Déployer manuellement une application Java avec JBoss EAP sur un cluster Azure Red Hat OpenShift
Cet article explique comment déployer une application Red Hat JBoss Enterprise Application Platform (EAP) sur un cluster Azure Red Hat OpenShift. L’exemple est une application Java sauvegardée par une base de données SQL. L’application est déployée à l’aide de graphiques Helm JBoss EAP.
Dans ce guide, vous allez apprendre à :
- Préparez une application JBoss EAP pour OpenShift.
- Créez une instance de base de données unique d’Azure SQL Database.
- Étant donné que l’identité de charge de travail Azure n’est pas encore prise en charge par Azure OpenShift, cet article utilise toujours le nom d’utilisateur et le mot de passe pour l’authentification de base de données au lieu d’utiliser des connexions de base de données sans mot de passe.
- Déployer l’application sur un cluster Azure Red Hat OpenShift à l’aide de JBoss Helm Charts et openShift Web Console
L’exemple d’application est une application avec état qui stocke des informations dans une session HTTP. Il utilise les fonctionnalités de clustering JBoss EAP et utilise les technologies Jakarta EE et MicroProfile suivantes :
- Jakarta Server Faces
- Jakarta Enterprise Beans
- Jakarta Persistence
- MicroProfile Health
Cet article est un guide manuel pas à pas pour exécuter l’application JBoss EAP sur un cluster Azure Red Hat OpenShift. Pour une solution plus automatisée qui accélère votre parcours vers un cluster Azure Red Hat OpenShift, consultez Démarrage rapide : Déployer JBoss EAP sur Azure Red Hat OpenShift à l’aide de la Portail Azure.
Si vous souhaitez fournir des commentaires ou travailler étroitement sur votre scénario de migration avec l’équipe d’ingénierie qui développe JBoss EAP sur des solutions Azure, renseignez cette courte enquête sur la migration JBoss EAP et incluez vos coordonnées. L’équipe de gestionnaires de programmes, d’architectes et d’ingénieurs vous contactera rapidement pour établir une collaboration.
Important
Cet article déploie une application en utilisant des charts Helm pour JBoss EAP. Au moment de la rédaction de cet article, cette fonctionnalité est encore proposée en préversion technologique. Avant de déployer des applications avec des charts Helm pour JBoss EAP dans des environnements de production, assurez-vous que cette fonctionnalité est prise en charge par la version de votre produit JBoss EAP/XP.
Important
Bien qu’Azure Red Hat OpenShift soit conçu, opéré et supporté conjointement par Red Hat et Microsoft pour offrir une expérience de support intégrée, le logiciel que vous exécutez sur Azure Red Hat OpenShift, y compris celui décrit dans cet article, est soumis à ses propres conditions de support et de licence. Pour plus d’informations sur la prise en charge d’Azure Red Hat OpenShift, consultez le cycle de vie de support d’Azure Red Hat OpenShift 4. Pour plus d’informations sur la prise en charge des logiciels décrits dans cet article, consultez les pages principales des logiciels en question, comme indiqué dans l’article.
Prérequis
Remarque
Azure Red Hat OpenShift requiert a minimum de 40 cœurs pour créer et exécuter un cluster OpenShift. Le quota de ressources Azure par défaut pour un nouvel abonnement Azure ne répond pas à cette exigence. Pour demander une augmentation de votre limite de ressources, consultez Quota standard : augmenter les limites par série de machines virtuelles. Notez que l’abonnement d’essai gratuit n’est pas éligible à une augmentation de quota. Passez à un abonnement Paiement à l’utilisation avant de demander une augmentation de quota.
Préparez une machine locale avec un système d’exploitation de type Unix pris en charge par les différents produits installés, tels que Ubuntu, macOS ou Sous-système Windows pour Linux.
Installez une implémentation java Édition Standard (SE). Les étapes de développement locales de cet article ont été testées avec le Kit de développement Java (JDK) 17 à partir de la build Microsoft d’OpenJDK.
Installez Maven 3.8.6 ou version ultérieure.
Installez Azure CLI 2.40 ou version ultérieure.
Clonez le code de cette application de démonstration (todo-list) sur votre système local. L’application de démonstration se trouve sur le site de GitHub.
Suivez les instructions de la section Créer un cluster Azure Red Hat OpenShift 4.
Bien que l’étape « Récupération d’un secret d’extraction Red Hat » soit étiquetée comme étant facultative, elle est requise pour cet article. Le secret d’extraction permet à votre cluster Azure Red Hat OpenShift de rechercher les images d’application JBoss EAP.
Si vous envisagez d’exécuter des applications gourmandes en mémoire sur le cluster, spécifiez la taille de machine virtuelle appropriée pour les nœuds Worker à l’aide du paramètre
--worker-vm-size. Pour plus d’informations, consultez l’article suivant :Connectez-vous au cluster en suivant les étapes décrites dans Se connecter à un cluster Azure Red Hat OpenShift 4.
- Suivez les étapes de la section « Installer l’interface CLI OpenShift ».
- Connectez-vous à un cluster Azure Red Hat OpenShift en utilisant l’interface CLI OpenShift avec l’utilisateur
kubeadmin.
Exécutez la commande suivante pour créer le projet OpenShift pour cette application de démonstration :
oc new-project eap-demoExécutez la commande suivante pour ajouter le rôle de consultation au compte de service par défaut. Ce rôle est nécessaire pour que l’application puisse découvrir d’autres pods et configurer un cluster avec eux :
oc policy add-role-to-user view system:serviceaccount:$(oc project -q):default -n $(oc project -q)
Préparer l’application
Clonez l’exemple d’application à l’aide de la commande suivante :
git clone https://github.com/Azure-Samples/jboss-on-aro-jakartaee
Vous avez cloné l’application Todo-list de démonstration et votre référentiel local se trouve sur la main branche. L’application de démonstration est une application Java simple qui crée, lit, met à jour et supprime des enregistrements sur Azure SQL. Vous pouvez déployer cette application telle qu’elle se trouve sur un serveur JBoss EAP installé sur votre ordinateur local. Il vous suffit de configurer le serveur avec le pilote de base de données et la source de données requis. Vous avez également besoin d'un serveur de base de données accessible depuis votre environnement local.
Toutefois, lorsque vous ciblez OpenShift, vous pouvez réduire les fonctionnalités de votre serveur JBoss EAP. Par exemple, vous pouvez réduire l’exposition de sécurité du serveur approvisionné et réduire l’empreinte globale. Vous pouvez également inclure certaines spécifications MicroProfile afin de rendre votre application plus adaptée à un environnement OpenShift. Lorsque vous utilisez JBoss EAP, une façon d’accomplir cette tâche consiste à empaqueter votre application et votre serveur dans une seule unité de déploiement appelée jar de démarrage. Pour cela, nous ajoutons les modifications requises à notre application de démonstration.
