Tutoriel : Envoyer des données d’un serveur OPC UA vers Azure Data Lake Storage Gen 2
Dans le guide de démarrage rapide, vous avez créé un flux de données qui envoie des données d’Opérations Azure IoT à Event Hubs, puis à Microsoft Fabric via EventStreams.
Toutefois, il est également possible d’envoyer les données directement à un point de terminaison de stockage sans utiliser Event Hubs. Cette approche nécessite la création d’un schéma Delta Lake qui représente les données, le chargement du schéma dans Opérations Azure IoT, puis la création d’un flux de données qui lit les données à partir du serveur OPC UA et les écrit dans le point de terminaison de stockage.
Ce tutoriel s’appuie sur la configuration du guide de démarrage rapide, et illustre comment bifurquer les données vers Azure Data Lake Storage Gen 2. Cette approche vous permet de stocker les données directement dans un lac de données évolutif et sécurisé, qui peut être utilisé pour une analyse et un traitement supplémentaires.
Prérequis
Terminez la deuxième étape du guide de démarrage rapide, qui vous permet d’obtenir et d’envoyer les données du serveur OPC UA vers l’Agent MQTT d’Opérations Azure IoT. Vérifiez que les données sont visibles dans Event Hubs.
Créer un compte de stockage avec la capacité Data Lake Storage
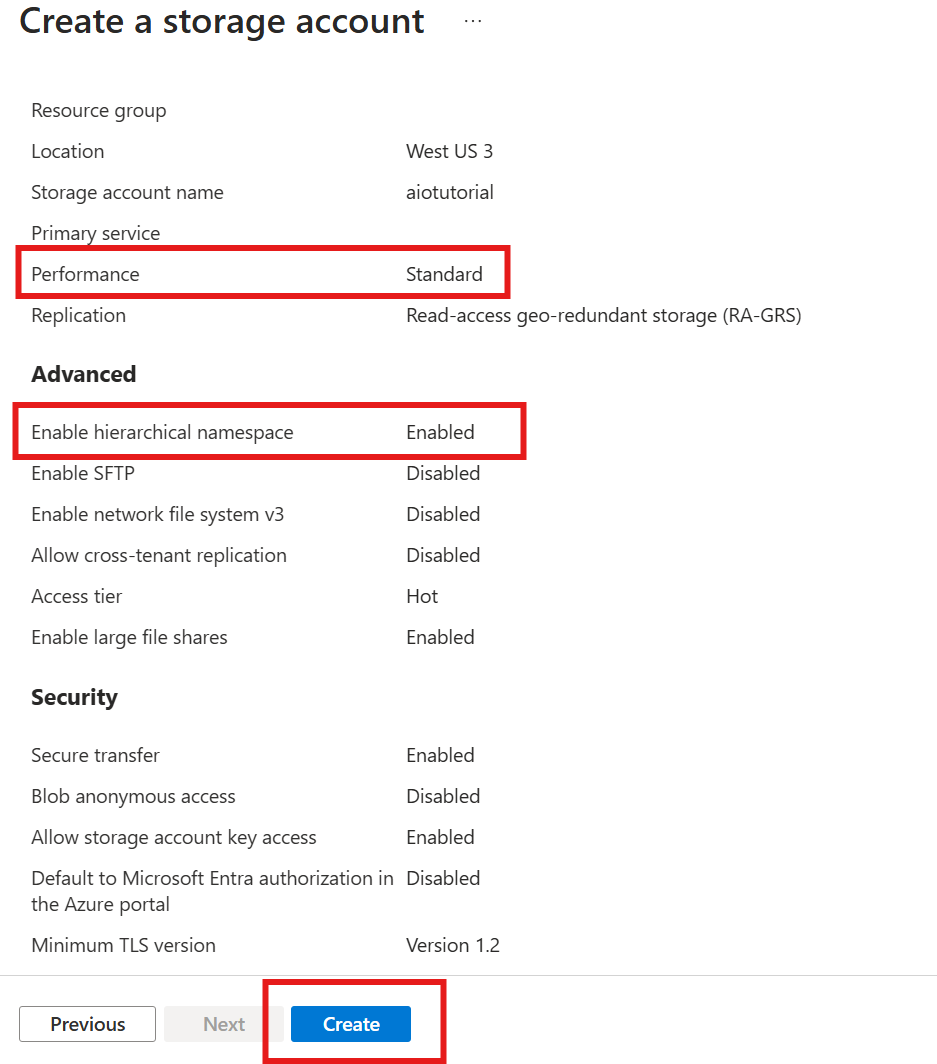
Tout d’abord, suivez les étapes pour créer un compte de stockage avec la capacité Data Lake Storage Gen 2.
