Guide de dimensionnement pour le cluster Azure HDInsight Interactive Query (Hive LLAP)
Ce document décrit le dimensionnement du cluster Interactive Query HDInsight (cluster Hive LLAP) pour une charge de travail classique, dans le but d’obtenir des performances raisonnables. Notez que les recommandations fournies dans ce document sont génériques et des indications ainsi que des charges de travail spécifiques peuvent nécessiter un paramétrage spécifique.
Types de machines virtuelles Azure par défaut pour le cluster HDInsight Interactive Query (LLAP)
| Type de nœud | Instance | Taille |
|---|---|---|
| Head | D13 v2 | 8 vcpus, 56 Go de RAM, 400 Go de SSD |
| Worker | D14 v2 |
16 vcpus, 112 Go de RAM, 800 Go de SSD |
| ZooKeeper | A4 v2 | 4 vcpus, 8 Go de RAM, 40 Go de SSD |
Remarque : Toutes les valeurs de configuration recommandées sont basées sur le nœud Worker de type D14 v2
Configuration :
| Clé de configuration | Valeur recommandée | Description |
|---|---|---|
| yarn.nodemanager.resource.memory-mb | 102 400 (Mo) | Mémoire totale donnée, en Mo, pour tous les conteneurs YARN sur un nœud |
| yarn.scheduler.maximum-allocation-mb | 102 400 (Mo) | Allocation maximale pour chaque requête de conteneur au gestionnaire des ressources, en Mo. Les requêtes de mémoire de valeur supérieure à celle-ci ne sont pas prises en compte |
| yarn.scheduler.maximum-allocation-vcores | 12 | Nombre maximal de cœurs de processeur pour chaque requête de conteneur adressée au gestionnaire des ressources. Les requêtes de mémoire de valeur supérieure à celle-ci ne sont pas prises en compte. |
| yarn.nodemanager.resource.cpu-vcores | 12 | Nombre de cœurs de processeur par NodeManager pouvant être alloués aux conteneurs. |
| yarn.scheduler.capacity.root.llap.capacity | 85 (%) | Allocation de la capacité YARN pour la file d’attente LLAP |
| tez.am.resource.memory.mb | 4 096 (Mo) | Quantité de mémoire (en Mo) que doit utiliser le AppMaster Tez |
| hive.server2.tez.sessions.per.default.queue | <number_of_worker_nodes> | Nombre de sessions pour chaque file d’attente nommée dans hive.server2.tez.default.queues. Ce nombre correspond au nombre de coordinateurs de requêtes (AppMaster Tez) |
| hive.tez.container.size | 4 096 (Mo) | Taille du conteneur Tez spécifiée en Mo |
| hive.llap.daemon.num.executors | 19 | Nombre d’exécuteurs par démon LLAP |
| hive.llap.io.threadpool.size | 19 | Taille du pool de threads pour les exécuteurs |
| hive.llap.daemon.yarn.container.mb | 81 920 (Mo) | Mémoire totale, en Mo, utilisée par les démons LLAP individuels (quantité de mémoire par démon) |
