Visualisations héritées
Cet article décrit les visualisations Azure Databricks héritées. Consultez Visualisations dans les notebooks Databricks pour connaître la prise en charge actuelle de la visualisation.
Azure Databricks prend également en charge en mode natif les bibliothèques de visualisation dans Python et R et vous permet d’installer et d’utiliser des bibliothèques tierces.
Créer une visualisation héritée
Pour créer une visualisation héritée à partir d’une cellule de résultats, cliquez sur + et sélectionnez Visualisation héritée.
Les visualisations héritées prennent en charge un ensemble complet de types de tracés :
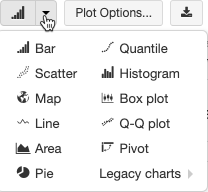
Choisir et configurer un type de graphique hérité
Pour choisir un graphique à barres, cliquez sur l’icône du graphique à barres  :
:
Pour choisir un autre type de tracé, cliquez sur ![]() à droite du graphique à barres et choisissez le type de tracé.
à droite du graphique à barres et choisissez le type de tracé.
Barre d’outils de graphique hérité
Les graphiques en courbes et à barres présentent une barre d’outils intégrée qui prend en charge un ensemble complet d’interactions côté client.
Pour configurer un graphique, cliquez sur Options de traçage....
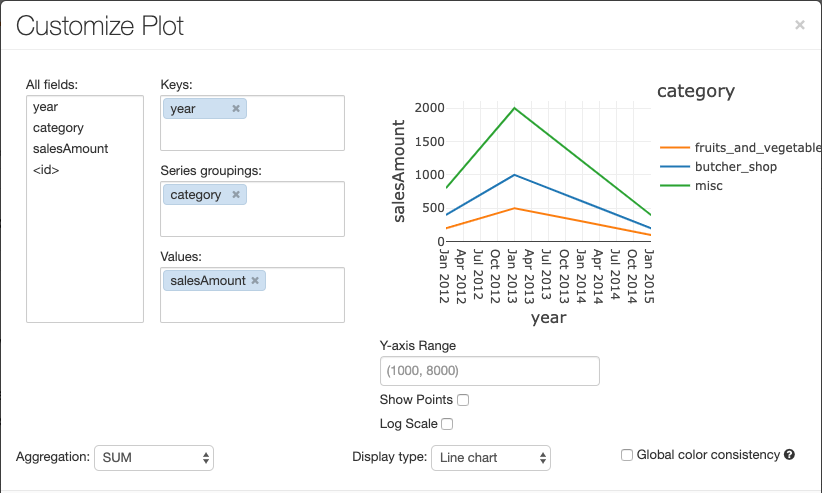
Le graphique en courbes présente quelques options de graphique personnalisées : définition d’une plage de l’axe des Y, affichage et masquage des points, et affichage de l’axe des Y avec une échelle logarithmique.
Pour plus d’informations sur les types de graphique existants, consultez :
Cohérence des couleurs entre les graphiques
Azure Databricks prend en charge deux types de cohérence des couleurs dans les graphiques hérités : ensemble de séries et globale.
La constance de couleur ensemble de séries$$$ affecte la même couleur à la même valeur si vous avez des séries ayant les mêmes valeurs mais dans des ordres différents (par exemple, A = ["Apple", "Orange", "Banana"] et B = ["Orange", "Banana", "Apple"]). Les valeurs étant triées avant le traçage, les deux légendes sont triées de la même façon (["Apple", "Banana", "Orange"]), et les mêmes valeurs reçoivent les mêmes couleurs. Toutefois, si vous aviez une série C = ["Orange", "Banana"], elle ne serait pas cohérente du point de vue la couleur avec l’ensemble A, car l’ensemble n’est pas le même. L’algorithme de tri affecte la première couleur à « Banana » dans l’ensemble C, mais la deuxième couleur à « Banana » dans l’ensemble A. Si vous souhaitez que ces séries soient cohérentes du point de vue la couleur, vous pouvez spécifier que les graphiques doivent avoir une constance de couleur globale.
