Orchestration des tâches Apache Flink® au moyen du gestionnaire du flux de travail géré par Azure Data Factory (avec Apache Airflow)
Remarque
Nous allons mettre hors service Azure HDInsight sur AKS le 31 janvier 2025. Avant le 31 janvier 2025, vous devrez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent afin d’éviter leur arrêt brutal. Les clusters restants de votre abonnement seront arrêtés et supprimés de l’hôte.
Seul le support de base est disponible jusqu’à la date de mise hors service.
Important
Cette fonctionnalité est disponible actuellement en mode Aperçu. Les Conditions d’utilisation supplémentaires pour les préversions de Microsoft Azure contiennent davantage de conditions légales qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou ne se trouvant pas encore en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les Informations sur la préversion d’Azure HDInsight sur AKS. Pour toute question ou pour des suggestions à propos des fonctionnalités, veuillez envoyer vos requêtes et leurs détails sur AskHDInsight, et suivez-nous sur la Communauté Azure HDInsight pour plus de mises à jour.
Cet article traite de la gestion d’une tâche Flink à l’aide de l’API REST Azure et du pipeline de données d’orchestration avec le gestionnaire du flux de travail géré par Azure Data Factory. Le service de gestionnaire du flux de travail géré par Azure Data Factory est un moyen simple et efficace de créer et de gérer des environnements Apache Airflow, ce qui vous permet d’exécuter facilement des pipelines de données à grande échelle.
Apache Airflow est une plateforme open source qui crée, planifie et supervise par programmation des workflows de données complexes. Elle vous permet de définir un ensemble de tâches, appelées opérateurs, pouvant être combinées en graphes orientés acyclique (DAG) pour représenter des pipelines de données.
Le diagramme suivant montre la sélection élective d’Airflow, de Key Vault et de HDInsight sur AKS dans Azure.

Plusieurs principaux de service Azure sont créés en fonction de l’étendue pour limiter l’accès dont elle a besoin et pour gérer indépendamment le cycle de vie des informations d’identification client.
Il est recommandé d’effectuer un roulement régulier des clés d’accès ou des secrets.
Étapes de configuration
Chargez le fichier jar de votre tâche Flink dans le compte de stockage. Il peut s’agir du compte de stockage principal associé au cluster Flink ou de tout autre compte de stockage, dans lequel vous devez attribuer le rôle « Propriétaire des données blob du stockage » au MSI attribué par l’utilisateur utilisé pour le cluster dans ce compte de stockage.
Azure Key Vault – Suivez ce tutoriel pour créer un Azure Key Vault au cas où vous n’en auriez pas.
Créez un principal de service Microsoft Entra pour accéder à Key Vault – Accordez l’autorisation d’accéder à Azure Key Vault avec le rôle « Agent des secrets Key Vault », puis notez les valeurs « appId », « mot de passe » et « locataire » à partir de la réponse. Nous devons utiliser la même chose pour Airflow afin de pouvoir utiliser le stockage Key Vault comme back-ends pour stocker des informations sensibles.
az ad sp create-for-rbac -n <sp name> --role “Key Vault Secrets Officer” --scopes <key vault Resource ID>Activez Azure Key Vault pour le gestionnaire du flux de travail pour stocker et gérer vos informations sensibles de manière sécurisée et centralisée. En procédant ainsi, vous pouvez ensuite utiliser des variables et des connexions qui seront automatiquement stockées dans Azure Key Vault. Le nom des connexions et des variables doit être préfixé par le variables_prefix défini dans AIRFLOW__SECRETS__BACKEND_KWARGS. Par exemple, si variables_prefix a une valeur hdinsight-aks-variables et que vous avez une clé de variable « hello », vous voudrez stocker votre variable comme hdinsight-aks-variable-hello.
