Tutoriel : Migrer JBoss EAP Application Server vers des machines virtuelles Azure avec haute disponibilité et reprise après sinistre
Ce tutoriel vous montre un moyen simple et efficace de mettre en œuvre la haute disponibilité et la reprise après sinistre (HA/DR) pour Java à l'aide de JBoss EAP sur des machines virtuelles (VM) Azure. La solution illustre comment atteindre un objectif de temps de récupération (RTO) et un objectif de point de récupération (RPO) faibles à l'aide d'une simple application Jakarta EE pilotée par une base de données et exécutée sur le serveur d'applications JBoss EAP. HA/DR est un sujet complexe, avec de nombreuses solutions possibles. La meilleure solution dépend de vos exigences spécifiques. Pour découvrir d'autres moyens de mettre en œuvre la haute disponibilité et la reprise après sinistre, consultez les ressources à la fin de cet article.
Dans ce didacticiel, vous apprendrez à :
- Configurez le cluster JBoss EAP sur des machines virtuelles Azure.
- Utilisez les bonnes pratiques optimisées pour Azure pour atteindre la haute disponibilité et la récupération d’urgence.
- Configurez un groupe de basculement de base de données SQL Azure dans des régions appairées.
- Configurer la récupération d’urgence pour le cluster en utilisant Azure Site Recovery.
- Configurez un Azure Traffic Manager
- Testez le basculement du principal au secondaire
Le diagramme suivant illustre l'architecture que vous construisez :

Azure Traffic Manager vérifie la santé de vos régions et dirige le trafic en conséquence vers le niveau d’application. La région primaire dispose d'un déploiement complet du cluster JBoss EAP. Après que la région primaire est protégée par Azure Site Recovery, vous pouvez restaurer la région secondaire lors du basculement. En conséquence, la région primaire gère activement les requêtes réseau des utilisateurs, tandis que la région secondaire est passive et activée pour recevoir du trafic uniquement lorsque la région principale subit une interruption de service.
Azure Traffic Manager détecte l'intégrité de l'application déployée dans le cluster JBoss EAP pour mettre en œuvre le routage conditionnel. Le RTO du basculement géographique du niveau applicatif dépend du temps nécessaire pour arrêter le cluster primaire, restaurer le cluster secondaire, démarrer les machines virtuelles et faire fonctionner le cluster JBoss EAP secondaire. Le RPO dépend de la stratégie de réplication d'Azure Site Recovery et d'Azure SQL Database car les données du cluster sont stockées et répliquées dans le stockage local des machines virtuelles et les données de l'application sont persistées et répliquées dans le groupe de basculement d'Azure SQL Database
Le schéma précédent montre Région primaire et Région secondaire comme les deux régions composant l’architecture HA/DR. Ces régions doivent être des régions jumelées d’Azure. Pour plus d’informations sur les régions jumelées, veuillez consulter la section Réplication interrégionale Azure. L’article utilise USA Est et USA Ouest comme les deux régions, mais elles peuvent être n’importe quelles régions jumelées adaptées à votre scénario. Pour la liste des jumelages de régions, veuillez consulter la section Régions jumelées Azure de Réplication interrégionale Azure.
Le niveau de la base de données se compose d’un groupe de basculement de base de données SQL Azure avec un serveur principal et un serveur secondaire. Le point de terminaison de l'auditeur en lecture/écriture pointe toujours vers le serveur primaire et est connecté au cluster JBoss EAP dans chaque région Un géobasculement bascule toutes les bases de données secondaires du groupe dans le rôle principal. Pour le RPO et le RTO du basculement géographique de la base de données SQL Azure, veuillez consulter la section Vue d’ensemble de la continuité d’activité.
Ce tutoriel a été rédigé avec Azure Site Recovery et le service Azure SQL Database, car il s'appuie sur les fonctionnalités HA de ces services D'autres choix de base de données sont possibles, mais les fonctionnalités HA de la base de données que vous avez choisie, quelle qu'elle soit, doivent être prises en compte
Prérequis
- Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
- Assurez-vous d’avoir le rôle
Contributordans l’abonnement. Vous pouvez vérifier l’affectation en suivant les étapes de la section Liste des affectations de rôles Azure en utilisant le portail Azure. - Préparez une machine locale avec Windows, GNU/Linux ou macOS installé.
- Installez et configurez Git.
- Installez une implémentation Java SE, version 17 ou ultérieure , par exemple, la build Microsoft d’OpenJDK.
- Installez Maven, version 3.9.3 ou une version ultérieure.
Configurez un groupe de basculement de base de données SQL Azure dans des régions appairées
Dans cette section, vous créez un groupe de basculement Azure SQL Database dans des régions appairées pour l'utiliser avec vos clusters et votre application JBoss EAP.
Tout d’abord, créez la base de données SQL Azure principale en suivant les étapes du portail Azure dans la section Prise en main rapide : Créer une base de données unique - Azure SQL Database. Suivre les étapes jusqu'à, mais sans inclure le nettoyage des ressources. Suivez les instructions suivantes en parcourant l’article, puis revenez à cet article après avoir créé et configuré Azure SQL Database.
Lorsque vous atteignez la section Créer une base de données unique, utilisez les étapes suivantes :
À l’étape 4 pour la création d’un groupe de ressources, notez la valeur du nom du groupe de ressources , par exemple,
sqlserver-rg-gzh032124.A l'étape 5 pour le nom de la base de données, notez la valeur du nom de la base de données - par exemple,
mySampleDatabaseÀ l’étape 6 pour la création du serveur, utilisez les étapes suivantes :
- Entrez un nom de serveur unique comme
sqlserverprimary-gzh032124. - Pour Emplacement, sélectionnez (États-Unis) USA Est.
- Pour la Méthode d’authentification, sélectionnez Utiliser l’authentification SQL.
- Notez la valeur du login de l'administrateur du serveur - par exemple,
azureuser - Notez la valeur du mot de passe .
- Entrez un nom de serveur unique comme
À l’étape 8, pour l’Environnement de travail, sélectionnez Développement. Regardez la description et envisagez d’autres options pour votre charge de travail.
À l'étape 10, pour le niveau Calcul, sélectionnez Provisionné.
À l'étape 11, pour redondance du stockage de sauvegarde, sélectionnez stockage de sauvegarde à redondance locale. Envisagez d’autres options pour vos sauvegardes. Pour plus d’informations, consultez la section Redondance du stockage de sauvegarde de Sauvegardes automatisées dans Azure SQL Database.
À l’étape 14, dans la configuration des Règles du pare-feu, pour Permettre aux services et ressources Azure d’accéder à ce serveur, sélectionnez Oui.
Lorsque vous arrivez à la section Interroger la base de données, utilisez les étapes suivantes au lieu des étapes de l'autre article :
À l’étape 3, entrez vos informations de connexion d’administrateur du serveur Authentification SQL pour vous connecter.
Remarque
Si la connexion échoue avec un message d’erreur similaire à Client avec l’adresse IP « xx.xx.xx.xx » n’est pas autorisé à accéder au serveur, sélectionnez Liste d'autorisation IP xx.xx.xx.xx sur le serveur <votre-sqlserver-name> à la fin du message d’erreur. Attendez que les règles du pare-feu du serveur soient mises à jour, puis sélectionnez de nouveau OK.
Après avoir exécuté la requête d’exemple à l’étape 5, effacez l’éditeur et entrez la requête suivante, puis sélectionnez Exécuter à nouveau :
CREATE TABLE ispn_entry_sessions_javaee_cafe_war ( id VARCHAR(255) PRIMARY KEY, -- ID Column to hold cache entry ids data VARBINARY(MAX), -- Data Column to hold cache entry data timestamp BIGINT, -- Timestamp Column to hold cache entry timestamps segment INT );Après une exécution réussie, vous verrez apparaître le message Requête réussie : lignes affectées : 0.
La table de base de données
ispn_entry_sessions_javaee_cafe_warest utilisée pour stocker les données de session de votre cluster JBoss EAP.
Puis créez un groupe de basculement de base de données SQL Azure en suivant les étapes du portail Azure dans la section Configurer un groupe de basculement pour Azure SQL Database. Vous n’avez besoin que des sections suivantes : Créer un groupe de basculement et Tester le basculement planifié. Utilisez les étapes suivantes pendant que vous suivez l’article, puis revenez à cet article après avoir créé et configuré le groupe de basculement de la base de données SQL Azure :
Lorsque vous atteignez la section Créer un groupe de basculement, procédez comme suit :
À l'étape 5 de la création du groupe de basculement, saisissez et notez le nom unique du groupe de basculement - par exemple,
failovergroup-gzh032124.À l’étape 5 pour la configuration du serveur, sélectionnez l’option pour créer un nouveau serveur secondaire, puis procédez comme suit :
- Entrez un nom de serveur unique comme
sqlserversecondary-gzh032124. - Entrez le même administrateur de serveur et mot de passe que pour votre serveur principal.
- Pour l'emplacement, sélectionnez (US) USA Ouest 2.
- Assurez-vous que Autoriser les services Azure à accéder au serveur est sélectionné.
- Entrez un nom de serveur unique comme
À l’étape 5 pour la configuration des Bases de données dans le groupe, sélectionnez la base de données que vous avez créée dans le serveur principal, par exemple
mySampleDatabase.
Après avoir effectué toutes les étapes de la section Test du basculement planifié, gardez la page du groupe de basculement ouverte et utilisez-la pour le test de basculement des clusters JBoss EAP ultérieurement.
Remarque
Cet article vous guide pour créer une base de données unique Azure SQL Database avec l'authentification SQL par souci de simplicité, car la configuration HA/DR sur laquelle porte cet article est déjà très complexe. Une pratique plus sûre consiste à utiliser l'authentification Microsoft Entra pour Azure SQL pour l'authentification de la connexion au serveur de base de données.
Configurez le cluster JBoss EAP primaire sur des machines virtuelles Azure.
Dans cette section, vous créez les clusters principaux JBoss EAP sur des machines virtuelles Azure en utilisant l'offre JBoss EAP Cluster sur VMs. Le cluster secondaire est restauré à partir du cluster principal lors du basculement en utilisant Azure Site Recovery plus tard.
Déployez le cluster JBoss EAP primaire.
Tout d'abord, ouvrez l'offre JBoss EAP Cluster on machines virtuelles dans votre navigateur et sélectionnez Créer. Vous devriez voir le volet Informations de base de l’offre.
Utilisez les étapes suivantes pour remplir le volet Informations de base :
- Assurez-vous que la valeur affichée pour Abonnement est la même que celle qui contient les rôles listés dans la section des prérequis.
- Vous devez déployer l’offre dans un groupe de ressources vide. Dans le champ Groupe de ressources, sélectionnez Créer nouveau et remplissez une valeur unique pour le groupe de ressources comme
jboss-eap-cluster-eastus-gzh032124. - Sous Détails de l’instance, pour Région, sélectionnez USA Est.
- Indiquez un mot de passe pour le mot de passe et utilisez la même valeur pour Confirmer le mot de passe
- Pour Nombre de machines virtuelles à créer, entrez 3.
- Laissez les autres champs à leurs valeurs par défaut.
- Sélectionnez Suivant pour accéder au volet (Paramètres JBoss EAP.

