Tutoriel : Migrer le serveur d’applications WebSphere vers des machines virtuelles Azure avec une haute disponibilité et une récupération d’urgence
Ce tutoriel vous montre un moyen simple et efficace d’implémenter la haute disponibilité et la récupération d’urgence (HA/DR) pour Java à l’aide de WebSphere Application Server sur des machines virtuelles Azure. Pour illustrer comment atteindre un faible objectif de temps de récupération (RTO) et un faible objectif de point de récupération (RPO), la solution utilise une simple application Jakarta EE basée sur une base de données, exécutée sur le serveur d'applications WebSphere. La HA/DR est un sujet complexe, avec de nombreuses solutions possibles. La meilleure solution dépend de vos besoins uniques. Pour d’autres façons de mettre en œuvre la HA/DR, veuillez consulter les ressources à la fin de cet article.
Dans ce tutoriel, vous allez apprendre à :
- Utilisez les meilleures pratiques optimisées Azure pour obtenir une haute disponibilité et une récupération d’urgence.
- Configurez un groupe de basculement de base de données SQL Azure dans des régions appairées.
- Configurez le cluster WebSphere principal sur les machines virtuelles Azure.
- Configurez la récupération d’urgence pour le cluster à l’aide d’Azure Site Recovery.
- Configurez un Azure Traffic Manager.
- Testez le basculement du principal au secondaire
Le diagramme suivant illustre l’architecture que vous générez :

Azure Traffic Manager vérifie l’intégrité de vos régions et route le trafic en conséquence vers la couche Application. La région primaire a un déploiement complet du cluster WebSphere. Après que la région primaire est protégée par Azure Site Recovery, vous pouvez restaurer la région secondaire lors du basculement. Par conséquent, la région primaire assure activement la maintenance des demandes réseau des utilisateurs, tandis que la région secondaire est passive et activée pour recevoir le trafic uniquement lorsque la région primaire subit une interruption de service.
Azure Traffic Manager détecte l’intégrité de l’application déployée dans le serveur HTTP IBM pour implémenter le routage conditionnel. Le RTO de basculement géographique de la couche d’application dépend du temps nécessaire pour arrêter le cluster principal, restaurer le cluster secondaire, démarrer les machines virtuelles et exécuter le cluster WebSphere secondaire. Le RPO dépend de la stratégie de réplication d’Azure Site Recovery et d’Azure SQL Database. Cette dépendance est due au fait que les données du cluster sont stockées et répliquées dans le stockage local des machines virtuelles et que les données d’application sont conservées et répliquées dans le groupe de basculement Azure SQL Database.
Le diagramme précédent montre région primaire et région secondaire comme les deux régions comprenant l’architecture haute disponibilité/récupération d’urgence. Ces régions doivent être des régions jumelées d’Azure. Pour plus d’informations sur les régions jumelées, veuillez consulter la section Réplication interrégionale Azure. L’article utilise USA Est et USA Ouest comme deux régions, mais il peut s’agir de n’importe quelle région jumelée qui est logique pour votre scénario. Pour la liste des jumelages de régions, veuillez consulter la section Régions jumelées Azure de Réplication interrégionale Azure.
Le niveau base de données se compose d’un groupe de basculement Azure SQL Database avec un serveur principal et un serveur secondaire. Le point de terminaison de l’écouteur en lecture/écriture pointe toujours vers le serveur principal et est connecté au cluster WebSphere dans chaque région. Un géobasculement bascule toutes les bases de données secondaires du groupe dans le rôle principal. Pour le RPO et le RTO de basculement géographique de la base de données Azure SQL, veuillez consulter la section Vue d’ensemble de la continuité d’activité avec la base de données Azure SQL.
Ce tutoriel a été écrit avec Azure Site Recovery et le service Azure SQL Database, car le tutoriel s’appuie sur les fonctionnalités de haute disponibilité de ces services. D’autres choix de base de données sont possibles, mais vous devez prendre en compte les fonctionnalités de haute disponibilité de la base de données que vous choisissez.
Conditions préalables
- Un abonnement Azure. Si vous n’avez pas d’abonnement Azure , créez un compte gratuit avant de commencer.
- Assurez-vous d’avoir le rôle
Contributordans l’abonnement. Vous pouvez vérifier l’attribution en suivant les étapes décrites dans Répertorier les attributions de rôles Azure à l’aide du portail Azure. - Préparez un ordinateur local avec Windows, Linux ou macOS installé.
- Installez et configurez Git.
- Installez une implémentation Java SE, version 17 ou ultérieure , par exemple, la build Microsoft d’OpenJDK.
- Installez Maven, version 3.9.3 ou ultérieure.
Configurez un groupe de basculement de base de données SQL Azure dans des régions appairées
Dans cette section, vous créez un groupe de basculement Azure SQL Database dans des régions jumelées pour l’utiliser avec vos clusters WebSphere et votre application. Dans une section ultérieure, vous allez configurer WebSphere pour stocker ses données de session dans cette base de données. Cette pratique fait référence à la section Créer une table pour la persistance de session.
Commencez par créer la base de données Azure SQL principale en suivant les étapes du portail Azure dans Démarrage rapide : Créer une base de données unique - Azure SQL Database. Suivez les étapes jusqu’à la section « Nettoyer les ressources », mais sans inclure cette dernière. Utilisez les instructions suivantes lorsque vous parcourez l’article, puis revenez à cet article après avoir créé et configuré Azure SQL Database :
Lorsque vous atteignez la section Créer une base de données unique, procédez comme suit :
- À l’étape 4 pour la création d’un nouveau groupe de ressources, mettez de côté la valeur Nom du groupe de ressources, par exemple
myResourceGroup. - À l’étape 5 pour le nom de la base de données, enregistrez la valeur Nom de la base de données, par exemple
mySampleDatabase. - À l’étape 6 pour la création du serveur, procédez comme suit :
- Renseignez un nom de serveur unique , par exemple,
sqlserverprimary-mjg022624. - Pour Emplacement, sélectionnez (États-Unis) USA Est.
- Pour méthode d’authentification, sélectionnez Utiliser l’authentification SQL.
- Mettez de côté la valeur Login de l’administrateur du serveur, par exemple
azureuser. - Mettez de côté la valeur Mot de passe.
- Renseignez un nom de serveur unique , par exemple,
- À l’étape 8, pour l'environnement de charge de travail , sélectionnez Développement . Examinez la description et envisagez d’autres options pour votre charge de travail.
- À l’étape 11, pour la Redondance du stockage de sauvegarde, sélectionnez Stockage de sauvegarde localement redondant. Envisagez d’autres options pour vos sauvegardes. Pour plus d’informations, veuillez consulter la section Redondance du stockage de sauvegarde de la rubrique Sauvegardes automatisées dans Azure SQL Database.
- À l’étape 14, dans les règles de pare-feu configuration, pour Autoriser les services et les ressources Azure à accéder à ce serveur, sélectionnez Oui.
- À l’étape 4 pour la création d’un nouveau groupe de ressources, mettez de côté la valeur Nom du groupe de ressources, par exemple
Lorsque vous atteignez la section Interroger la base de données, procédez comme suit :
À l’étape 3, entrez vos informations de connexion administrateur du serveur pour l’authentification SQL afin de vous connecter.
Remarque
Si la connexion échoue avec un message d’erreur similaire à Client avec l’adresse IP 'xx.xx.xx.xx' n’est pas autorisé à accéder au serveur, sélectionnez Liste autorisée IP xx.xx.xx.xx sur le serveur <votre_nom_sqlserver-> à la fin du message d’erreur. Attendez que les règles de pare-feu du serveur terminent la mise à jour, puis sélectionnez OK à nouveau.
Après avoir exécuté l’exemple de requête à l’étape 5, décochez l’éditeur et entrez la requête suivante, puis sélectionnez Réexécuter :
CREATE TABLE sessions ( ID VARCHAR(128) NOT NULL, PROPID VARCHAR(128) NOT NULL, APPNAME VARCHAR(128) NOT NULL, LISTENERCNT SMALLINT, LASTACCESS BIGINT, CREATIONTIME BIGINT, MAXINACTIVETIME INT, USERNAME VARCHAR(256), SMALL VARBINARY(MAX), MEDIUM VARCHAR(MAX), LARGE VARBINARY(MAX) );Une fois l'exécution réussie, vous devriez voir le message Requête réussie : lignes affectées : 0.
La table de base de données
sessionsest utilisée pour stocker les données de session pour votre application WebSphere. Les données du cluster WebSphere, y compris les journaux des transactions, sont conservées dans le stockage local des machines virtuelles où le cluster est déployé.
