Gestion de la configuration Apache Flink® dans HDInsight sur AKS
Remarque
Nous allons mettre hors service Azure HDInsight sur AKS le 31 janvier 2025. Avant le 31 janvier 2025, vous devrez migrer vos charges de travail vers Microsoft Fabric ou un produit Azure équivalent afin d’éviter leur arrêt brutal. Les clusters restants de votre abonnement seront arrêtés et supprimés de l’hôte.
Seul le support de base est disponible jusqu’à la date de mise hors service.
Important
Cette fonctionnalité est disponible actuellement en mode Aperçu. Les Conditions d’utilisation supplémentaires pour les préversions de Microsoft Azure contiennent davantage de conditions légales qui s’appliquent aux fonctionnalités Azure en version bêta, en préversion ou ne se trouvant pas encore en disponibilité générale. Pour plus d’informations sur cette préversion spécifique, consultez les Informations sur la préversion d’Azure HDInsight sur AKS. Si vous avez des questions ou des suggestions de fonctionnalités, soumettez une demande sur AskHDInsight avec les détails et suivez-nous pour obtenir les dernières actualités sur la Communauté Azure HDInsight.
HDInsight sur AKS fournit un ensemble de configurations par défaut d’Apache Flink pour la plupart des propriétés et quelques-unes en fonction des profils d’application courants. Toutefois, si vous devez ajuster les propriétés de configuration Flink pour améliorer les performances de certaines applications avec l’utilisation de l’état, le parallélisme ou les paramètres de mémoire, vous pouvez modifier la configuration du travail Flink à l’aide de la section Travaux Flink dans HDInsight sur le cluster AKS.
Accédez aux paramètres > Flink Jobs > cliquez sur Mettre à jour.
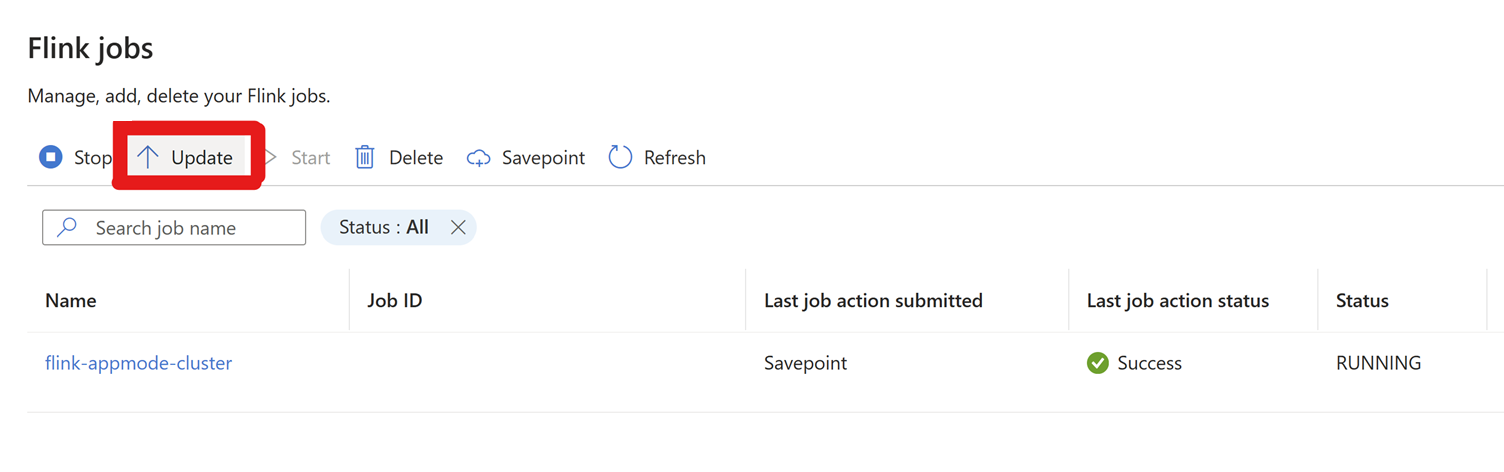
Cliquez sur + Ajouter une ligne pour modifier la configuration.