Utilisez les étapes suivantes pour remplir le volet Paramètres JBoss EAP :
- Fournissez un mot de passe JBoss EAP pour le mot de passe JBoss EAP. Utilisez la même valeur pour Confirmer le mot de passe. Notez la valeur pour une utilisation ultérieure.
- Laissez les autres champs à leurs valeurs par défaut.
- Sélectionnez Suivant pour accéder au volet Azure Application Gateway.

Suivez les étapes suivantes pour remplir le volet de l’Application Gateway Azure :
- Pour Se connecter à Azure Application Gateway ?, sélectionnez Oui.
- Laissez les autres champs à leurs valeurs par défaut.
- Sélectionnez Suivant pour accéder au volet Networking (Mise en réseau).

Vous devriez voir tous les champs pré-remplis avec les valeurs par défaut dans le volet Mise en réseau. Sélectionnez Suivant pour passer au volet Base de données.

Pour remplir le volet base de données, procédez comme indiqué ci-dessous :
- Pour Se connecter à la base de données, sélectionnez Oui.
- Pour Choisissez le type de base de données, sélectionnez Microsoft SQL Server.
- Pour le nom JNDI, entrez java:jboss/datasources/JavaEECafeDB.
- Pour la chaîne de connexion de la source de données (jdbc:sqlserver://<host>:<port>;database=<database>), remplacez les caractères génériques par les valeurs que vous avez notées à partir de la section précédente pour le groupe de basculement d'Azure SQL Database - par exemple,
jdbc:sqlserver://failovergroup-gzh032124.database.windows.net:1433;database=mySampleDatabase. - Pour le nom d'utilisateur de la base de données, entrez le nom de connexion de l'administrateur du serveur et le nom du groupe de basculement que vous avez noté dans la section précédente - par exemple,
azureuser@failovergroup-gzh032124. - Saisissez le mot de passe de connexion à l'administrateur du serveur que vous avez noté précédemment pour le mot de passe de la base de données. Entrez la même valeur pour Confirmer le mot de passe.
- Sélectionnez Revoir + créer.
- Attendez que Exécution de la validation finale... soit terminée avec succès, puis sélectionnez Créer.

Après un moment, vous devriez voir la page Déploiement où Le déploiement est en cours est affiché.
Remarque
Si vous constatez des problèmes pendant l'exécution de la validation finale ..., corrigez-les et réessayez.
En fonction des conditions réseau et de l’activité dans votre région sélectionnée, le déploiement peut prendre jusqu’à 35 minutes pour se terminer. Après cela, le texte Votre déploiement a été effectué doit s’afficher dans la page de déploiement.
Vérifier la fonctionnalité du déploiement
Suivez les étapes suivantes pour vérifier la fonctionnalité du déploiement pour un cluster JBoss EAP sur des machines virtuelles Azure à partir de la console de gestion de Red Hat JBoss Enterprise Application Platform :
Sur la page Votre déploiement est terminé, sélectionnez Sorties.
Sélectionnez l'icône de copie à côté de adminConsole.
Collez l'URL dans un navigateur Web connecté à Internet et appuyez sur Entrée. Vous devez voir le familier écran de connexion de la console de gestion Red Hat JBoss Enterprise Application Platform, comme illustré dans la capture d’écran suivante.
Renseignez jbossadmin pour nom d’utilisateur administrateur JBoss EAP. Fournissez la valeur du mot de passe JBoss EAP que vous avez spécifiée auparavant pour Mot de passe, puis sélectionnez Se connecter.
Vous devriez voir la page d'accueil de la console de gestion Red Hat JBoss Enterprise Application Platform, comme illustré dans la capture d’écran suivante.
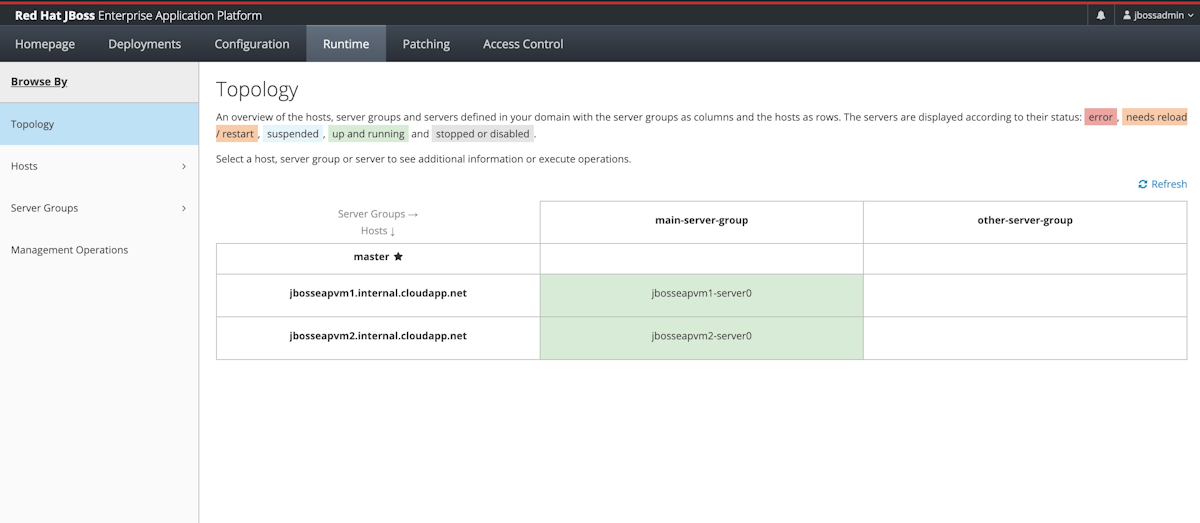
Sélectionnez l’onglet Runtime. Dans le volet de navigation, sélectionnez Topology. Vous devriez voir que le cluster contient un contrôleur de domaine maître et deux nœuds Worker, comme le montre la capture d'écran suivante :