- Choisissez un nom mémorable mais unique pour le compte de stockage, car vous en aurez besoin lors des étapes suivantes.
- Pour obtenir des résultats optimaux, utilisez un emplacement proche du cluster Kubernetes où Opérations Azure IoT est en cours d’exécution.
- Pendant le processus de création, activez le paramètre Espace de noms hiérarchique. Ce paramètre est requis pour qu’Opérations Azure IoT écrive dans le compte de stockage.
- Vous pouvez conserver les valeurs par défaut des autres paramètres.
À l’étape Révision, vérifiez les paramètres et sélectionnez Créer pour créer le compte de stockage.
Obtenir le nom d’extension d’Opérations Azure IoT
Dans le portail Azure, recherchez l’instance Opérations Azure IoT que vous avez créée dans le guide de démarrage rapide. Dans le volet Vue d’ensemble, recherchez la section Extension Arc et consultez le nom de l’extension. Il doit ressembler à azure-iot-operations-xxxxx.
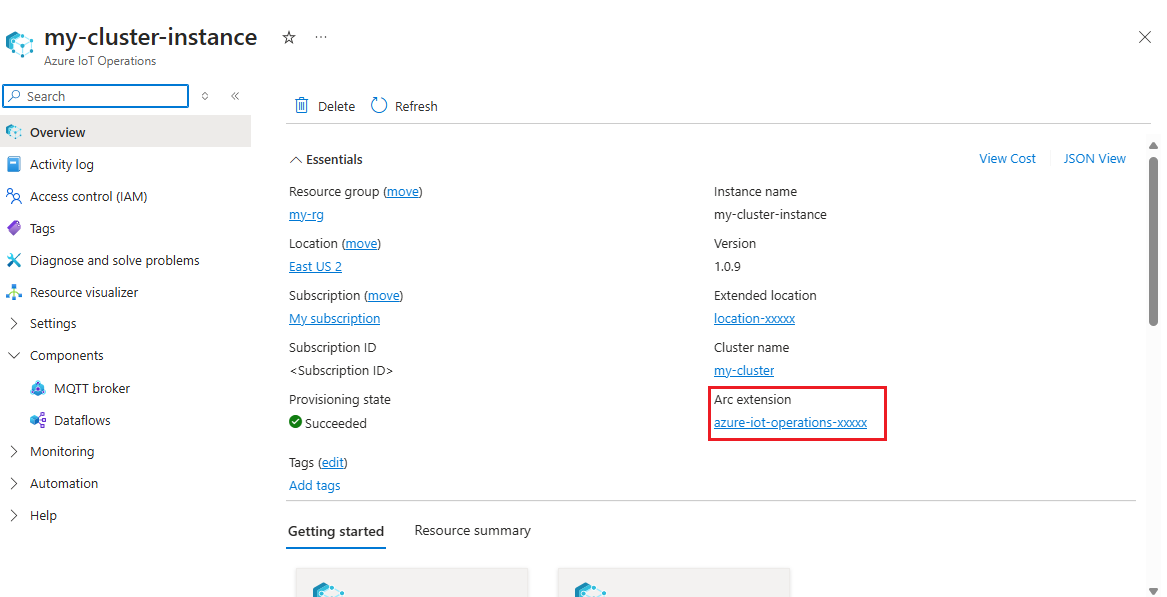
Ce nom d’extension est utilisé lors des étapes suivantes pour attribuer des autorisations au compte de stockage.
