Utiliser C# avec streaming MapReduce sur Apache Hadoop dans HDInsight
Découvrez comment utiliser C# pour créer une solution MapReduce dans HDInsight.
Le streaming Apache Hadoop vous permet d’exécuter des tâches MapReduce à l’aide d’un script ou d’un exécutable. Ici, .NET est utilisé pour implémenter le mappeur et le raccord de réduction pour une solution de comptage de mots.
.NET sur HDInsight
Les clusters HDInsight utilisent Mono (https://mono-project.com) pour exécuter les applications .NET. La version 4.2.1 de Mono est incluse dans la version 3.6 de HDInsight. Pour plus d’informations sur la version de Mono incluse dans HDInsight, consultez Composants Apache Hadoop disponibles avec les versions de HDInsight.
Pour plus d’informations sur la compatibilité Mono avec les versions de .NET Framework, consultez Compatibilité Mono.
Fonctionnement de la diffusion en continu Hadoop
Le processus de base utilisé pour la diffusion en continu dans ce document est la suivante :
- Hadoop transmet des données vers le mappeur (mapper.exe dans cet exemple) sur STDIN.
- Le mappeur traite les données et émet des paires clé/valeur séparées par des tabulations sur STDOUT.
- La sortie est lue par Hadoop, puis transmise au raccord de réduction (reducer.exe dans cet exemple) sur STDIN.
- Le raccord de réduction lit les paires clé/valeur séparées par des tabulations, traite les données, puis émet le résultat sous forme de paires clé/valeur séparées par des tabulations sur STDOUT.
- La sortie est lue par Hadoop et écrite dans le répertoire de sortie.
Pour plus d’informations sur la diffusion en continu, consultez l’article Diffusion en continu Hadoop.
Prérequis
Visual Studio.
Des connaissances en écriture et en génération de code C# qui cible .NET Framework 4.5.
Permet de charger des fichiers .exe dans le cluster. Les étapes de ce document utilisent Data Lake Tools pour Visual Studio pour télécharger les fichiers vers le stockage principal pour le cluster.
Si vous utilisez PowerShell, vous aurez besoin du module Az.
Un cluster Apache Hadoop sur HDInsight. Consultez Bien démarrer avec HDInsight sur Linux.
Le schéma d'URI de votre principal espace de stockage de clusters. Ce schéma serait
wasb://pour Stockage Azure,abfs://pour Azure Data Lake Storage Gen2 ouadl://pour Azure Data Lake Storage Gen1. Si l’option de transfert sécurisé était activée pour Stockage Azure ou Data Lake Storage Gen2, l’URI seraitwasbs://ouabfss://, respectivement.
Créer le mappeur
Dans Visual Studio, créez une nouvelle application console .NET Framework nommée mapper. Utilisez le code suivant pour l’application :
using System;
using System.Text.RegularExpressions;
namespace mapper
{
class Program
{
static void Main(string[] args)
{
string line;
//Hadoop passes data to the mapper on STDIN
while((line = Console.ReadLine()) != null)
{
// We only want words, so strip out punctuation, numbers, etc.
var onlyText = Regex.Replace(line, @"\.|;|:|,|[0-9]|'", "");
// Split at whitespace.
var words = Regex.Matches(onlyText, @"[\w]+");
// Loop over the words
foreach(var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t1",word);
}
}
}
}
}
Une fois que vous avez créé l’application, générez-la pour produire le fichier /bin/Debug/mapper.exe dans le répertoire du projet.
Créer le raccord de réduction
Dans Visual Studio, créez une nouvelle application console .NET Framework nommée reducer. Utilisez le code suivant pour l’application :
using System;
using System.Collections.Generic;
namespace reducer
{
class Program
{
static void Main(string[] args)
{
//Dictionary for holding a count of words
Dictionary<string, int> words = new Dictionary<string, int>();
string line;
//Read from STDIN
while ((line = Console.ReadLine()) != null)
{
// Data from Hadoop is tab-delimited key/value pairs
var sArr = line.Split('\t');
// Get the word
string word = sArr[0];
// Get the count
int count = Convert.ToInt32(sArr[1]);
//Do we already have a count for the word?
if(words.ContainsKey(word))
{
//If so, increment the count
words[word] += count;
} else
{
//Add the key to the collection
words.Add(word, count);
}
}
//Finally, emit each word and count
foreach (var word in words)
{
//Emit tab-delimited key/value pairs.
