Corriger une erreur de mémoire insuffisante Apache Hive dans Azure HDInsight
Découvrez comment résoudre une erreur de mémoire insuffisante (OOM) dans Apache Hive lors du traitement de tables volumineuses en configurant les paramètres de mémoire Hive.
Exécuter une requête Apache Hive sur des tables de grande taille
Un client exécute une requête Hive :
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
Voici quelques caractéristiques de cette requête :
- T1 est un alias correspondant à une table volumineuse nommée TABLE1 qui comporte de nombreux types de colonnes au format de chaîne.
- Les autres tables ne sont pas si volumineuses, mais elles ont un grand nombre de colonnes.
- Toutes les tables sont associées les unes aux autres, parfois avec plusieurs colonnes dans TABLE1 et d’autres tables.
La requête Hive prend fin au bout de 26 minutes sur un cluster HDInsight à 24 nœuds A3. Le client a remarqué les messages d’avertissement suivants :
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
En utilisant le moteur d’exécution Apache Tez. La même requête a fonctionné pendant 15 minutes, puis a renvoyé l’erreur suivante :
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
L’erreur persiste lors de l’utilisation d’une machine virtuelle plus grande (par exemple, D12).
Déboguer l’erreur de mémoire insuffisante
Nos équipes d’ingénierie et de support technique ont trouvé qu’un des problèmes à l’origine de l’erreur de mémoire insuffisante était décrit dans Apache JIRA :
« Quand hive.auto.convert.join.noconditionaltask = true, nous vérifions noconditionaltask.size ; si la somme des tailles des tables dans la jointure de mappage est inférieure à noconditionaltask.size, le plan génère une jointure de mappage. Le problème ici est que le calcul ne prend pas en compte la surcharge introduite par une implémentation différente de HashTable comme résultats ; si la somme des tailles d’entrée est légèrement inférieure à la taille noconditionaltask, les requêtes rencontrent un problème de mémoire insuffisante. »
hive.auto.convert.join.noconditionaltask dans le fichier hive-site.xml avait la valeur true :
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
La jointure de mappage est sans doute la cause de l’erreur de mémoire insuffisante dans l’espace de tas Java. Comme expliqué dans le billet de blog Hadoop Yarn memory settings in HDInsight, lorsque le moteur d’exécution Tez est utilisé, l’espace de tas utilisé appartient en fait au conteneur Tez. Consultez l’image suivante décrivant la mémoire de conteneur Tez.
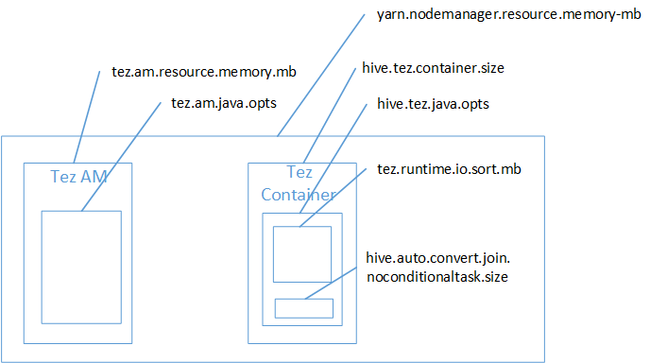
Comme le suggère le billet de blog, les deux paramètres de mémoire suivants définissent la mémoire de conteneur du tas : hive.tez.container.size et hive.tez.java.opts. D’après notre expérience, l’exception relative à une mémoire insuffisante ne signifie pas que la taille du conteneur est trop petite. Elle signifie que la taille du tas Java (hive.tez.java.opts) est trop petite. Par conséquent, lorsque vous voyez une erreur de mémoire insuffisante, vous pouvez essayer d’augmenter la valeur de hive.tez.java.opts. Si nécessaire, vous pouvez augmenter hive.tez.container.size. Le paramètre java.opts doit correspondre à environ 80 % de la taille de conteneur (container.size).
Notes
Le paramètre hive.tez.java.opts doit toujours être inférieur à hive.tez.container.size.
Comme une machine D12 a une mémoire de 28 Go, nous avons décidé d’utiliser une taille de conteneur de 10 Go (10 240 Mo) et d’affecter la valeur 80 % à java.opts :
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
Avec les nouveaux paramètres, la requête s’est correctement exécutée en moins de 10 minutes.
Étapes suivantes
L’obtention d’une erreur de mémoire insuffisante ne signifie pas nécessairement que la taille du conteneur est insuffisante. Vous devez plutôt configurer les paramètres de mémoire afin que la taille du tas soit augmentée et qu’elle représente au moins 80 % de la taille de la mémoire du conteneur. Pour optimiser les requêtes Hive, consultez Optimisation des requêtes Apache Hive pour Apache Hadoop dans HDInsight.