| hive.llap.io.memory.size | 24 2688 (Mo) | Taille, en Mo, du cache affecté à chaque démon LLAP, si le cache SSD est activé |
| hive.auto.convert.join.noconditionaltask.size | 2 048 (Mo) | Taille de la mémoire pour la jointure de mappage, en Mo |
Composants/Architecture LLAP :
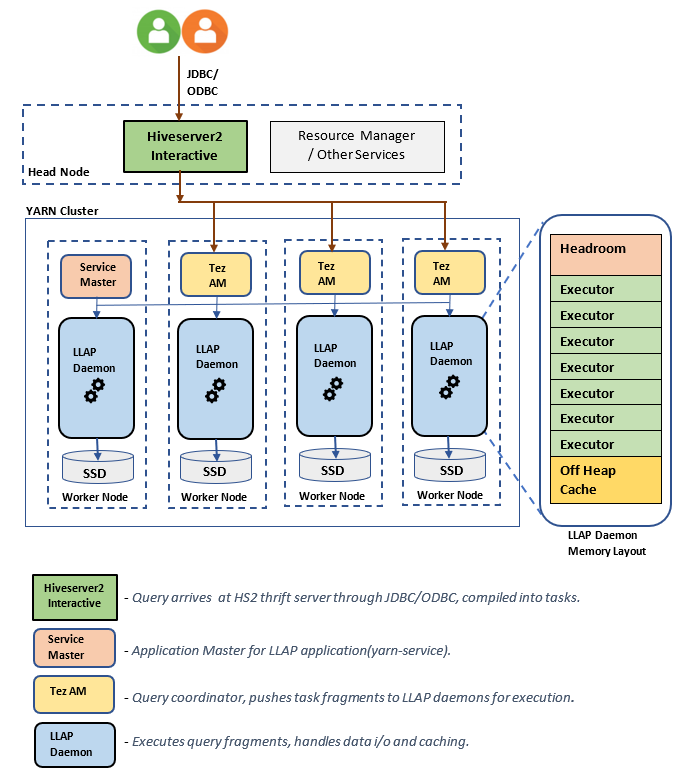
Estimation des tailles de démons LLAP :
1. Détermination de l’allocation de mémoire YARN totale pour tous les conteneurs sur un nœud
Configuration : yarn.nodemanager.resource.memory-mb
Cette valeur indique la quantité maximale de mémoire pouvant être utilisée par les conteneurs YARN sur chaque nœud, en Mo. La valeur spécifiée doit être inférieure à la quantité totale de mémoire physique sur ce nœud.
Mémoire totale pour tous les conteneurs YARN sur un nœud = (mémoire physique totale - mémoire pour le système d’exploitation + autres services)
Définissez cette valeur sur environ 90 % de l’espace de mémoire RAM disponible.
La valeur recommandée est de 102 400 Mo pour D14 v2.
2. Détermination de la quantité maximale de mémoire par requête de conteneur YARN
Configuration : yarn.scheduler.maximum-allocation-mb
Cette valeur indique l’allocation maximale pour chaque requête de conteneur au gestionnaire des ressources, en Mo. Les requêtes de mémoire de taille supérieure à celle-ci ne sont pas prises en compte. Le gestionnaire des ressources peut fournir de la mémoire aux conteneurs par incréments de yarn.scheduler.minimum-allocation-mb et ne peut pas dépasser la taille spécifiée par yarn.scheduler.maximum-allocation-mb. La valeur spécifiée ne doit pas être supérieure à la mémoire totale donnée pour tous les conteneurs sur le nœud spécifiée par yarn.nodemanager.resource.memory-mb.
Pour les nœuds Worker D14 v2, la valeur recommandée est de 102 400 Mo
3. Détermination de la quantité maximale de vcores par requête de conteneur YARN
Configuration : yarn.scheduler.maximum-allocation-vcores
Cette valeur indique le nombre maximal de cœurs de processeur virtuel pour chaque requête de conteneur adressée au gestionnaire des ressources. Demander un nombre plus élevé de vcores que cette valeur n’aura pas d’effet. Il s’agit d’une propriété globale du planificateur YARN. Pour le conteneur démon LLAP, cette valeur peut être définie sur 75 % du total disponible vcores. Les 25 % restants doivent être réservés à NodeManager, DataNode et d’autres services s’exécutant sur les nœuds Worker.
Il existe des 16 vcores sur VMs D14 v2 et 75 % du total 16 vcores peut être utilisé par le conteneur de démon LLAP.
Pour D14 v2, la valeur recommandée est 12.