Ensuite, créez un groupe de basculement pour Azure SQL Database en suivant les étapes indiquées sur le portail Azure dans Configurer un groupe de basculement pour Azure SQL Database. Vous n’avez besoin que des sections suivantes : Créer un groupe de basculement et Tester le basculement planifié. Procédez comme suit lorsque vous parcourez l’article, puis revenez à cet article après avoir créé et configuré le groupe de basculement Azure SQL Database :
Dans la section Créer un groupe de basculement, procédez comme suit :
- À l’étape 5 pour la création du groupe de basculement, entrez et enregistrez le nom unique du groupe de basculement comme
failovergroup-mjg022624. - À l’étape 5 pour configurer le serveur, sélectionnez l’option permettant de créer un serveur secondaire, puis procédez comme suit :
- Entrez un nom de serveur unique ( par exemple,
sqlserversecondary-mjg022624. - Entrez le même administrateur de serveur et le même mot de passe que votre serveur principal.
- Pour l'emplacement , sélectionnez (É.-U.) Ouest des États-Unis.
- Assurez-vous que Autoriser les services Azure à accéder au serveur est sélectionné.
- Entrez un nom de serveur unique ( par exemple,
- À l’étape 5 pour configurer les bases de données au sein du groupe, sélectionnez la base de données que vous avez créée dans le serveur principal, par exemple,
mySampleDatabase.
- À l’étape 5 pour la création du groupe de basculement, entrez et enregistrez le nom unique du groupe de basculement comme
Après avoir complété toutes les étapes de la section Tester le basculement planifié, laissez la page du groupe de basculement ouverte et utilisez-la pour le test de basculement des clusters WebSphere plus tard.
Remarque
Cet article vous guide pour créer une base de données unique Azure SQL Database avec l’authentification SQL. Une pratique plus sécurisée consiste à utiliser authentification Microsoft Entra pour Azure SQL pour authentifier la connexion du serveur de base de données. L’authentification SQL est requise pour que le cluster WebSphere se connecte à la base de données pour la persistance de session ultérieurement. Pour plus d’informations, consultez Configuration de la persistance de session de base de données.
Configurer le cluster WebSphere principal sur des machines virtuelles Azure
Dans cette section, vous allez créer les clusters WebSphere principaux sur des machines virtuelles Azure à l’aide de l'offre IBM WebSphere Application Server Cluster sur des machines virtuelles Azure. Le cluster secondaire est restauré à partir du cluster principal lors du basculement en utilisant Azure Site Recovery plus tard.
Déployer le cluster WebSphere principal
Tout d’abord, ouvrez l'offre de cluster IBM WebSphere Application Server sur Azure VMs dans votre navigateur, puis sélectionnez Créer. Vous devriez voir le volet Informations de base de l’offre.
Utilisez les étapes suivantes pour remplir le volet Informations de base :
- Assurez-vous que la valeur affichée pour Abonnement est la même que celle qui contient les rôles listés dans la section des prérequis.
- Dans le champ groupe de ressources
, sélectionnez Créer une et renseignez une valeur unique pour le groupe de ressources, par exemple. - Sous Détails de l’instance, pour Région, sélectionnez USA Est.
- Pour Déployer avec un droit existant pour WebSphere ou avec une licence d’évaluation ?, sélectionnez Évaluation pour ce tutoriel. Vous pouvez également sélectionner Avec droits et fournir vos identifiants IBMid.
- Sélectionnez j’ai lu et accepté le contrat de licence IBM..
- Conservez les valeurs par défaut pour les autres champs.
- Sélectionnez Suivant pour passer au volet Configuration du cluster.

Pour remplir le volet de configuration de cluster
- Pour Mot de passe de l’administrateur VM, fournissez un mot de passe. Pour une meilleure sécurité, envisagez d’utiliser clé publique SSH comme type d’authentification de machine virtuelle.
- Pour Mot de passe de l’administrateur WebSphere, fournissez un mot de passe. Mettez de côté le nom d'utilisateur et le mot de passe pour l'administrateur WebSphere .
- Conservez les valeurs par défaut pour les autres champs.
- Sélectionnez Suivant pour passer au volet Load Balancer.

Procédez comme suit pour remplir le volet d’équilibreur de charge :
- Pour Mot de passe de l’administrateur VM, fournissez un mot de passe. Pour une meilleure sécurité, envisagez d’utiliser clé publique SSH comme authentification de machine virtuelle.
- Pour Mot de passe de l’administrateur IBM HTTP Server, fournissez un mot de passe.
- Conservez les valeurs par défaut pour les autres champs.
- Sélectionnez suivant pour accéder au volet Mise en réseau.

Vous devez voir tous les champs préremplis avec les valeurs par défaut dans le volet Mise en réseau. Sélectionnez Suivant pour accéder au volet Base de données.

Les étapes suivantes vous montrent comment remplir le volet base de données :
- Pour Se connecter à la base de données, sélectionnez Oui.
- Pour Choisir le type de base de données, sélectionnez Microsoft SQL Server .
- Pour Nom JNDI, entrez jdbc/WebSphereCafeDB.
- Pour Chaîne de connexion de la source de données (jdbc:sqlserver://<hôte>:<port>;base de données=<base de données>), remplacez les espaces réservés par les valeurs que vous avez enregistrées dans la section précédente pour le groupe de basculement pour la base de données Azure SQL, par exemple
jdbc:sqlserver://failovergroup-mjg022624.database.windows.net:1433;database=mySampleDatabase. - Pour Nom d’utilisateur de la base de données, entrez le nom de connexion administrateur du serveur et le nom du groupe de basculement que vous avez enregistrés dans la section précédente, par exemple
azureuser@failovergroup-mjg022624.Remarque
Veillez bien à utiliser le nom d’hôte du serveur de base de données et le nom d’utilisateur de base de données appropriés pour le groupe de basculement, et non ceux provenant du serveur de la base de données primaire ou de sauvegarde. En utilisant les valeurs du groupe de basculement, vous dites en fait à WebSphere de parler au groupe de basculement. Toutefois, pour WebSphere, il s’agit simplement d’une connexion de base de données normale.
- Entrez le mot de passe de connexion de l’administrateur du serveur que vous avez enregistré précédemment pour mot de passe de base de données. Entrez la même valeur pour Confirmer le mot de passe.
- Conservez les valeurs par défaut pour les autres champs.
- Sélectionnez Revoir + créer.
- Attendez que Exécution de la validation finale... soit terminée avec succès, puis sélectionnez Créer.

Remarque
Cet article vous guide pour vous connecter à une base de données Azure SQL avec l’authentification SQL. Une pratique plus sécurisée consiste à utiliser authentification Microsoft Entra pour Azure SQL pour authentifier la connexion du serveur de base de données. L’authentification SQL est requise pour que le cluster WebSphere se connecte à la base de données pour la persistance de session ultérieurement. Pour plus d’informations, consultez Configuration de la persistance de session de base de données.
Après un moment, vous devriez voir la page Déploiement où Le déploiement est en cours est affiché.
Remarque
Si vous rencontrez des problèmes lors de l’exécution de la validation finale..., corrigez-les et essayez à nouveau.
Selon les conditions réseau et d’autres activités de votre région sélectionnée, le déploiement peut prendre jusqu’à 25 minutes. Après cela, vous devez voir le texte Votre déploiement est terminé affiché sur la page de déploiement.
Vérifier le déploiement du cluster
Vous avez déployé un serveur HTTP IBM (IHS) et un Gestionnaire de déploiement WebSphere (Dmgr) dans le cluster. L’IHS agit comme équilibreur de charge pour tous les serveurs d’applications du cluster. Dmgr fournit une console web pour la configuration du cluster.
Procédez comme suit pour vérifier si la console IHS et Dmgr fonctionnent avant de passer à l’étape suivante :
Revenez à la page de déploiement , puis sélectionnez Sorties.
Copiez la valeur de la propriété ihsConsole. Ouvrez cette URL dans un nouvel onglet de navigateur. Notez que nous n’utilisons pas
httpspour l’IHS dans cet exemple. Vous devriez voir une page d’accueil de l’IHS sans message d’erreur. Si ce n'est pas le cas, vous devez dépanner et résoudre le problème avant de continuer. Maintenez la console ouverte et utilisez-la pour vérifier le déploiement de l’application du cluster ultérieurement.
Copiez et enregistrez la valeur de la propriété adminSecuredConsole. Ouvrez-le dans un nouvel onglet de navigateur. Acceptez l’avertissement du navigateur pour le certificat TLS auto-signé. N’allez pas en production en utilisant un certificat TLS auto-signé.
Vous devriez voir la page de connexion de la WebSphere Integrated Solutions Console . Connectez-vous à la console avec le nom d’utilisateur et le mot de passe de l’administrateur WebSphere que vous avez enregistrés précédemment. Si vous n’êtes pas en mesure de vous connecter, vous devez identifier et résoudre le problème avant de continuer. Conservez la console ouverte et utilisez-la pour une configuration supplémentaire du cluster WebSphere ultérieurement.

