Déployer sur des machines virtuelles Linux dans un environnement
Azure DevOps Services | Azure DevOps Server 2022 | Azure DevOps Server 2020
Dans ce guide de démarrage rapide, vous allez apprendre à configurer un pipeline Azure DevOps pour le déploiement sur plusieurs ressources de machine virtuelle Linux dans un environnement. Vous pouvez utiliser ces instructions pour n’importe quelle application qui publie un package de déploiement web.
Prérequis
- Compte Azure avec un abonnement actif. Créez un compte gratuitement.
- Une organisation et un projet Azure DevOps. Inscrivez-vous à Azure Pipelines.
Pour les applications JavaScript ou Node.js, au moins deux machines virtuelles Linux configurées avec Nginx sur Azure.
Duplication de l’exemple de code
Si vous disposez déjà d’une application dans GitHub que vous souhaitez déployer, vous pouvez créer un pipeline pour ce code.
Si vous êtes un nouvel utilisateur, dupliquez ce référentiel dans GitHub :
https://github.com/MicrosoftDocs/pipelines-javascript
Créer un environnement avec des machines virtuelles Linux
Vous pouvez ajouter des machines virtuelles en tant que ressources dans des environnements et les cibler pour les déploiements à plusieurs machines virtuelles. L’historique de déploiement de l’environnement fournit la traçabilité de la machine virtuelle à la validation.
Ajouter une ressource de machine virtuelle
Dans votre projet Azure DevOps, allez dans Pipelines>Environnements puis sélectionnez Créer un environnement ou Nouvel environnement.
Dans le premier écran Nouvel environnement, ajoutez un nom et une description facultative.
Sous Ressource, sélectionnez Machines virtuelles, puis Sélectionnez Suivant.
Dans l’écran Nouvel environnement suivant, choisissez Linux sous Système d’exploitation.
Copiez le script d’inscription Linux. Le script est le même pour toutes les machines virtuelles Linux ajoutées à l’environnement.
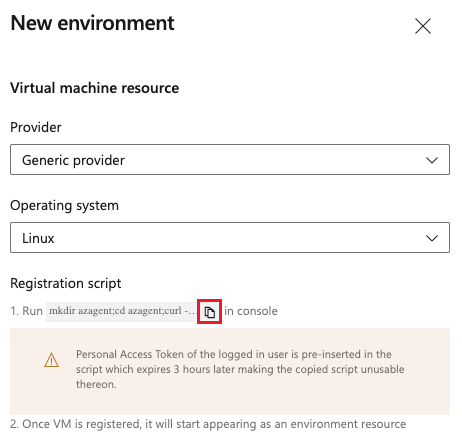
Remarque
Le jeton d’accès personnel (PAT) de l’utilisateur connecté est préinséré dans le script et expire après trois heures.
Sélectionnez Fermer, puis notez que le nouvel environnement est créé.
Exécutez le script copié sur chaque machine virtuelle cible que vous souhaitez inscrire auprès de l’environnement.
Remarque
Si la machine virtuelle dispose déjà d’un autre agent en cours d’exécution, fournissez un nom unique pour que l’agent s’inscrive auprès de l’environnement.
Une fois la machine virtuelle inscrite, elle apparaît sous l’onglet Ressources de l’environnement.
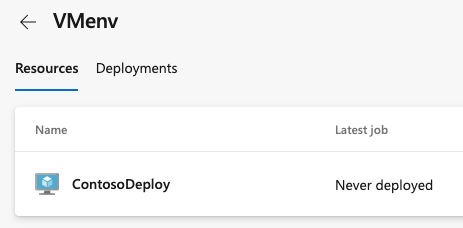
Pour copier à nouveau le script pour créer davantage de ressources, par exemple si votre pater est arrivé à expiration, sélectionnez Ajouter une ressource sur la page de l’environnement.
Ajouter et gérer des balises
Les balises permettent de cibler un ensemble spécifique de machines virtuelles dans un environnement pour le déploiement. Vous pouvez utiliser un nombre illimité de balises. Les balises sont limitées à 256 caractères chacune.
Vous pouvez ajouter des balises ou supprimer des balises pour les machines virtuelles dans le script d’inscription interactif ou via l’interface utilisateur en sélectionnant Plus d’actions ![]() pour une ressource de machine virtuelle. Pour ce guide de démarrage rapide, affectez une balise différente à chaque machine virtuelle de votre environnement.
pour une ressource de machine virtuelle. Pour ce guide de démarrage rapide, affectez une balise différente à chaque machine virtuelle de votre environnement.

Définir un pipeline de build CI
Vous avez besoin d’un pipeline de build d’intégration continue (CI) qui publie votre application web et un script de déploiement pour s’exécuter localement sur le serveur Linux. Configurez votre pipeline de build CI en fonction du runtime que vous souhaitez utiliser.
Important
Lors des procédures GitHub, il est possible qu’il vous soit demandé de créer une connexion de service GitHub ou que vous soyez redirigé vers GitHub pour vous connecter, installer Azure Pipelines, ou autoriser Azure Pipelines. Suivez les instructions à l’écran pour compléter le processus. Pour plus d’informations, veuillez consulter la section Accès aux référentiels GitHub.
- Dans votre projet Azure DevOps, sélectionnez Pipelines>Créer un pipeline, puis gitHub comme emplacement de votre code source.