Accédez au référentiel local de votre application de démonstration et remplacez la branche par bootable-jar :
## cd jboss-on-aro-jakartaee
git checkout bootable-jar
Revenons rapidement sur ce que nous avons modifié dans cette branche :
- Nous avons ajouté le
wildfly-jar-mavenplug-in pour approvisionner le serveur et l’application dans un fichier JAR exécutable unique. L’unité de déploiement OpenShift sera maintenant notre serveur avec notre application. - Sur le plug-in Maven, nous avons spécifié un ensemble de couches Galleon. Cette configuration nous permet de réduire les fonctionnalités du serveur uniquement à ce dont nous avons besoin. Pour obtenir une documentation complète sur Galleon, consultez la documentation de WildFly.
- Notre application utilise Jakarta Faces avec des requêtes Ajax, ce qui signifie qu’il existe des informations stockées dans la session HTTP. Nous ne voulons pas perdre ces informations si un pod est supprimé. Nous pourrions enregistrer ces informations sur le client et les renvoyer à chaque requête. Toutefois, dans certains cas, vous pouvez décider de ne pas distribuer certaines informations aux clients. Pour cette démonstration, nous avons choisi de répliquer la session sur tous les réplicas de pod. Pour ce faire, nous avons ajouté
<distributable />auweb.xml. Cela, avec les fonctionnalités de clustering de serveur, rend la session HTTP distribuable sur tous les pods. - Nous avons ajouté deux contrôles d’intégrité MicroProfile qui vous permettent d’identifier quand l’application est active et prête à recevoir des demandes.
Exécuter localement l’application
Avant de déployer l’application sur OpenShift, nous allons l’exécuter localement pour vérifier son fonctionnement. Les étapes suivantes supposent que vous disposez d’Azure SQL en cours d’exécution et disponibles à partir de votre environnement local.
Pour créer la base de données, suivez les étapes de démarrage rapide : Créez une base de données unique Azure SQL Database, mais utilisez les substitutions suivantes.
- Pour le groupe de ressources, utilisez le groupe de ressources que vous avez créé précédemment.
- Pour Nom de la base de données, utilisez
todos_db. - Pour Identifiants de l’administrateur de serveur, utilisez
azureuser. - Pour mot de passe utilisez
Passw0rd!. - Dans la section Règles de pare-feu, basculez l’option Autoriser les services et ressources Azure à accéder à ce serveur sur Oui.
Tous les autres paramètres peuvent être utilisés en toute sécurité à partir de l’article lié.
Dans la page Paramètres supplémentaires , vous n’avez pas à choisir l’option permettant de préremplir la base de données avec des exemples de données, mais il n’y a pas de mal à le faire.
Après avoir créé la base de données, obtenez la valeur du nom du serveur à partir de la page vue d’ensemble. Pointez la souris sur la valeur du champ Nom du serveur et sélectionnez l’icône de copie qui apparaît à côté de la valeur. Enregistrez cette valeur de côté pour une utilisation ultérieure (nous définissons une variable nommée MSSQLSERVER_HOST sur cette valeur).
Remarque
Pour réduire les coûts monétaires, le guide de démarrage rapide indique au lecteur de sélectionner le niveau de calcul serverless. Ce niveau est mis à l’échelle à zéro en l’absence d’activité. Dans ce cas, la base de données ne réagit pas immédiatement. Si, à un moment quelconque de l’exécution des étapes décrites dans cet article, vous observez des problèmes liés à la base de données, envisagez de désactiver la mise en pause automatique. Pour savoir comment faire, recherchez Pause automatique dans Azure SQL Database serverless. Au moment de l’écriture, la commande AZ CLI suivante désactive la pause automatique pour la base de données configurée dans cet article. az sql db update --resource-group $RESOURCEGROUP --server <Server name, without the .database.windows.net part> --name todos_db --auto-pause-delay -1
Suivez les étapes suivantes pour générer et exécuter l’application localement.
Générez le fichier JAR de démarrage. Étant donné que nous utilisons la
eap-datasources-galleon-packbase de données MS SQL Server, nous devons spécifier la version du pilote de base de données que nous voulons utiliser avec cette variable d’environnement spécifique. Pour plus d’informations sur ms SQL Server et leeap-datasources-galleon-packserveur SQL Server, consultez la documentation de Red Hatexport MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 mvn clean packageLancez le fichier JAR de démarrage à l’aide des commandes suivantes.
Vous devez vous assurer que la base de données Azure SQL autorise le trafic réseau à partir de l’hôte sur lequel ce serveur s’exécute. Étant donné que vous avez sélectionné Ajouter l’adresse IP client actuelle lors de la procédure Démarrage rapide : Créer une base de données unique Azure SQL Database, si l’hôte sur lequel le serveur s’exécute est le même hôte que celui à partir duquel votre navigateur se connecte au portail Azure, le trafic réseau doit être autorisé. Si l’hôte sur lequel le serveur s’exécute est un autre hôte, vous devez faire référence à Utiliser le Portail Azure pour gérer les règles de pare-feu IP au niveau du serveur.
Lorsque nous lancez l’application, nous devons transmettre les variables d’environnement requises pour configurer la source de données :
export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:runSi vous souhaitez en savoir plus sur le runtime sous-jacent utilisé dans cette démonstration, la documentation Galleon Feature Pack pour l’intégration des sources de données contient une liste complète des variables d’environnement disponibles. Pour plus d’informations sur le concept de pack de fonctionnalités, consultez la documentation de WildFly.
Si vous recevez une erreur avec du texte similaire à l’exemple suivant :
Cannot open server '<your prefix>mysqlserver' requested by the login. Client with IP address 'XXX.XXX.XXX.XXX' is not allowed to access the server.Ce message indique que vos étapes pour vous assurer que le trafic réseau est autorisé n’a pas fonctionné. Vérifiez que l’adresse IP du message d’erreur est incluse dans les règles de pare-feu.
Si vous recevez un message avec du texte similaire à l’exemple suivant :
Caused by: com.microsoft.sqlserver.jdbc.SQLServerException: There is already an object named 'TODOS' in the database.Ce message indique que les échantillons de données se trouvent déjà dans la base de données. Ignorez ce message.
