Connecter Apache Flink® sur HDInsight sur AKS à Azure Event Hubs pour Apache Kafka®
Important
Azure HDInsight sur AKS a été mis hors service le 31 janvier 2025. En savoir plus avec cette annonce.
Vous devez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent pour éviter l’arrêt brusque de vos charges de travail.
Important
Cette fonctionnalité est actuellement en préversion. Les Conditions d’utilisation supplémentaires pour les préversions Microsoft Azure incluent des termes juridiques supplémentaires qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou qui ne sont pas encore publiées en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez informations en préversion sur Azure HDInsight sur AKS. Pour des questions ou des suggestions de fonctionnalités, envoyez une demande sur AskHDInsight avec les détails et suivez-nous pour plus de mises à jour sur Communauté Azure HDInsight.
Un cas d’usage bien connu pour Apache Flink est l’analytique de flux. Le choix populaire par de nombreux utilisateurs d’utiliser les flux de données, qui sont ingérés à l’aide d’Apache Kafka. Les installations typiques de Flink et Kafka commencent par l'envoi de flux d'événements vers Kafka, qui peuvent ensuite être consommés par des travaux Flink. Azure Event Hubs fournit un point de terminaison Apache Kafka sur un hub d’événements, qui permet aux utilisateurs de se connecter au hub d’événements à l’aide du protocole Kafka.
Dans cet article, nous allons explorer comment connecter Azure Event Hubs avec Apache Flink sur HDInsight sur AKS et nous aborderons les éléments suivants :
- Créer un espace de noms Event Hubs
- Créer un cluster HDInsight sur AKS avec Apache Flink
- Lancer le producteur Flink
- Package Jar pour Apache Flink
- Validation de la soumission de travaux &
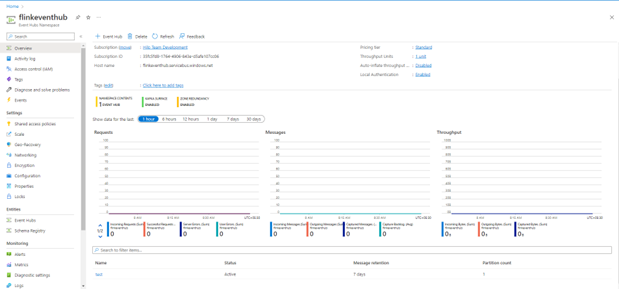
Créer un espace de noms pour Event Hubs et des instances Event Hubs
Pour créer un espace de noms Event Hubs et des Event Hubs, voir et.
capture d’écran

Configurer le cluster Flink sur HDInsight sur AKS
À l’aide de HDInsight existant sur le pool de clusters AKS, vous pouvez créer un cluster Flink
Exécutez le producteur Flink en ajoutant bootstrap.servers et les informations
producer.config.bootstrap.servers={YOUR.EVENTHUBS.FQDN}:9093 client.id=FlinkExampleProducer sasl.mechanism=PLAIN security.protocol=SASL_SSL sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required \ username="$ConnectionString" \ password="{YOUR.EVENTHUBS.CONNECTION.STRING}";Remplacez
{YOUR.EVENTHUBS.CONNECTION.STRING}par la chaîne de connexion de votre espace de noms Event Hubs. Pour obtenir des instructions sur l’obtention de la chaîne de connexion, consultez les détails sur la façon de obtenir une chaîne de connexion Event Hubs.Par exemple
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="$ConnectionString" password="Endpoint=sb://mynamespace.servicebus.windows.net/;SharedAccessKeyName=RootManageSharedAccessKey;SharedAccessKey=XXXXXXXXXXXXXXXX";
Empaquetage du fichier JAR pour Flink
Package com.example.app ;
package contoso.example; import org.apache.flink.api.common.functions.MapFunction; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.api.java.utils.ParameterTool; import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema; import org.apache.flink.connector.kafka.sink.KafkaSink; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import java.io.FileReader; import java.util.Properties; public class AzureEventHubDemo { public static void main(String[] args) throws Exception { // 1. get stream execution environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment().setParallelism(1); ParameterTool parameters = ParameterTool.fromArgs(args); String input = parameters.get("input"); Properties properties = new Properties(); properties.load(new FileReader(input)); // 2. generate stream input DataStream<String> stream = createStream(env); // 3. sink to eventhub KafkaSink<String> sink = KafkaSink.<String>builder().setKafkaProducerConfig(properties) .setRecordSerializer(KafkaRecordSerializationSchema.builder() .setTopic("topic1") .setValueSerializationSchema(new SimpleStringSchema()) .build()) .build(); stream.sinkTo(sink); // 4. execute the stream env.execute("Produce message to Azure event hub"); } public static DataStream<String> createStream(StreamExecutionEnvironment env){ return env.generateSequence(0, 200) .map(new MapFunction<Long, String>() { @Override public String map(Long in) { return "FLINK PRODUCE " + in; } }); } }Ajoutez l’extrait de code pour exécuter le producteur Flink.