- Dans l’écran Sélectionner un référentiel , sélectionnez votre exemple de référentiel forked.
- Dans l’écran Configurer votre pipeline, sélectionnez Pipeline de démarrage. Azure Pipelines génère un fichier YAML appelé azure-pipelines.yml pour votre pipeline.
- Sélectionnez le menu déroulant en regard de Enregistrer et exécuter, sélectionnez Enregistrer, puis enregistrez à nouveau. Le fichier est enregistré dans votre dépôt GitHub forked.
Modifier le code
Sélectionnez Modifier, puis remplacez le contenu du fichier azure-pipelines.yml par le code suivant. Vous ajoutez à ce YAML dans les prochaines étapes.
Le code suivant génère votre projet Node.js avec npm.
trigger:
- main
pool:
vmImage: ubuntu-latest
stages:
- stage: Build
displayName: Build stage
jobs:
- job: Build
displayName: Build
steps:
- task: UseNode@1
inputs:
version: '16.x'
displayName: 'Install Node.js'
- script: |
npm install
npm run build --if-present
npm run test --if-present
displayName: 'npm install, build and test'
- task: ArchiveFiles@2
displayName: 'Archive files'
inputs:
rootFolderOrFile: '$(System.DefaultWorkingDirectory)'
includeRootFolder: false
archiveType: zip
archiveFile: $(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip
replaceExistingArchive: true
- upload: $(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip
artifact: drop
Pour plus d’informations, passez en revue les étapes décrites dans Générer votre application Node.js avec gulp pour créer une build.
Exécuter votre pipeline
Sélectionnez Valider et enregistrer, puis sélectionnez Enregistrer, Exécuter, puis Réexécuter.
Une fois votre pipeline exécuté, vérifiez que le travail s’est correctement exécuté et qu’un artefact publié apparaît.
Déployer sur les machines virtuelles Linux
Modifiez votre pipeline pour ajouter le travail de déploiement suivant. Remplacez
<environment name>par le nom de l’environnement que vous avez créé précédemment. Sélectionnez des machines virtuelles spécifiques de l’environnement pour recevoir le déploiement en spécifiant celle<VM tag>que vous avez définie pour chaque machine virtuelle.jobs: - deployment: VMDeploy displayName: Web deploy environment: name: <environment name> resourceType: VirtualMachine tags: <VM tag> # Update value for VMs to deploy to strategy:Pour plus d’informations, consultez la définition complète de jobs.deployment.
Pour plus d’informations sur le mot clé et les
environmentressources ciblées par un travail de déploiement, consultez la définition jobs.deployment.environment.Spécifiez l’un ou l’autre
runOnceen tant que déploiementstrategy.rollingLa stratégie de déploiement la plus simple est
runOnce. LespreDeploydeployhooks ,routeTrafficetpostRouteTrafficcycle de vie s’exécutent une seule fois. Ensuite, soiton:s’exécuteon:success.failureLe code suivant montre un travail de déploiement pour
runOnce:jobs: - deployment: VMDeploy displayName: Web deploy environment: name: <environment name> resourceType: VirtualMachine tags: <VM tag> strategy: runOnce: deploy: steps: - script: echo my first deploymentLe code suivant montre un extrait de code YAML pour la stratégie de déploiement, à l’aide
rollingd’un pipeline Java. Vous pouvez mettre à jour jusqu’à cinq cibles dans chaque itération. LemaxParallelparamètre spécifie le nombre de cibles pouvant être déployées en parallèle.La
maxParallelsélection compte pour le nombre absolu ou le pourcentage de cibles qui doivent rester disponibles à tout moment, à l’exclusion des cibles déployées et détermine les conditions de réussite et d’échec pendant le déploiement.jobs: - deployment: VMDeploy displayName: web environment: name: <environment name> resourceType: VirtualMachine tags: <VM tag> strategy: rolling: maxParallel: 2 #for percentages, mention as x% preDeploy: steps: - download: current artifact: drop - script: echo initialize, cleanup, backup, install certs deploy: steps: - task: Bash@3 inputs: targetType: 'inline' script: | # Modify deployment script based on the app type echo "Starting deployment script run" sudo java -jar '$(Pipeline.Workspace)/drop/**/target/*.jar' routeTraffic: steps: - script: echo routing traffic postRouteTraffic: steps: - script: echo health check post-route traffic on: failure: steps: - script: echo Restore from backup! This is on failure success: steps: - script: echo Notify! This is on successAvec chaque exécution de ce travail, l’historique de déploiement est enregistré sur l’environnement dans lequel vous avez créé et inscrit les machines virtuelles.
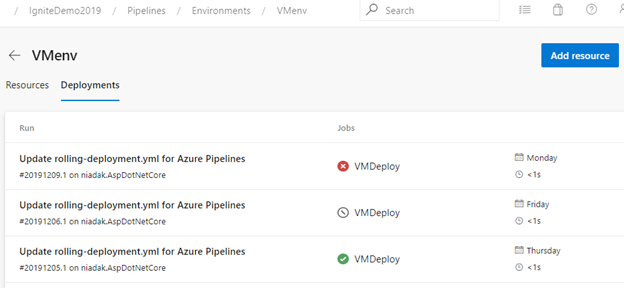
Traçabilité du pipeline d’accès dans l’environnement
La vue Déploiements d’environnement fournit une traçabilité complète des validations et des éléments de travail et un historique de déploiement entre pipelines pour l’environnement.