Pour obtenir le nom de l’adresse IP publique de l’IHS, procédez comme suit. Vous l’utilisez lorsque vous configurez Azure Traffic Manager ultérieurement.
- Ouvrez le groupe de ressources dans lequel votre cluster est déployé, par exemple, sélectionnez Vue d’ensemble pour revenir au volet Vue d’ensemble de la page de déploiement, puis sélectionnez Accéder au groupe de ressources.
- Dans la table des ressources, recherchez la colonne Type. Sélectionnez-la pour trier par type de ressource.
- Trouvez la ressource Adresse IP publique préfixée par
ihs, puis copiez et enregistrez son nom.
Configurer le cluster
Tout d’abord, procédez comme suit pour activer l’option Synchroniser les modifications avec les nœuds afin que toute configuration puisse être automatiquement synchronisée avec tous les serveurs d’applications :
- Revenez à la console WebSphere Integrated Solutions et reconnectez-vous si vous êtes déconnecté.
- Dans le volet de navigation, sélectionnez Administration système>Préférences de la console.
- Dans le volet Préférences de la console , sélectionnez Synchroniser les modifications avec les nœuds, puis sélectionnez Appliquer. Vous devriez voir le message Vos préférences ont été modifiées.
Ensuite, procédez comme suit pour configurer les sessions distribuées de base de données pour tous les serveurs d’applications :
- Dans le volet de navigation, sélectionnez Serveurs>types de serveurs>serveurs d’applications WebSphere.
- Dans le volet Serveurs d’applications, vous devez voir 3 serveurs d’applications répertoriés. Pour chaque serveur d’applications, utilisez les instructions suivantes pour configurer les sessions distribuées de base de données :
- Dans le tableau sous le texte Vous pouvez administrer les ressources suivantes, sélectionnez le lien hypertexte du serveur d’applications, qui commence par
MyCluster. - Dans la section paramètres du conteneur, sélectionnez Gestion de session.
- Dans la section Propriétés supplémentaires, sélectionnez paramètres d’environnement distribué.
- Pour Sessions distribuées, sélectionnez Base de données (pris en charge uniquement pour le conteneur Web).
- Sélectionnez base de données et procédez comme suit :
- Pour Nom JNDI de la source de données, entrez jdbc/WebSphereCafeDB.
- Pour Identifiant d’utilisateur, entrez le nom de connexion administrateur du serveur et le nom du groupe de basculement que vous avez enregistrés dans la section précédente, par exemple
azureuser@failovergroup-mjg022624. - Renseignez le mot de passe de connexion de l’administrateur du serveur Azure SQL que vous avez enregistré précédemment pour Mot de passe.
- Pour Nom de l’espace de table, entrez sessions.
- Sélectionnez Utiliser le schéma à plusieurs lignes.
- Sélectionnez OK. Vous êtes redirigé vers le volet Paramètres d’environnement distribué.
- Sous la section Propriétés supplémentaires, sélectionnez paramètres de paramétrage personnalisés.
- Pour Niveau de réglage, sélectionnez Faible (optimisé pour le basculement).
- Sélectionnez OK.
- Sous Messages, sélectionnez Enregistrer. Attendez la fin.
- Sélectionnez Serveurs d’applications depuis la barre de navigation supérieure. Vous revenez au volet Serveurs d’applications.
- Dans le tableau sous le texte Vous pouvez administrer les ressources suivantes, sélectionnez le lien hypertexte du serveur d’applications, qui commence par
- Dans le volet de navigation, sélectionnez Serveurs>Clusters>Clusters de serveurs d’applications WebSphere.
- Dans le volet des clusters de serveurs d'applications WebSphere , vous devez voir le cluster
MyClusterrépertorié. Cochez la case à côté de MyCluster. - Sélectionnez Ripplestart.
- Attendez que le cluster soit redémarré. Vous pouvez sélectionner l’icône Statut et si la nouvelle fenêtre n’affiche pas Démarré, revenez à la console et actualisez la page web après un moment. Répétez l’opération jusqu’à ce que vous voyiez Démarré. Vous pourriez voir Démarrage partiel avant d’atteindre l’état Démarré.
Laissez la console ouverte et utilisez-la pour le déploiement d’applications ultérieurement.
Déployer un exemple d’application
Cette section vous montre comment déployer et exécuter une application Java/Jakarta EE CRUD sur un cluster WebSphere pour un test de basculement de récupération d’urgence plus tard.
Vous avez configuré des serveurs d’applications pour utiliser la source de données jdbc/WebSphereCafeDB pour stocker les données de session précédemment, ce qui permet le basculement et l’équilibrage de charge sur un cluster de serveurs d’applications WebSphere. L’exemple d’application configure également un schéma de persistance pour conserver les données d’application coffee dans la même source de données jdbc/WebSphereCafeDB.
Tout d’abord, utilisez les commandes suivantes pour télécharger, générer et empaqueter l’exemple :
git clone https://github.com/Azure-Samples/websphere-cafe
cd websphere-cafe
git checkout 20240326
mvn clean package
Si vous voyez un message concernant un état Detached HEAD, ce message peut être ignoré sans risque.
Le package doit être correctement généré et situé à <parent-path-to-your-local-clone>/websphere-café/websphere-café-application/target/websphere-café.ear. Si vous ne voyez pas le package, veuillez résoudre le problème avant de continuer.
Ensuite, procédez comme suit pour déployer l’exemple d’application sur le cluster :
- Revenez à la console WebSphere Integrated Solutions et reconnectez-vous si vous êtes déconnecté.
- Dans le volet de navigation, sélectionnez Applications>Types d’applications>applications d’entreprise WebSphere.
- Dans le volet Applications d’entreprise, sélectionnez Installer>Choisir un fichier. Ensuite, trouvez le package situé à <chemin-parent-vers-votre-clone-local>/websphere-cafe/websphere-cafe-application/target/websphere-cafe.ear et sélectionnez Ouvrir. Sélectionnez Suivant>Suivant>Suivant.
- Dans le volet Mapper les modules aux serveurs, appuyez sur Ctrl et sélectionnez tous les éléments listés sous Clusters et serveurs. Cochez la case à côté de websphere-cafe.war. Sélectionnez Appliquer. Sélectionnez Suivant jusqu’à ce que vous voyiez le bouton Terminer.
- Sélectionnez Terminer>Enregistrer, puis attendez l’achèvement. Sélectionnez OK.
- Sélectionnez l’application installée
websphere-cafe, puis sélectionnez Démarrer. Attendez les messages indiquant que l'application a démarré avec succès. Si vous n’êtes pas en mesure de voir le message de succès, vous devez identifier et résoudre le problème avant de poursuivre.
Utilisez maintenant les étapes suivantes pour vérifier que l’application s’exécute comme prévu :
Revenez à la console IHS. Ajoutez la racine de contexte
/websphere-cafe/de l’application déployée à la barre d’adresse, par exemplehttp://ihs70685e.eastus.cloudapp.azure.com/websphere-cafe/, puis appuyez sur Entrée. Vous devez voir la page d’accueil de l’exemple d’application.Créez un café avec un nom et un prix , par exemple, Café 1 avec le prix $10 - qui est conservé dans la table de données de l’application et la table de session de la base de données. L’interface utilisateur que vous voyez doit ressembler à la capture d’écran suivante :
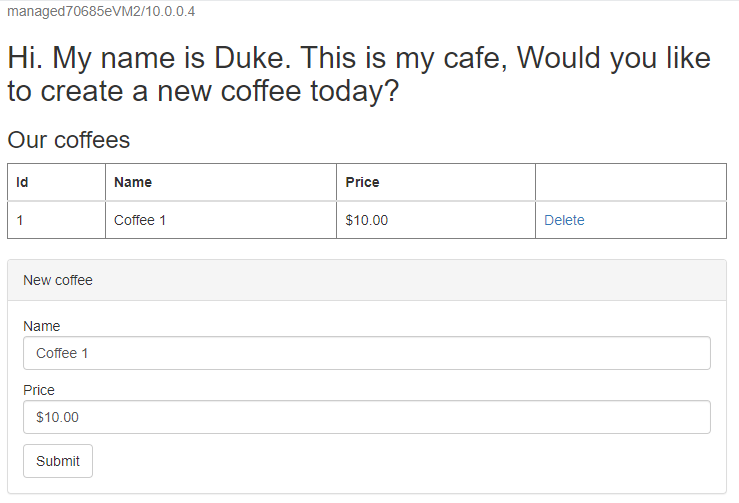

Si votre interface utilisateur ne ressemble pas à l'original, dépannez et résolvez le problème avant de continuer.