Attribuer à Opérations Azure IoT l’autorisation d’écrire dans le compte de stockage
Tout d’abord, dans le compte de stockage, accédez au volet Contrôle d’accès (IAM) et sélectionnez + Ajouter une attribution de rôle. Dans le volet Ajouter une attribution de rôle, recherchez le rôle Contributeur aux données Blob du stockage, puis sélectionnez-le.
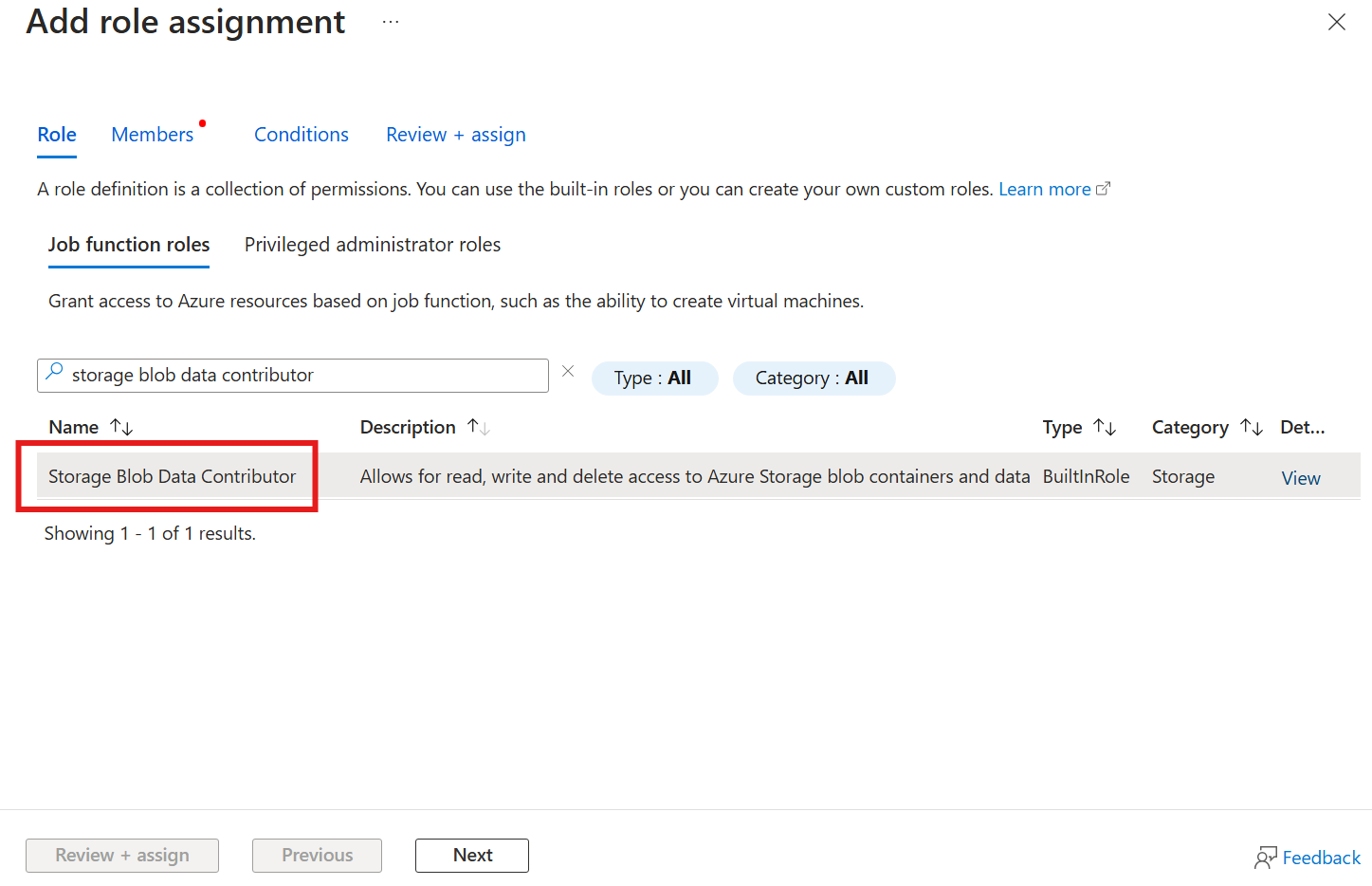
Ensuite, sélectionnez Suivant pour accéder à la section Membres.
