les entrées et sorties dans une table d’états avec laquelle vous pouvez interagir via votre application logique. Si vous n’avez pas besoin des entrées et sorties, ou si vous écrivez déjà les résultats dans une table de la procédure stockée, vous pouvez simplifier cette approche.
Important
Assurez-vous que votre procédure stockée et tous les travaux sont idempotents, ce qui signifie qu’ils peuvent s’exécuter plusieurs fois sans affecter les résultats. Si le traitement asynchrone échoue ou expire, l’agent de travail peut réessayer d’effectuer l’étape, et donc votre procédure stockée, à plusieurs reprises. Pour éviter la duplication des sorties, avant de créer des objets, consultez ces meilleures pratiques et approches.
La section suivante décrit comment utiliser l’Agent de travail élastique Azure pour Azure SQL Database. Pour SQL Server et Azure SQL Managed Instance, vous pouvez utiliser le service SQL Server Agent. Certains détails de gestion diffèrent, mais les étapes fondamentales restent les mêmes que la configuration d’un agent de travail pour Azure SQL Database.
Agent de travail pour Azure SQL Database
Pour créer un travail pouvant exécuter la procédure stockée pour Azure SQL Database, utilisez l’Agent de travail élastique Azure. Créez votre agent de travail dans le portail Azure. Cette approche ajoute plusieurs procédures stockées à la base de données que l’agent utilise, également appelée base de données de l’agent. Vous pouvez ensuite créer un travail exécutant votre procédure stockée dans la base de données cible, et capturant la sortie une fois que vous avez terminé.
Avant de pouvoir créer le travail, vous devez configurer des autorisations, des groupes et des cibles en procédant de la manière décrite dans la documentation complète de l’Agent de travail élastique Azure. Vous devez également créer une table associée dans la base de données cible, comme décrit dans les sections suivantes.
Créer une table d’états pour l’inscription de paramètres et le stockage d’entrées
Les travaux de SQL Agent n’acceptent pas de paramètres d’entrée. Au lieu de cela, dans la base de données cible, créez une table d’états dans laquelle vous inscrivez les paramètres et stockez les entrées à utiliser pour appeler vos procédures stockées. Toutes les étapes du travail de l’agent s’exécutent sur la base de données cible, mais les procédures stockées du travail s’exécutent sur la base de données de l’agent.
Pour créer la table d’états, utilisez le schéma suivant :
CREATE TABLE [dbo].[LongRunningState](
[jobid] [uniqueidentifier] NOT NULL,
[rowversion] [timestamp] NULL,
[parameters] [nvarchar](max) NULL,
[start] [datetimeoffset](7) NULL,
[complete] [datetimeoffset](7) NULL,
[code] [int] NULL,
[result] [nvarchar](max) NULL,
CONSTRAINT [PK_LongRunningState] PRIMARY KEY CLUSTERED
( [jobid] ASC
)WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
Voici à quoi ressemble la table dans SQL Server Management Studio (SMSS) :
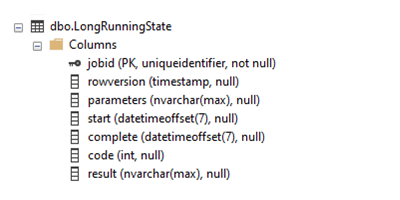
Pour garantir de bonnes performances et s’assurer que le travail de l’agent peut trouver l’enregistrement associé, la table utilise l’ID d’exécution du travail (jobid) comme clé primaire. Si vous le souhaitez, vous pouvez également ajouter des colonnes pour les paramètres d’entrée. Le schéma décrit précédemment peut généralement gérer plusieurs paramètres, mais il est limité à la taille calculée par NVARCHAR(MAX).