Laissez la console de gestion ouverte. Vous l'utiliserez pour déployer un exemple d'application sur le cluster JBoss EAP dans la section suivante.
Configurer le cluster
Suivez les étapes suivantes pour configurer les sessions distribuées de la base de données pour tous les serveurs d'application :
Sélectionnez Configuration dans le panneau de navigation. Sélectionnez ensuite Profils>ha>Infinspan>Web.
Dans la colonne Cache, sélectionnez Ajouter un cache distribué.
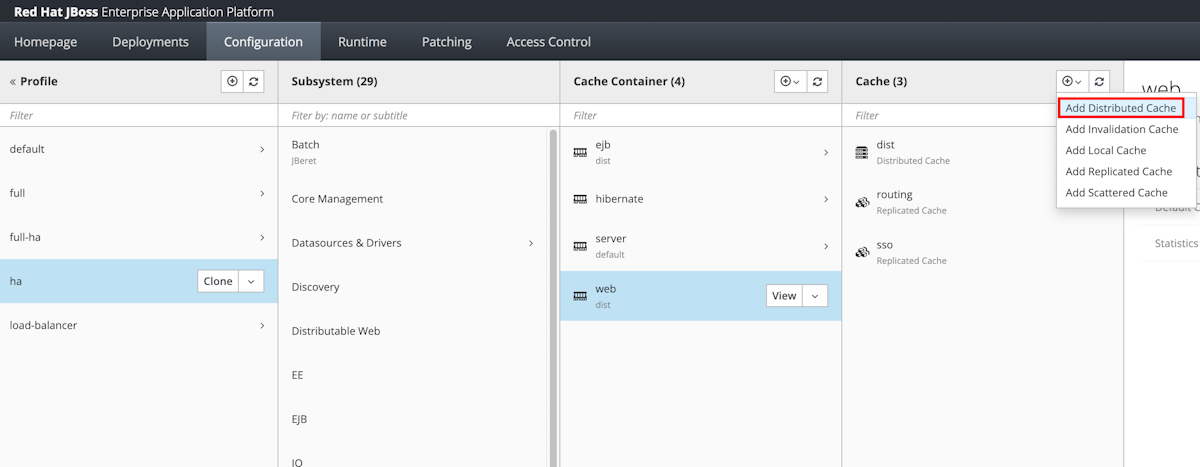
Pour Nom, entrez azure-session et sélectionnez Ajouter.
Vous devriez voir le message Distributed Cache azure-session successfully added. Si vous ne voyez pas ce message, consultez le centre de notification. Vous devez voir ce message avant de continuer.
Une fois le cache ajouté, sélectionnez azure-session>View.
Sélectionnez Store.
Modifiez le menu déroulant pour afficher JDBC, puis sélectionnez Ajouter.
Pour Data source, sélectionnez dataSource-mssqlserver, puis cliquez sur Ajouter.
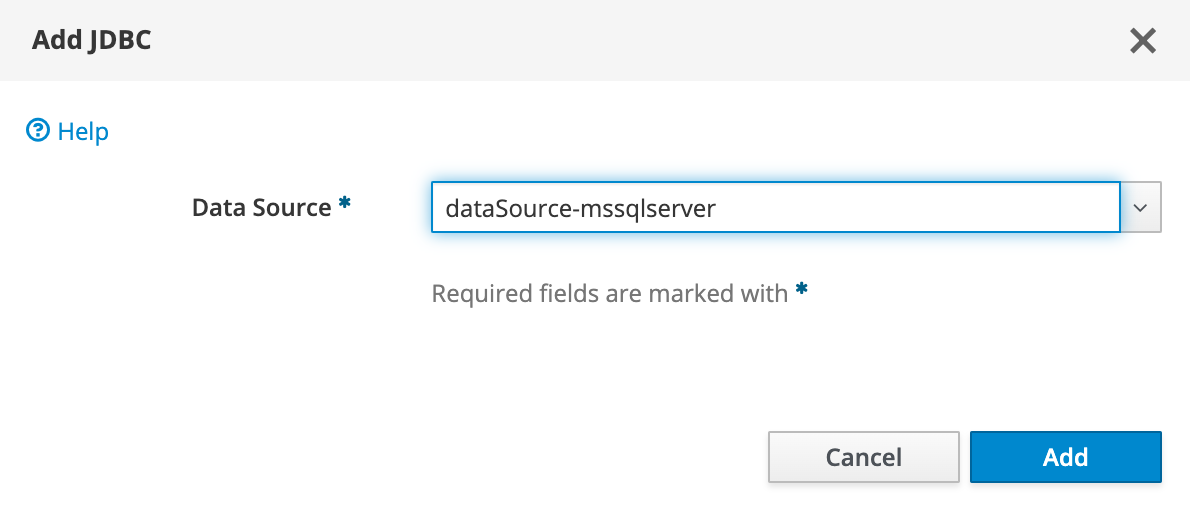
Le message suivant devrait s'afficher : JDBC a été ajouté avec succès. Si vous ne voyez pas ce message, consultez le centre de notification. Vous devez voir ce message avant de continuer.
Sur la page Store : JDBC, sélectionnez Modifier. Définissez les valeurs de propriété suivantes :
- Définir le dialecte sur SQL_SERVER.
- Réglez la passivation sur OFF.
- Régler la purge sur OFF.
- Régler Shared sur ON.
Sélectionnez Enregistrer.
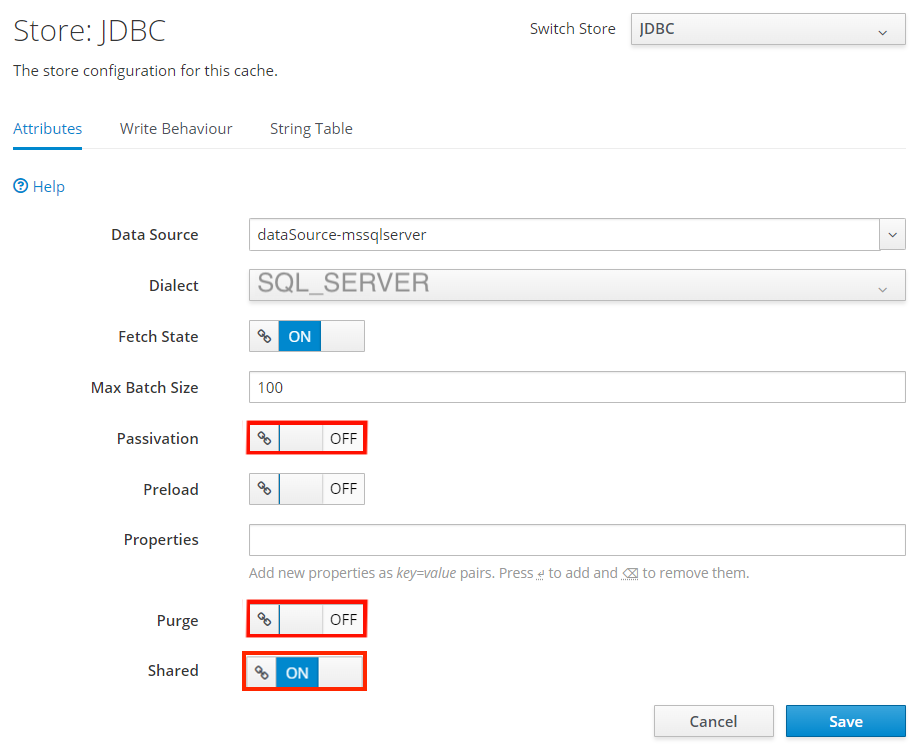
Vous devriez voir le message JDBC modifié avec succès. Si vous ne voyez pas ce message, consultez le centre de notification. Vous devez voir ce message avant de continuer.
Modifiez le tableau de chaînes en sélectionnant tableau de chaînes>Éditer Renseignez les valeurs suivantes, puis sélectionnez Enregistrer :
- Définissez le préfixe sur ispn_entry_sessions.
- Définissez ID Column / ID Column Name sur id.
- définissez ID Column / ID Column Type sur VARCHAR(255).
- Définissez Data Column / Data Column Name sur data.
- Définissez Data Column / Data Column Type sur VARBINARY(MAX).
- Définissez Timestamp Column / Timestamp Column Name sur timestamp.
- Définissez Timestamp Column / Timestamp Column Type sur BIGINT.