Dans la constance de couleur globale, chaque valeur est toujours mappée à la même couleur, quelle que soient les valeurs de la série. Pour permettre cela pour chaque graphique, cochez la case Constance de couleur globale.
Remarque
Pour atteindre cette cohérence, Azure Databricks effectue un hachage direct à partir des valeurs vers les couleurs. Pour éviter les collisions (où deux valeurs sont mappées avec la même couleur), le hachage porte sur un grand ensemble de couleurs, ce qui a pour effet secondaire que des couleurs attrayantes ou facilement différenciées ne peuvent pas être garanties ; en raison de la multitude de couleurs, certaines sont très similaires à d’autres.
Visualisations de machine learning
En plus des types de graphiques standard, les visualisations héritées prennent en charge les paramètres et résultats d’entraînement de Machine Learning suivants :
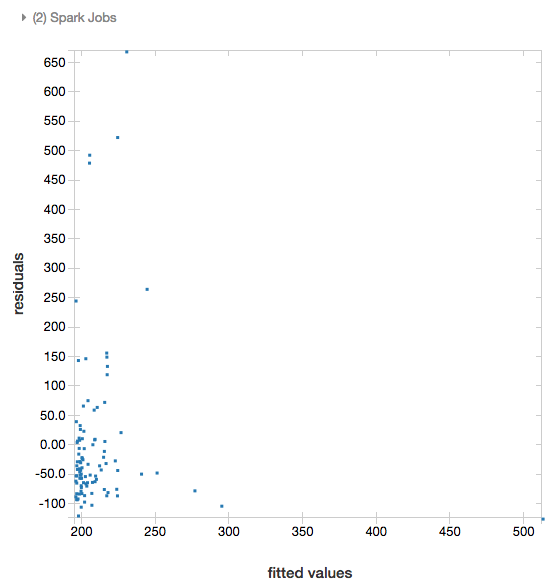
Résidus
Pour les régressions linéaires et logistiques, vous pouvez afficher un tracé des valeurs ajustées par rapport aux résidus. Pour obtenir ce tracé, fournissez le modèle et le DataFrame.
L’exemple suivant exécute une régression linéaire sur les données de la population des villes par rapport aux prix de vente des maisons, puis affiche les données des résidus par rapport aux valeurs ajustées.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
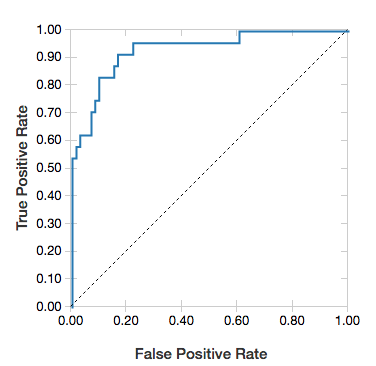
Courbes ROC
Pour les régressions logistiques, vous pouvez afficher une courbe ROC. Pour obtenir ce tracé, fournissez le modèle, les données préparées qui sont entrées dans la méthode fit et le paramètre "ROC".
L’exemple suivant développe un classifieur qui prédit à partir de divers attributs d’une personne si celle-ci a un revenu annuel inférieur ou égal à 50 000 ou supérieur à ce montant. Le jeu de données Adult est dérivé des données de recensement et contient des informations sur 48 842 personnes et leurs revenus annuels.