(Facultatif) Si vous voulez vérifier les capacités de clustering, vous pouvez également lancer d’autres instances de la même application en transmettant au fichier JAR de démarrage l’argument
jboss.node.nameet, afin d’éviter les conflits avec les numéros de port, en décalant les numéros de port en utilisantjboss.socket.binding.port-offset. Par exemple, pour lancer une deuxième instance qui représente un nouveau pod sur OpenShift, vous pouvez exécuter la commande suivante dans une nouvelle fenêtre de terminal :export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:run -Dwildfly.bootable.arguments="-Djboss.node.name=node2 -Djboss.socket.binding.port-offset=1000"Si votre cluster fonctionne, vous pouvez voir sur la console serveur une trace similaire à celle-ci :
INFO [org.infinispan.CLUSTER] (thread-6,ejb,node) ISPN000094: Received new cluster view for channel ejbRemarque
Par défaut, le fichier JAR de démarrage configure le sous-système JGroups pour qu’il utilise le protocole UDP et envoie des messages pour découvrir les autres membres du cluster à l’adresse de multidiffusion 230.0.0.4. Pour vérifier correctement les capacités de clustering sur votre ordinateur local, votre système d’exploitation doit être capable d’envoyer et de recevoir des datagrammes de multidiffusion et de les acheminer vers l’adresse IP 230.0.0.4 via votre interface Ethernet. Si vous voyez des avertissements liés au cluster dans les journaux du serveur, vérifiez votre configuration réseau et assurez-vous qu’elle prend en charge la multidiffusion à cette adresse.
Ouvrez
http://localhost:8080/dans votre navigateur pour accéder à la page d’accueil de l’application. Si vous avez créé d’autres instances, vous pouvez y accéder en déplaçant le numéro de port, par exemplehttp://localhost:9080/. L’application doit ressembler à l’image suivante :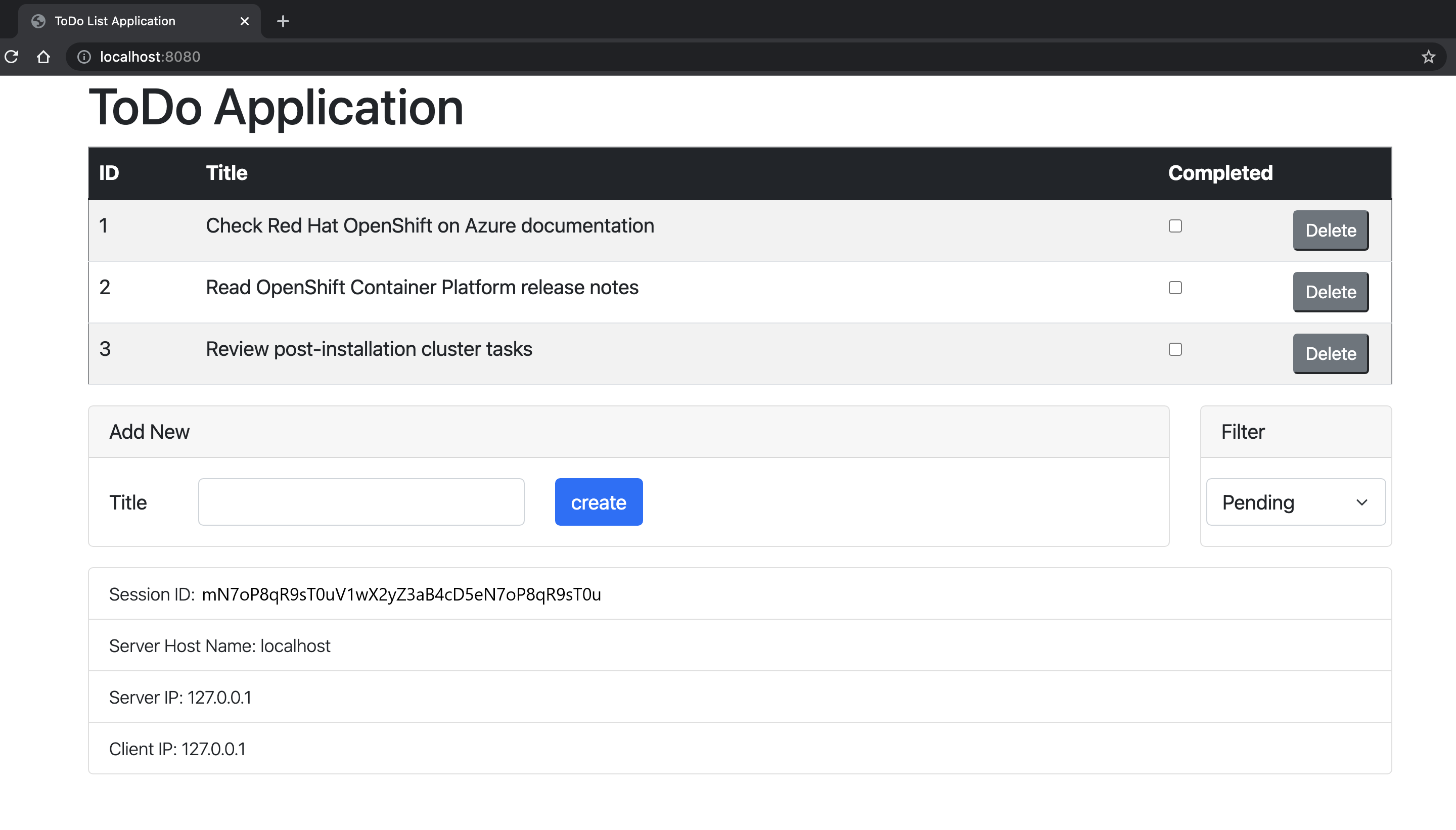
Vérifiez les probes liveness et readiness pour l’application. OpenShift utilise ces points de terminaison pour vérifier quand votre pod est actif et prêt à recevoir des demandes utilisateur.
Pour vérifier l’état de probe liveness, exécutez :
curl http://localhost:9990/health/liveCette sortie doit s’afficher :
{"status":"UP","checks":[{"name":"SuccessfulCheck","status":"UP"}]}Pour vérifier l’état de préparation, exécutez :
curl http://localhost:9990/health/readyCette sortie doit s’afficher :
{"status":"UP","checks":[{"name":"deployments-status","status":"UP","data":{"todo-list.war":"OK"}},{"name":"server-state","status":"UP","data":{"value":"running"}},{"name":"boot-errors","status":"UP"},{"name":"DBConnectionHealthCheck","status":"UP"}]}Appuyez sur Contrôle+C pour arrêter l’application.
Déployer sur OpenShift
Pour déployer l’application, nous allons utiliser les graphiques Helm JBoss EAP déjà disponibles dans Azure Red Hat OpenShift. Nous devons également fournir la configuration souhaitée, par exemple, l’utilisateur de la base de données, le mot de passe de la base de données, la version du pilote que nous voulons utiliser et les informations de connexion utilisées par la source de données. Les étapes suivantes supposent que vous avez Azure SQL en cours d’exécution et accessible à partir de votre cluster OpenShift, et que vous avez stocké le nom d’utilisateur de la base de données, le mot de passe, le nom d’hôte, le port et le nom de la base de données dans un objet Secret OpenShift OpenShift nommé mssqlserver-secret.