Ensuite, choisissez Sélectionner des membres et, dans la zone Sélectionner, recherchez l’identité managée de l’extension Arc Opérations Azure IoT nommée azure-iot-operations-xxxxx et sélectionnez-la.
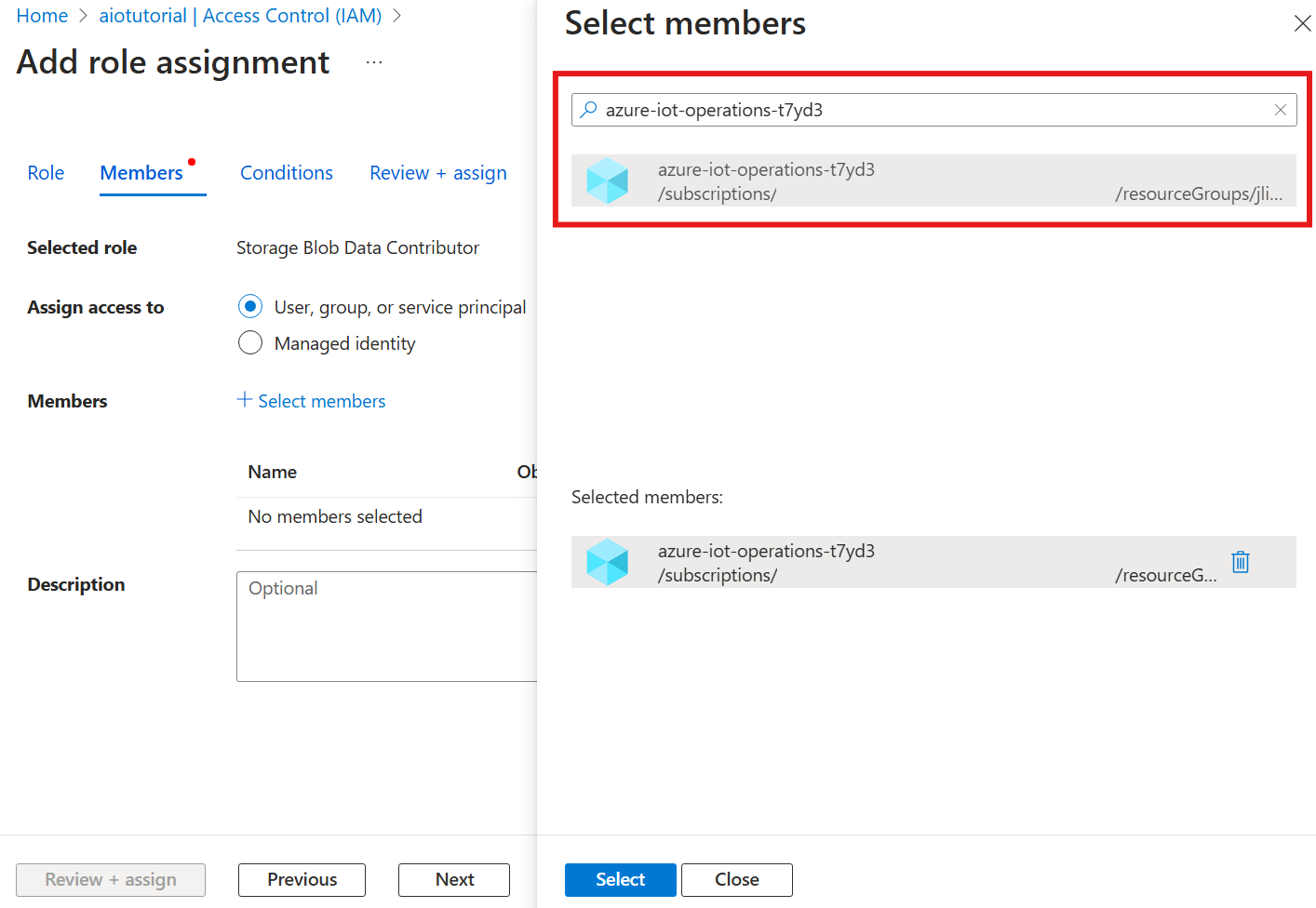
Terminez l’attribution avec Vérifier + attribuer.