L’exemple de code mentionné dans cette section utilise un encodage à chaud.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")
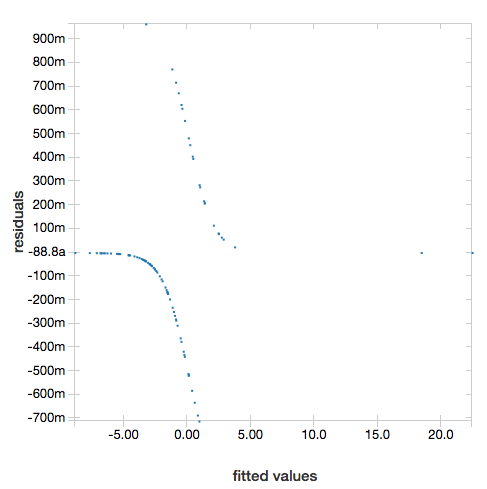
Pour afficher les résidus, omettez le paramètre "ROC" :
display(lrModel, preppedDataDF)
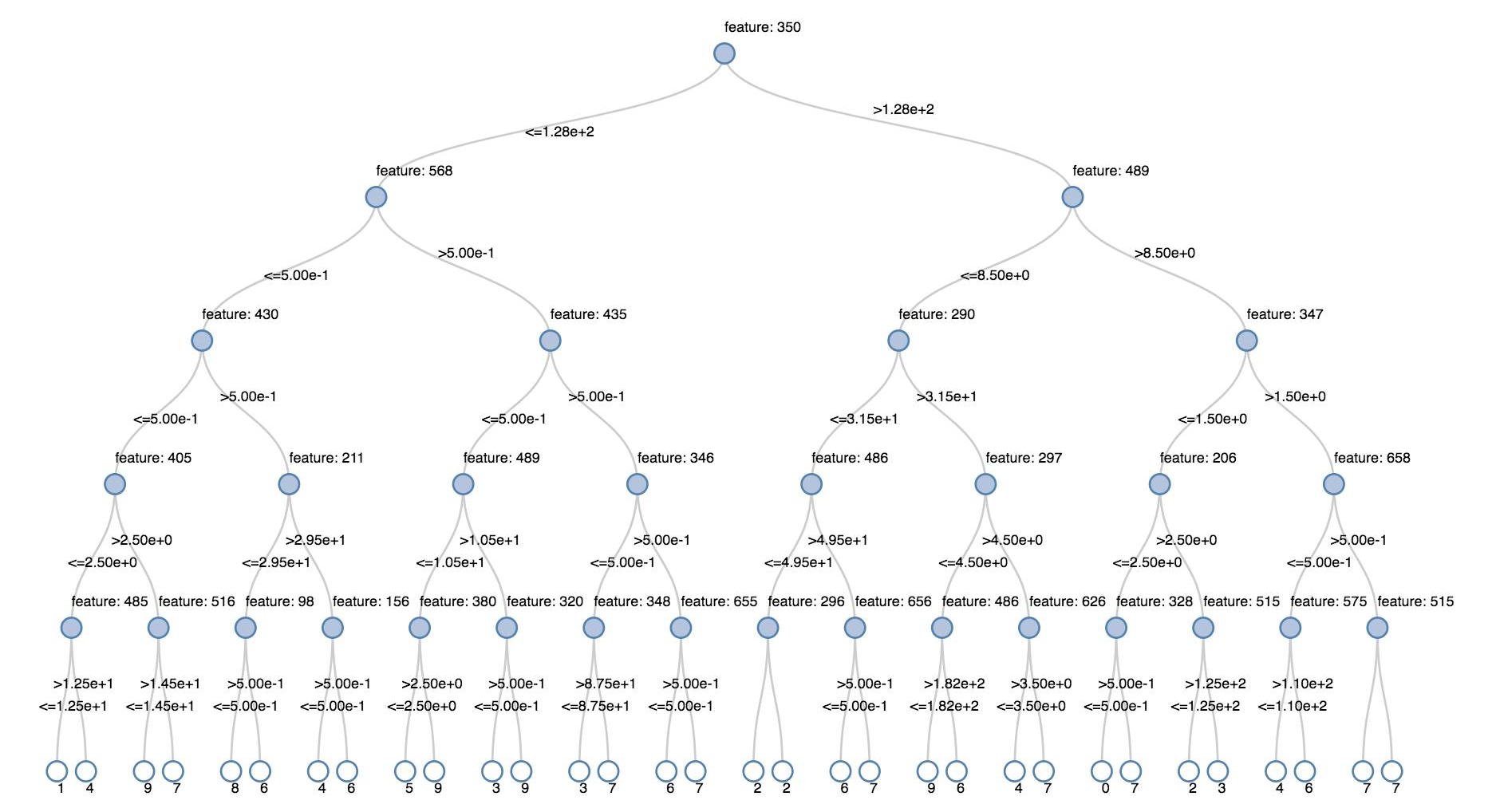
Arbres de décision
Les visualisations héritées prennent en charge le rendu d’un arbre de décision.