Accédez au référentiel local de votre application de démonstration et remplacez la branche actuelle par bootable-jar-openshift :
git checkout bootable-jar-openshift
Examinons rapidement ce que nous avons changé dans cette branche :
- Nous avons ajouté un nouveau profil Maven nommé
bootable-jar-openshiftqui prépare le fichier JAR de démarrage avec une configuration spécifique pour l’exécution du serveur sur le cloud. Par exemple, il permet au sous-système JGroups d’utiliser des requêtes réseau pour découvrir d’autres pods à l’aide du protocole KUBE_PING. - Nous avons ajouté un ensemble de fichiers de configuration dans le répertoire jboss-on-aro-jakartaee/deployment . Dans ce répertoire, vous trouverez les fichiers de configuration pour déployer l’application.
Déployer l’application sur OpenShift
Les étapes suivantes expliquent comment déployer l’application avec un chart Helm à l’aide de la console web OpenShift. Évitez de coder en dur des valeurs sensibles dans votre graphique Helm à l’aide d’une fonctionnalité appelée « secrets ». Un secret est simplement une collection de paires name=value, où les valeurs sont spécifiées dans un endroit connu avant qu’elles ne soient nécessaires. Dans notre cas, le chart Helm utilise deux secrets, avec les paires nom=valeur suivantes.
mssqlserver-secretdb-hosttransmet la valeur deMSSQLSERVER_HOST.db-nametransmet la valeur deMSSQLSERVER_DATABASEdb-passwordtransmet la valeur deMSSQLSERVER_PASSWORDdb-porttransmet la valeur deMSSQLSERVER_PORT.db-usertransmet la valeur deMSSQLSERVER_USER.
todo-list-secretapp-cluster-passwordtransmet un mot de passe quelconque spécifié par l’utilisateur afin que les nœuds de cluster puissent se former de manière plus sécurisée.app-driver-versiontransmet la valeur deMSSQLSERVER_DRIVER_VERSION.app-ds-jnditransmet la valeur deMSSQLSERVER_JNDI.
Créez
mssqlserver-secret.oc create secret generic mssqlserver-secret \ --from-literal db-host=${MSSQLSERVER_HOST} \ --from-literal db-name=${MSSQLSERVER_DATABASE} \ --from-literal db-password=${MSSQLSERVER_PASSWORD} \ --from-literal db-port=${MSSQLSERVER_PORT} \ --from-literal db-user=${MSSQLSERVER_USER}Créez
todo-list-secret.export MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 oc create secret generic todo-list-secret \ --from-literal app-cluster-password=mut2UTG6gDwNDcVW \ --from-literal app-driver-version=${MSSQLSERVER_DRIVER_VERSION} \ --from-literal app-ds-jndi=${MSSQLSERVER_JNDI}Ouvrez la console OpenShift et accédez à la vue des développeurs. Vous pouvez découvrir l’URL de console de votre cluster OpenShift en exécutant cette commande. Connectez-vous avec l’id utilisateur et le
kubeadminmot de passe que vous avez obtenus à partir d’une étape précédente.az aro show \ --name $CLUSTER \ --resource-group $RESOURCEGROUP \ --query "consoleProfile.url" \ --output tsvSélectionnez le <point de vue du> développeur dans le menu déroulant en haut du volet de navigation.
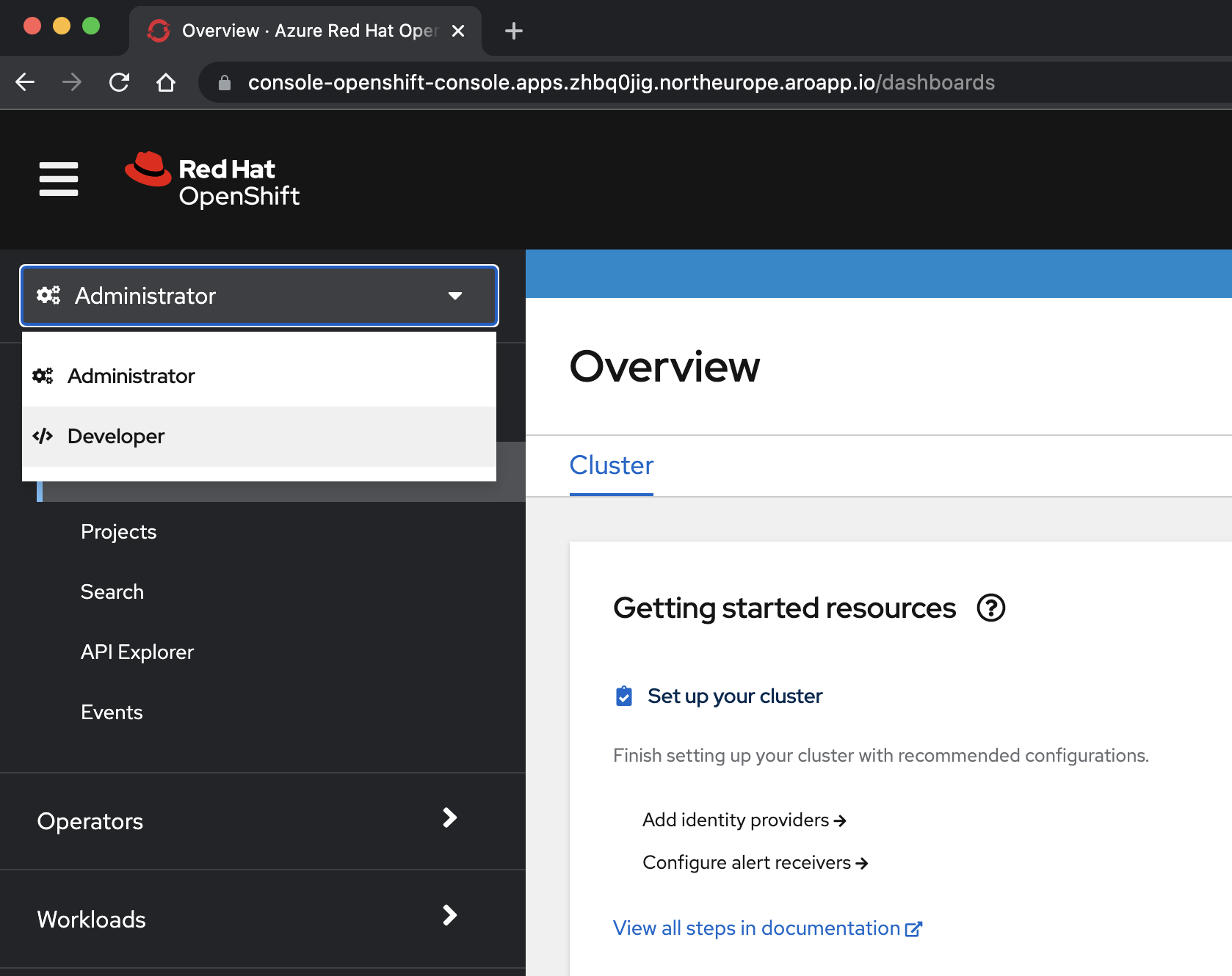
Dans la <perspective /> Développeur , sélectionnez le projet eap-demo dans le menu déroulant Project .