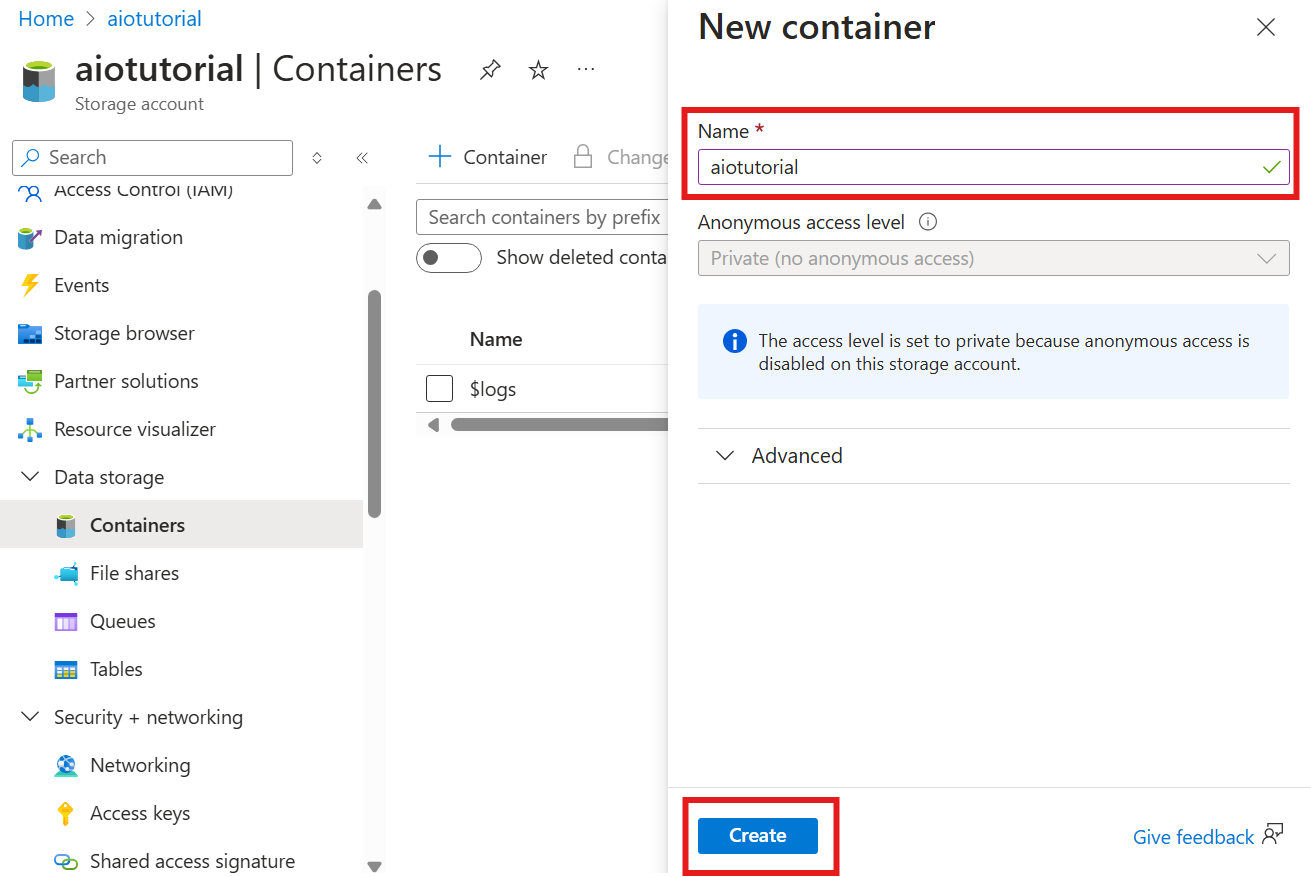
Créer un conteneur dans le compte de stockage
Dans le compte de stockage, accédez au volet Conteneurs et sélectionnez + Conteneur. Pour ce tutoriel, nommez le conteneur aiotutorial. Sélectionnez Créer pour créer le conteneur.