Pour obtenir cette visualisation, fournissez le modèle d’arbre de décision.
Les exemples suivants entraînent une arborescence à reconnaître des chiffres (0-9) à partir du jeu de données MNIST d’images de chiffres manuscrits, puis affichent l’arborescence.
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
DataFrames Structured Streaming
Pour visualiser le résultat d’une requête de streaming en temps réel, vous pouvez display un DataFrame Structured Streaming en Scala et Python.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
display prend en charge les paramètres facultatifs suivants :
streamName: nom de la requête de streaming.trigger(Scala) etprocessingTime(Python) : définit la fréquence d’exécution de la requête de streaming. S’il n’est pas spécifié, le système recherche si de nouvelles données sont disponibles dès que le traitement précédent est terminé. Pour réduire le coût de production, Databricks recommande de toujours définir un intervalle de déclencheur. L’intervalle de déclencheur par défaut est de 500 ms.checkpointLocation: emplacement où le système écrit toutes les informations de point de contrôle. S’il n’est pas spécifié, le système génère automatiquement un emplacement de point de contrôle temporaire sur DBFS. Pour que votre flux continue à traiter les données à partir de là où il s’est arrêté, vous devez fournir un emplacement de point de contrôle. En production, Databricks vous recommande de toujours spécifier l’optioncheckpointLocation.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Pour plus d’informations sur ces paramètres, consultez Starting Streaming Queries.
Fonction displayHTML
Les notebooks de langage de programmation Azure Databricks (Python, R et Scala) prennent en charge les graphismes HTML à l’aide de la fonction displayHTML ; vous pouvez passer à la fonction n’importe quel code HTML, CSS ou JavaScript. Cette fonction prend en charge les graphismes interactifs à l’aide de bibliothèques JavaScript telles que D3.
Pour des exemples d’utilisation de displayHTML, consultez :
Remarque
L’iframe displayHTML est traité à partir du domaine databricksusercontent.com et le bac à sable (sandbox) de l’iframe comprend l’attribut allow-same-origin. databricksusercontent.com doit être accessible à partir de votre navigateur. S’il est bloqué par votre réseau d’entreprise, il doit être ajouter dans une liste verte.
Images
Les colonnes contenant des types de données image sont restituées sous forme de HTML enrichi. Azure Databricks tente de restituer des miniatures d’images pour les colonnes DataFrame correspondant à l’ImageSchema Spark.
Le rendu des miniatures fonctionne pour toutes les images lues correctement par le biais de la fonction spark.read.format('image'). Pour les valeurs d’image générées par d’autres moyens, Azure Databricks prend en charge le rendu des images à 1, 3 ou 4 canaux (où chaque canal se compose d’un octet unique), avec les contraintes suivantes :
- Images à un canal : le champ
modedoit être égal à 0. Les champsheight,widthetnChannelsdoivent décrire avec précision les données d’image binaires dans le champdata. - Images à trois canaux : le champ
modedoit être égal à 16. Les champsheight,widthetnChannelsdoivent décrire avec précision les données d’image binaires dans le champdata. Le champdatadoit contenir des données de pixels dans des segments de trois octets, avec le classement de canaux(blue, green, red)pour chaque pixel. - Images à quatre canaux : le champ
modedoit être égal à 24. Les champsheight,widthetnChannelsdoivent décrire avec précision les données d’image binaires dans le champdata. Le champdatadoit contenir des données de pixels dans des segments de quatre octets, avec le classement de canaux(blue, green, red, alpha)pour chaque pixel.