4. Nombre de requêtes simultanées
Configuration : hive.server2.tez.sessions.per.default.queue
Cette valeur de configuration détermine le nombre de sessions Tez pouvant être lancées en parallèle. Ces sessions Tez sont lancées pour chacune des files d'attente spécifiées par « hive.server2.tez.default.queues ». Cela correspond au nombre d’AM Tez (coordinateurs de requêtes). Nous vous recommandons d’utiliser le même nombre de nœuds Worker. Le nombre d’AM Tez peut être supérieur au nombre de nœuds du démon LLAP. La principale responsabilité des AM Tez consiste à coordonner l’exécution de la requête et à affecter des fragments de plan de requête aux démons LLAP correspondants, à des fins d’exécution. Conservez cette valeur comme multiple de nombreux nœuds de démon LLAP pour obtenir un débit plus élevé.
Le cluster HDInsight par défaut a quatre démons LLAP en cours d’exécution sur quatre nœuds Worker ; la valeur recommandée est donc 4.
Curseur de l’interface utilisateur Ambari pour la variable de configuration Hive hive.server2.tez.sessions.per.default.queue:
5. Taille du AppMaster Tez et du conteneur Tez
Configuration : tez.am.resource.memory.mb, hive.tez.container.size
tez.am.resource.memory.mb : définit la taille du AppMaster Tez.
La valeur recommandée est de 4 096 Mo.
hive.tez.container.size : définit la quantité de mémoire donnée pour le conteneur Tez. Cette valeur doit être comprise entre la taille minimale du conteneur YARN (yarn.scheduler.minimum-allocation-mb) et la taille maximale du conteneur YARN (yarn.scheduler.maximum-allocation-mb). Les exécuteurs du démon LLAP utilisent cette valeur pour limiter l’utilisation de la mémoire par exécuteur.
La valeur recommandée est de 4 096 Mo.
6. Allocation de la capacité de la file d’attente LLAP
Configuration : yarn.scheduler.capacity.root.llap.capacity
Cette valeur indique un pourcentage de capacité octroyé à la file d’attente LLAP. Les allocations de capacité peuvent avoir des valeurs différentes pour les différentes charges de travail en fonction de la configuration des files d’attente YARN. Si votre charge de travail est une opération en lecture seule, la définir sur une valeur allant jusqu’à 90 % de la capacité doit fonctionner. Toutefois, si votre charge de travail combine des opérations de mise à jour/suppression/fusion à l’aide de tables managées, il est recommandé de définir la capacité de la file d’attente LLAP sur 85 %. Les 15 % de capacité restante peuvent être utilisés par d’autres tâches, par exemple le compactage, pour allouer des conteneurs à partir de la file d’attente par défaut. Ainsi, les tâches de la file d’attente par défaut ne priveront pas les ressources YARN.
Pour les nœuds Worker D14v2, la valeur recommandée pour la file d’attente LLAP est 85.
(Pour les charges de travail en lecture seule, elle peut être augmentée jusqu’à 90, comme il convient.)
7. Taille du conteneur du démon LLAP
Configuration : hive.llap.daemon.yarn.container.mb
Le démon LLAP est exécuté en tant que conteneur YARN sur chaque nœud Worker. La taille totale de la mémoire pour le conteneur du démon LLAP dépend des facteurs suivants,
- Configurations de la taille du conteneur YARN (yarn.scheduler.minimum-allocation-mb, yarn.scheduler.maximum-allocation-mb, yarn.nodemanager.resource.memory-mb)
- Nombre de AM Tez sur un nœud
- Mémoire totale configurée pour tous les conteneurs sur un nœud et capacité de la file d’attente LLAP
La mémoire requise par les AppMaster Tez (AM Tez) peut être calculée comme suit.
L’AM Tez agit comme coordinateur des requêtes et le nombre d’AM Tez doit être configuré en fonction de nombreuses requêtes simultanées à servir. En théorie, nous pouvons considérer un AM TEZ par nœud Worker. Toutefois, il est possible que vous rencontriez plusieurs AM Tez sur un nœud Worker. À des fins de calcul, nous supposons une distribution uniforme des AM Tez sur tous les nœuds Daemon LLAP ou nœuds Worker.
Il est recommandé d’avoir 4 Go de mémoire par AM Tez.
Nombre d’AM Tez = valeur spécifiée par la configuration Hive hive.server2.tez.sessions.per.default.queue.