Obtenir le nom et l’espace de noms du registre de schémas
Pour charger le schéma dans Opérations Azure IoT, vous devez connaître le nom et l’espace de noms du registre de schémas. Vous pouvez obtenir ces informations à l’aide d’Azure CLI.
Exécutez la commande suivante pour obtenir le nom et l’espace de noms du registre de schémas. Remplacez les espaces réservés par vos valeurs.
az iot ops schema registry list -g <RESOURCE_GROUP> --query "[0].{name: name, namespace: properties.namespace}" -o tsv
La sortie doit ressembler à ceci :
<REGISTRY_NAME> <SCHEMA_NAMESPACE>
Enregistrez les valeurs pour les étapes suivantes.
Charger le schéma dans Opérations Azure IoT
Dans le guide de démarrage rapide, les données provenant de la ressource de four ressemblent à ce qui suit :
{
"Temperature": {
"SourceTimestamp": "2024-11-15T21:40:28.5062427Z",
"Value": 6416
},
"FillWeight": {
"SourceTimestamp": "2024-11-15T21:40:28.5063811Z",
"Value": 6416
},
"EnergyUse": {
"SourceTimestamp": "2024-11-15T21:40:28.506383Z",
"Value": 6416
}
}
Le format de schéma requis pour Delta Lake est un objet JSON qui suit le format de sérialisation de schéma Delta Lake. Le schéma doit définir la structure des données, y compris les types et les propriétés de chaque champ. Pour plus d’informations sur le format du schéma, consultez la documentation sur le format de sérialisation de schéma Delta Lake.
Conseil
Pour générer le schéma à partir d’un exemple de fichier de données, utilisez Schema Gen Helper.
Pour ce tutoriel, le schéma des données ressemble à ceci :
{
"$schema": "Delta/1.0",
"type": "object",
"properties": {
"type": "struct",
"fields": [
{
"name": "Temperature",
"type": {
"type": "struct",
"fields": [
{
"name": "SourceTimestamp",
"type": "timestamp",
"nullable": false,
"metadata": {}
},
{
"name": "Value",
"type": "integer",
"nullable": false,
"metadata": {}
}
]
},
"nullable": false,
"metadata": {}
},
{
"name": "FillWeight",
"type": {
"type": "struct",
"fields": [
{
"name": "SourceTimestamp",
"type": "timestamp",
"nullable": false,
"metadata": {}
},
{
"name": "Value",
"type": "integer",
"nullable": false,
"metadata": {}
}
]
},
"nullable": false,
"metadata": {}
},
{
"name": "EnergyUse",
"type": {
"type": "struct",
"fields": [
{
"name": "SourceTimestamp",
"type": "timestamp",
"nullable": false,
"metadata": {}
},
{
"name": "Value",
"type": "integer",
"nullable": false,
"metadata": {}
}
]
},
"nullable": false,
"metadata": {}
}
]
}
}
Enregistrez-le en tant que fichier nommé opcua-schema.json.
Ensuite, chargez le schéma dans Opérations Azure IoT à l’aide d’Azure CLI. Remplacez les espaces réservés par vos valeurs.
az iot ops schema create -n opcua-schema -g <RESOURCE_GROUP> --registry <REGISTRY_NAME> --format delta --type message --version-content opcua-schema.json --ver 1
Cela crée un schéma nommé opcua-schema dans le registre Opérations Azure IoT avec la version 1.
Pour vérifier que le schéma est chargé, dressez la liste des versions de schéma à l’aide d’Azure CLI.
az iot ops schema version list -g <RESOURCE_GROUP> --schema opcua-schema --registry <REGISTRY_NAME>
Créer un point de terminaison de flux de données
Le point de terminaison du flux de données est la destination où les données sont envoyées. En l’occurrence, les données sont envoyées à Azure Data Lake Storage Gen 2. La méthode d’authentification est l’identité managée affectée par le système, que vous avez configurée afin de disposer des autorisations appropriées pour écrire dans le compte de stockage.