Toute faute de frappe entraîne l'échec de l'ensemble du système. Examinez attentivement les valeurs remplies avant de poursuivre.
Sélectionnez Enregistrer.
Le message suivant devrait s'afficher : String Table successfully modified. Si vous ne voyez pas ce message, consultez le centre de notification. Vous devez voir ce message avant de continuer.
Sélectionnez Configuration dans le volet de navigation supérieur. Sélectionnez ensuite Profiles>ha>Distributable Web>View.
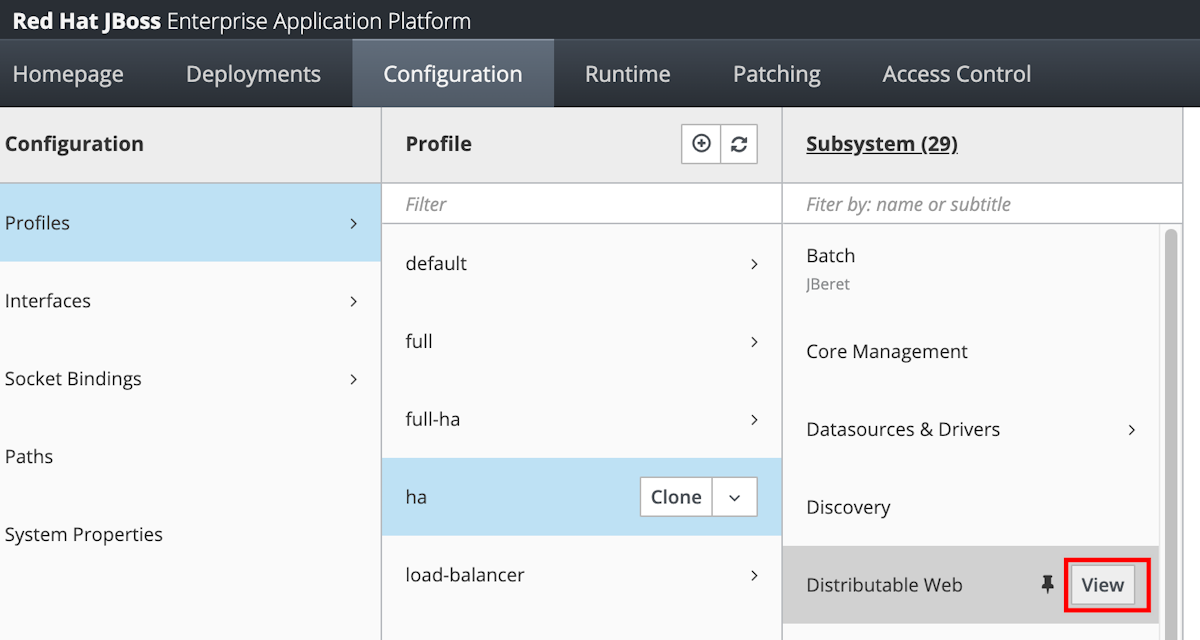
Sélectionnez Infinspan SSO>par défaut>Modifier.
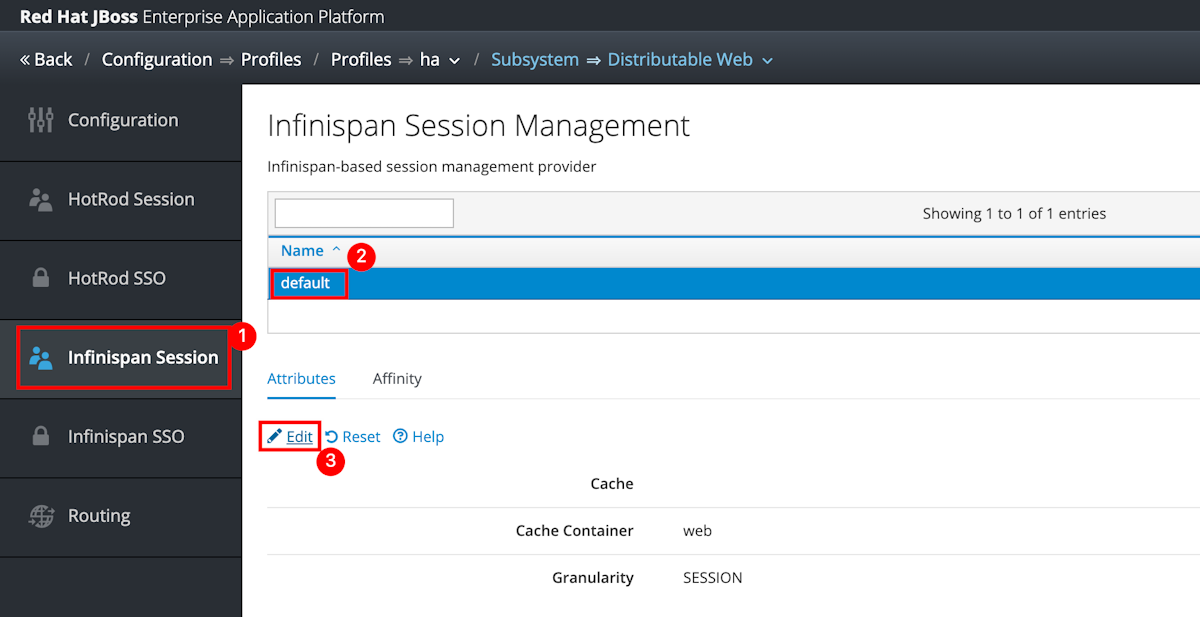
Définissez la valeur de Cache sur azure-session, puis sélectionnez Enregistrer.
Vous devriez voir le message Infinispan Single Sign On Management default successfully modified. Si vous ne voyez pas ce message, consultez le centre de notification. Vous devez voir ce message avant de continuer.
Utilisez la topologie pour recharger ou redémarrer les serveurs concernés.
Sélectionnez Runtime dans le volet de navigation, puis sélectionnez Topologie.
Pour chaque ligne de la colonne main-server-group, sélectionnez le serveur, puis sélectionnez Reload.
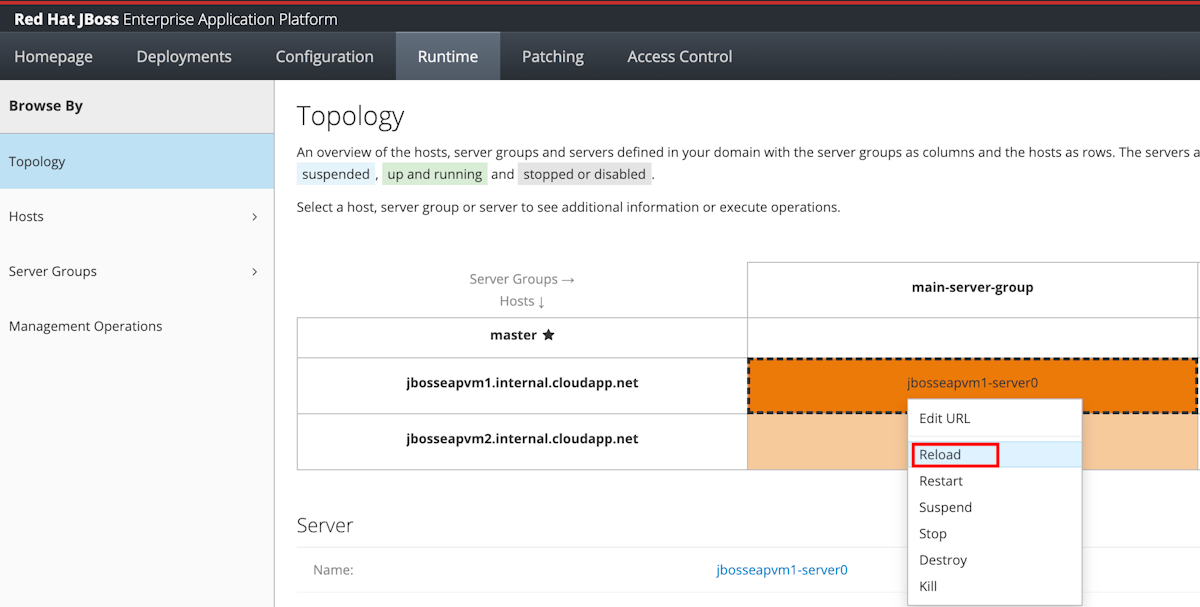
Les cellules rechargées devraient maintenant afficher la couleur verte.