Créer un travail de niveau supérieur pour exécuter la procédure stockée
Pour exécuter la procédure stockée de longue durée, créez cet agent de travail de niveau supérieur dans la base de données de l’agent :
EXEC jobs.sp_add_job
@job_name='LongRunningJob',
@description='Execute Long-Running Stored Proc',
@enabled = 1
À présent, ajoutez au travail des étapes qui paramètrent, exécutent et accomplissent la procédure stockée. Par défaut, une étape de travail expire au bout de 12 heures. Si votre procédure stockée a besoin de plus de temps, ou si vous souhaitez que la procédure expire plus tôt, vous pouvez modifier le paramètre step_timeout_seconds en spécifiant une autre valeur exprimée en secondes. Par défaut, une étape comporte 10 tentatives intégrées avec un délai d’attente d’interruption entre chaque nouvelle tentative, que vous pouvez utiliser à votre avantage.
Voici les étapes à ajouter :
Attendre que les paramètres s’affichent dans la table
LongRunningState.Cette première étape attend que les paramètres soient ajoutés dans
LongRunningStatetable, ce qui se produit peu après le démarrage du travail. Si l’ID d’exécution du travail (jobid) n’est pas ajouté à la tableLongRunningState, l’étape échoue simplement et le délai d’attente par défaut de nouvelle tentative ou d’interruption est le suivant :EXEC jobs.sp_add_jobstep @job_name='LongRunningJob', @step_name= 'Parameterize WaitForIt', @step_timeout_seconds = 30, @command= N' IF NOT EXISTS(SELECT [jobid] FROM [dbo].[LongRunningState] WHERE jobid = $(job_execution_id)) THROW 50400, ''Failed to locate call parameters (Step1)'', 1', @credential_name='JobRun', @target_group_name='DatabaseGroupLongRunning'Interroger les paramètres de la table d’états et les transmettre à la procédure stockée. Cette étape exécute également la procédure en arrière-plan.
Si votre procédure stockée n’a pas besoin de paramètres, appelez directement la procédure stockée. Sinon, pour passer le paramètre