Configurer la récupération d’urgence pour le cluster à l’aide d’Azure Site Recovery
Dans cette section, vous allez configurer la récupération d’urgence pour les machines virtuelles Azure dans le cluster principal à l’aide d’Azure Site Recovery, en suivant les étapes décrites dans Tutoriel : Configurer la récupération d’urgence pour les machines virtuelles Azure. Vous avez seulement besoin des sections suivantes : Créer un coffre Recovery Services et Activer la réplication. Faites attention aux étapes suivantes lorsque vous parcourez l’article, puis revenez à cet article une fois le cluster principal protégé :
Dans la section Créer un coffre Recovery Services, procédez comme suit :
À l’étape 5 pour groupe de ressources, créez un groupe de ressources avec un nom unique dans votre abonnement, par exemple
was-cluster-westus-mjg022624.À l’étape 6 pour Nom du coffre, fournissez un nom de coffre, par exemple
recovery-service-vault-westus-mjg022624.À l’étape 7 pour Région, sélectionnez Ouest USA.
Avant de sélectionner Vérifier + créer à l’étape 8, sélectionnez Suivant : Redondance. Dans le volet Redondance, sélectionnez Géoredondant pour Redondance du stockage de sauvegarde et Activer pour Restauration interrégionale.
Remarque
Assurez-vous de sélectionner Géoredondant pour Redondance du stockage de sauvegarde et Activer pour Restauration interrégionale dans le volet Redondance. Sinon, le stockage du cluster principal ne peut pas être répliqué dans la région secondaire.
Activez Site Recovery en suivant les étapes de la section Activer site Recovery.
Lorsque vous atteignez la section Activer la réplication, procédez comme suit :
- Dans la section Sélectionner les paramètres sources, procédez comme suit :
Pour Région, sélectionnez Est des États-Unis.
Pour groupe de ressources, sélectionnez la ressource dans laquelle le cluster principal est déployé , par exemple,
was-cluster-eastus-mjg022624.Remarque
Si le groupe de ressources souhaité n’est pas répertorié, vous pouvez d’abord sélectionner USA Ouest pour la région, puis revenir à USA Est.
Conservez les valeurs par défaut pour les autres champs. Sélectionnez Suivant.
- Dans la section Sélectionner les machines virtuelles, pour machines virtuelles, sélectionnez les cinq machines virtuelles répertoriées, puis sélectionnez Suivant.
- Dans la section Vérifier les paramètres de réplication, procédez comme suit :
- Pour Emplacement cible, sélectionnez USA Ouest.
- Pour Groupe de ressources cible, sélectionnez le groupe de ressources où le coffre de récupération de service est déployé, par exemple
was-cluster-westus-mjg022624. - Notez le nouveau réseau virtuel de basculement et le sous-réseau de basculement, qui sont mappés à partir de ceux de la région primaire.
- Conservez les valeurs par défaut pour les autres champs.
- Sélectionnez suivant.
- Dans la section Gérer, procédez comme suit :
- Pour Politique de réplication, utilisez la politique par défaut Politique de rétention de 24 heures. Vous pouvez également créer une stratégie pour votre entreprise.
- Conservez les valeurs par défaut pour les autres champs.
- Sélectionnez suivant.
- Dans la section Révision, procédez comme suit :
Après avoir sélectionné Activer la réplication, notez le message Création de ressources Azure. Ne fermez pas cette fenêtre. affiché en bas de la page. Ne rien faire et attendre que le volet soit fermé automatiquement. Vous êtes redirigé vers la page Site Recovery.
Sous Éléments protégés, sélectionnez Éléments répliqués. Au départ, il n’y a pas d’éléments répertoriés, car la réplication est toujours en cours. La réplication prend environ une heure. Actualisez régulièrement la page jusqu’à ce que toutes les machines virtuelles soient dans l’état Protégé, comme illustré dans l’exemple de capture d’écran suivant :
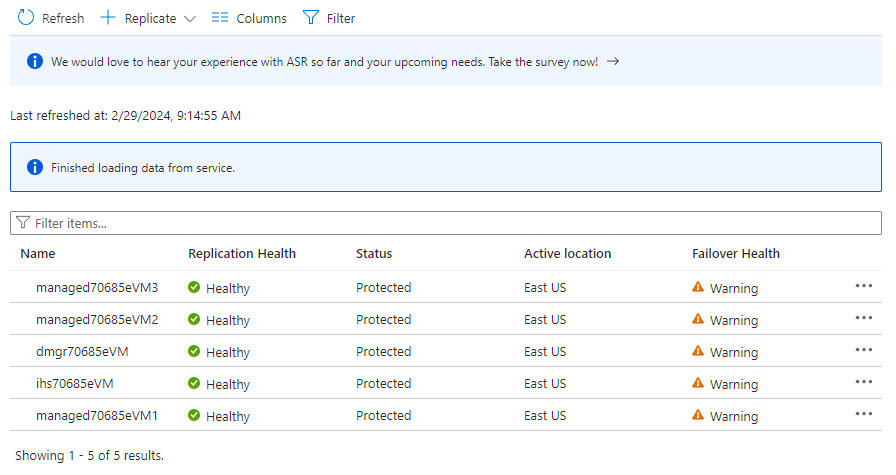
- Dans la section Sélectionner les paramètres sources, procédez comme suit :

Ensuite, créez un plan de récupération pour inclure tous les éléments répliqués afin qu’ils puissent basculer ensemble. Utilisez les instructions de Créer un plan de récupération, avec les personnalisations suivantes :
- À l’étape 2, entrez un nom pour le plan , par exemple,
recovery-plan-mjg022624. - À l’étape 3, pour source, sélectionnez USA Est et pour cible, sélectionnez USA Ouest.
- À l'étape 4 pour , sélectionnez des éléments, et sélectionnez les cinq machines virtuelles protégées pour ce didacticiel.
Ensuite, vous créez un plan de récupération. Gardez la page ouverte afin de pouvoir l’utiliser pour tester le basculement plus tard.
Configuration réseau supplémentaire pour la région secondaire
Vous avez également besoin d’une configuration réseau supplémentaire pour activer et protéger l’accès externe à la région secondaire dans un événement de basculement. Procédez comme suit pour cette configuration :
Créez une adresse IP publique pour Dmgr dans la région secondaire en suivant les instructions de Démarrage rapide : Créer une adresse IP publique à l’aide du portail Azure, avec les personnalisations suivantes :
- Pour Groupe de ressources, sélectionnez le groupe de ressources où le coffre de récupération de service est déployé, par exemple
was-cluster-westus-mjg022624. - Pour Région, sélectionnez (USA) USA Ouest.
- Pour Nom, entrez une valeur , par exemple,
dmgr-public-ip-westus-mjg022624. - Pour étiquette de nom DNS, entrez une valeur unique , par exemple,
dmgrmjg022624.
- Pour Groupe de ressources, sélectionnez le groupe de ressources où le coffre de récupération de service est déployé, par exemple
Créez une autre adresse IP publique pour IHS dans la région secondaire en suivant le même guide, avec les personnalisations suivantes :
- Pour Groupe de ressources, sélectionnez le groupe de ressources où le coffre de récupération de service est déployé, par exemple
was-cluster-westus-mjg022624. - Pour Région, sélectionnez (USA) USA Ouest.
- Pour Nom, entrez une valeur , par exemple,
ihs-public-ip-westus-mjg022624. Notez-le. - Pour étiquette de nom DNS, entrez une valeur unique , par exemple,
ihsmjg022624.
- Pour Groupe de ressources, sélectionnez le groupe de ressources où le coffre de récupération de service est déployé, par exemple
Créez un groupe de sécurité réseau dans la région secondaire en suivant les instructions de la Créer un groupe de sécurité réseau section de Créer, modifier ou supprimer un groupe de sécurité réseau, avec les personnalisations suivantes :
- Pour Groupe de ressources, sélectionnez le groupe de ressources où le coffre de récupération de service est déployé, par exemple
was-cluster-westus-mjg022624. - Pour Nom, entrez une valeur , par exemple,
nsg-westus-mjg022624. - Pour région, sélectionnez Ouest USA.
- Pour Groupe de ressources, sélectionnez le groupe de ressources où le coffre de récupération de service est déployé, par exemple
Créez une règle de sécurité entrante pour le groupe de sécurité réseau en suivant les instructions de l'Créer une règle de sécurité section du même article, avec les personnalisations suivantes :
- À l’étape 2, sélectionnez le groupe de sécurité réseau que vous avez créé , par exemple,
nsg-westus-mjg022624. - À l’étape 3, sélectionnez Règles de sécurité entrantes.
- À l’étape 4, personnalisez les paramètres suivants :
- Pour Plages de ports de destination, entrez 9060,9080,9043,9443,80.
- Pour le protocole , sélectionnez TCP.
- Pour Nom, entrez ALLOW_HTTP_ACCESS.