Déployez l'application dans le cluster JBoss EAP
Suivez les étapes suivantes pour déployer l'application d'exemple JavaEE Cafe sur le cluster Red Hat JBoss EAP :
Suivez les étapes suivantes pour construire l'exemple Java EE Cafe. Ces étapes supposent que vous disposez d'un environnement local avec Git et Maven installés.
Utilisez la commande suivante pour cloner le code source depuis GitHub et consultez la balise correspondant à cette version de l'article :
git clone https://github.com/Azure/rhel-jboss-templates.git --branch 20240904 --single-branchSi vous voyez un message d'erreur avec le texte
You are in 'detached HEAD' state, vous pouvez l'ignorer.Utilisez la commande suivante pour générer le code source :
mvn clean install --file rhel-jboss-templates/eap-coffee-app/pom.xmlCette commande crée le fichier rhel-jboss-templates/eap-coffee-app/target/javaee-cafe.war. Vous chargez ce fichier à l'étape suivante.
Suivez les étapes suivantes dans la console de gestion de Red Hat JBoss Enterprise Application Platform pour charger le fichier javaee-cafe.war dans le référentiel de contenu :
Dans l'onglet Déploiements de la console de gestion de Red Hat JBoss EAP, sélectionnez Référentiel de contenu dans le panneau de navigation.
Sélectionnez Ajouter, puis sélectionnez Charger le contenu.

Utilisez le sélecteur de fichier de navigateur pour sélectionner le fichier javaee-cafe.war.
Sélectionnez suivant.
Acceptez les valeurs par défaut sur l’écran suivant, puis sélectionnez Finish.
Sélectionnez View content.
Suivez les étapes suivantes pour déployer une application sur
main-server-group:Dans Content Repository, sélectionnez javaee-cafe.war.
Ouvrez le menu déroulant et sélectionnez Déployer.
Sélectionnez le groupe principal de serveurs en tant que groupe de serveurs pour le déploiement de javaee-cafe.war.
Sélectionnez Déployer pour démarrer le déploiement. Une notification similaire à la capture d’écran suivante doit s’afficher :



Vous avez maintenant terminé le déploiement de l'application JavaEE. Suivez les étapes suivantes pour accéder à l'application et valider tous les paramètres :
Dans la zone de recherche située en haut du portail Azure, saisissez Groupes de ressources et sélectionnez Groupes de ressources dans les résultats de la recherche.
Sélectionnez le nom du groupe de ressources - par exemple,
jboss-eap-cluster-eastus-gzh032124Sélectionnez la ressource Application Gateway dans le groupe de ressources.
Copiez l'adresse IP publique du Frontend dans le volet Vue d'ensemble.
Construisez une URL avec l'adresse IP et le chemin d'accès - par exemple,
http://40.88.26.22/javaee-cafe.Collez l'URL dans la barre de navigation d'un navigateur Web, puis appuyez sur Entrée. Vous devriez voir la page d'accueil de l'application JavaEE Cafe.
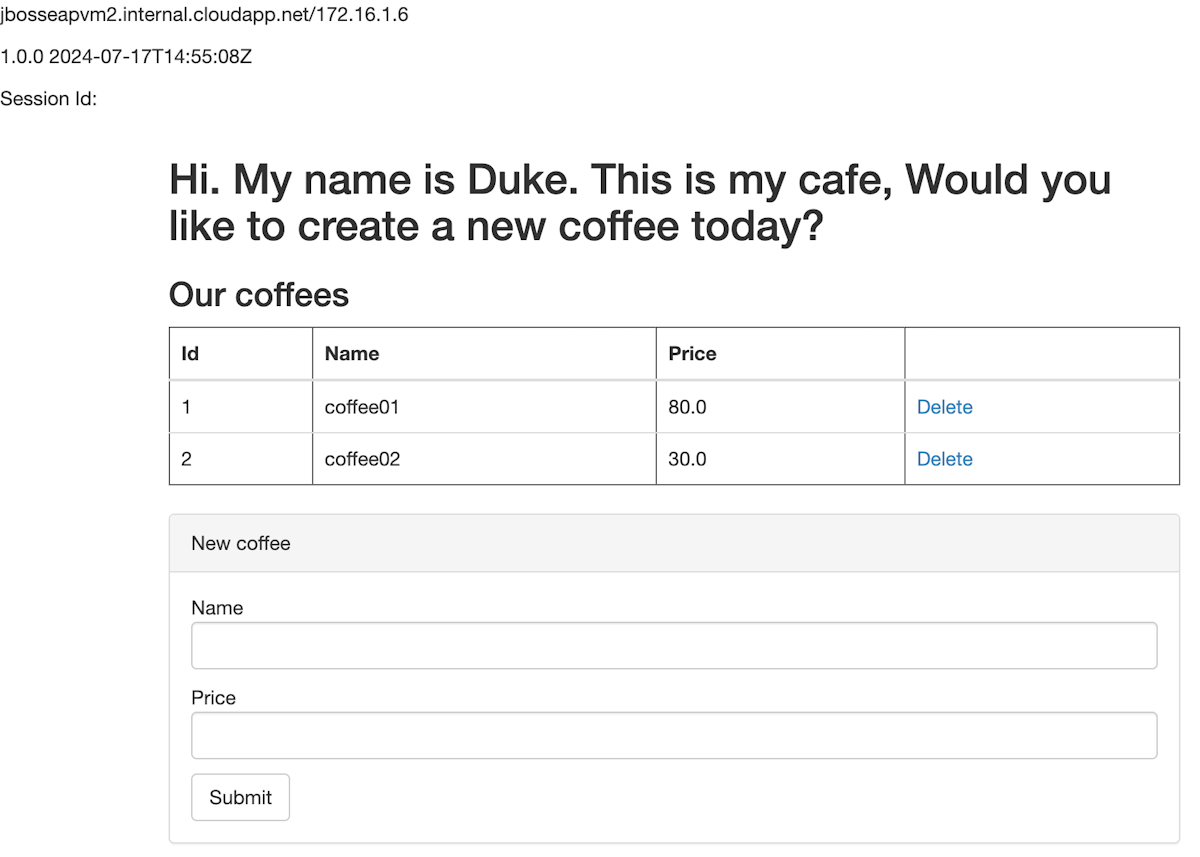
Créez deux cafés avec des noms et des prix différents. Vous devriez voir une page similaire à la capture d'écran suivante :