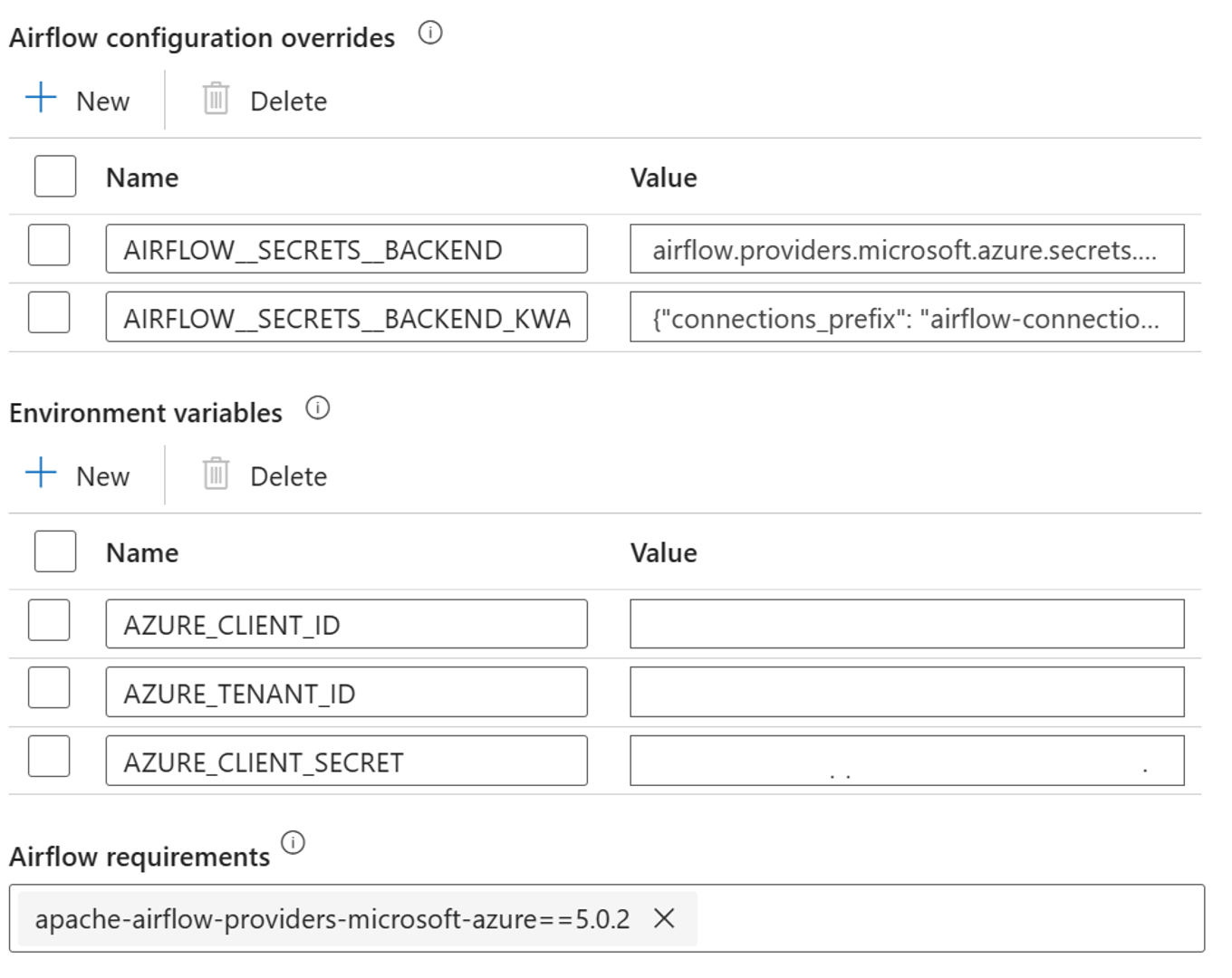
Ajoutez les paramètres suivants pour les paramètres de remplacement de la configuration Airflow dans les propriétés du runtime intégré :
AIRFLOW__SECRETS__BACKEND :
"airflow.providers.microsoft.azure.secrets.key_vault.AzureKeyVaultBackend"AIRFLOW__SECRETS__BACKEND_KWARGS :
"{"connections_prefix": "airflow-connections", "variables_prefix": "hdinsight-aks-variables", "vault_url": <your keyvault uri>}”
Ajoutez le paramètre suivant pour la configuration des variables d’environnement dans les propriétés du runtime intégré Airflow :
AZURE_CLIENT_ID =
<App Id from Create Azure AD Service Principal>AZURE_TENANT_ID =
<Tenant from Create Azure AD Service Principal>AZURE_CLIENT_SECRET =
<Password from Create Azure AD Service Principal>
Ajoutez des exigences Airflow – apache-airflow-providers-microsoft-azure
Créez un principal de service Microsoft Entra pour accéder à Azure – Accordez l’autorisation d’accéder au cluster HDInsight AKS avec le rôle Contributeur, puis notez les valeurs « appId », « mot de passe » et « locataire » à partir de la réponse.