//In this case, a word and a count of 1.
Console.WriteLine("{0}\t{1}", word.Key, word.Value);
}
}
}
}
Une fois que vous avez créé l’application, générez-la pour produire le fichier /bin/Debug/reducer.exe dans le répertoire du projet.
Téléchargement vers le stockage
Ensuite, vous devez charger les applications mapper et reducer sur le stockage HDInsight.
Dans Visual Studio, sélectionnez Affichage>Explorateur de serveurs.
Cliquez avec le bouton droit sur Azure, sélectionnez Se connecter à un abonnement Microsoft Azure... , puis terminez le processus de connexion.
Développez le cluster HDInsight sur lequel vous souhaitez déployer cette application. Une entrée avec le texte (compte de stockage par défaut) est répertoriée.
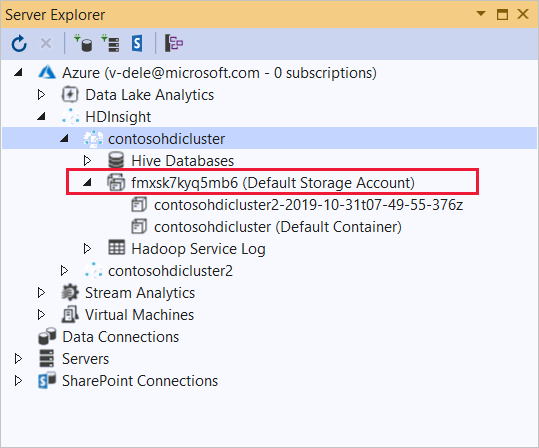
Si l’entrée (compte de stockage par défaut) peut être développée, vous utilisez un compte de stockage Azure en tant que stockage par défaut pour le cluster. Pour afficher les fichiers sur le stockage par défaut pour le cluster, développez l’entrée, puis double-cliquez sur le (conteneur par défaut) .
Si l’entrée (compte de stockage par défaut) ne peut pas être développée, vous utilisez Azure Data Lake Storage en tant que stockage par défaut pour le cluster. Pour afficher les fichiers sur le stockage par défaut pour le cluster, double-cliquez sur l’entrée (compte de stockage par défaut) .
Pour charger les fichiers .exe, appliquez l’une des méthodes suivantes :
Si vous utilisez un compte de stockage Azure, sélectionnez l’icône Télécharger un objet Blob.

Dans la boîte de dialogue Télécharger un nouveau fichier, sous Nom de fichier, sélectionnez Parcourir. Dans la boîte de dialogue Télécharger un objet Blob, accédez au dossier bin\debug pour le projet mapper, puis sélectionnez le fichier mapper.exe. Enfin, sélectionnez Ouvrir, puis OK pour terminer le téléchargement.
Pour Azure Data Lake Storage, cliquez avec le bouton droit sur une zone vide de la liste des fichiers, puis sélectionnez Charger. Enfin, sélectionnez le fichier mapper.exe et cliquez sur Ouvrir.
Une fois que le chargement de mapper.exe est terminé, répétez le processus de chargement pour le fichier reducer.exe.
Exécuter un travail : Utilisation d’une session SSH
La procédure suivante décrit comment exécuter un travail MapReduce à l’aide d’une session SSH :
Utilisez la commande ssh pour vous connecter à votre cluster. Modifiez la commande ci-dessous en remplaçant CLUSTERNAME par le nom de votre cluster, puis entrez la commande :
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netExécutez une des commandes suivantes pour démarrer la tâche MapReduce :
Si le stockage par défaut est Stockage Azure :
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files wasbs:///mapper.exe,wasbs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutSi le stockage par défaut est Data Lake Storage Gen1 :
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files adl:///mapper.exe,adl:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountoutSi le stockage par défaut est Data Lake Storage Gen2 :
yarn jar /usr/hdp/current/hadoop-mapreduce-client/hadoop-streaming.jar \ -files abfs:///mapper.exe,abfs:///reducer.exe \ -mapper mapper.exe \ -reducer reducer.exe \ -input /example/data/gutenberg/davinci.txt \ -output /example/wordcountout
La liste suivante fournit la signification de chaque paramètre et option :
Paramètre Description hadoop-streaming.jar Indique le fichier jar contenant la fonctionnalité MapReduce de streaming. -files Indique les fichiers mapper.exe et reducer.exe pour ce travail. La déclaration de protocole wasbs:///,adl:///ouabfs:///devant chaque fichier correspond au chemin d’accès à la racine du stockage par défaut pour le cluster.-mapper Indique le fichier qui implémente le mappeur. -reducer Indique le fichier qui implémente le raccord de réduction. -input Indique les données d’entrée. -output Indique le répertoire de sortie. Une fois le travail MapReduce terminé, utilisez la commande suivante pour afficher les résultats :
hdfs dfs -text /example/wordcountout/part-00000Le texte suivant est un exemple de données renvoyées par cette commande :
you 1128 young 38 younger 1 youngest 1 your 338 yours 4 yourself 34 yourselves 3 youth 17
Exécuter un travail : Utilisation de PowerShell
Utilisez le script PowerShell suivant pour exécuter une tâche MapReduce et télécharger les résultats.