@timespan, utilisez la valeur@callparams, que vous pouvez également étendre pour passer des paramètres supplémentaires.EXEC jobs.sp_add_jobstep @job_name='LongRunningJob', @step_name='Execute WaitForIt', @command=N' DECLARE @timespan char(8) DECLARE @callparams NVARCHAR(MAX) SELECT @callparams = [parameters] FROM [dbo].[LongRunningState] WHERE jobid = $(job_execution_id) SET @timespan = @callparams EXECUTE [dbo].[WaitForIt] @delay = @timespan', @credential_name='JobRun', @target_group_name='DatabaseGroupLongRunning'Terminer le travail et enregistrer les résultats.
EXEC jobs.sp_add_jobstep @job_name='LongRunningJob', @step_name='Complete WaitForIt', @command=N' UPDATE [dbo].[LongRunningState] SET [complete] = GETUTCDATE(), [code] = 200, [result] = ''Success'' WHERE jobid = $(job_execution_id)', @credential_name='JobRun', @target_group_name='DatabaseGroupLongRunning'
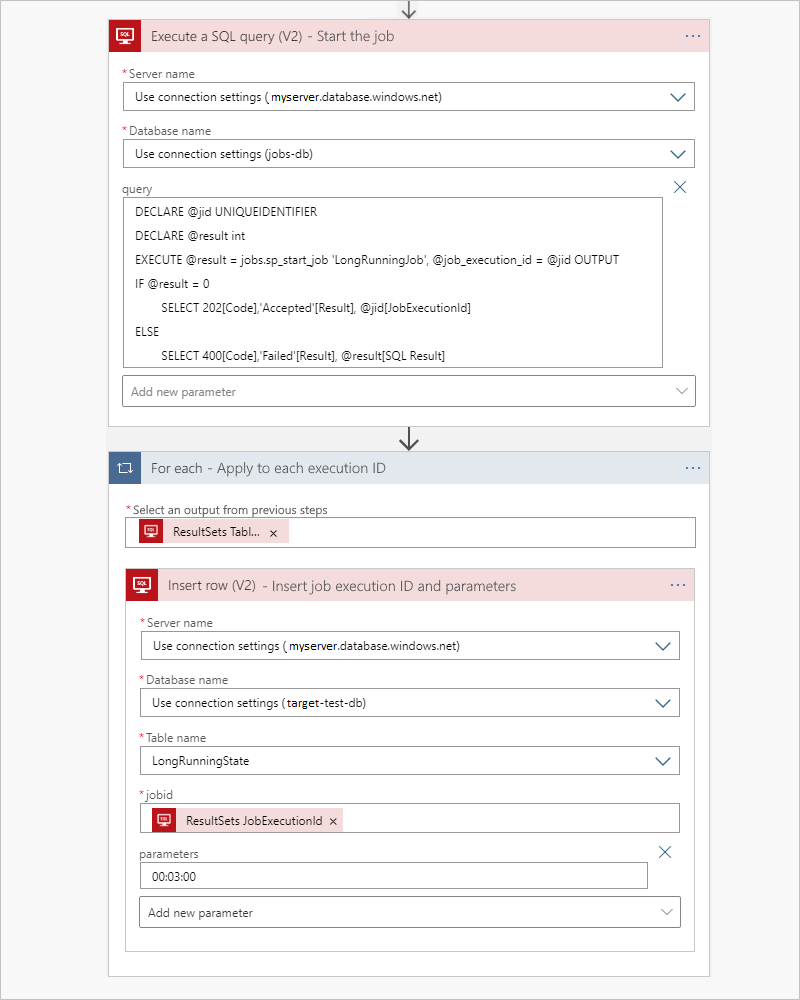
Démarrer le travail et passer les paramètres
Pour démarrer le travail, utilisez une requête native pass-through avec l’action Exécuter une requête SQL, et envoyez immédiatement les paramètres du travail à la table d’états. Pour fournir une entrée à l’attribut jobid de la table cible, Logic Apps ajoute une boucle For Each qui itère dans la sortie de la table résultant de l’action précédente. Pour chaque ID d’exécution de travail, exécutez une action Insérer une ligne qui utilise la sortie de données dynamiques, ResultSets JobExecutionId, pour ajouter les paramètres du travail à décompresser et à passer à la procédure stockée cible.
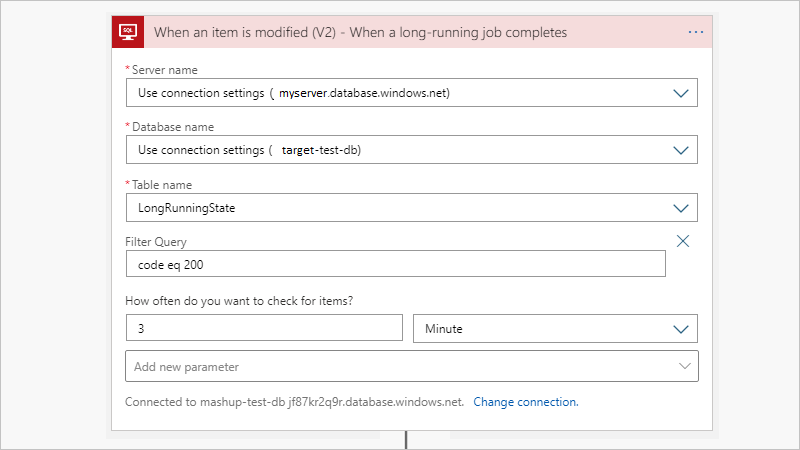
Une fois terminé, le travail met à jour la table LongRunningState afin que vous puissiez facilement déclencher sur le résultat à l’aide du déclencheur Quand un élément est modifié. Si vous n’avez pas besoin de la sortie ou si vous disposez déjà d’un déclencheur qui surveille une table de sortie, vous pouvez ignorer cette partie.
Agent de travail pour SQL Server ou Azure SQL Managed Instance
Pour le même scénario, vous pouvez utiliser le service SQL Server Agent pour SQL Server local et Azure SQL Managed Instance. Bien que certains détails de gestion diffèrent, les étapes fondamentales restent les mêmes que pour la configuration d’un agent de travail pour Azure SQL Database.
Étapes suivantes
Établir une connexion à SQL Server, Azure SQL Database ou Azure SQL Managed Instance