Configurez le cluster JBoss EAP secondaire sur des machines virtuelles Azure
Déployer le cluster JBoss EAP secondaire
Suivez les étapes de la section Déployer le cluster JBoss EAP primaire pour déployer le cluster JBoss EAP secondaire dans la région appairée. Cet exemple utilise West US 2. Lorsque vous utilisez l'offre, le cluster JBoss EAP secondaire est configuré de manière à ce que vous puissiez utiliser Azure Site Recovery pour restaurer la topologie.
Ouvrez l'offre JBoss EAP Cluster on machines virtuelles dans votre navigateur et sélectionnez Créer. Vous devriez voir le volet Informations de base de l’offre.
Utilisez les étapes suivantes pour remplir le volet Informations de base :
Dans le champ Groupe de ressources, sélectionnez Créer nouveau et remplissez une valeur unique pour le groupe de ressources comme
jboss-eap-cluster-westus-gzh032124.Sous Détails de l'instance, pour Région, sélectionnez USA Ouest 2.
Laissez les autres configurations identiques à celles du cluster primaire.
Dans le volet paramètres JBoss EAP, conservez les mêmes paramètres que pour le cluster principal.
Pour le volet Azure Application Gateway, conservez les mêmes informations que pour le cluster primaire.
Dans le volet Mise en réseau, ouvrez le paramètre Réseau virtuel et entrez l'espace d'adressage, qui est le même que celui du cluster primaire.

Procédez comme suit pour le volet Base de données :
- Gardez le même que le cluster primaire.
- Sélectionnez Revoir + créer.
- Attendez que Exécution de la validation finale... soit terminée avec succès, puis sélectionnez Créer.
Après un moment, vous devriez voir la page Déploiement où Le déploiement est en cours est affiché.
Nettoyez les ressources inutilisées dans la région secondaire.
Suivez les étapes suivantes pour nettoyer les ressources du groupe de ressources nommé jboss-eap-cluster-westus-gzh032124 qui ne sont pas utilisées et qui seront répliquées ultérieurement par le service Azure Site Recovery dans la région primaire. Cette approche peut sembler du gaspillage, mais elle permet de s'assurer que le groupe de ressources secondaire a une configuration identique à celle du primaire. Une solution de niveau production utiliserait davantage de technologies d'infrastructure en tant que code pour garantir une configuration identique, mais cela dépasse l'étendue de cet article.
Dans la zone de recherche en haut du portail Azure, entrez Groupes de ressources puis sélectionnez Groupes de ressources dans les résultats de recherche.
Sélectionnez le nom du groupe de ressources pour votre région secondaire nouvellement créée.
En regard de la zone de texte intitulée Filtre pour n'importe quel champ..., sélectionnez le X pour supprimer tous les filtres.
Sélectionnez Ajouter le filtre. Définissez Filter sur Type. Définissez Operator sur Equals.
Sélectionnez le menu déroulant en regard du champ Value.
Activez la case à cocher Sélectionner tout jusqu'à ce qu'aucune valeur ne soit sélectionnée.
Assurez-vous que tous les types suivants sont sélectionnés :
- Machine virtuelle
- Disque
- Point de terminaison privé
- Interface réseau
- Compte de stockage
Sélectionnez le menu déroulant en regard du champ Value pour fermer le menu déroulant. Vous devez voir 5 types de ressources dans le champ Valeur.
Sélectionnez Appliquer.
Cochez la case à côté de l'étiquette Nom en haut de la liste filtrée.
Sélectionnez Supprimer.
Saisissez delete confirmer la suppression, puis sélectionnez Supprimer. Surveillez le processus dans les notifications jusqu’à ce qu’il soit terminé.
Configurer la récupération d’urgence pour le cluster en utilisant Azure Site Recovery
Dans cette section, vous configurez la récupération d’urgence pour les machines virtuelles Azure dans le cluster principal en utilisant Azure Site Recovery, en suivant les étapes de Tutoriel : Configurer la récupération d’urgence pour les machines virtuelles Azure. Vous avez seulement besoin des sections suivantes : Créer un coffre Recovery Services et Activer la réplication. Faites attention aux étapes suivantes en parcourant l’article, puis revenez à cet article après que le cluster principal soit protégé :
Lorsque vous arrivez à la section Créer un coffre Recovery Services, procédez comme suit :
À l’étape 5 pour Groupe de ressources, créez un nouveau groupe de ressources avec un nom unique dans votre abonnement, par exemple
recovery-service-westus-gzh032124.À l’étape 6 pour Nom du coffre, fournissez un nom de coffre, par exemple
recovery-service-vault-westus-gzh032124.À l'étape 7 pour la région, sélectionnez USA Ouest 2.
Avant de sélectionner Examiner + créer à l'étape 8, sélectionnez Suivant : Redondance. Dans le volet Redondance, sélectionnez Géo-redondant pour la redondance du stockage de sauvegarde et Activer pour la restauration interrégionale.
Remarque
Assurez-vous de sélectionner Géo-redondant pour la redondance du stockage de sauvegarde et Activer pour la restauration interrégionale dans le volet Redondance. Sinon, le stockage du cluster primaire ne peut pas être répliqué dans la région secondaire.
Activez Site Recovery en suivant les étapes de la section Activer Site Recovery.
Lorsque vous atteignez la section Activer la réplication, procédez comme suit :
Procédez comme suit pour sélectionner les paramètres de la source :
Pour Région, sélectionnez Est des États-Unis.
Pour Groupe de ressources, sélectionnez la ressource où le cluster principal est déployé, par exemple
jboss-eap-cluster-eastus-gzh032124.Remarque
Si le groupe de ressources souhaité n'est pas répertorié, vous pouvez d'abord sélectionner USA Ouest 2 pour la région, puis revenir à USA Est.
Laissez les autres champs à leurs valeurs par défaut
Sélectionnez les machines virtuelles. Dans Machines virtuelles, sélectionnez toutes les machines virtuelles listées - par exemple, il y a 3 machines virtuelles déployées dans le cluster primaire pour ce tutoriel.
Procédez comme suit lorsque vous examinez les paramètres de réplication :
Pour l'emplacement cible, sélectionnez USA Ouest 2.
Pour Groupe de ressources cible, sélectionnez le groupe de ressources où le coffre de récupération de service est déployé, par exemple
jboss-eap-cluster-westus-gzh032124.Si le groupe de ressources attendu n'est pas affiché, sélectionnez une autre région, puis revenez à Ouest US 2.
Notez le nouveau réseau virtuel de basculement et le sous-réseau de basculement, qui sont mappés à partir de ceux de la région primaire.
Laissez les valeurs par défaut pour les autres champs.
Suivez les étapes suivantes pour gérer :
Pour Politique de réplication, utilisez la politique par défaut Politique de rétention de 24 heures. Vous pouvez également créer une nouvelle politique pour votre entreprise.
Laissez les valeurs par défaut pour les autres champs.
Suivez les étapes suivantes pour la révision :
Après avoir sélectionné Activer la réplication, remarquez le message Création de ressources Azure. Ne fermez pas cette fenêtre. affiché en bas de la page. Ne faites rien et attendez que le volet se ferme automatiquement. Vous êtes redirigé vers la page Site Recovery.
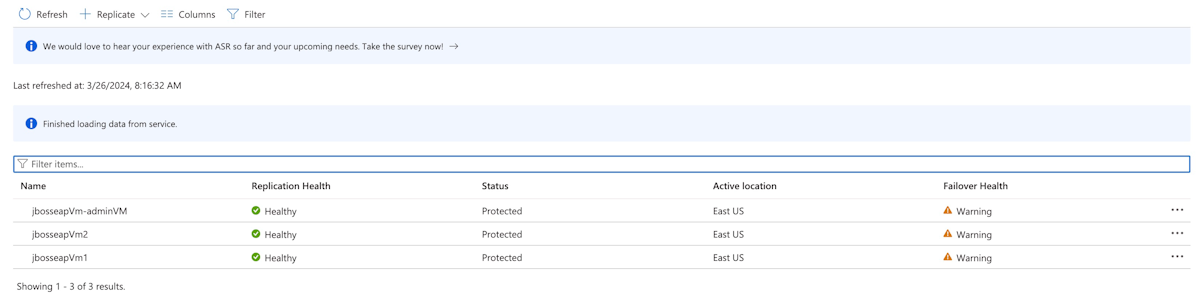
Sous Éléments protégés, sélectionnez Éléments répliqués. Au début, aucun élément n’est listé car la réplication est toujours en cours. La réplication prend du temps - environ 1 heure pour ce tutoriel. Rafraîchissez régulièrement la page jusqu'à voir que toutes les machines virtuelles sont protégées, comme illustré dans la capture d'écran suivante :