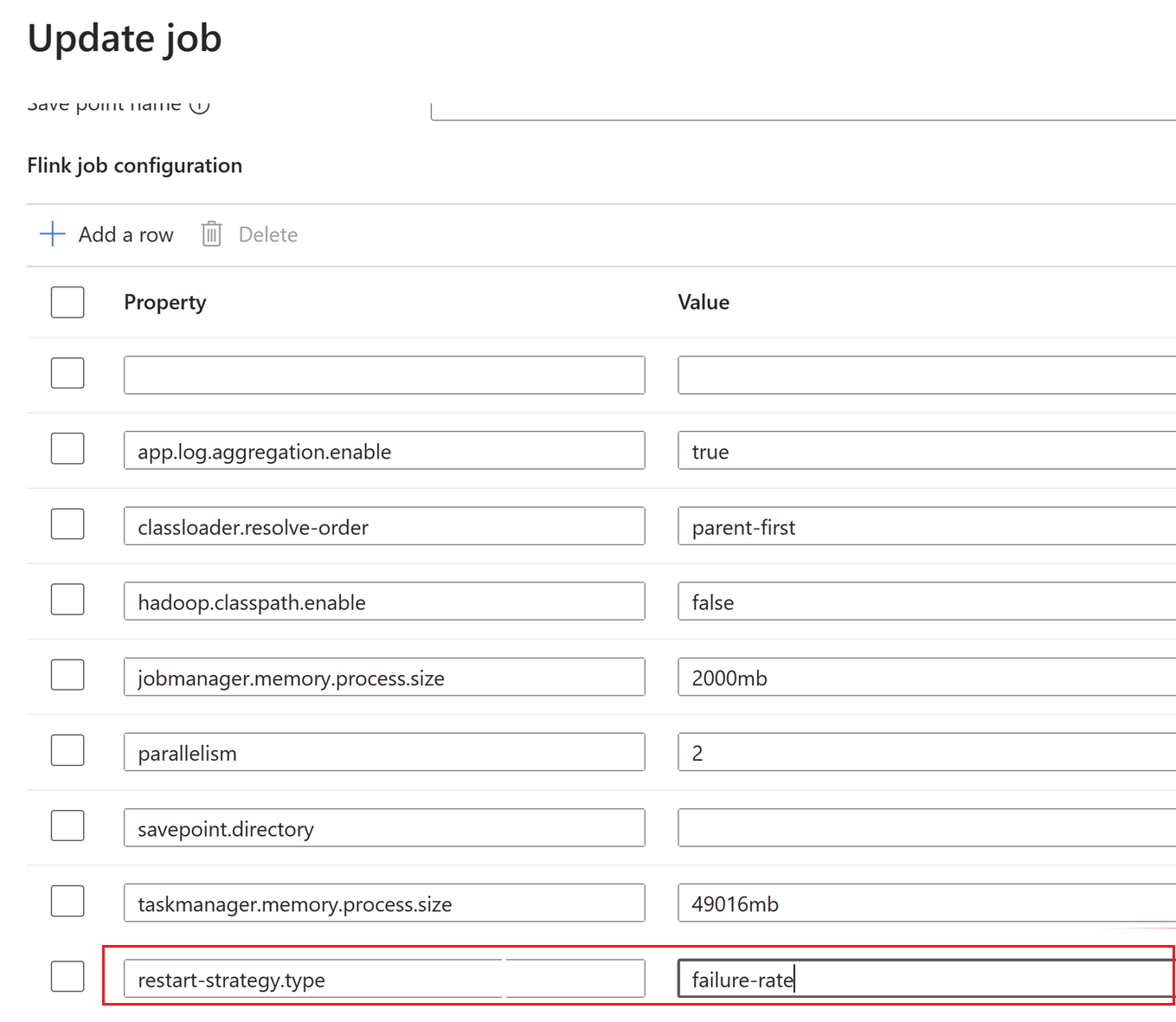
Ici, l’intervalle de point de contrôle est modifié au niveau du cluster.
Mettez à jour les modifications en cliquant sur OK, puis enregistrez.
Une fois enregistrées, les nouvelles configurations sont mises à jour en quelques minutes (environ 5 minutes).
Configurations, qui peuvent être mises à jour à l’aide des paramètres de gestion de la configuration.
processMemory size:Les paramètres par défaut de la taille de mémoire du processus ou du gestionnaire de travaux et du gestionnaire de tâches sont la mémoire configurée par l’utilisateur lors de la création du cluster.
Cette taille peut être configurée à l’aide de la propriété de configuration ci-dessous. Pour modifier la mémoire du processus du gestionnaire de tâches, utilisez cette configuration.
taskmanager.memory.process.size : <value>Exemple :
taskmanager.memory.process.size : 2000mbPour le gestionnaire de travaux
jobmanager.memory.process.size : <value>Remarque
La mémoire de processus configurable maximale est égale à la mémoire configurée pour
jobmanager/taskmanager.


Intervalle de point de contrôle
L’intervalle de point de contrôle détermine la fréquence à laquelle Flink déclenche un point de contrôle. Défini en millisecondes et peut être défini à l’aide de la propriété de configuration suivante
execution.checkpoint.interval: <value>
Le paramètre par défaut est de 60 000 millisecondes (1 min), cette valeur peut être modifiée comme vous le souhaitez.