- À l’étape 2, sélectionnez le groupe de sécurité réseau que vous avez créé , par exemple,
Associez le groupe de sécurité réseau à un sous-réseau en suivant les instructions de la section Associer ou dissocier un groupe de sécurité réseau à ou d’un sous-réseau du même article, avec les personnalisations suivantes :
- À l’étape 2, sélectionnez le groupe de sécurité réseau que vous avez créé , par exemple,
nsg-westus-mjg022624. - Sélectionnez Associer pour associer le groupe de sécurité réseau au sous-réseau de basculement que vous avez noté précédemment.
- À l’étape 2, sélectionnez le groupe de sécurité réseau que vous avez créé , par exemple,
Configurer un Azure Traffic Manager
Dans cette section, vous allez créer un Gestionnaire de trafic Azure pour distribuer le trafic vers vos applications publiques dans les régions Azure globales. Le point de terminaison principal pointe vers l’adresse IP publique de l’IHS dans la région primaire. Le point de terminaison secondaire pointe vers l’adresse IP publique de l’IHS dans la région secondaire.
Créez un profil Azure Traffic Manager en suivant les instructions de Démarrage rapide : Créer un profil Traffic Manager à l’aide du portail Azure. Vous avez simplement besoin des sections suivantes : Créer un profil Traffic Manager et Ajouter des points de terminaison Traffic Manager. Vous devez ignorer les sections qui vous demandent de créer des ressources App Service. Procédez comme suit lorsque vous parcourez ces sections, puis revenez à cet article après avoir créé et configuré Azure Traffic Manager.
Dans la section Créer un profil Traffic Manager, à l’étape 2, pour Créer un profil Traffic Manager, procédez comme suit :
- Mettez de côté le nom unique du profil Traffic Manager pour Nom, par exemple
tmprofile-mjg022624. - Mettez de côté le nouveau nom du groupe de ressources pour le groupe de ressources , par exemple
myResourceGroupTM1.
- Mettez de côté le nom unique du profil Traffic Manager pour Nom, par exemple
Lorsque vous atteignez la section Ajouter des points de terminaison du Traffic Manager, procédez comme suit :
- Après avoir ouvert le profil Traffic Manager à l’étape 2, dans la page Configuration, procédez comme suit :
- Pour Durée de vie du DNS (TTL), entrez 10.
- Sous Paramètres de surveillance des points de terminaison, pour Chemin, entrez /websphere-cafe/, qui est la racine de contexte de l’application d’exemple déployée.
- Sous Paramètres de basculement rapide du point de terminaison, utilisez les valeurs suivantes :
- Pour Intervalle de sondage, sélectionnez 10.
- Pour Nombre toléré d’échecs, entrez 3.
- Pour Délai d’attente de la sonde, utilisez 5.
- Sélectionnez Enregistrer. Attendez qu’elle se termine.
- À l’étape 4 pour ajouter le point de terminaison principal
myPrimaryEndpoint, procédez comme suit :- Pour type de ressource cible, sélectionnez adresse IP publique.
- Sélectionnez la liste déroulante Choisir l’adresse IP publique et entrez le nom de l’adresse IP publique de l’IHS dans la région Est des États-Unis que vous avez enregistrée précédemment. Vous devriez voir une entrée correspondante. Sélectionnez-la pour Adresse IP publique.
- À l’étape 6 pour ajouter un point de terminaison de basculement/secondaire
myFailoverEndpoint, procédez comme suit :- Pour type de ressource cible, sélectionnez adresse IP publique.
- Sélectionnez la liste déroulante Choisir l’adresse IP publique et entrez le nom de l’adresse IP publique de l’IHS dans la région Ouest des États-Unis que vous avez enregistrée précédemment. Vous devriez voir une entrée correspondante. Sélectionnez-la pour Adresse IP publique.
- Attendez un certain temps. Sélectionnez Actualiser jusqu’à ce que le Statut de la surveillance du point de terminaison
myPrimaryEndpointsoit En ligne et que le Statut de la surveillance du point de terminaisonmyFailoverEndpointsoit Dégradé.
- Après avoir ouvert le profil Traffic Manager à l’étape 2, dans la page Configuration, procédez comme suit :
Ensuite, procédez comme suit pour vérifier que l’exemple d’application déployé sur le cluster WebSphere principal est accessible à partir du profil Traffic Manager :
Sélectionnez Vue d’ensemble pour le profil Traffic Manager que vous avez créé.
Sélectionnez et copiez le nom DNS (Domain Name System) du profil Traffic Manager, puis ajoutez-le avec
/websphere-cafe/, par exemple,http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/.Ouvrez l’URL dans un nouvel onglet du navigateur. Vous devriez voir le café que vous avez créé précédemment répertorié sur la page.
Créez un autre café avec un nom et un prix différents , par exemple, Café 2 avec le prix 20 - qui est conservé dans la table de données d’application et la table de session de la base de données. L’interface utilisateur que vous voyez doit ressembler à la capture d’écran suivante :
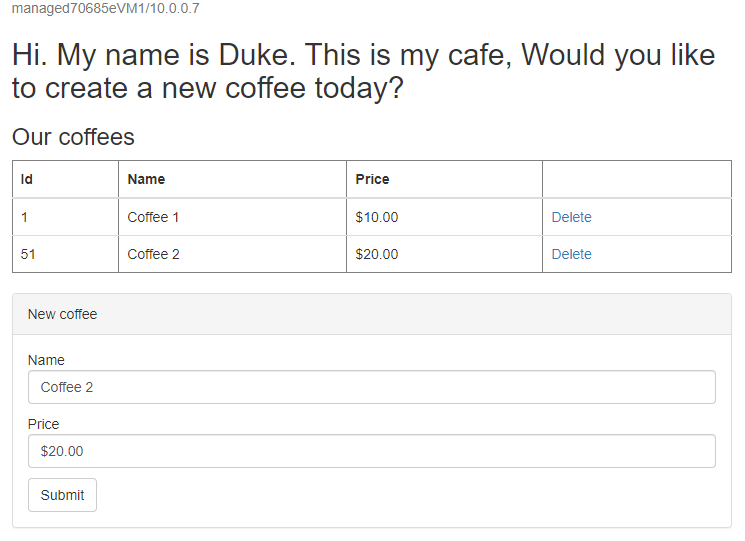

Si votre interface utilisateur ne ressemble pas à ce qui est attendu, identifiez et résolvez le problème avant de continuer. Gardez la console ouverte et utilisez-la pour tester le basculement plus tard.
Vous configurez maintenant le profil Traffic Manager. Gardez la page ouverte et utilisez-la plus tard pour surveiller le changement de statut du point de terminaison lors d'un événement de basculement.
Testez le basculement du principal au secondaire
Pour tester le basculement, vous basculez manuellement votre serveur de base de données Azure SQL et votre cluster, puis vous revenez en arrière en utilisant le portail Azure.
Basculer vers le site secondaire
Tout d’abord, procédez comme suit pour basculer Azure SQL Database du serveur principal vers le serveur secondaire :
- Revenez à l’onglet de navigateur de votre groupe de basculement Azure SQL Database, par exemple
failovergroup-mjg022624. - Sélectionnez Basculement>Oui.
- Attendez qu’elle se termine.
Ensuite, procédez comme suit pour basculer le cluster WebSphere avec le plan de récupération :
Dans la zone de recherche en haut du portail Azure, entrez Coffres Recovery Services puis sélectionnez Coffres Recovery Services dans les résultats de recherche.
Sélectionnez le nom de votre coffre Recovery Services, par exemple
recovery-service-vault-westus-mjg022624.Sous Gérer, sélectionnez Plans de récupération (Site Recovery). Sélectionnez le plan de récupération que vous avez créé , par exemple,
recovery-plan-mjg022624.Sélectionnez Basculement. Sélectionnez Je comprends le risque. Ignorer le test de basculement. Conservez les valeurs par défaut pour d’autres champs et sélectionnez OK.
Remarque
Vous pouvez éventuellement exécuter Test de basculement et Nettoyage du test de basculement pour vous assurer que tout fonctionne comme prévu avant de tester Basculement. Pour plus d'informations, consultez Tutoriel : Effectuer un exercice de récupération d'urgence pour les machines virtuelles Azure. Ce tutoriel teste directement le Basculement pour simplifier l’exercice.