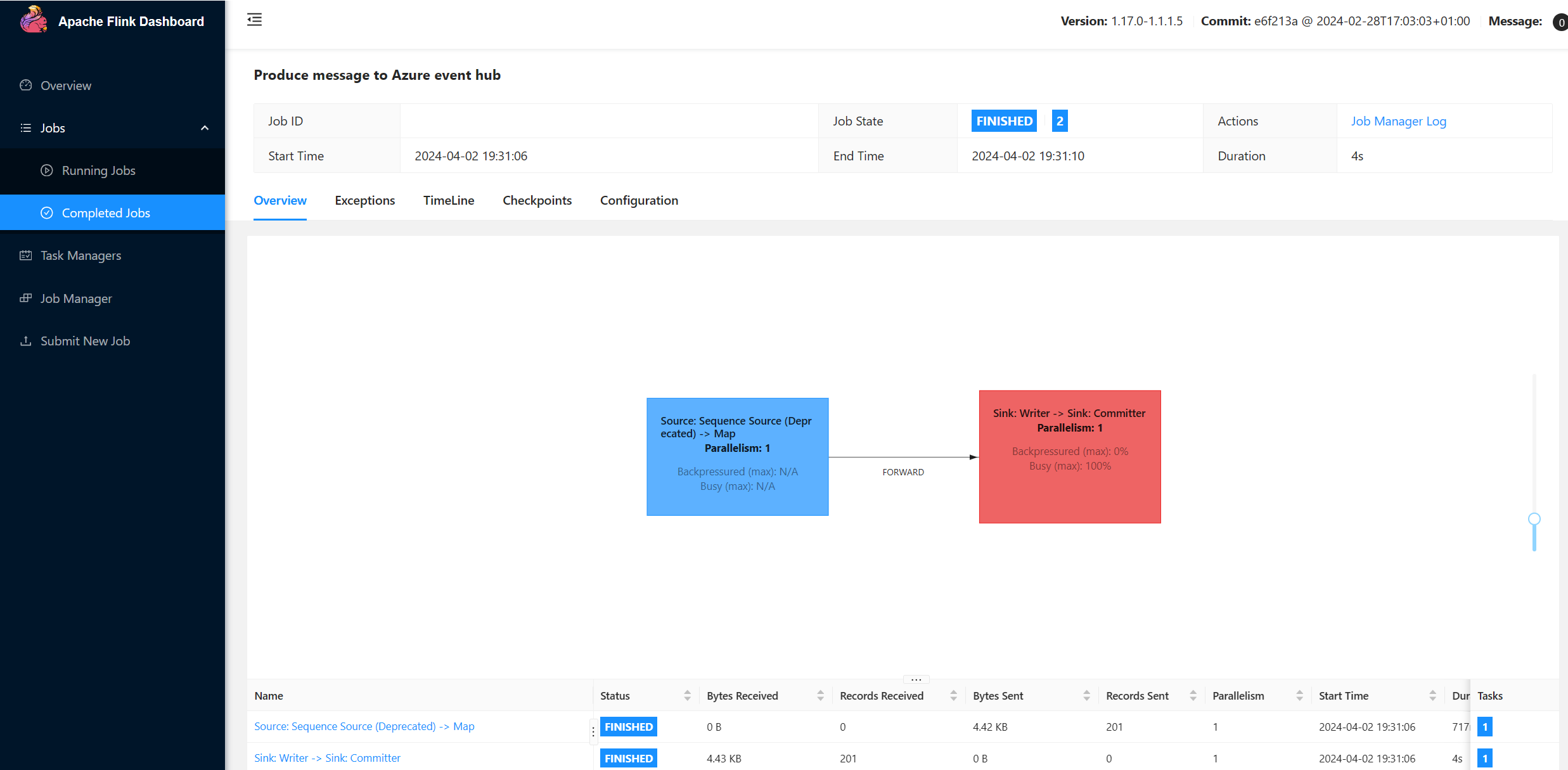
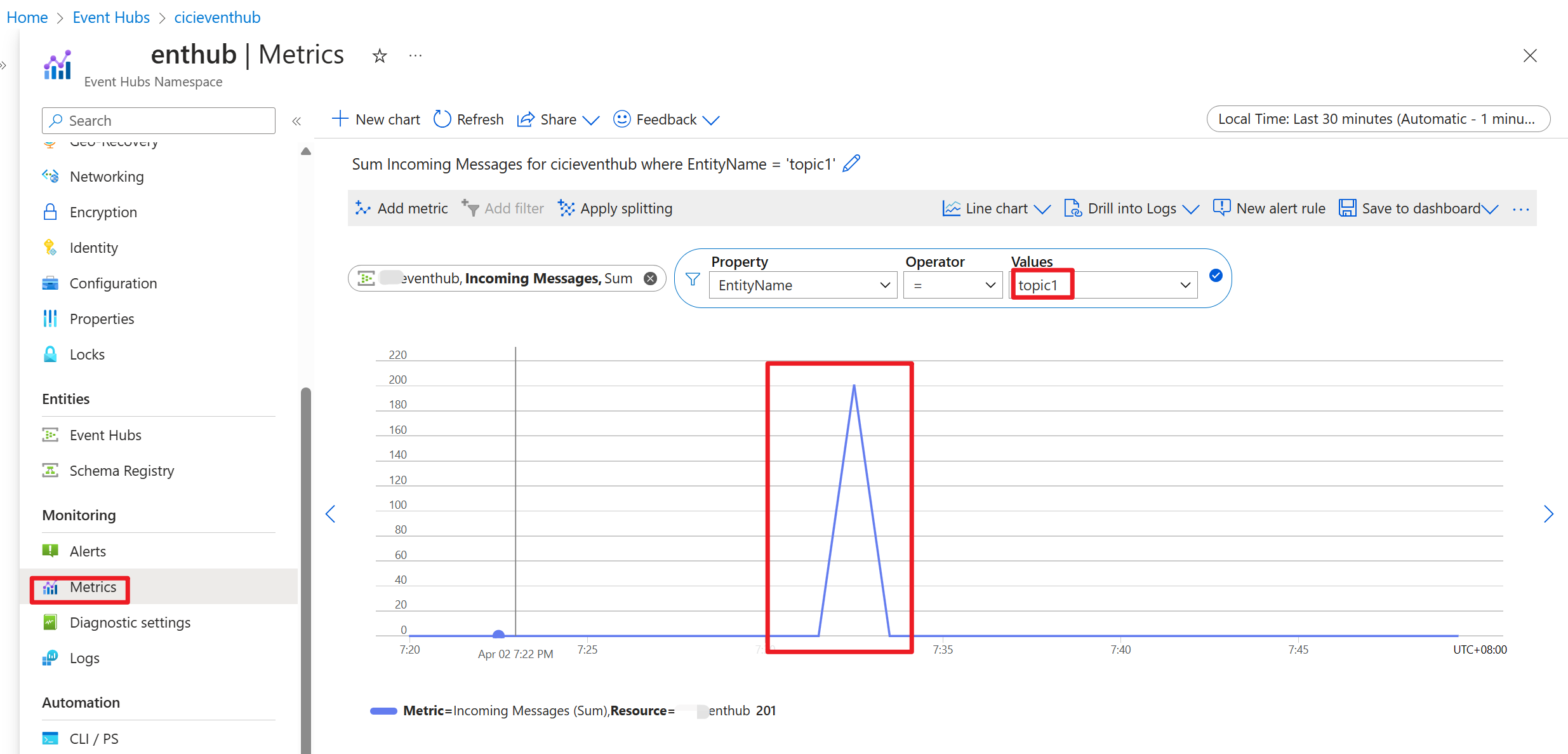
Une fois le code exécuté, les événements sont stockés dans la rubrique « topic1 »


Référence
- Site officiel Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink et les noms de projet open source associés sont marques de commerce du Apache Software Foundation (ASF).