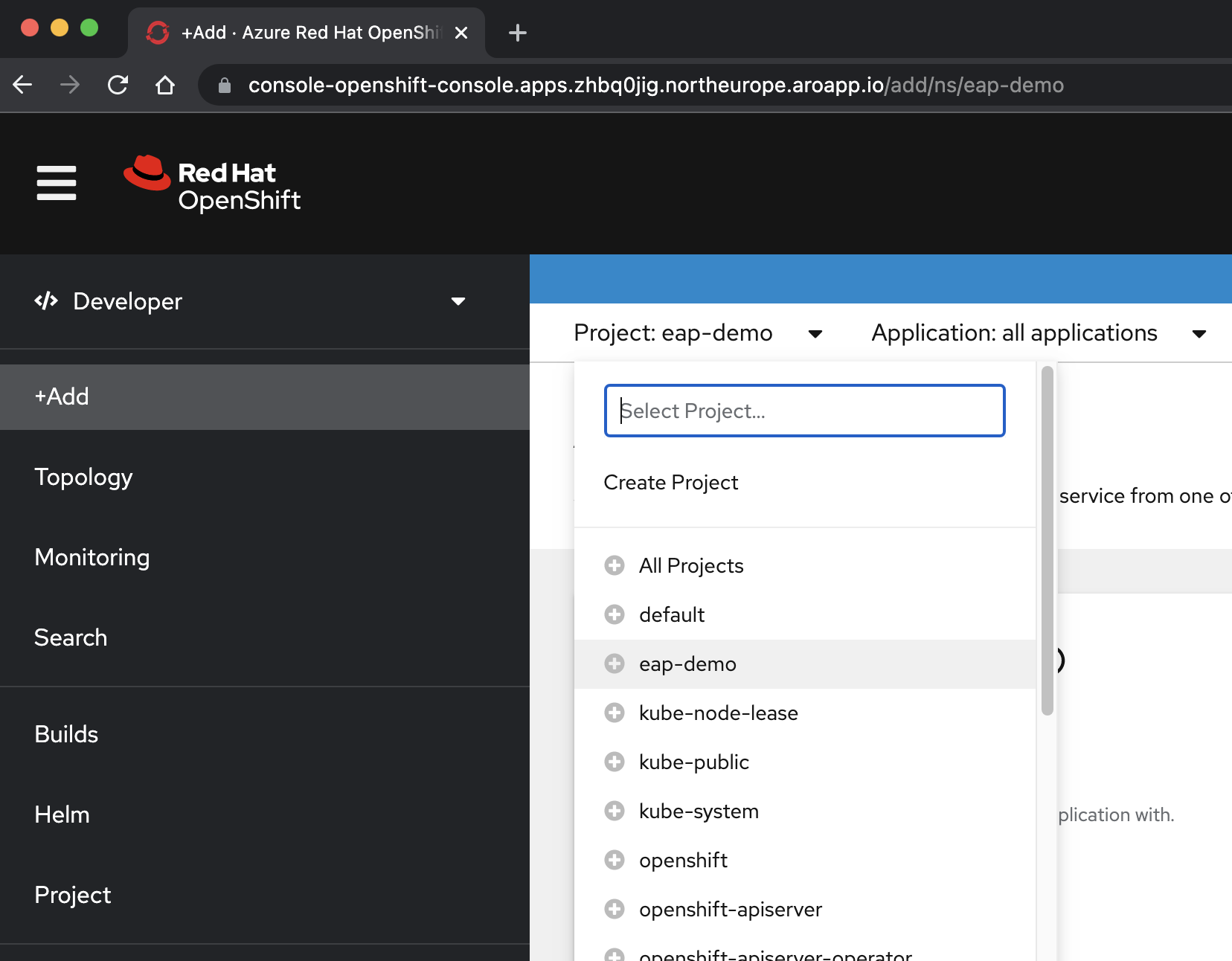
Sélectionnez +Ajouter. Dans la section Catalogue des développeurs, sélectionnez Helm Chart. Vous arrivez au catalogue Helm Chart disponible sur votre cluster Azure Red Hat OpenShift. Dans la zone Filtrer par mot clé, saisissez eap. Vous devez voir plusieurs options, comme illustré ici :
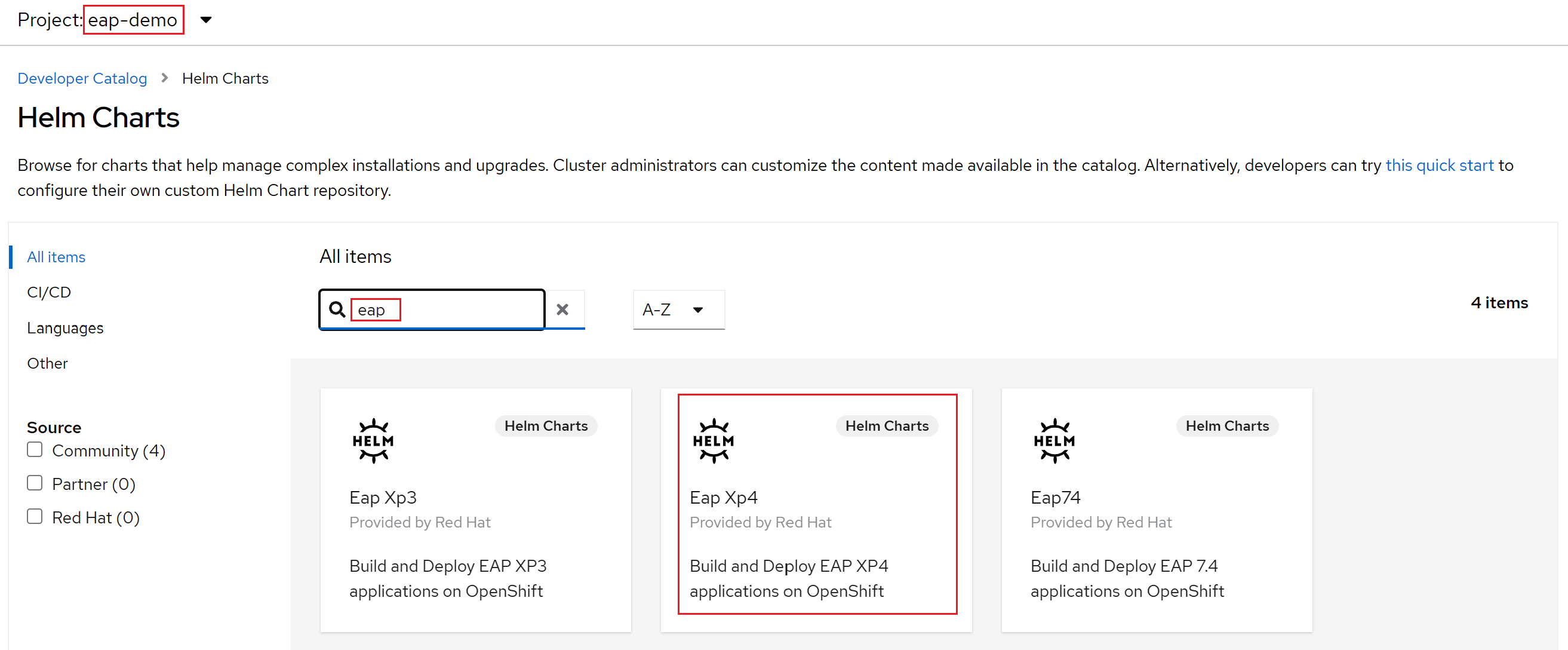
Étant donné que notre application utilise des fonctionnalités MicroProfile, nous sélectionnons le graphique Helm pour EAP Xp.