Créez un point de terminaison de flux de données à l’aide de Bicep. Remplacez les espaces réservés par vos valeurs.
// Replace with your values
param aioInstanceName string = '<AIO_INSTANCE_NAME>'
param customLocationName string = '<CUSTOM_LOCATION_NAME>'
// Tutorial specific values
param endpointName string = 'adls-gen2-endpoint'
param host string = 'https://<ACCOUNT>.blob.core.windows.net'
resource aioInstance 'Microsoft.IoTOperations/instances@2024-11-01' existing = {
name: aioInstanceName
}
resource customLocation 'Microsoft.ExtendedLocation/customLocations@2021-08-31-preview' existing = {
name: customLocationName
}
resource adlsGen2Endpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-11-01' = {
parent: aioInstance
name: endpointName
extendedLocation: {
name: customLocation.id
type: 'CustomLocation'
}
properties: {
endpointType: 'DataLakeStorage'
dataLakeStorageSettings: {
host: host
authentication: {
method: 'SystemAssignedManagedIdentity'
systemAssignedManagedIdentitySettings: {}
}
}
}
}
Enregistrez le fichier sous adls-gen2-endpoint.bicep et déployez-le à l’aide d’Azure CLI.
az deployment group create -g <RESOURCE_GROUP> --template-file adls-gen2-endpoint.bicep
Créer un flux de données
Pour envoyer des données à Azure Data Lake Storage Gen 2, vous devez créer un flux de données qui lit les données du serveur OPC UA et les écrit dans le compte de stockage. Aucune transformation n’est nécessaire dans ce cas ; les données sont écrites telles quelles.
Créez un flux de données à l’aide de Bicep. Remplacez les espaces réservés par vos valeurs.
// Replace with your values
param aioInstanceName string = '<AIO_INSTANCE_NAME>'
param customLocationName string = '<CUSTOM_LOCATION_NAME>'
param schemaNamespace string = '<SCHEMA_NAMESPACE>'
// Tutorial specific values
param schema string = 'opcua-schema'
param schemaVersion string = '1'
param dataflowName string = 'tutorial-adls-gen2'
param assetName string = 'oven'
param endpointName string = 'adls-gen2-endpoint'
param containerName string = 'aiotutorial'
param serialFormat string = 'Delta'
resource aioInstance 'Microsoft.IoTOperations/instances@2024-11-01' existing = {
name: aioInstanceName
}
resource customLocation 'Microsoft.ExtendedLocation/customLocations@2021-08-31-preview' existing = {
name: customLocationName
}
// Pointer to the default data flow profile
resource defaultDataflowProfile 'Microsoft.IoTOperations/instances/dataflowProfiles@2024-11-01' existing = {
parent: aioInstance
name: 'default'
}
resource adlsEndpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-11-01' existing = {
parent: aioInstance
name: endpointName
}
resource defaultDataflowEndpoint 'Microsoft.IoTOperations/instances/dataflowEndpoints@2024-11-01' existing = {
parent: aioInstance
name: 'default'
}
resource asset 'Microsoft.DeviceRegistry/assets@2024-11-01' existing = {
name: assetName
}
resource dataflow 'Microsoft.IoTOperations/instances/dataflowProfiles/dataflows@2024-11-01' = {
// Reference to the parent data flow profile, the default profile in this case
// Same usage as profileRef in Kubernetes YAML
parent: defaultDataflowProfile
name: dataflowName
extendedLocation: {
name: customLocation.id
type: 'CustomLocation'
}
properties: {
mode: 'Enabled'
operations: [
{
operationType: 'Source'
sourceSettings: {
endpointRef: defaultDataflowEndpoint.name
assetRef: asset.name
dataSources: ['azure-iot-operations/data/${assetName}']
}
}
// Transformation optional
{
operationType: 'BuiltInTransformation'
builtInTransformationSettings: {
serializationFormat: serialFormat
schemaRef: 'aio-sr://${schemaNamespace}/${schema}:${schemaVersion}'
map: [
{
type: 'PassThrough'
inputs: [
'*'
]
output: '*'
}
]
}
}
{
operationType: 'Destination'
destinationSettings: {
endpointRef: adlsEndpoint.name
dataDestination: containerName
}
}
]
}
}
Enregistrez le fichier sous adls-gen2-dataflow.bicep et déployez-le à l’aide d’Azure CLI.