az ad sp create-for-rbac -n <sp name> --role Contributor --scopes <Flink Cluster Resource ID>Créez les secrets suivants dans votre coffre de clés avec les valeurs « appId », « mot de passe » et « locataire » du précédent principal de service AD, préfixés par le variables_prefix de propriété défini dans AIRFLOW__SECRETS__BACKEND_KWARGS. Le code DAG peut accéder à l’une de ces variables sans variables_prefix.
hdinsight-aks-variables-api-client-id=
<App ID from previous step>hdinsight-aks-variables-api-secret=
<Password from previous step>hdinsight-aks-variables-tenant-id=
<Tenant from previous step>
from airflow.models import Variable def retrieve_variable_from_akv(): variable_value = Variable.get("client-id") print(variable_value)

Définition de DAG
Un DAG (Graphe orienté acyclique) est le concept principal d’Airflow. Le DAG collecte les tâches ensemble, organisées avec des dépendances et des relations pour indiquer la manière dont elles doivent s’exécuter.
Il existe trois façons de déclarer un DAG :
Vous pouvez utiliser un gestionnaire de contexte, qui ajoute le DAG à tout ce qu’il contient implicitement
Vous pouvez utiliser un constructeur standard, en passant le DAG dans tous les opérateurs que vous utilisez
Vous pouvez utiliser l’élément décoratif @dag pour transformer une fonction en générateur DAG (à partir d’airflow.decorationors import dag)
Les DAG ne sont rien sans tâches à exécuter, et celles-ci sont fournies sous la forme d’opérateurs, de capteurs ou de TaskFlow.
Pour en savoir plus sur les DAG, le flux de contrôle, les SubDAGs, les TaskGroups, etc., reportez-vous directement à Apache Airflow.
Exécution du DAG
Un exemple de code est disponible sur le git ; téléchargez le code localement sur votre ordinateur et chargez le wordcount.py dans un stockage d’objets blob. Suivez les étapes pour importer le DAG dans votre flux de travail créé lors de l’installation.
Le wordcount.py est un exemple d’orchestration d’une soumission de travail Flink à l’aide d’Apache Airflow avec HDInsight sur AKS. Le DAG a deux tâches :
get
OAuth TokenAppeler l’API REST Azure de soumission de travail Flink HDInsight pour envoyer un nouveau travail
Le DAG s’attend à avoir un configuration du principal de service, comme décrit lors du processus d’installation pour les informations d’identification du client OAuth, et passe la configuration d’entrée suivante pour l’exécution.
Étapes d'exécution
Exécutez le DAG à partir de l’IU Airflow ; vous pouvez ouvrir l’interface utilisateur du gestionnaire du flux de travail d’Azure Data Factory en cliquant sur l’icône de moniteur.

Sélectionnez le DAG « FlinkWordCountExample » sur la page « DAGs ».

Cliquez sur l’icône « exécuter » dans le coin supérieur droit, puis sélectionnez « Trigger DAG w/ config ».
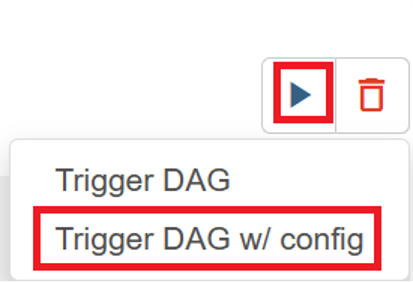
Passer une configuration JSON requise
{ "jarName":"WordCount.jar", "jarDirectory":"abfs://filesystem@<storageaccount>.dfs.core.windows.net", "subscription":"<cluster subscription id>", "rg":"<cluster resource group>", "poolNm":"<cluster pool name>", "clusterNm":"<cluster name>" }Cliquez sur le « Trigger », ce qui démarre l’exécution du DAG.