Nombre de nœuds Daemon LLAP = spécifiés par la variable env num_llap_nodes_for_llap_daemons dans l’interface utilisateur Ambari.
Taille du conteneur de l’AM Tez = valeur indiquée par la config Tez tez.am.resource.memory.mb.
Mémoire d’AM Tez par nœud = (ceil(Nombre d’AM Tez /Nombre de nœuds LLAP Daemon)x Taille du conteneur de l’AM Tez **)**
Pour D14 v2, la configuration par défaut comprend quatre nœuds AM Tez et quatre nœuds LLAP daemon.
Mémoire d’AM Tez par nœud = (ceil(4/4) x 4 Go) = 4 Go
La mémoire totale disponible pour la file d’attente LLAP par nœud Worker peut être calculée comme suit :
Cette valeur dépend de la quantité totale de mémoire disponible pour tous les conteneurs YARN sur un nœud (yarn.nodemanager.resource.memory-mb) et du pourcentage de capacité configuré pour la file d’attente LLAP (yarn.scheduler.capacity.root.llap.capacity).
Mémoire totale pour la file d’attente LLAP sur le nœud Worker = Mémoire totale disponible pour tous les conteneurs YARN sur un nœud x Pourcentage de la capacité de la file d’attente LLAP.
Pour D14 v2, cette valeur est de (100 Go x 0,85) = 85 Go.
La taille du conteneur de démon LLAP est calculée comme suit :
Taille du conteneur du démon LLAP = (Mémoire totale pour la file d'attente LLAP sur un nœud worker) – (Mémoire Tez AM par nœud) - (Taille du conteneur Service Master)
Il n’existe qu’un seul principal de service (applications principales pour le service LLAP) sur le cluster généré sur l’un des nœuds Worker. À des fins de calcul, nous considérons un seul principal de service par nœud Worker.
Pour les nœuds Worker D14 v2, HDI 4.0 : la valeur recommandée est de (85 Go - 4 Go -1 Go)) = 80 Go
8. Détermination du nombre d’exécuteurs par démon LLAP
Configuration : hive.llap.daemon.num.executors, hive.llap.io.threadpool.size
hive.llap.daemon.num.executors :
Cette configuration contrôle le nombre d’exécuteurs qui peuvent lancer des tâches en parallèle pour chaque démon LLAP. Cette valeur dépend du nombre de cœurs virtuels, de la quantité de mémoire utilisée par exécuteur et de la quantité totale de mémoire disponible pour le conteneur LLAP Daemon. Le nombre d’exécuteurs peut être sursouscrit à 120 % des vcores disponibles par nœud Worker. Toutefois, il doit être ajusté s’il ne répond pas aux besoins en mémoire en fonction de la mémoire requise par l’exécuteur et de la taille du conteneur LLAP Daemon.
Chaque exécuteur est équivalent à un conteneur Tez et peut consommer 4 Go (taille du conteneur Tez) de la mémoire. Tous les exécuteurs LLAP Daemon partagent la même mémoire du tas. En partant du principe que tous les exécuteurs n’exécutent pas les opérations gourmandes en mémoire en même temps, vous pouvez considérer 75 % de la taille du conteneur Tez (4 Go) par exécuteur. De cette façon, vous pouvez augmenter le nombre d’exécuteurs en donnant à chaque exécuteur moins de mémoire (par exemple, 3 Go) pour augmenter le parallélisme. Toutefois, il est recommandé d’ajuster ce paramètre pour votre charge de travail cible.
Les machines virtuelles D14 v2 comportent 16 cœurs virtuels. Pour D14 v2, la valeur recommandée pour le nombre d’exécuteurs est (16 vcores x 120 %) ~ = 19 sur chaque nœud Worker qui prend en compte 3 Go par exécuteur.
hive.llap.io.threadpool.size :
Cette valeur spécifie la taille du pool de threads pour les exécuteurs. Étant donné que les exécuteurs sont définis de manière fixe comme spécifié, leur nombre est égal à celui des exécuteurs par démon LLAP.