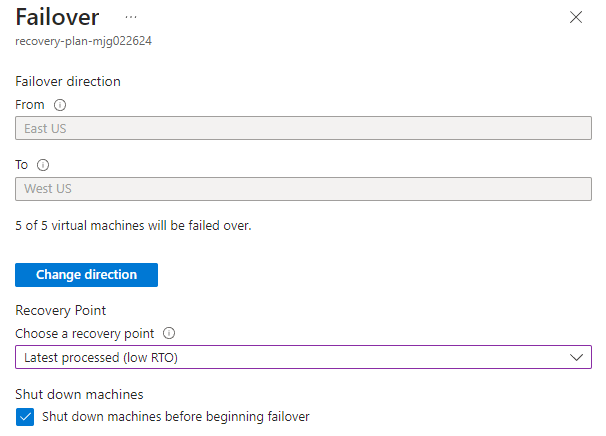
Surveillez le basculement dans les notifications jusqu’à ce qu’il soit terminé. L’exercice de ce didacticiel prend environ 10 minutes.
Vous pouvez éventuellement consulter les détails du travail de basculement en sélectionnant l’événement de basculement, par exemple Le basculement de ’recovery-plan-mjg022624’ est en cours... dans les notifications.
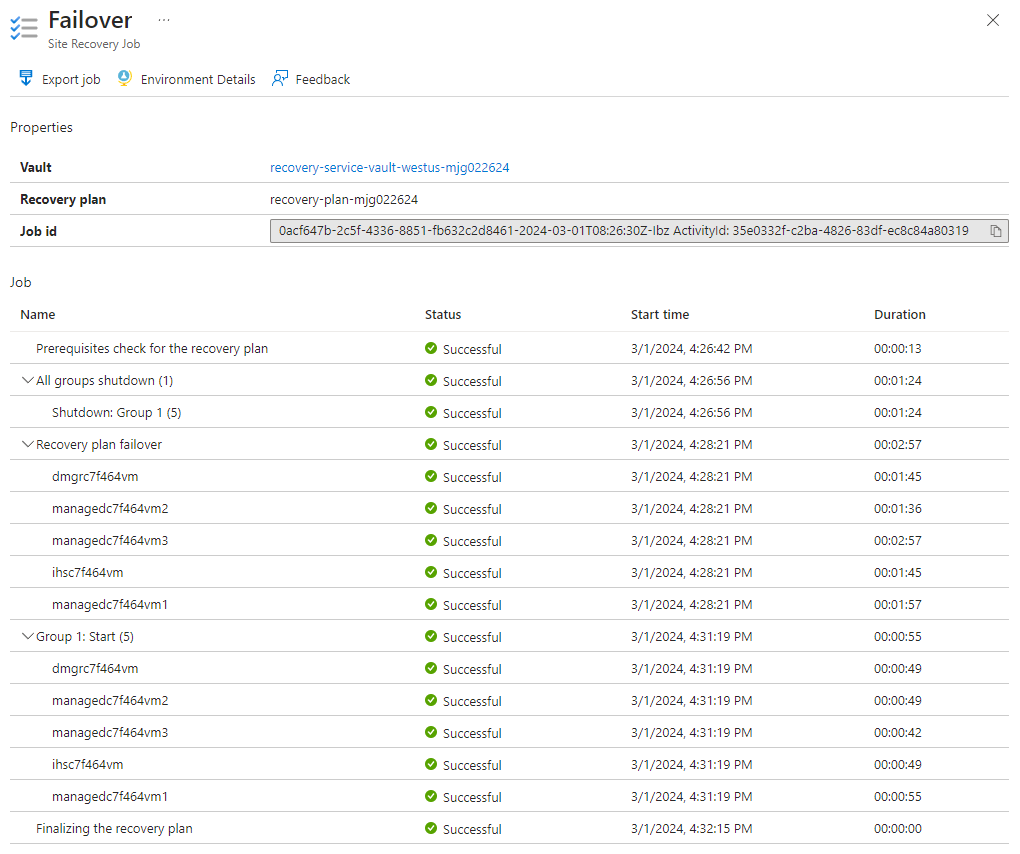




Ensuite, procédez comme suit pour activer l’accès externe à la console solutions intégrées WebSphere et à l’exemple d’application dans la région secondaire :
- Dans la zone de recherche située en haut du portail Azure, entrez groupes de ressources, puis sélectionnez groupes de ressources dans les résultats de la recherche.
- Sélectionnez le nom du groupe de ressources pour votre région secondaire, par exemple,
was-cluster-westus-mjg022624. Triez les éléments par typedans la page du groupe de ressources . - Sélectionnez interface réseau précédée de
dmgr. Sélectionnez Configurations IP>ipconfig1. Sélectionnez Associer une adresse IP publique. Pour adresse IP publique, sélectionnez l’adresse IP publique précédée dedmgr. Cette adresse est celle que vous avez créée précédemment. Dans cet article, l’adresse est nomméedmgr-public-ip-westus-mjg022624. Sélectionnez Enregistrer, puis attendez que cela se termine. - Revenez au groupe de ressources, puis sélectionnez l’interface réseau précédée de
ihs. Sélectionnez Configurations IP>ipconfig1. Sélectionnez Associer une adresse IP publique. Pour adresse IP publique, sélectionnez l’adresse IP publique précédée deihs. Cette adresse est celle que vous avez créée précédemment. Dans cet article, l’adresse est nomméeihs-public-ip-westus-mjg022624. Sélectionnez Enregistrer, puis attendez que ce soit terminé.
Maintenant, procédez comme suit pour vérifier que le basculement fonctionne comme prévu :
Recherchez l’étiquette de nom DNS pour l’adresse IP publique du Dmgr que vous avez créé précédemment. Ouvrez l’URL de la console solutions intégrées Dmgr WebSphere dans un nouvel onglet de navigateur. N’oubliez pas d’utiliser
https. Par exemple,https://dmgrmjg022624.westus.cloudapp.azure.com:9043/ibm/console. Actualisez la page jusqu’à ce que vous voyiez la page d’accueil pour la connexion.Connectez-vous à la console avec le nom d’utilisateur et le mot de passe de l’administrateur WebSphere que vous avez enregistré précédemment, puis procédez comme suit :
Dans le volet de navigation, sélectionnez Serveurs>Tous les serveurs. Dans le volet serveurs middleware, vous devez voir 4 serveurs répertoriés, y compris 3 serveurs d’applications WebSphere composés de serveurs de cluster WebSphere
MyClusteret 1 serveur web qui est un IHS. Actualisez la page jusqu’à ce que tous les serveurs soient démarrés.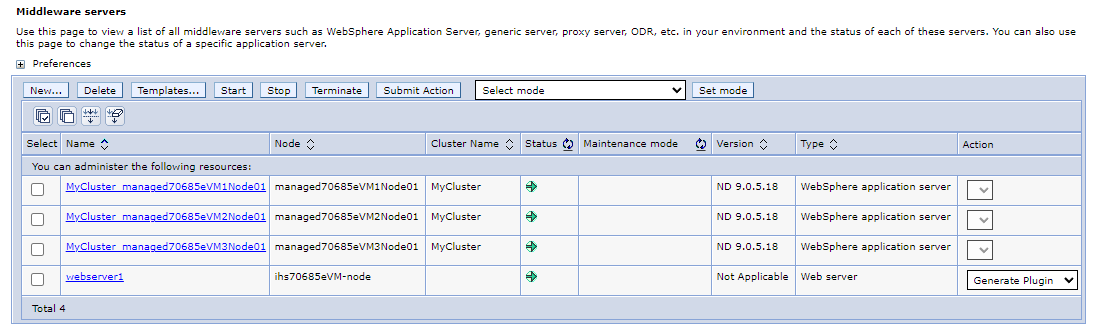
Dans le volet de navigation, sélectionnez Applications>Types d’applications>applications d’entreprise WebSphere. Dans le volet Applications d’entreprise, vous devez voir 1 application -
websphere-cafe- listée et démarrée.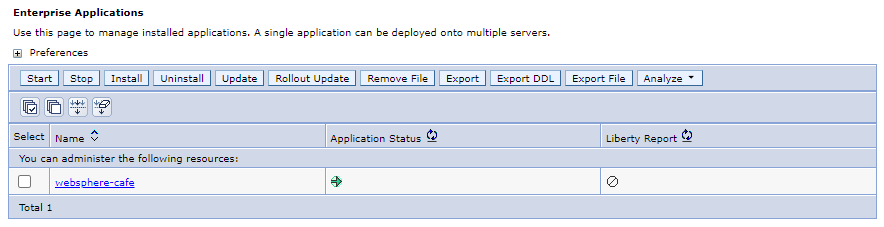
Pour valider la configuration du cluster dans la région secondaire, suivez les étapes décrites dans la section Configurer le cluster. Vous devriez voir que les paramètres pour Synchroniser les modifications avec les nœuds et Sessions distribuées sont répliqués sur le cluster de basculement, comme illustré dans les captures d’écran suivantes :
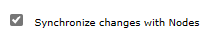
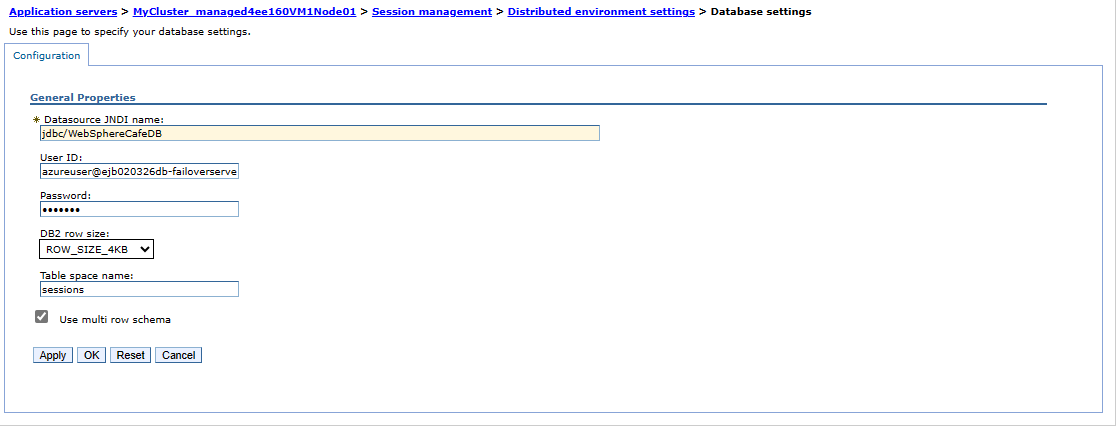
Recherchez l’étiquette de nom DNS pour l’adresse IP publique de l’IHS que vous avez créée précédemment. Ouvrez l’URL de la console IHS en ajoutant la racine de contexte
/websphere-cafe/. Notez que vous ne devez pas utiliserhttps. Cet exemple n’utilise pashttpspour IHS , par exemple,http://ihsmjg022624.westus.cloudapp.azure.com/websphere-cafe/. Vous devriez voir les deux cafés que vous avez créés précédemment listés sur la page.Passez à l’onglet du navigateur de votre profil Traffic Manager, puis rafraîchissez la page jusqu’à ce que vous voyiez que la valeur État du moniteur du point de terminaison
