Architecture Apache Hadoop dans HDInsight
Apache Hadoop comprend deux composants principaux : Apache Hadoop Distributed File System (HDFS) pour le stockage, et Apache Hadoop Yet Another Resource Negotiator (YARN) pour le traitement. Ces capacités de stockage et de traitement permettent à un cluster d’exécuter les programmes MapReduce pour effectuer le traitement de données souhaité.
Notes
Un système HDFS n’est généralement pas déployé au sein du cluster HDInsight pour fournir le stockage. Une couche d’interface compatible HDFS est utilisée à la place par les composants Hadoop. La capacité de stockage réelle est fournie par Stockage Azure ou Azure Data Lake Storage. Pour Hadoop, les tâches MapReduce exécutées sur le cluster HDInsight sont traitées comme si un système HDFS était présent. Elles ne nécessitent par conséquent aucune modification pour prendre en charge leurs besoins en stockage. Dans Hadoop sur HDInsight, le stockage est externalisé, mais le traitement YARN reste un composant principal. Pour plus d’informations, consultez Présentation d’Azure HDInsight.
Cet article présente YARN et décrit comment il coordonne l’exécution des applications sur HDInsight.
Concepts de base d’Apache Hadoop YARN
YARN gouverne et orchestre le traitement des données dans Hadoop. YARN inclut deux services principaux qui s’exécutent en tant que processus sur des nœuds du cluster :
- ResourceManager
- NodeManager
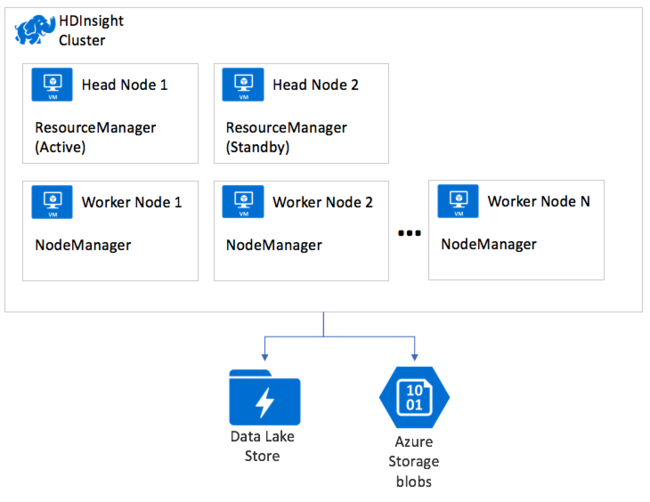
ResourceManager accorde des ressources de calcul de cluster aux applications telles que les tâches MapReduce. ResourceManager accorde ces ressources en tant que conteneurs, où chaque conteneur est composé d’une allocation de cœurs de processeur et de mémoire RAM. Si vous avez combiné toutes les ressources disponibles dans un cluster, puis avez distribué les cœurs et la mémoire dans des blocs, chaque bloc de ressources est un conteneur. Comme chaque nœud du cluster peut héberger un certain nombre de conteneurs, le nombre de conteneurs disponibles du cluster est limité. L’allocation de ressources dans un conteneur est configurable.
Quand une application MapReduce s’exécute sur un cluster, ResourceManager fournit à l’application les conteneurs dans lesquels elle doit s’exécuter. ResourceManager effectue le suivi de l’état de l’exécution des applications, de la capacité disponible sur le cluster et des applications au fur et à mesure qu’elles se terminent et libèrent leurs ressources.
ResourceManager exécute également un processus de serveur web qui fournit une interface utilisateur web pour superviser l’état des applications.
Quand un utilisateur soumet une application MapReduce à exécuter sur le cluster, l’application est soumise à ResourceManager. À son tour, ResourceManager alloue un conteneur sur les nœuds NodeManager disponibles. Ces nœuds représentent l’emplacement où l’application s’exécute réellement. Le premier conteneur alloué exécute une application spéciale, appelée ApplicationMaster. Celle-ci se charge de l’acquisition des ressources, sous la forme de conteneurs suivants, nécessaires pour exécuter l’application soumise. ApplicationMaster examine les phases de l’application (par exemple, la phase de mappage et la phase de réduction), ainsi que les facteurs permettant de déterminer la quantité de données à traiter. ApplicationMaster demande ensuite (négocie) les ressources auprès de ResourceManager pour le compte de l’application. ResourceManager accorde à son tour des ressources à partir des NodeManagers dans le cluster à ApplicationMaster qui peut les utiliser pour exécuter l’application.
Les NodeManagers exécutent les tâches qui forment l’application, puis informent ApplicationMaster de leur progression et de leur l’état. ApplicationMaster informe à son tour ResourceManager de l’état de l’application. ResourceManager retourne les résultats au client.
YARN sur HDInsight
Tous les types de clusters HDInsight déploient YARN. ResourceManager est déployé pour la haute disponibilité avec des instances principale et secondaire, qui s’exécutent respectivement sur le premier et le deuxième nœud de tête au sein du cluster. Seule une instance de ResourceManager est active à la fois. Les instances de NodeManager s’exécutent sur les nœuds de travail disponibles dans le cluster.
Suppression réversible
Pour annuler la suppression d’un fichier de votre compte de stockage, consultez :
Stockage Azure
- Suppression réversible pour les objets blob de Stockage Azure
- Annuler la suppression d’un objet blob
Azure Data Lake Storage Gen 1
Restore-AzDataLakeStoreDeletedItem
Azure Data Lake Storage Gen 2
Problèmes connus avec Azure Data Lake Storage Gen2
Purge de la corbeille
La valeur par défaut 0 de la propriété fs.trash.interval de HDFS>Advanced core-site doit être conservée, car vous ne devez pas stocker de données sur le système de fichiers local. Cette valeur n’affecte pas les comptes de stockage à distance (WASB, ADLS GEN1, ABFS).