Xpsignifie Pack d’extension. Grâce au pack d’extension JBoss Enterprise Application Platform, les développeurs peuvent utiliser des interfaces de programmation d’applications (API) Eclipse MicroProfile pour générer et déployer des applications basées sur des microservices.Sélectionnez le graphique Helm JBoss EAP XP 4 , puis sélectionnez Installer Helm Chart.
À ce stade, nous devons configurer le chart pour générer et déployer l’application :
Modifiez le nom de la version en eap-todo-list-demo.
Nous pouvons configurer le chart Helm à l’aide d’une vue formulaire ou d’une vue YAML. Dans la section Intitulée Configurer via, sélectionnez Vue YAML.
Modifiez le contenu YAML pour configurer le chart Helm en copiant et en collant le contenu du fichier Helm Chart disponible dans deployment/application/todo-list-helm-chart.yaml à la place du contenu existant :
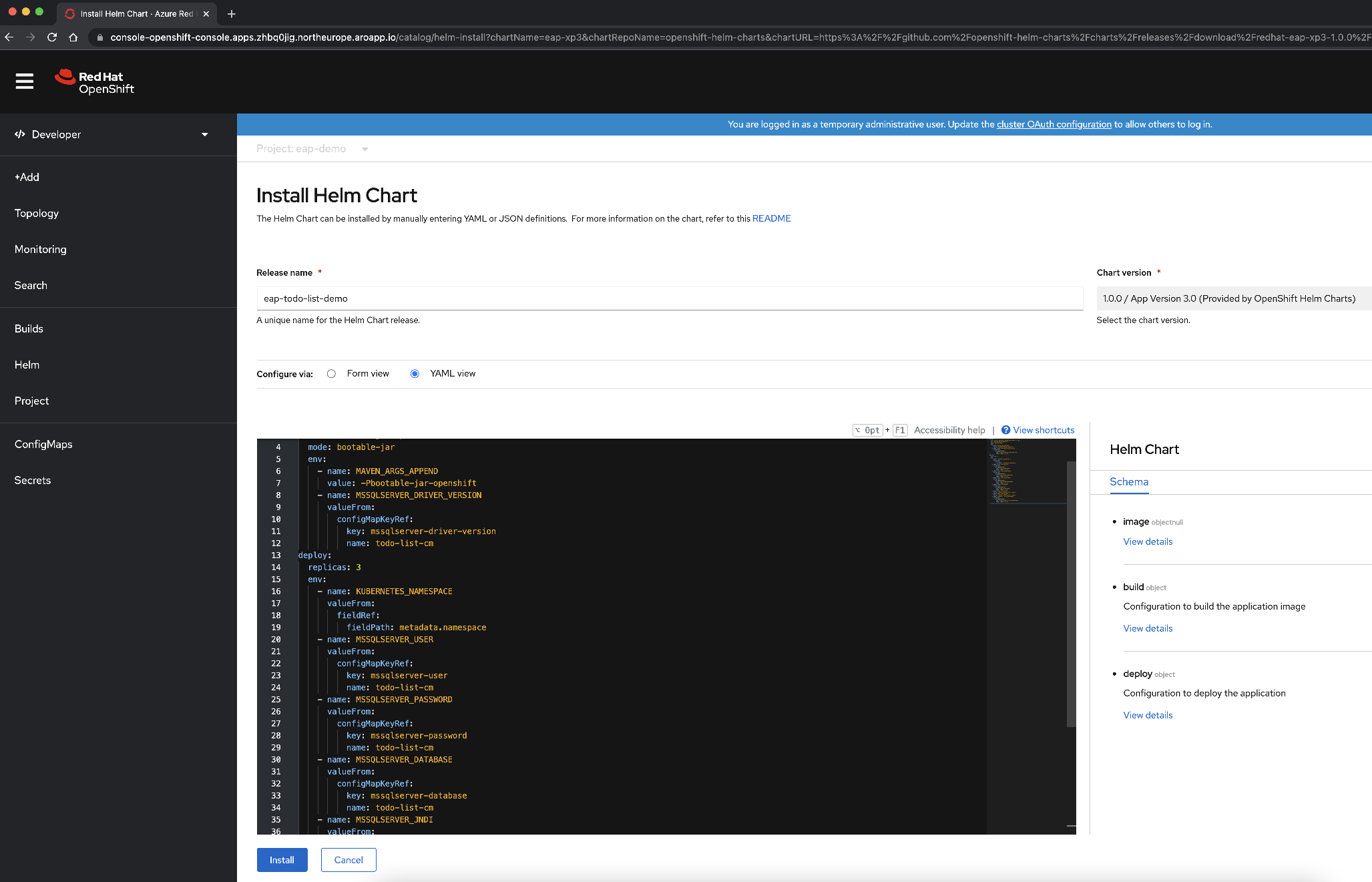
Ce contenu fait référence aux secrets que vous avez définis précédemment.
Enfin, sélectionnez Install (Installer) pour démarrer le déploiement de l’application. Cette action ouvre la vue Topologie avec une représentation graphique de la version Helm (nommée eap-todo-list-demo) et ses ressources associées.