myFailoverEndpointdevienne En ligne et que la valeur État du moniteur du point de terminaisonmyPrimaryEndpointdevienne Dégradé.Passez à l’onglet du navigateur avec le nom DNS du profil Traffic Manager - par exemple
http://tmprofile-mjg022624.trafficmanager.net/websphere-cafe/. Actualisez la page et vous devez voir les mêmes données persistantes dans la table de données de l’application et la table de session affichée. L’interface utilisateur que vous voyez doit ressembler à la capture d’écran suivante :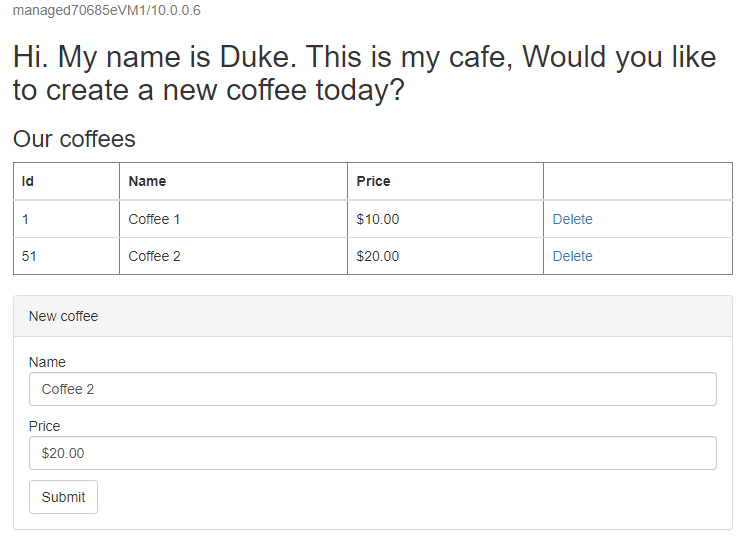
Si vous n’observez pas ce comportement, cela peut être dû au fait que Traffic Manager prend le temps de mettre à jour DNS pour qu’il pointe vers le site de basculement. Le problème peut également être que votre navigateur a mis en cache le résultat de résolution de noms DNS qui pointe vers le site ayant échoué. Attendez un certain temps et actualisez à nouveau la page.





Validez le basculement
Procédez comme suit pour valider le basculement une fois que vous êtes satisfait du résultat du basculement :
Dans la zone de recherche en haut du portail Azure, entrez Coffres Recovery Services puis sélectionnez Coffres Recovery Services dans les résultats de recherche.
Sélectionnez le nom de votre coffre Recovery Services, par exemple
recovery-service-vault-westus-mjg022624.Sous Gérer, sélectionnez Plans de récupération (Site Recovery). Sélectionnez le plan de récupération que vous avez créé , par exemple,
recovery-plan-mjg022624.Sélectionnez Valider>OK.
Surveillez la validation dans les notifications jusqu’à ce qu’elle se termine.
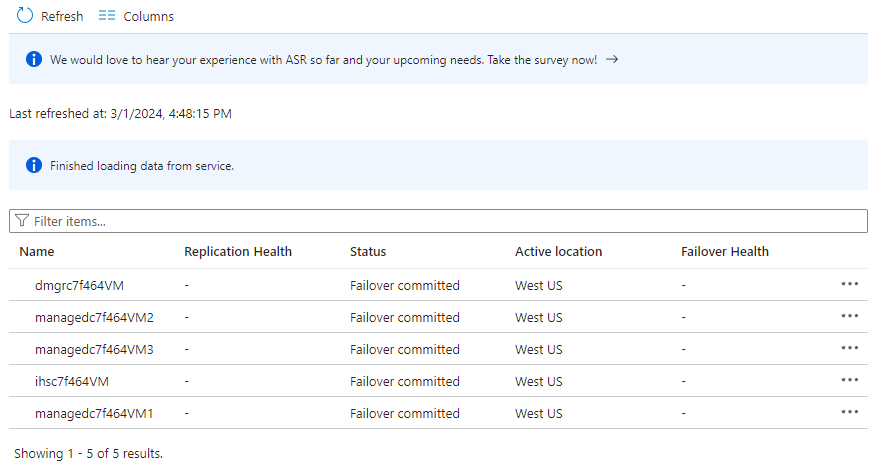
Sélectionnez Éléments dans le plan de récupération. Vous devriez voir 5 éléments listés comme Validation du basculement.



Désactiver la réplication
Procédez comme suit pour désactiver la réplication des éléments du plan de récupération, puis supprimer le plan de récupération :
Pour chaque élément de Éléments du plan de récupération, sélectionnez le bouton d'ellipse (...), puis sélectionnez Désactiver la réplication.
Si vous êtes invité à fournir une raison de désactiver la protection pour cette machine virtuelle, sélectionnez-en un que vous préférez , par exemple, j’ai terminé la migration de mon application. Sélectionnez OK.
Répétez l’étape 1 jusqu’à ce que vous désactiviez la réplication pour tous les éléments.
Surveillez le processus dans les notifications jusqu’à ce qu’il se termine.
Sélectionnez Vue d’ensemble>Supprimer. Sélectionnez Oui pour confirmer la suppression.

Préparer le retour arrière : re-protéger le site de basculement
La région secondaire est maintenant le site de basculement et est active. Vous devez la re-protéger dans votre région principale.
Tout d'abord, procédez comme suit pour nettoyer les ressources inutilisées que le service Azure Site Recovery répliquera dans votre région primaire à l'avenir. Vous ne pouvez pas simplement supprimer le groupe de ressources, car site recovery restaure les ressources dans le groupe de ressources existant.
- Dans la zone de recherche située en haut du portail Azure, entrez groupes de ressources, puis sélectionnez groupes de ressources dans les résultats de la recherche.
- Sélectionnez le nom du groupe de ressources pour votre région primaire , par exemple,
was-cluster-eastus-mjg022624. Triez les éléments par Type sur la page Groupe de ressources. - Procédez comme suit pour supprimer les machines virtuelles :
- Sélectionnez le filtre Type, puis sélectionnez Machine virtuelle dans la liste déroulante Valeur.
- Sélectionnez Appliquer.
- Sélectionnez toutes les machines virtuelles, sélectionnez Supprimer, puis entrez supprimer pour confirmer la suppression.
- Sélectionnez Supprimer.
- Surveillez le processus dans les notifications jusqu’à ce qu’il se termine.
- Procédez comme suit pour supprimer les disques :
- Sélectionnez le filtre Type, puis sélectionnez Disques dans la liste déroulante Valeur.
- Sélectionnez Appliquer.
- Sélectionnez tous les disques, sélectionnez Supprimer, puis entrez supprimer pour confirmer la suppression.