Back-end d’état
Le back-end d’état détermine comment Flink gère et conserve l’état de votre application. Elle a un impact sur la façon dont les points de contrôle sont stockés. Vous pouvez configurer le back-end d’état à l’aide de la propriété suivante :
state.backend: <value>
Par défaut, les clusters Apache Flink dans HDInsight sur AKS utilisent la base de données Rocks.
Chemin d’accès au stockage de point de contrôle
Nous autorisons les points de contrôle persistants par défaut en stockant les points de contrôle dans le stockage abfs, comme configuré par l’utilisateur. Même si le travail échoue, étant donné que les points de contrôle sont conservés, il peut être facilement démarré avec le dernier point de contrôle.
state.checkpoints.dir: <path> Remplacez <path> par le chemin d’accès souhaité où les points de contrôle sont stockés.
Par défaut, stocké dans le compte de stockage (ABFS), configuré par l’utilisateur. Cette valeur peut être modifiée en n’importe quel chemin souhaité tant que les pods Flink peuvent y accéder.
Nombre maximal de points de contrôle simultanés
Vous pouvez limiter le nombre maximal de points de contrôle simultanés en définissant la propriété suivante : checkpoint.max-concurrent-checkpoints: <value>
Remplacez <value> par le nombre maximal de points de contrôle simultanés souhaité. Par exemple, 1 pour autoriser un seul point de contrôle à la fois.
Nombre maximal de points de contrôle conservés
Vous pouvez limiter le nombre maximal de points de contrôle à conserver en définissant la propriété suivante : state.checkpoints.num-retained: <value> Remplacez <value> par le nombre maximal souhaité. Par défaut, nous conservons au maximum cinq points de contrôle.
Chemin d’accès du stockage de point de sauvegarde
Nous autorisons les points d’enregistrement persistants par défaut en stockant les points de sauvegarde dans le stockage abfs (tel que configuré par l’utilisateur). Si l’utilisateur souhaite arrêter et démarrer ultérieurement le travail avec un point de sauvegarde particulier, il peut configurer cet emplacement.
state.checkpoints.dir : <path> remplacer <path> par le chemin souhaité où les points d’enregistrement sont stockés.
Par défaut, il est stocké dans le compte de stockage, configuré par l’utilisateur. (Nous prenons en charge ABFS). Cette valeur peut être modifiée en n’importe quel chemin souhaité tant que les pods Flink peuvent y accéder.
Haute disponibilité du gestionnaire de travaux
Dans HDInsight sur AKS, Flink utilise Kubernetes comme back-end. Même si le Gestionnaire de travaux échoue entre deux en raison d’un problème connu/inconnu, le pod est redémarré en quelques secondes. Par conséquent, même si le travail redémarre en raison de ce problème, le travail est récupéré à partir du dernier point de contrôle.
Forum aux questions
Pourquoi le travail échoue-t-il entre les deux ? Même si les travaux échouent brusquement, si les points de contrôle se produisent en continu, le travail est redémarré par défaut à partir du dernier point de contrôle.
Modifier la stratégie de travail entre deux ? Il existe des cas d’usage où le travail doit être modifié en production en raison d’un bogue de niveau de travail. Pendant ce temps, l’utilisateur peut arrêter le travail, ce qui prend automatiquement un point de sauvegarde et l’enregistre à l’emplacement de point de sauvegarde.
Cliquez sur
savepointet attendez quesavepointsoit terminée.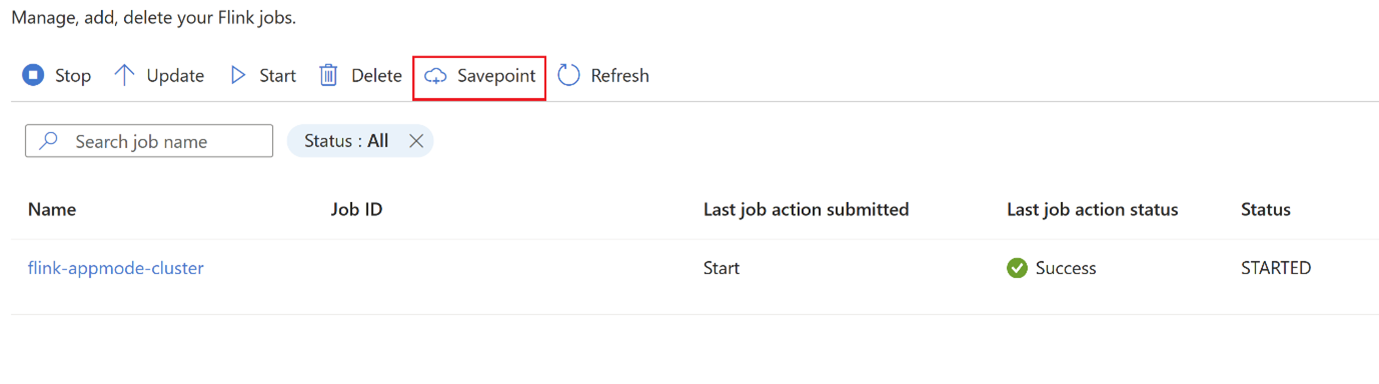
Une fois le point d’enregistrement terminé, cliquez sur Démarrer et l’onglet Démarrer le travail s’affiche. Sélectionnez le nom du point d’enregistrement dans la liste déroulante. Modifiez les configurations si nécessaire. Cliquez sur ok.