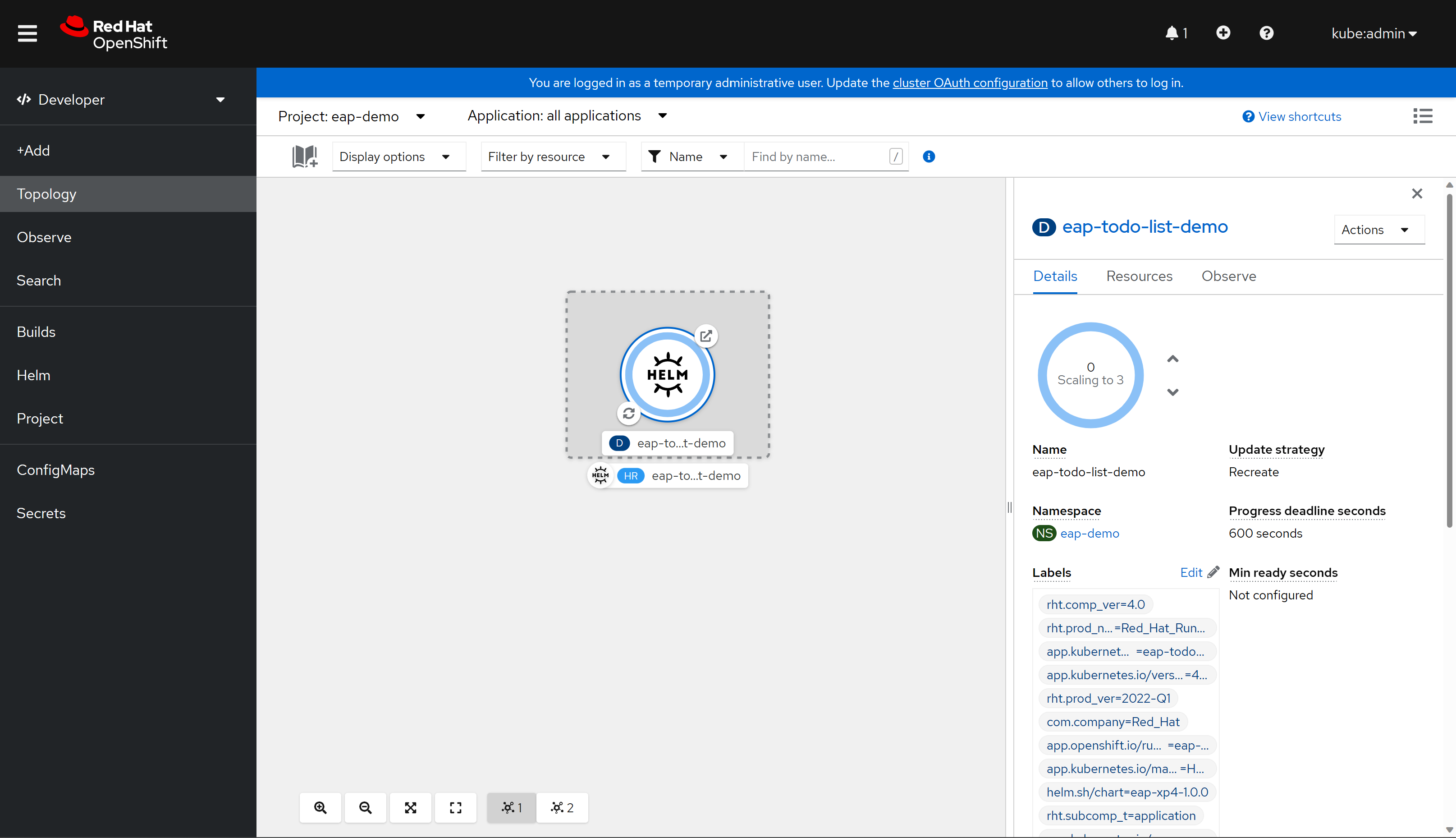
La version Helm (abrégée HR) est nommée eap-todo-list-demo. Elle comprend une ressource de déploiement (abrégée D) également nommée eap-todo-list-demo.
Si vous sélectionnez l’icône avec deux flèches dans un cercle situé en bas à gauche de la zone D , vous accédez au volet Journaux . Ici, vous pouvez observer la progression de la génération. Pour revenir à la vue de la topologie, sélectionnez Topologie dans le volet de navigation gauche.
Une fois la build terminée, l’icône en bas à gauche affiche une vérification verte
Une fois le déploiement terminé, le contour du cercle est bleu foncé. Si vous pointez la souris sur le bleu foncé, un message s’affiche indiquant quelque chose de similaire à
3 Running. Lorsque vous voyez ce message, vous pouvez accéder à l’URL de l’application (à l’aide de l’icône en haut à droite) à partir de l’itinéraire associé au déploiement.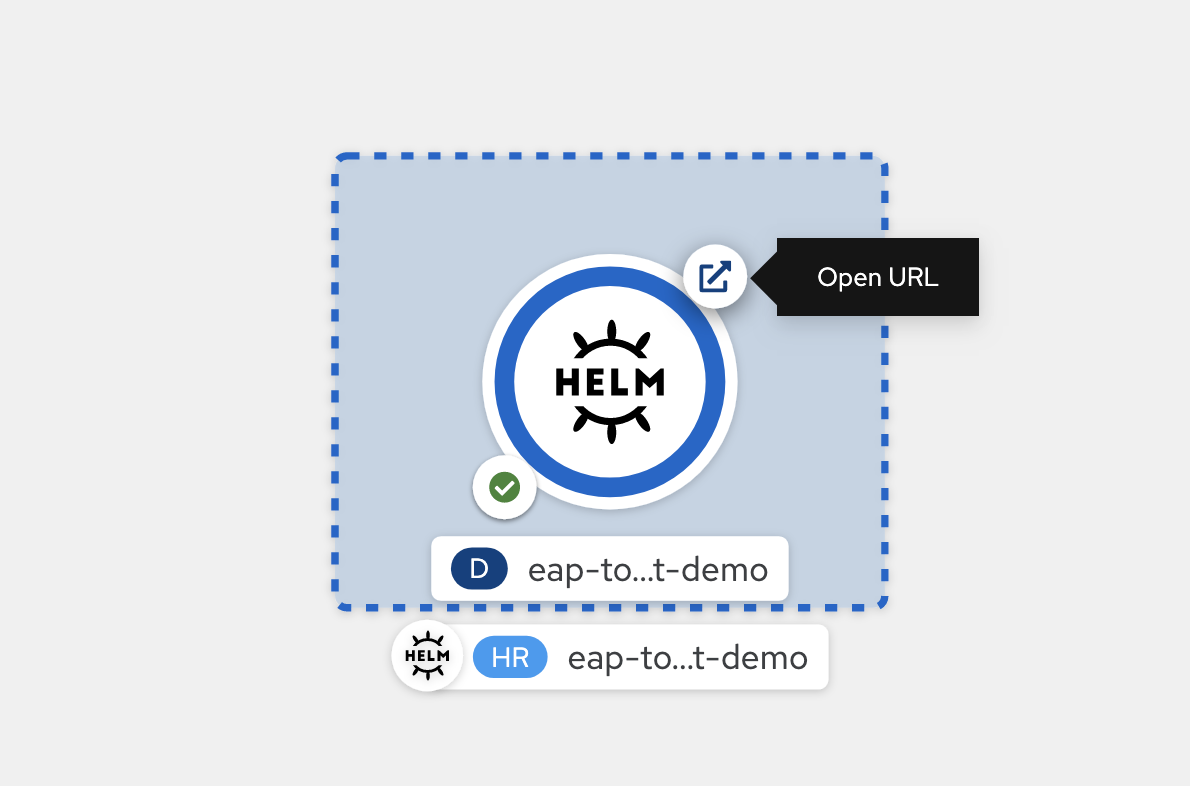
L’application s’ouvre dans votre navigateur et ressemble à l’image suivante, prête à être utilisée :
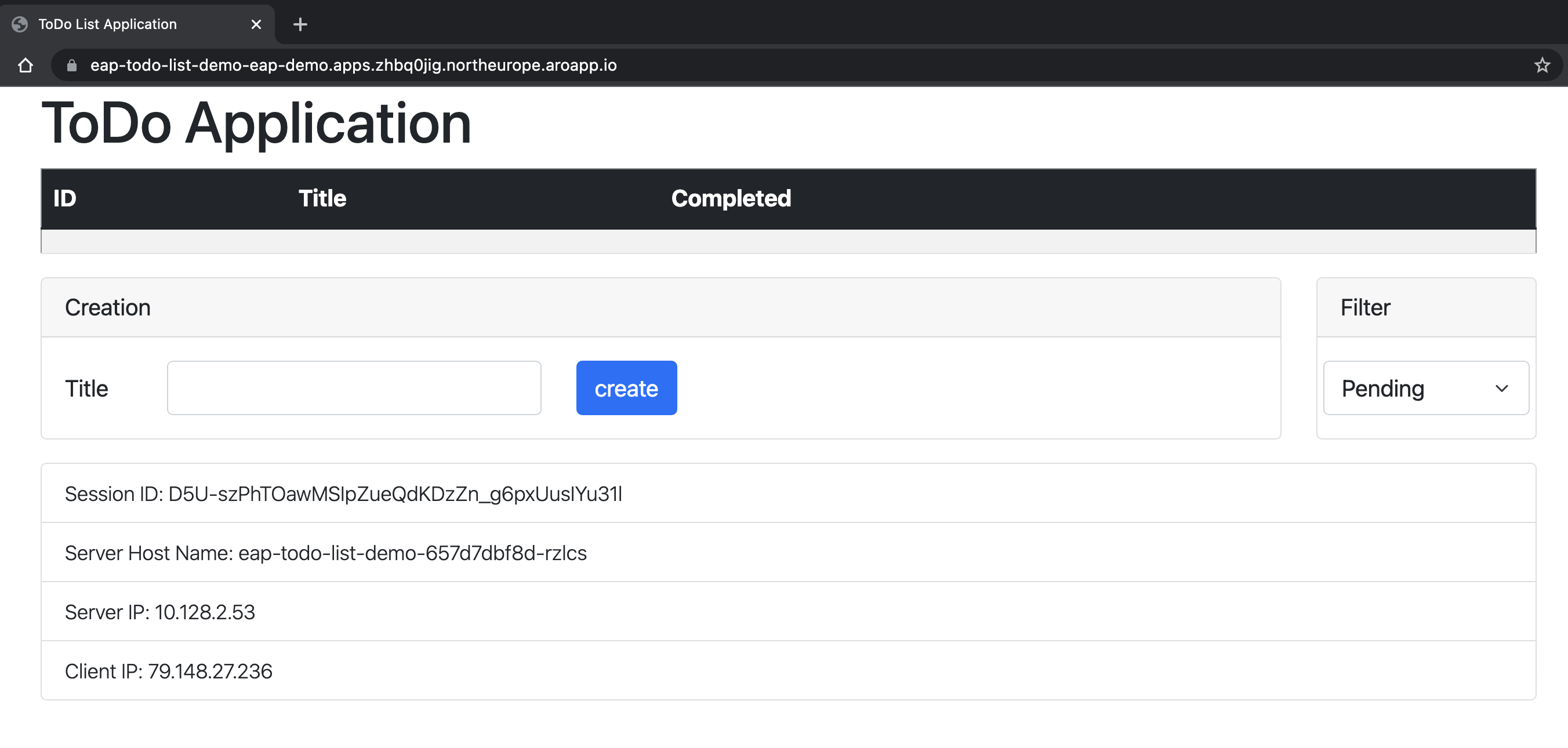
L’application affiche le nom du pod qui fournit les informations. Pour vérifier les capacités de clustering, vous pouvez ajouter des éléments Todo. Ensuite, supprimez le pod avec le nom indiqué dans le champ Nom d’hôte du serveur qui apparaît sur l’application à l’aide
oc delete pod <pod-name>de . Après avoir supprimé le pod, créez un nouveau Todo dans la même fenêtre d’application. Vous pouvez voir que le nouveau Todo est ajouté via une requête Ajax et que le champ Nom d’hôte du serveur affiche désormais un autre nom. En arrière-plan, l’équilibreur de charge OpenShift a distribué la nouvelle requête et l’a remis à un pod disponible. La vue Jakarta Faces est restaurée à partir de la copie de session HTTP stockée dans le pod qui traite la requête. En effet, vous pouvez voir que le champ ID de session n’a pas changé. Si la session n’est pas répliquée sur vos pods, vous obtenez un Jakarta FacesViewExpiredExceptionet votre application ne fonctionne pas comme prévu.