- Sélectionnez Supprimer.
- Surveillez le processus dans les notifications et attendez qu’il se termine.
- Procédez comme suit pour supprimer les points de terminaison :
- Sélectionnez le filtre Type, sélectionnez Point de terminaison privé dans la liste déroulante Valeur.
- Sélectionnez Appliquer.
- Sélectionnez tous les points de terminaison privés, sélectionnez Supprimer, puis entrez supprimer pour confirmer la suppression.
- Sélectionnez Supprimer.
- Surveillez le processus dans les notifications jusqu’à ce qu’il se termine. Ignorez cette étape si le type point de terminaison privé n’est pas répertorié.
- Procédez comme suit pour supprimer les interfaces réseau :
- Sélectionnez le filtre Type > sélectionnez Interface réseau dans la liste déroulante Valeur.
- Sélectionnez Appliquer.
- Sélectionnez toutes les interfaces réseau, sélectionnez Supprimer, puis entrez supprimer pour confirmer la suppression.
- Sélectionnez Supprimer. Surveillez le processus dans les notifications jusqu’à ce qu’il se termine.
- Pour supprimer des comptes de stockage, procédez comme suit :
- Sélectionnez le filtre Type > sélectionnez Compte de stockage dans la liste déroulante Valeur.
- Sélectionnez Appliquer.
- Sélectionnez tous les comptes de stockage, sélectionnez Supprimer, puis entrez supprimer pour confirmer la suppression.
- Sélectionnez Supprimer. Surveillez le processus dans les notifications jusqu’à ce qu’il se termine.
Ensuite, utilisez les mêmes étapes dans la section Configurer la récupération d’urgence pour le cluster à l’aide d’Azure Site Recovery pour la région primaire, à l’exception des différences suivantes :
- Pour la section Créer un coffre Recovery Services, procédez comme suit :
- Sélectionnez le groupe de ressources déployé dans la région primaire , par exemple,
was-cluster-eastus-mjg022624. - Entrez un nom différent pour le coffre de service, par exemple
recovery-service-vault-eastus-mjg022624. - Pour la région , sélectionnez Est des États-Unis.
- Sélectionnez le groupe de ressources déployé dans la région primaire , par exemple,
- Pour Activer la réplication, procédez comme suit :
- Pour Région dans Source, sélectionnez USA Ouest.
- Pour Paramètres de réplication, procédez comme suit :
- Pour groupe de ressources cible, sélectionnez le groupe de ressources existant déployé dans la région primaire, par exemple
was-cluster-eastus-mjg022624. - Pour Réseau virtuel de basculement, sélectionnez le réseau virtuel existant dans la région primaire.
- Pour groupe de ressources cible, sélectionnez le groupe de ressources existant déployé dans la région primaire, par exemple
- Pour Créer un plan de récupération, pour Source, sélectionnez Ouest des États-Unis, et pour Cible, sélectionnez Est des États-Unis.
- Ignorez les étapes de la section Configuration réseau supplémentaire pour la région secondaire, car vous avez créé et configuré ces ressources précédemment.
Remarque
Vous remarquerez peut-être qu’Azure Site Recovery prend en charge la reprotection des machines virtuelles lorsque la machine virtuelle cible existe. Pour plus d’informations, veuillez consulter la section Re-protéger la machine virtuelle de Tutoriel : Basculer les machines virtuelles Azure vers une région secondaire. En raison de l’approche que nous prenons pour WebSphere, cette fonctionnalité ne fonctionne pas. La raison est que les seules modifications entre le disque source et le disque cible sont synchronisées pour le cluster WebSphere, en fonction du résultat de la vérification. Pour remplacer la fonctionnalité de re-protection de la machine virtuelle, ce tutoriel établit une nouvelle réplication du site secondaire vers le site primaire après le basculement. Les disques entiers sont copiés de la région basculée vers la région primaire. Pour plus d’informations, veuillez consulter la section Que se passe-t-il lors de la re-protection? de Re-protéger les machines virtuelles Azure basculées vers la région primaire.
Retour au site principal
Utilisez les mêmes étapes dans la section Basculement vers le site secondaire pour revenir au site principal, y compris le serveur de base de données et le cluster, sauf pour les différences suivantes :
- Sélectionnez le coffre Recovery Services déployé dans la région primaire, par exemple
recovery-service-vault-eastus-mjg022624. - Sélectionnez le groupe de ressources déployé dans la région primaire , par exemple,
was-cluster-eastus-mjg022624. - Après avoir activé l’accès externe à la console Solutions intégrées WebSphere et l’exemple d’application dans la région primaire, réexévrez les onglets de navigateur de la console Solutions intégrées WebSphere et l’exemple d’application pour le cluster principal que vous avez ouvert précédemment. Vérifiez qu’ils fonctionnent comme prévu. Selon le temps qu’il a fallu pour revenir en arrière, il se peut que vous ne voyiez pas les données de session affichées dans la section Nouveau café de l’interface utilisateur de l’application d’exemple si elles ont expiré il y a plus d’une heure.
- Dans la section Valider le basculement, sélectionnez votre coffre Recovery Services déployé dans la région primaire par exemple
recovery-service-vault-eastus-mjg022624. - Dans le profil du gestionnaire de trafic, vous devriez voir que le point de terminaison
myPrimaryEndpointdevient En ligne et le point de terminaisonmyFailoverEndpointdevient Dégradé. - Dans la section Préparer le retour arrière : re-protéger le site de basculement, procédez comme suit :
- La région primaire est votre site de basculement et est active, vous devez donc la re-protéger dans votre région secondaire.
- Nettoyez les ressources déployées dans votre région secondaire , par exemple, les ressources déployées dans
was-cluster-westus-mjg022624. - Suivez les mêmes étapes dans la section Configurer la récupération d’urgence pour le cluster à l’aide d’Azure Site Recovery pour protéger la région primaire dans la région secondaire, en apportant les modifications suivantes :
- Ignorez les étapes de la section Créer un coffre Recovery Services car vous en avez déjà créé un précédemment, par exemple
recovery-service-vault-westus-mjg022624. - Pour Activer la réplication>Paramètres de réplication>Réseau virtuel de basculement, sélectionnez le réseau virtuel existant dans la région secondaire.
- Ignorez les étapes de la Configuration réseau supplémentaire de la région secondaire section, car vous avez créé et configuré ces ressources précédemment.
- Ignorez les étapes de la section Créer un coffre Recovery Services car vous en avez déjà créé un précédemment, par exemple
Nettoyer les ressources
Si vous ne souhaitez pas continuer à utiliser les clusters WebSphere et d’autres composants, procédez comme suit pour supprimer les groupes de ressources pour nettoyer les ressources utilisées dans ce tutoriel :
- Entrez le nom du groupe de ressources des serveurs Azure SQL Database ( par exemple,
myResourceGroup) dans la zone de recherche située en haut du portail Azure, puis sélectionnez le groupe de ressources correspondant dans les résultats de la recherche. - Sélectionnez Supprimer le groupe de ressources.
- Dans Entrez le nom du groupe de ressources pour confirmer la suppression, entrez le nom du groupe de ressources.
- Sélectionnez Supprimer.
- Répétez les étapes 1 à 4 pour le groupe de ressources du Traffic Manager , par exemple,
myResourceGroupTM1. - Dans la zone de recherche en haut du portail Azure, entrez Coffres Recovery Services puis sélectionnez Coffres Recovery Services dans les résultats de recherche.
- Sélectionnez le nom de votre coffre Recovery Services, par exemple
recovery-service-vault-westus-mjg022624. - Sous Gérer, sélectionnez Plans de récupération (Site Recovery). Sélectionnez le plan de récupération que vous avez créé , par exemple,
recovery-plan-mjg022624. - Utilisez les mêmes étapes dans la section Désactivation de la réplication pour supprimer les verrous sur les éléments répliqués.
- Répétez les étapes 1 à 4 pour le groupe de ressources du cluster WebSphere principal , par exemple,
was-cluster-westus-mjg022624. - Répétez les étapes 1 à 4 pour le groupe de ressources du cluster WebSphere secondaire, par exemple,
was-cluster-eastus-mjg022624.
Étapes suivantes
Dans ce tutoriel, vous allez configurer une solution haute disponibilité/récupération d’urgence composée d’un niveau d’infrastructure d’application actif-passif avec un niveau de base de données actif-passif, et dans laquelle les deux niveaux s’étendent sur deux sites géographiquement différents. Sur le premier site, la couche Infrastructure d’application et la couche Base de données sont actives. Sur le deuxième site, le domaine secondaire est restauré avec le service Azure Site Recovery et la base de données secondaire est en veille.
Poursuivez l’exploration des références suivantes pour obtenir d’autres options pour créer des solutions haute disponibilité/récupération d’urgence et exécuter WebSphere sur Azure :