Pour D14 v2, la valeur recommandée est 19.
9. Détermination de la taille du cache du démon LLAP
Configuration : hive.llap.io.memory.size
La mémoire du conteneur du démon LLAP est constituée des composants suivants :
- La marge
- La mémoire de tas utilisée par les exécuteurs (Xmx)
- Le cache en mémoire par démon (sa taille de mémoire hors tas, non applicable lorsque le cache SSD est activé)
- La taille des métadonnées du cache en mémoire (applicable uniquement lorsque le cache SSD est activé)
Taille de la hauteur sous plafond : Cette taille indique une partie de la mémoire hors tas utilisée pour la surcharge de la VM Java (métaespace, pile de threads, gc structures de données, etc.). En règle générale, cette surcharge est d’environ 6 % de la taille du tas (Xmx). Par prudence, cette valeur peut être calculée comme correspondant à 6 % de la taille de la mémoire totale du démon LLAP.
Pour D14 v2, la valeur recommandée est : ceil(80 Go x 0,06) ~= 4 Go.
Taille du tas (Xmx) : Il s’agit de la quantité de mémoire de tas disponible pour tous les exécuteurs.
Taille totale du tas = nombre d’exécuteurs x 3 Go
Pour D14 v2, cette valeur est 19 x 3 Go = 57 Go
Ambari environment variable for LLAP heap size:

Lorsque le cache SSD est désactivé, le cache en mémoire est la quantité de mémoire restante après avoir retiré la taille de la marge et la taille du tas de la taille du conteneur du démon LLAP.
Le calcul de la taille du cache diffère lorsque le cache SSD est activé.
Le réglage hive.llap.io.allocator.mmap = true active la mise en cache SSD.
Lorsque le cache SSD est activé, une partie de la mémoire est utilisée pour stocker les métadonnées du cache SSD. Les métadonnées sont stockées en mémoire et doivent représenter environ 8 % de la taille du cache SSD.
Taille des métadonnées en mémoire du cache SSD = taille du conteneur LLAP Daemon - (marge + taille du tas)
Pour D14 v2, avec HDI 4.0, la taille des métadonnées en mémoire du cache SSD = 80 Go - (4 Go + 57 Go) = 19 Go
Compte tenu de la taille de la mémoire disponible pour le stockage des métadonnées du cache SSD, nous pouvons calculer la taille du cache SSD pouvant être prise en charge.
Taille des métadonnées en mémoire du cache SSD =taille du conteneur LLAP Deamon - (marge + taille du tas) = 19 Go
Taille du cache SSD = taille des métadonnées en mémoire pour le cache SSD (19 Go) / 0,08 (8 %)
Pour D14 v2 et HDI 4.0, la taille de cache SSD recommandée est de 19 Go x 0,08 = 237 Go
10. Réglage de la mémoire de jointure de mappage
Configuration : hive.auto.convert.join.noconditionaltask.size
Vérifiez que hive.auto.convert.join.noconditionaltask est activé pour que ce paramètre prenne effet.
Cette configuration détermine le seuil pour la sélection de MapJoin par l’optimiseur Hive qui considère le surabonnement de la mémoire d’autres exécuteurs comme plus d’espace pour les tables de hachage en mémoire afin d’autoriser davantage de conversions de mappage. En prenant 3 Go par exécuteur, cette taille peut être surabonnée à 3 Go, mais une partie de la mémoire du tas peut également être utilisée pour les tampons de tri, les mémoires tampons de lecture aléatoire, etc. par les autres opérations.
Ainsi, pour D14 v2, avec 3 Go de mémoire par exécuteur, il est recommandé de définir cette valeur sur 2 048 Mo.
(Remarque : cette valeur peut nécessiter des ajustements en fonction de votre charge de travail. La définition d’une valeur trop basse peut ne pas utiliser la fonctionnalité de conversion automatique. De plus, la définition d’une valeur trop haute peut entraîner des exceptions de mémoire insuffisante ou des pauses GC pouvant entraîner de mauvaises performances.)