Exemple
Supposons que vous ayez un dossier contenant des images :

Si vous lisez les images dans un DataFrame et que vous affichez ensuite le DataFrame, Azure Databricks rend les miniatures des images :
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Visualisations en Python
Dans cette section :
Seaborn
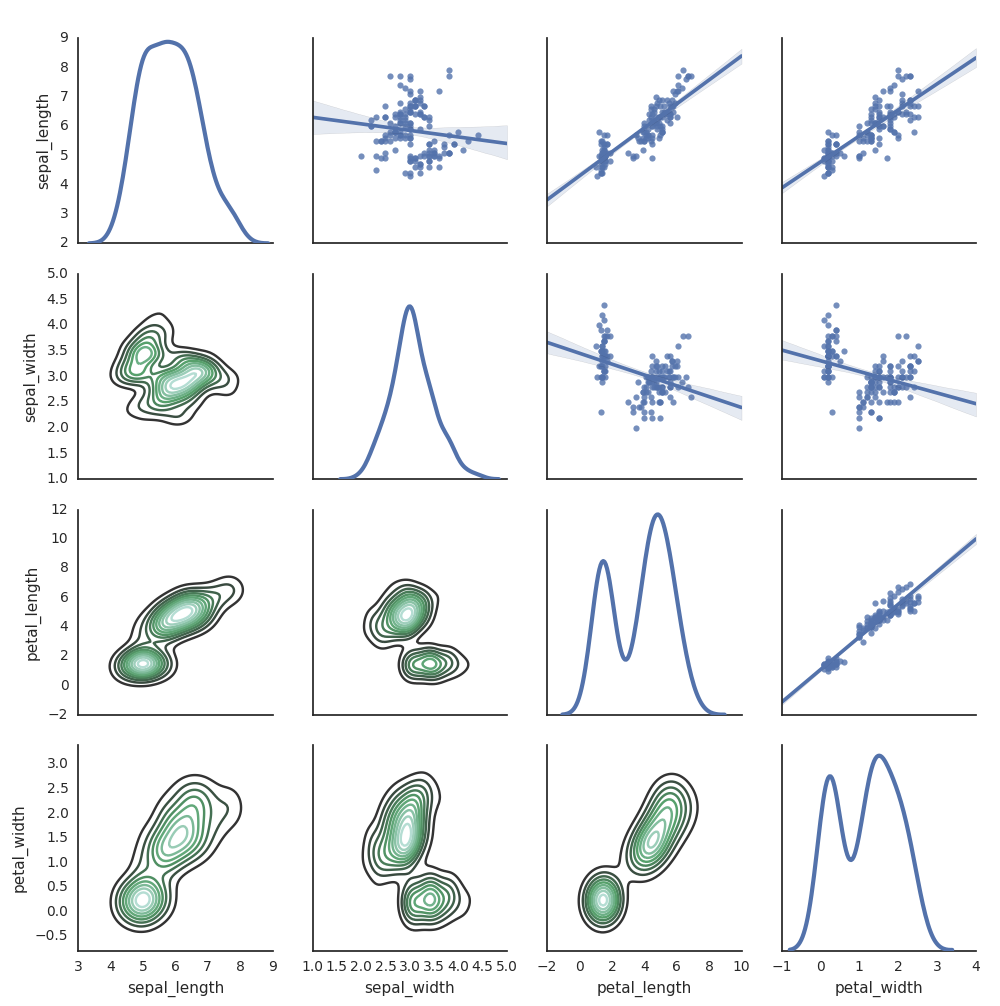
Vous pouvez également utiliser d’autres bibliothèques Python pour générer des tracés. Le runtime Databricks comprend la bibliothèque de visualisations seaborn. Pour créer un tracé seaborn, importez la bibliothèque, créez un tracé et passez-le à la fonction display.