Ensuite, créez un plan de récupération pour inclure tous les éléments répliqués afin qu'ils puissent basculer ensemble. Suivez les instructions de la section Créer un plan de reprise d'activité, avec les adaptations suivantes :
- À l’étape 2, entrez un nom pour le plan, par exemple
recovery-plan-gzh032124. - À l'étape 3, sélectionnez USA Est pour Source et USA Ouest 2 pour Target.
- À l'étape 4 pour Sélectionner les éléments, sélectionnez tous les éléments protégés - par exemple, les 3 machines virtuelles protégées pour ce tutoriel.
Gardez la page ouverte afin de l'utiliser ultérieurement pour tester le basculement.
Configurez un Azure Traffic Manager
Dans cette section, vous créez un Azure Traffic Manager pour distribuer le trafic vers vos applications publiques à travers les régions Azure. Le point de terminaison principal pointe vers l'adresse IP publique de l'Application Gateway dans la région primaire, et le point de terminaison secondaire pointe vers l'adresse IP publique de la passerelle d'application dans la région secondaire.
Créez un profil Azure Traffic Manager en suivant les instructions de Prise en main rapide : Créer un profil Traffic Manager en utilisant le portail Azure. Vous avez juste besoin des sections suivantes : Créer un profil Traffic Manager et Ajouter des points de terminaison Traffic Manager. Procédez comme suit pendant ces sections, puis revenez à cet article après avoir créé et configuré le Traffic Manager Azure.
Lorsque vous atteignez la section Créer un profil Traffic Manager, à l’étape 2 Créer un profil Traffic Manager, procédez comme suit :
- Notez le nom de profil unique de Gestionnaire de Trafic pour - par exemple
tm-profile-gzh032124. - Notez le nouveau nom du groupe de ressources pour groupe de ressources, par exemple
myResourceGroupTM1.
- Notez le nom de profil unique de Gestionnaire de Trafic pour - par exemple
Lorsque vous atteignez la section Ajouter des points de terminaison Traffic Manager, procédez comme suit :
Après avoir ouvert le profil Traffic Manager à l’étape 2, sur la page Configuration, procédez comme suit :
Pour Durée de vie du DNS (TTL), entrez 10.
Sous Paramètres de basculement rapide du point de terminaison, utilisez les valeurs suivantes :
- Pour Intervalle de sondage, sélectionnez 10.
- Pour Nombre toléré d’échecs, entrez 3.
- Pour Délai d’expiration du sondage (probe), entrez 5.
Sélectionnez Enregistrer. Attendez que cela soit terminé.
À l’étape 4 pour l’ajout du point de terminaison principal
myPrimaryEndpoint, procédez comme suit :Pour Type de ressource cible, sélectionnez Adresse IP publique.
Sélectionnez la liste déroulante Choose public IP address et entrez le nom de l'adresse IP publique de l'Application Gateway dans la région USA Est. Vous devriez voir une entrée correspondante. Sélectionnez-la pour Adresse IP publique.
À l'étape 6 pour l'ajout d'un point de terminaison secondaire de basculement
myFailoverEndpoint, procédez comme suit :Pour Type de ressource cible, sélectionnez Adresse IP publique.
Sélectionnez la liste déroulante Choisissez une adresse IP publique et entrez le nom de l'adresse IP publique de l'Application Gateway dans la région USA Ouest 2. Vous devriez voir une entrée correspondante. Sélectionnez-la pour Adresse IP publique.
Patientez un moment. Sélectionnez Actualiser jusqu’à ce que le Statut de la surveillance du point de terminaison
myPrimaryEndpointsoit En ligne et que le Statut de la surveillance du point de terminaisonmyFailoverEndpointsoit Dégradé.
Ensuite, utilisez les étapes suivantes pour vérifier que l'exemple d'application déployé sur le cluster JBoss EAP primaire est accessible depuis le profil Traffic Manager :
Sélectionnez Vue d’ensemble du profil Gestionnaire de trafic que vous avez créé.
Vérifiez et copiez le nom DNS du profil Traffic Manager. Ajoutez-y /javaee-cafe/ Par exemple :
http://tm-profile-gzh032124.trafficmanager.net/javaee-cafe/.Ouvrez l’URL dans un nouvel onglet du navigateur. Vous devriez voir que le café que vous avez créé précédemment est listé dans la page.
Si votre interface utilisateur ne ressemble pas à l'attendu, dépannez et résolvez le problème avant de continuer. Gardez la console ouverte et utilisez-la pour tester le basculement plus tard.
Vous pouvez maintenant configurer le profil Traffic Manager. Gardez la page ouverte et afin que vous puissiez l'utiliser pour surveiller le changement d'état du point de terminaison dans un événement de basculement plus tard.
Testez le basculement du principal au secondaire
Les étapes de cette section testent le basculement en basculant manuellement votre serveur Azure SQL Database et votre cluster de primaire à secondaire, puis de nouveau à l'aide du portail Azure.
Basculer vers le site secondaire
Tout d’abord, procédez comme suit pour basculer la base de données Azure SQL du serveur principal vers le serveur secondaire :
- Revenez à l’onglet de navigateur de votre groupe de basculement Azure SQL Database, par exemple
failovergroup-gzh032124. - Sélectionnez Basculement>Oui.
- Attendez que cela soit terminé.
Ensuite, utilisez les étapes suivantes pour basculer le cluster JBoss EAP avec le plan de récupération :
Dans le champ de recherche situé en haut du portail Azure, saisissez coffres Recovery Services et sélectionnez Recovery Services vaults dans les résultats de la recherche.
Sélectionnez le nom de votre coffre Recovery Services, par exemple
recovery-service-vault-westus-gzh032124.Sous Gérer, sélectionnez Plans de récupération (Site Recovery). Sélectionnez le plan de récupération que vous avez créé, par exemple
recovery-plan-gzh032124.Sélectionnez Basculement. Sélectionnez Je comprends le risque. Ignorer le test de basculement. Laissez les valeurs par défaut pour les autres valeurs. Sélectionnez OK.
Remarque
En option, vous pouvez exécuter Test failover et Cleanup test failover pour vous assurer que tout fonctionne comme prévu avant le Failover. Pour plus d’informations, consultez Tutoriel : Exécuter une simulation de récupération d'urgence pour les machines virtuelles Azure. Ce didacticiel utilise directement le basculement pour simplifier l'exercice.
Surveillez le basculement dans les notifications jusqu’à ce qu’il soit terminé. L'exercice de ce tutoriel prend environ 10 minutes.
Validez le basculement
Assurez-vous que les étapes de la section précédente se sont déroulées correctement. Ensuite, suivez les étapes suivantes pour valider le basculement :
Dans le champ de recherche en haut du portail Azure, tapez Recovery Services vaults et sélectionnez-le dans les résultats de la recherche.
Sélectionnez votre coffre Recovery Services - par exemple,
recovery-service-vault-westus-gzh032124Dans la rubrique Gérer, sélectionnez Plans de récupération (Site Recovery).
Sélectionnez le plan de récupération - par exemple,
recovery-plan-gzh032124.Sélectionnez Commit, puis OK.
Surveillez les notifications jusqu'à ce qu'elles soient terminées.

Sélectionnez Éléments dans le plan de récupération. Vous devriez voir 3 éléments listés comme Validation du basculement.