# Login to your Azure subscription
$context = Get-AzContext
if ($context -eq $null)
{
Connect-AzAccount
}
$context
# Get HDInsight info
$clusterName = Read-Host -Prompt "Enter the HDInsight cluster name"
$creds=Get-Credential -Message "Enter the login for the cluster"
# Path for job output
$outputPath="/example/wordcountoutput"
# Progress indicator
$activity="C# MapReduce example"
Write-Progress -Activity $activity -Status "Getting cluster information..."
#Get HDInsight info so we can get the resource group, storage, etc.
$clusterInfo = Get-AzHDInsightCluster -ClusterName $clusterName
$resourceGroup = $clusterInfo.ResourceGroup
$storageActArr=$clusterInfo.DefaultStorageAccount.split('.')
$storageAccountName=$storageActArr[0]
$storageType=$storageActArr[1]
# Progress indicator
#Define the MapReduce job
# Note: using "/mapper.exe" and "/reducer.exe" looks in the root
# of default storage.
$jobDef=New-AzHDInsightStreamingMapReduceJobDefinition `
-Files "/mapper.exe","/reducer.exe" `
-Mapper "mapper.exe" `
-Reducer "reducer.exe" `
-InputPath "/example/data/gutenberg/davinci.txt" `
-OutputPath $outputPath
# Start the job
Write-Progress -Activity $activity -Status "Starting MapReduce job..."
$job=Start-AzHDInsightJob `
-ClusterName $clusterName `
-JobDefinition $jobDef `
-HttpCredential $creds
#Wait for the job to complete
Write-Progress -Activity $activity -Status "Waiting for the job to complete..."
Wait-AzHDInsightJob `
-ClusterName $clusterName `
-JobId $job.JobId `
-HttpCredential $creds
Write-Progress -Activity $activity -Completed
# Download the output
if($storageType -eq 'azuredatalakestore') {
# Azure Data Lake Store
# Fie path is the root of the HDInsight storage + $outputPath
$filePath=$clusterInfo.DefaultStorageRootPath + $outputPath + "/part-00000"
Export-AzDataLakeStoreItem `
-Account $storageAccountName `
-Path $filePath `
-Destination output.txt
} else {
# Az.Storage account
# Get the container
$container=$clusterInfo.DefaultStorageContainer
#NOTE: This assumes that the storage account is in the same resource
# group as HDInsight. If it is not, change the
# --ResourceGroupName parameter to the group that contains storage.
$storageAccountKey=(Get-AzStorageAccountKey `
-Name $storageAccountName `
-ResourceGroupName $resourceGroup)[0].Value
#Create a storage context
$context = New-AzStorageContext `
-StorageAccountName $storageAccountName `
-StorageAccountKey $storageAccountKey
# Download the file
Get-AzStorageBlobContent `
-Blob 'example/wordcountoutput/part-00000' `
-Container $container `
-Destination output.txt `
-Context $context
}
Ce script vous invite à entrer le nom et le mot de passe du compte de connexion du cluster, ainsi que le nom du cluster HDInsight. Une fois que le travail est terminé, la sortie est téléchargée sous la forme d’un fichier nommé output.txt. Le texte suivant constitue un exemple des données contenues dans le fichier output.txt :
you 1128
young 38
younger 1
youngest 1
your 338
yours 4
yourself 34
yourselves 3
youth 17