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
Autres bibliothèques Python
Visualisations en R
Pour tracer des données dans R, utilisez la fonction display comme suit :
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
Vous pouvez utiliser la fonction R plot par défaut.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
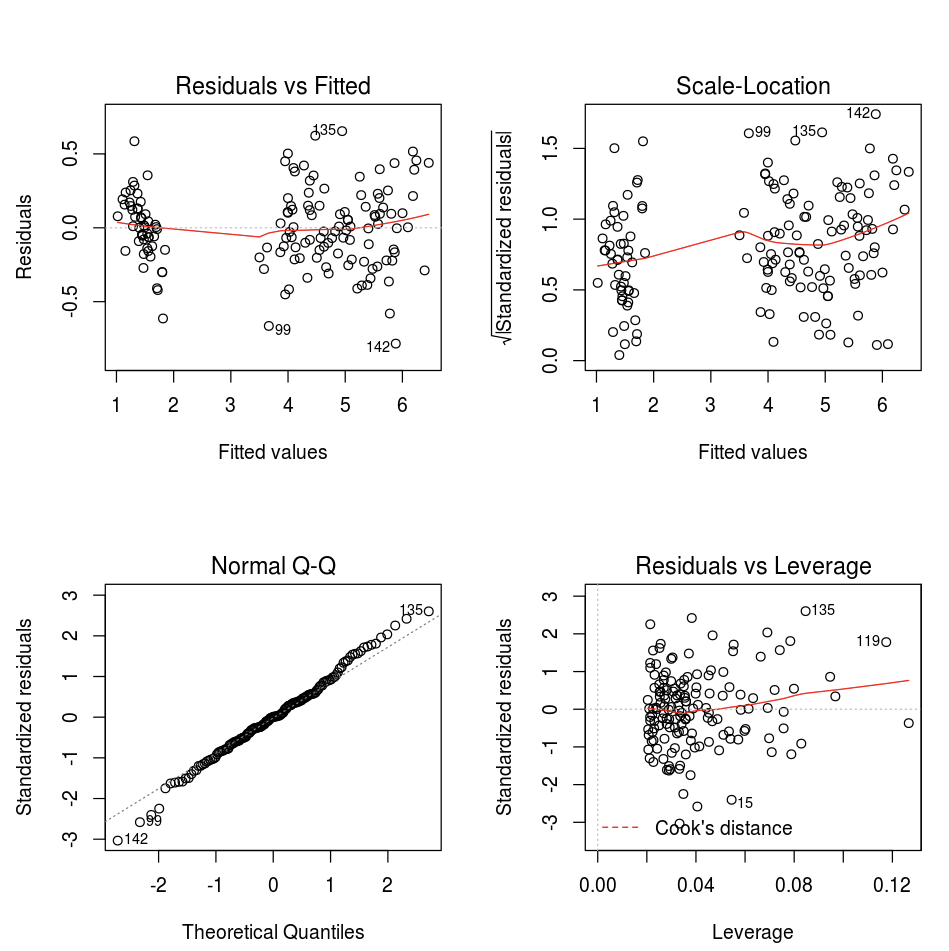
Vous pouvez aussi utiliser n’importe quel package de visualisation R. Le notebook R capture le tracé résultant au format .png et l’affiche inline.