az deployment group create -g <RESOURCE_GROUP> --template-file adls-gen2-dataflow.bicep
Vérifier les données dans Azure Data Lake Storage Gen 2
Dans le compte de stockage, accédez au volet Conteneurs et sélectionnez le conteneur aiotutorialque vous avez créé. Vous devez voir un dossier nommé aiotutorial, et à l’intérieur de celui-ci doivent figurer des fichiers Parquet avec les données du serveur OPC UA. Les noms de fichiers sont au format part-00001-44686130-347f-4c2c-81c8-eb891601ef98-c000.snappy.parquet.
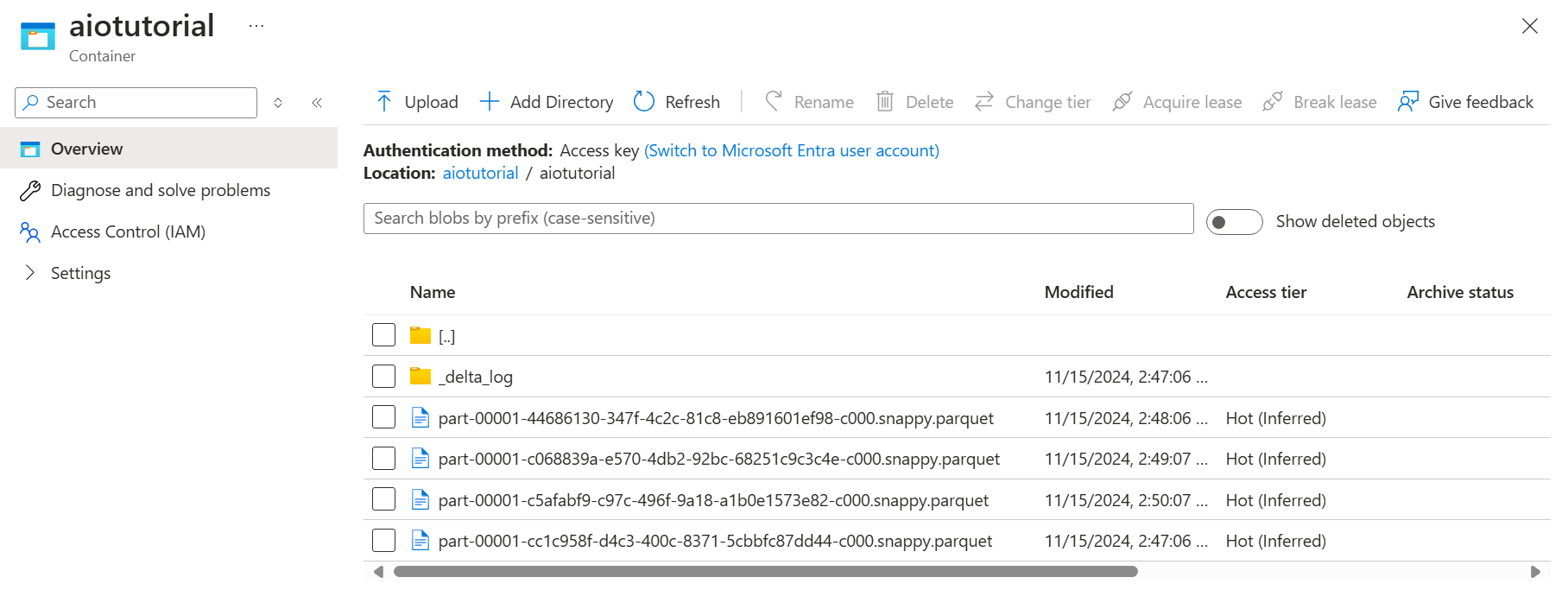
Pour afficher le contenu des fichiers, sélectionnez chaque fichier puis Modifier.
Le contenu ne s’affiche pas correctement dans le portail Azure, mais vous pouvez télécharger le fichier et l’ouvrir dans un outil tel que Parquet Viewer.