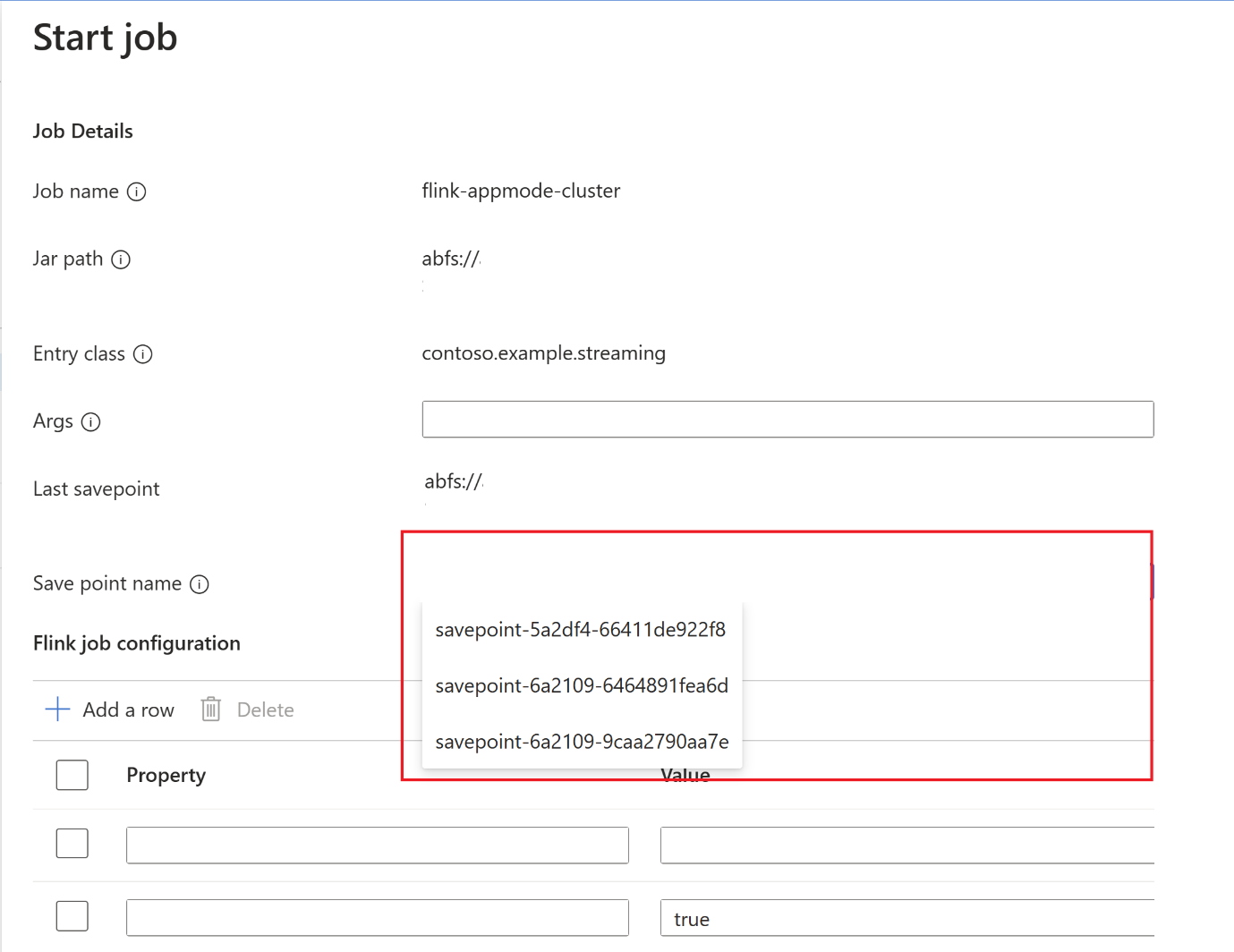


Étant donné que le point de sauvegarde est fourni dans le travail, le Flink sait à partir d’où commencer à traiter les données.
Référence
- Configurations Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink et les noms de projet open source associés sont des marques de commerce d’Apache Software Foundation (ASF).