Vous pouvez visualiser l’état des tâches DAG depuis l’exécution du DAG
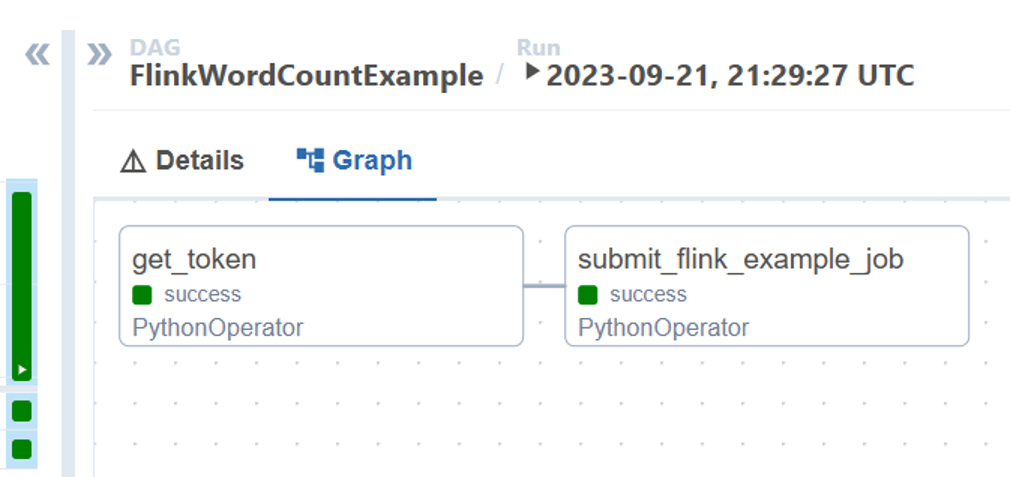
Valider l’exécution du travail à partir du portail
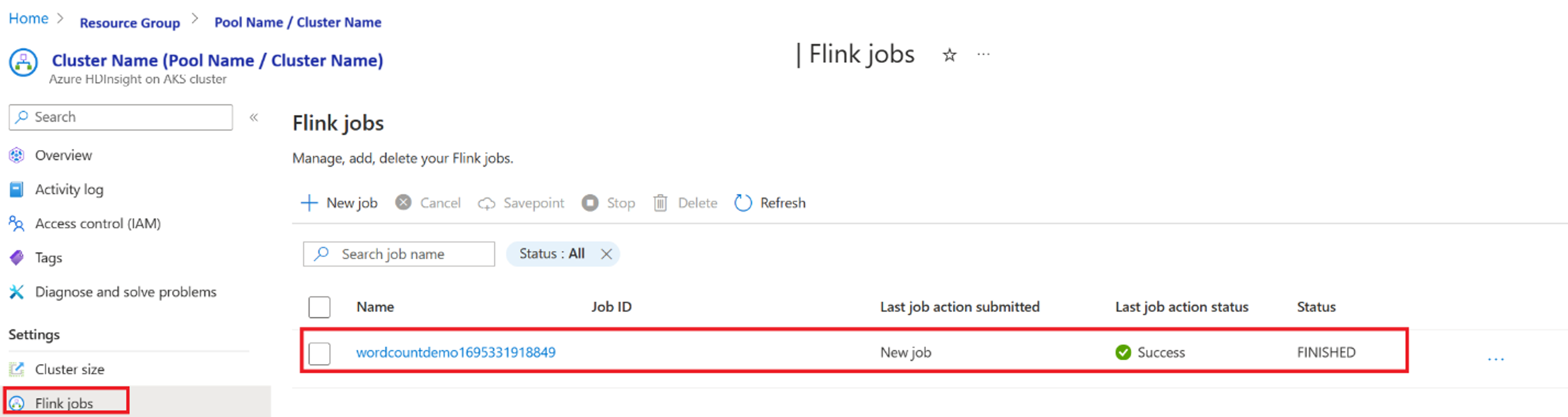
Valider le travail à partir du tableau de bord « Apache Flink Dashboard »






Exemple de code
Il s’agit d’un exemple d’orchestration du pipeline de données en utilisant Airflow avec HDInsight sur AKS.
Le DAG s’attend à avoir une configuration du principal de service pour les informations d’identification du client OAuth, tout en passant la configuration d’entrée suivante pour l’exécution :
{
'jarName':'WordCount.jar',
'jarDirectory':'abfs://filesystem@<storageaccount>.dfs.core.windows.net',
'subscription':'<cluster subscription id>',
'rg':'<cluster resource group>',
'poolNm':'<cluster pool name>',
'clusterNm':'<cluster name>'
}
Référence
- Reportez-vous à l’exemple de code.
- Site web d’Apache Flink
- Apache, Apache Airflow, Airflow, Apache Flink, Flink et les noms de projet open source associés sont des marques de commerce d’Apache Software Foundation (ASF).