Nettoyer les ressources
Supprimer l’application
Si vous souhaitez uniquement supprimer votre application, vous pouvez ouvrir la console OpenShift et, dans la vue développeur, accéder à l’option de menu Helm. Dans ce menu, vous pouvez voir toutes les versions de Helm Chart installées sur votre cluster.

Localisez le chart Helm eap-todo-list-demo et, à la fin de la ligne, sélectionnez les trois points verticaux pour ouvrir l’entrée du menu contextuel d’action.
Sélectionnez Uninstall Helm Release (Désinstaller la version Helm) pour supprimer l’application. Notez que l’objet secret utilisé pour fournir la configuration de l’application ne fait pas partie du graphique. Vous devez le supprimer séparément si vous n’en avez plus besoin.
Exécutez la commande suivante si vous souhaitez supprimer le secret qui contient la configuration de l’application :
$ oc delete secrets/todo-list-secret
# secret "todo-list-secret" deleted
Supprimer le projet OpenShift
Vous pouvez également supprimer toutes les configurations créées pour cette démonstration en supprimant le projet eap-demo. Pour ce faire, exécutez la commande suivante :
$ oc delete project eap-demo
# project.project.openshift.io "eap-demo" deleted
Supprimer le cluster Azure Red Hat OpenShift
Supprimez le cluster Azure Red Hat OpenShift en suivant les étapes de Tutoriel : Supprimer un cluster Azure Red Hat OpenShift 4.
Supprimer le groupe de ressources
Si vous souhaitez supprimer toutes les ressources créées par les étapes précédentes, supprimez le groupe de ressources que vous avez créé pour le cluster Azure Red Hat OpenShift.
Étapes suivantes
Vous pouvez en savoir plus sur les références utilisées dans ce guide :
- Red Hat JBoss Enterprise Application Platform
- Azure Red Hat OpenShift
- Charts Helm pour JBoss EAP
- Fichier JAR de démarrage JBoss EAP
Continuez à explorer les options permettant d'exécuter JBoss EAP sur Azure.