11. Nombre de LLAP Daemon
Variables d’environnement Ambari : num_llap_nodes, num_llap_nodes_for_llap_daemons
num_llap_nodes - spécifie le nombre de nœuds utilisés par le service Hive LLAP, y compris les nœuds exécutant le LLAP Daemon, le LLAP du principal de service et l’application principale Tez (AM Tez).
num_llap_nodes_for_llap_daemons nombre spécifié de nœuds utilisés uniquement pour les LLAP Daemon. La taille des conteneurs du démon LLAP est définie sur un nœud d'ajustement maximum, il en résulte donc un démon llap sur chaque nœud.

Il est recommandé de conserver les deux valeurs comme le nombre de nœuds Worker dans le cluster Interactive Query.
Considérations pour la gestion des charges de travail
Si vous souhaitez activer la gestion de la charge de travail pour le LLAP, assurez-vous de réserver suffisamment de capacité pour que la gestion de la charge de travail fonctionne comme prévu. La gestion des charges de travail nécessite la configuration d’une file d’attente YARN personnalisée, en plus de la file d’attente llap. Assurez-vous de diviser la capacité totale des ressources du cluster entre la file d'attente llap et la file d'attente de gestion de la charge de travail en fonction des exigences de votre charge de travail.
La gestion des charges de travail génère dynamiquement des AM Tez lorsqu’un plan de ressources est activé.
Remarque :
- Les AM Tez ont été générées par l’activation d’un plan de ressources et consomment des ressources de la file d’attente de gestion des charges de travail, comme spécifié par
hive.server2.tez.interactive.queue. - Le nombre d’AM Tez dépend de la valeur de
QUERY_PARALLELISMspécifiée dans le plan de ressources. - Une fois la gestion de la charge de travail active, les AM Tez dans la file d’attente LLAP ne sont pas utilisées. Seules les AM Tez de la file d’attente de gestion des charges de travail sont utilisées pour la coordination des requêtes. Les AM Tez dans la file d’attente
llapsont utilisées lorsque la gestion de la charge de travail est désactivée.
Exemple : Capacité totale du cluster = 100 Go de mémoire, divisée entre le LLAP, la gestion des charges de travail et les files d’attente par défaut comme suit :
- Capacité de la file d’attente LLAP = 70 Go
- Capacité de la file d’attente de gestion des charges de travail = 20 Go
- Capacité de file d’attente par défaut = 10 Go
Avec une capacité de file d'attente de gestion de charge de travail de 20 Go, un plan de ressources peut spécifier une valeur QUERY_PARALLELISM égale à cinq, ce qui signifie que la gestion de charge de travail peut lancer cinq AM Tez avec une taille de conteneur de 4 Go chacun. Si QUERY_PARALLELISM est supérieure à la capacité, il est possible que certaines AM Tez ne répondent plus dans l’état ACCEPTED. Le serveur Hive 2 Interactive ne peut pas soumettre de fragments de requête aux Tez AM qui ne sont pas dans l'état RUNNING.
Étapes suivantes
Si la définition de ces valeurs n’a pas résolu votre problème, envisagez l’une des solutions suivantes...
Obtenez des réponses de la part d’experts Azure en faisant appel au Support de la communauté Azure.
Connectez-vous avec @AzureSupport, qui est le compte Microsoft Azure officiel pour améliorer l’expérience client en connectant la communauté Azure aux ressources appropriées : réponses, support technique et experts.
Si vous avez besoin d’une aide supplémentaire, vous pouvez envoyer une requête de support à partir du Portail Microsoft Azure. Sélectionnez Support dans la barre de menus, ou ouvrez le hub Aide + Support. Pour plus d’informations, consultez Création d’une demande de support Azure. L’accès au support relatif à la gestion et à la facturation des abonnements est inclus avec votre abonnement Microsoft Azure. En outre, le support technique est fourni avec l’un des plans de support Azure.
Autres références :