Désactiver la réplication
Suivez les étapes suivantes pour désactiver la réplication des éléments du plan de récupération et pour supprimer le plan de récupération :
- Pour chaque élément dans Éléments du plan de récupération, cliquez avec le bouton droit de la souris sur l'élément, puis sélectionnez Désactiver la réplication.
- Si vous êtes invité à fournir une ou plusieurs raisons de désactiver la protection pour cette machine virtuelle, sélectionnez celle que vous préférez - par exemple, J'ai terminé la migration de mon application. Sélectionnez OK.
- Répétez l’étape 1 jusqu’à ce que vous désactiviez la réplication pour tous les éléments.
- Surveillez le processus dans les notifications jusqu’à ce qu’il soit terminé.
- Sélectionnez Aperçu>Supprimer. Sélectionnez Oui pour confirmer la suppression.
Reprotéger le site de basculement
Maintenant que la région secondaire est le site de basculement et qu'elle est active, vous devez la reprotéger dans votre région primaire.
Tout d'abord, nettoyez les ressources du groupe de ressources nommé jboss-eap-cluster-eastus-gzh032124 qui ne sont plus utilisées.
Dans la zone de recherche en haut du portail Azure, entrez Groupes de ressources puis sélectionnez Groupes de ressources dans les résultats de recherche.
Sélectionnez le nom du groupe de ressources pour votre région secondaire nouvellement créée.
En regard de la zone de texte intitulée Filtre pour n'importe quel champ..., sélectionnez le X pour supprimer tous les filtres.
Sélectionnez Ajouter le filtre. Définissez Filter sur Type. Définissez Operator sur Equals.
Sélectionnez le menu déroulant en regard du champ Value.
Activez la case à cocher Sélectionner tout jusqu'à ce qu'aucune valeur ne soit sélectionnée.
Assurez-vous que tous les types suivants sont sélectionnés :
- Machine virtuelle
- Disque
- Point de terminaison privé
- Interface réseau
- Compte de stockage
Sélectionnez le menu déroulant en regard du champ Value pour fermer le menu déroulant. Vous devez voir 5 types de ressources dans le champ Valeur.
Sélectionnez Appliquer.
Cochez la case à côté de l'étiquette Nom en haut de la liste filtrée.
Sélectionnez Supprimer.
Saisissez delete confirmer la suppression, puis sélectionnez Supprimer. Surveillez le processus dans les notifications jusqu’à ce qu’il soit terminé.
Ensuite, utilisez les mêmes étapes que dans Configurer la récupération d’urgence pour le cluster à l'aide d’Azure Site Recovery dans la région principale, à l’exception de ce qui suit :
Pour créer un coffre Recovery Services, procédez comme suit :
- Sélectionnez le groupe de ressources déployé dans la région primaire, par exemple
jboss-eap-cluster-eastus-gzh032124. - Saisissez un nom différent pour le coffre-fort de service - par exemple,
recovery-service-vault-eastus-gzh032124. - Sélectionnez USA Est pour la région.
- Sélectionnez le groupe de ressources déployé dans la région primaire, par exemple
Pour Activer la réplication, procédez comme suit :
Pour Region dans la Source, sélectionnez USA Ouest 2.
Dans Paramètres de réplication, procédez comme suit :
Pour Groupe de ressources cible, sélectionnez le groupe de ressources existant déployé dans la région primaire, par exemple
jboss-eap-cluster-eastus-gzh032124.Pour Réseau virtuel de basculement, sélectionnez le réseau virtuel existant dans la région primaire.
Pour Créer un plan de reprise, pour Source, sélectionnez USA Ouest 2 et pour Cible, USA Est.
Remarque
Vous remarquerez peut-être qu'Azure Site Recovery prend en charge la reprotection des machines virtuelles lorsque la machine virtuelle cible existe. Pour plus d’informations, consultez la section Reprotéger la machine virtuelle du Tutoriel : Basculer les machines virtuelles Azure vers une région secondaire. Cependant, cela ne fonctionne pas lorsque les seules modifications entre le disque source et le disque cible sont synchronisées pour le cluster JBoss EAP, d'après le résultat de la vérification. Ce didacticiel établit une nouvelle réplication du site secondaire vers le site principal après le basculement, dans laquelle les disques entiers sont copiés de la région défaillante vers la région primaire. Pour plus d'informations, consultez la section Que se passe-t-il pendant la reprotection ? dans Reprotéger les machines virtuelles Azure ayant subi une défaillance vers la région primaire.
Retour au site principal
Suivez les mêmes étapes que dans la section Basculement vers le site secondaire pour basculer vers le site primaire, y compris le serveur de base de données et le cluster, à l'exception des différences suivantes :
Sélectionnez le coffre Recovery Services déployé dans la région primaire, par exemple
recovery-service-vault-eastus-gzh032124.Sélectionnez le groupe de ressources déployé dans la région primaire, par exemple
jboss-eap-cluster-eastus-gzh032124.Dans la section Engager le basculement, sélectionnez votre coffre Recovery Services déployée dans le primaire - par exemple,
recovery-service-vault-eastus-gzh032124.Dans le profil du gestionnaire de trafic, vous devriez voir que le point de terminaison
myPrimaryEndpointdevient En ligne et le point de terminaisonmyFailoverEndpointdevient Dégradé.Dans la section Reprotection du site de basculement, procédez comme suit :
La région primaire est votre site de basculement et est active, vous devez donc la reprotéger dans votre région secondaire.
Nettoyez les ressources déployées dans votre région secondaire, par exemple les ressources déployées dans
jboss-eap-cluster-westus-gzh032124.Utilisez les mêmes étapes de la section Configurer la reprise après sinistre pour le cluster à l'aide d'azure Site Recovery pour protéger la région primaire dans la région secondaire, à l'exception des étapes suivantes :
Sautez les étapes de Créer un coffre Recovery Services car vous avez déjà créé un espace de stockage Recovery Services - par exemple,
recovery-service-vault-westus-gzh032124.Pour Activer la réplication>Paramètres de réplication>Réseau virtuel de basculement, sélectionnez le réseau virtuel existant dans la région secondaire.
Nettoyer les ressources
Si vous ne comptez pas continuer à utiliser les clusters JBoss EAP et les autres composants, procédez comme suit pour supprimer les groupes de ressources afin de nettoyer les ressources utilisées dans ce didacticiel :
Saisissez le nom du groupe de ressources des serveurs Azure SQL Database - par exemple,
sqlserver-rg-gzh032124- dans le champ de recherche situé en haut du portail Azure. Ensuite, sélectionnez le groupe de ressources correspondant dans les résultats de la recherche.Sélectionnez Supprimer le groupe de ressources.
Pour Saisir le nom du groupe de ressources pour confirmer la suppression, saisissez le nom du groupe de ressources.
Sélectionnez Supprimer.
Répétez les étapes 1 à 4 pour le groupe de ressources du Traffic Manager, par exemple
myResourceGroupTM1.Dans la zone de recherche en haut du portail Azure, entrez Coffres Recovery Services puis sélectionnez Coffres Recovery Services dans les résultats de recherche.
Sélectionnez le nom de votre coffre Recovery Services, par exemple
recovery-service-vault-westus-gzh032124.Sous Gérer, sélectionnez Plans de récupération (Site Recovery). Sélectionnez le plan de récupération que vous avez créé, par exemple
recovery-plan-gzh032124.Utilisez les mêmes étapes que dans la section pour désactiver la réplication afin de supprimer les verrous sur les éléments répliqués.
Répétez les étapes 1 à 4 pour le groupe de ressources du cluster JBoss EAP primaire - par exemple,
jboss-eap-cluster-westus-gzh032124Répétez les étapes 1 à 4 pour le groupe de ressources du cluster JBoss EAP secondaire - par exemple,
jboss-eap-cluster-eastus-gzh032124.
Étapes suivantes
Dans ce tutoriel, vous avez configuré une solution HA/DR composée d’une couche d’infrastructure applicative active-passive avec une couche de base de données active-passive, et dans laquelle les deux couches s’étendent sur deux sites géographiquement distincts. Sur le premier site, la couche d’infrastructure applicative et la couche de base de données sont toutes deux actives. Sur le deuxième site, le domaine secondaire est restauré avec le service Azure Site Recovery, et la base de données secondaire est en attente.
Continuez à explorer les références suivantes pour obtenir plus d'options pour construire des solutions HA/DR et exécuter JBoss EAP sur Azure :