Dans cette section :
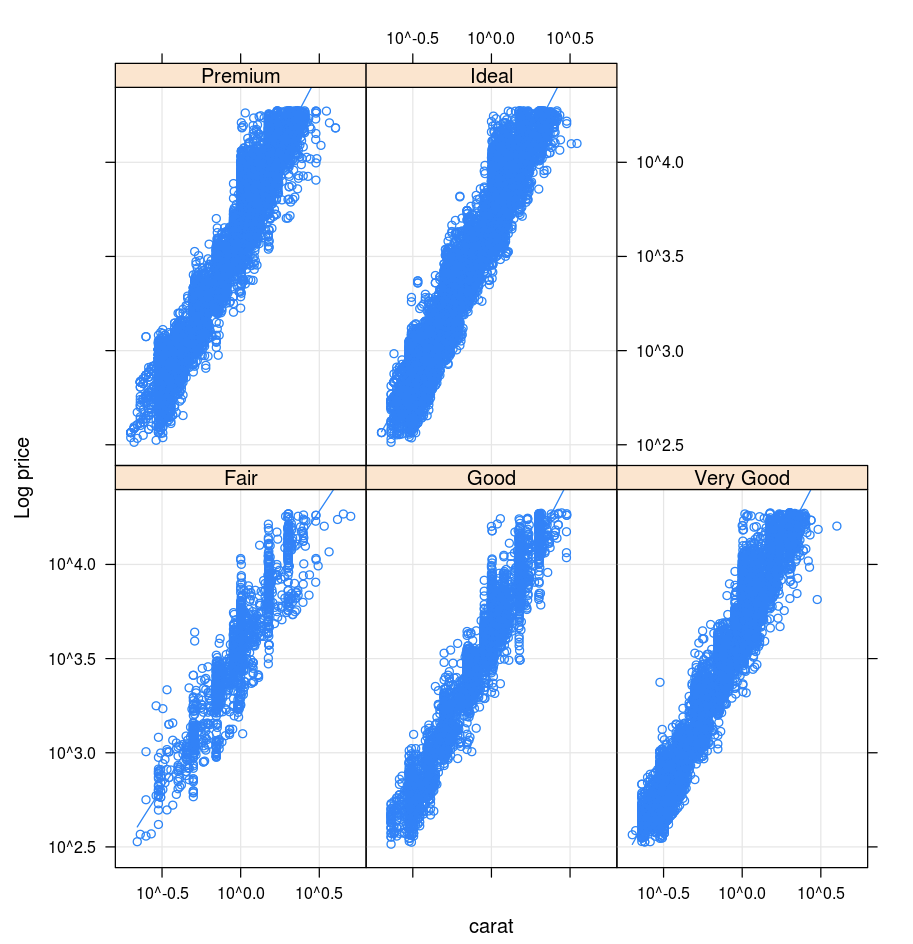
Lattice
Le package Lattice prend en charge les graphiques en treillis, c’est-à-dire les graphiques qui affichent une variable ou la relation entre les variables, conditionnée sur une ou plusieurs autres variables.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
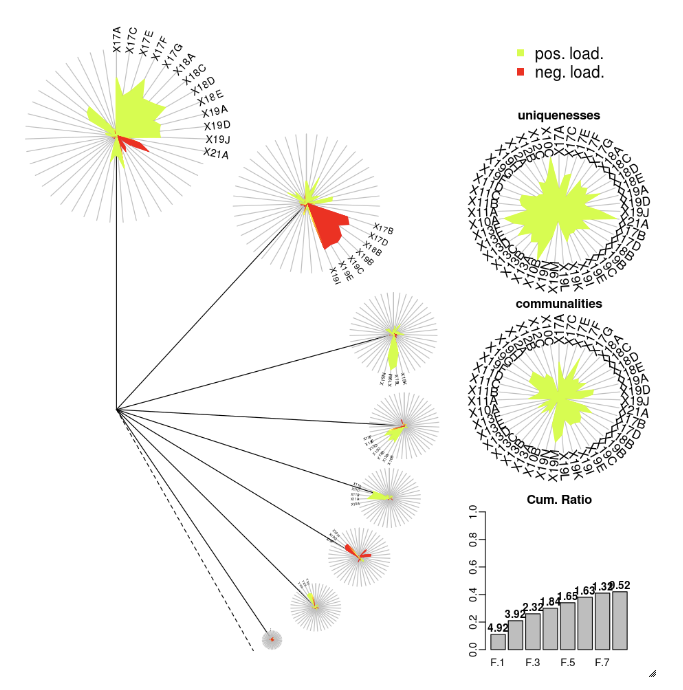
DandEFA
Le package DandEFA prend en charge les tracés en pissenlit.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
Plotly
Le package R Plotly est basé sur htmlwidgets for R. Pour des instructions d’installation et un notebook, consultez htmlwidgets.
Autres bibliothèques R
Visualisations en Scala
Pour tracer des données dans Scala, utilisez la fonction display comme suit :
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Notebooks de présentation approfondie pour Python et Scala
Pour une présentation approfondie des visualisations Python, consultez le notebook :
Pour une présentation approfondie des visualisations Scala, consultez le notebook :